










前言
随着城市化进程的加快,城市水体污染问题日益突出。在众多污染源中,降雨带来的径流被认为是城市水体污染的一个重要因素。本文以 2023 年 1 月至 2024 年 9 月期间某站点的降雨数据及其关联的污染物数据为基础,探讨降雨情形下污染物的变化规律。以高锰酸盐指数、氨氮和总磷作为主要污染物指标,通过对这些指标在不同降雨事件中的表现进行分析,以期为城市水污染治理提供参考。
分析方法
为了更好地理解降雨对污染物浓度的影响,首先定义了“降雨事件”这一概念。在本研究中,连续小时值均大于 0 的数值是为一个降雨事件,且连续无降雨超过 24 小时后视为不同的降雨事件,此外,只有当累计降雨量超过 10 毫米时,才会被计入我们的分析范围之内。 这样做是为了保证所选降雨事件具有一定的强度,能够对环境产生明显的影响。 分别计算每次降雨的开始时间、结束事件、累计雨量、最大小时雨量、降雨持续时间等特征。
data = pd.read_excel('pages/datas/降雨量.xlsx')
# 转换为DataFrame
columns = ['监测时间', '气温', '风力', '降雨量', '相对湿度']
df = pd.DataFrame(data, columns=columns)
df['监测时间'] = pd.to_datetime(df['监测时间'])
df['降雨量'] = df['降雨量'].fillna(0)
df['降雨量'] = df['降雨量'].astype(float)
# 删除包含NaT的行
# 将降雨量列中的空值和负数填充为0
df['降雨量'] = df['降雨量'].replace({np.nan: 0, '<0': 0}).astype(float)
# 确保所有降雨量都为非负数
df['降雨量'] = df['降雨量'].clip(lower=0)
def analyze_rainfall(df):
# 添加一列来标记降雨
df['RainEvent'] = (df['降雨量'] > 0).astype(int)
# 计算时间差
df['TimeDiff'] = df['监测时间'].diff().dt.total_seconds() / 3600
# 初始化一个新事件的标志
df['NewEvent'] = False
# 当时间差大于24小时时,设置为新事件
df.loc[df['TimeDiff'] >= 24, 'NewEvent'] = True
# 当前降雨与上一次降雨之间的状态变化时,标记为新事件
df.loc[(df['RainEvent'].shift() != df['RainEvent']) & (df['TimeDiff'] < 24), 'NewEvent'] = True
# 将第一行标记为新事件开始
df.loc[df.index[0], 'NewEvent'] = True
# 使用累加求和来给每个事件分配一个唯一的ID
df['RainEventID'] = df['NewEvent'].cumsum()
# 对每场雨进行分组,计算开始时间、结束时间、累计降雨量和最大降雨量
rain_events_summary = df.groupby(['RainEventID']).agg({
'监测时间': ['min', 'max'],
'降雨量': ['sum', 'max']
}).reset_index()
# 重命名列名
rain_events_summary.columns = ['RainEventID', 'Start', 'End', 'TotalRainfall', 'MaxRainfall']
# 计算降雨持续时间
rain_events_summary['DurationHours'] = (rain_events_summary['End'] - rain_events_summary[
'Start']).dt.total_seconds() / 3600
rain_events_summary['DurationHours'] = rain_events_summary['DurationHours'] + 1
# 过滤掉没有实际降雨的事件
rain_events_summary = rain_events_summary[rain_events_summary['TotalRainfall'] > 0]
# 检查并合并事件
merged_events = []
current_event = None
for i, row in rain_events_summary.iterrows():
if current_event is None:
current_event = row
else:
time_diff = row['Start'] - current_event['End']
time_diff_hours = time_diff.total_seconds() / 3600
if time_diff_hours <= 24:
# 合并事件
current_event['End'] = max(current_event['End'], row['End'])
current_event['TotalRainfall'] += row['TotalRainfall']
current_event['MaxRainfall'] = max(current_event['MaxRainfall'], row['MaxRainfall'])
current_event['DurationHours'] = (current_event['End'] - current_event['Start']).total_seconds() / 3600
else:
# 结束当前事件,开始新的事件
merged_events.append(current_event)
current_event = row
# 添加最后一个事件
if current_event is not None:
merged_events.append(current_event)
# 将合并后的事件转换为DataFrame
merged_df = pd.DataFrame(merged_events)
merged_df['RainEventID'] = range(1, len(merged_df) + 1)
return merged_df
# 应用函数并查看结果
result = analyze_rainfall(df)
min_total_rainfall = 10 # 你可以根据需要调整这个值
# 过滤掉累计雨量小于指定阈值的降雨场次
rain_events_summary = result[result['TotalRainfall'] >= min_total_rainfall]
# 重新排序 RainEventID
rain_events_summary.reset_index(drop=True, inplace=True)
# 重新分配
RainEventIDrain_events_summary['RainEventID'] = range(1, len(rain_events_summary) + 1)
经过统计,2023 年 1 月至 2024 年 9 月出有 35 次降雨事件,累计降雨量为 1476.40 毫米,其中属于降雨事件的降雨量达到了 1302.50 毫米,占比达 88.22%。因此用降雨事件分析对应的污染物浓度变化具有代表性。 降雨事件分布如下:
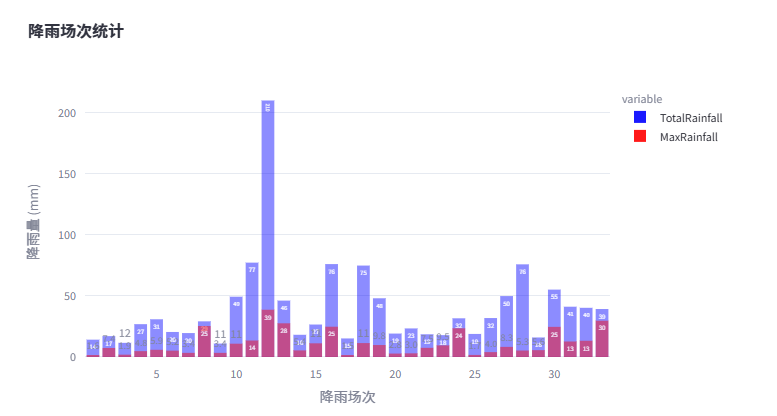
接下来,对应每次降雨事件事件范围,计算出站点各污染物的最大浓度、平均浓度以及变差系数。 其中变差系数为一列数的标准差除以期望,反映数据的变化情况,一般大于 0.2,表面数据波动较大。
# 加载数据
df_w = pd.read_excel('pages/datas/datas.xlsx') # 假设这是污染物数据集
# 将监测时间列转换为 datetime 类型
df_w['监测时间'] = pd.to_datetime(df_w['监测时间'])
# 获取污染物因子的列名
pollutant_columns = df_w.columns.drop(['监测时间'])
# 创建一个新的 DataFrame 来保存分析结果
pollutant_stats = pd.DataFrame(columns=['RainEventID'] +
[f'{col}_Ma' for col in pollutant_columns] +
[f'{col}_Me' for col in pollutant_columns] +
[f'{col}_Va' for col in pollutant_columns])
# 遍历每个降雨事件
for _, row in rain_events_summary.iterrows():
event_id = row['RainEventID']
start_time = row['Start']
end_time = row['End']
# 提取该事件时间段内的污染物数据
event_pollutants = df_w[(df_w['监测时间'] >= start_time) & (df_w['监测时间'] <= end_time)]
# 初始化统计数据
max_concentration = {}
mean_concentration = {}
variation_coefficient = {}
if event_pollutants.empty:
# 如果没有数据,记录为 NaN
for col in pollutant_columns:
max_concentration[col] = np.nan
mean_concentration[col] = np.nan
variation_coefficient[col] = np.nan
else:
# 计算每个因子的最大浓度、平均浓度和变差系数
for col in pollutant_columns:
if col in event_pollutants.columns and pd.notna(event_pollutants[col]).any():
max_concentration[col] = event_pollutants[col].max()
mean_concentration[col] = event_pollutants[col].mean()
variation_coefficient[col] = event_pollutants[col].std(ddof=0) / event_pollutants[col].mean()
else:
max_concentration[col] = np.nan
mean_concentration[col] = np.nan
variation_coefficient[col] = np.nan
# 构建统计数据行
stats_row = {
'RainEventID': event_id
}
for col in pollutant_columns:
stats_row[f'{col}_Ma'] = max_concentration[col]
stats_row[f'{col}_Me'] = mean_concentration[col]
stats_row[f'{col}_Va'] = variation_coefficient[col]
# 将统计数据行添加到 DataFrame 中
pollutant_stats = pd.concat([pollutant_stats, pd.DataFrame(stats_row, index=[0])], ignore_index=True)
# 合并统计数据到 rainfall_summary 中
rain_events_summary = pd.merge(rain_events_summary, pollutant_stats, on='RainEventID', how='left')
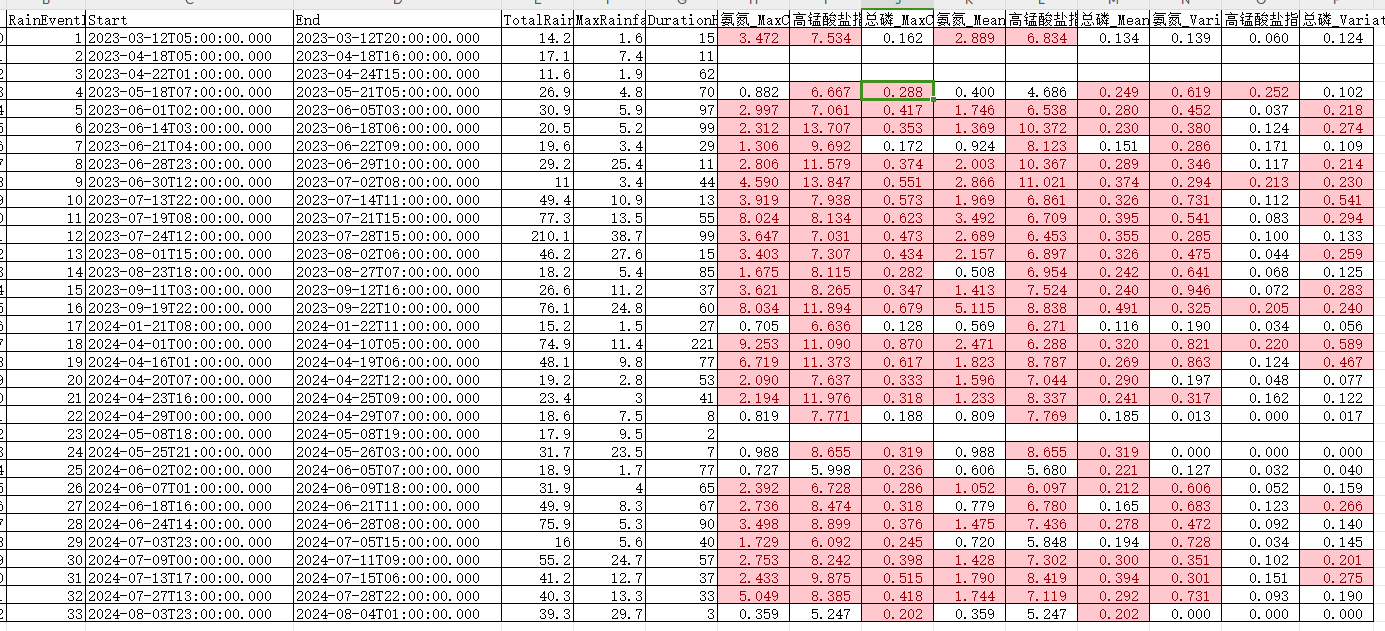
得到统计结果如下:其中因子最大浓度、平均浓度超标处标记为红色,变差系数大于 0.2 的也标为红色。从结果得出,超过 10 mm 的降雨量会引起对应站点水质超标,氨氮最敏感、总磷次之。
最后将各数据汇总,计算这些统计值之间的相关系数,并绘制相关性热图,得出单次降雨量、小时最大雨量与各指标的平均浓度、最大浓度并无强相关性;氨氮最大浓度与总磷最大浓度之间为强相关,符合污染物汇入特征。
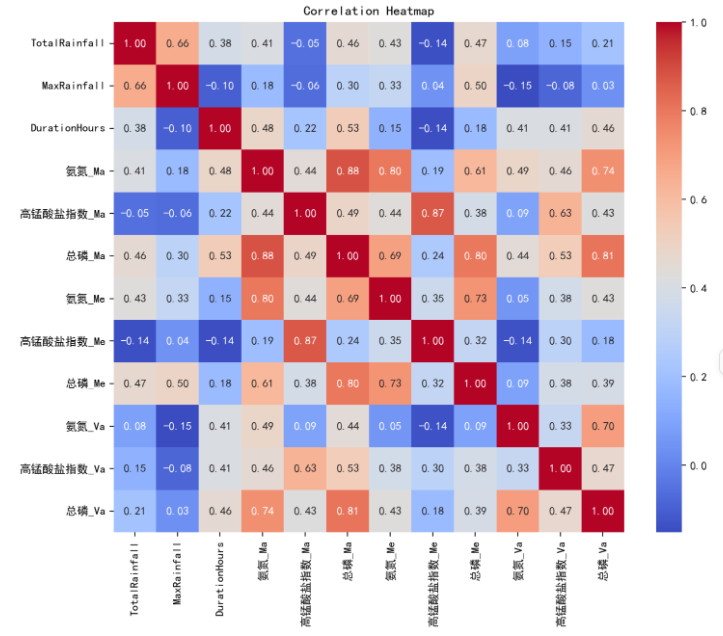
image.png
小结与讨论
-
污染物浓度超标现象:在各个降雨时间内,高锰酸盐指数、氨氮和总磷这三种主要污染物的最大浓度和平均浓度均存在超标现象。特别是氨氮的变差系数经常高于 0.2,表明其对降雨的响应较为敏感。
-
降雨量与污染物浓度的关系:单次降雨量、小时最大雨量与各指标的平均浓度、最大浓度并无强相关性;总磷与小时最大降雨量之间相关性为 0.5,为中相关,降雨引起的污染物变化较为复杂,污染物浓度变化与降雨量强度之间并非简单的线性关系,可能涉及更多因素,如降雨稀释、降雨间隔、清洁程度、污染事件等。
-
污染物间的相互作用:降雨引起的污染源汇入也导致各污染物之间的相关性增强。
-
局限及展望:本文仍存在一定局限性。首先,数据的时间跨度有限,未来可以通过长时间序列数据分析,进一步确认这些规律的稳定性和普遍性。其次,研究对象集中在少数几种污染物,未来可以扩展到更多的污染物种类,以全面评估降雨对城市水体质量的影响。此外,本文仅分析了一个雨量站与水质站的数据,样本量较小。未来研究可以考虑扩大样本范围,收集更多站点的数据,进一步验证降雨事件对污染物浓度变化的影响,并探索其他潜在的影响因素。此外,可以通过模型模拟的方法,定量分析不同降雨模式下的污染物迁移和转化机制,为制定更有效的污染控制策略提供科学依据。
-
管理建议:对于任何一次累计降雨量超过10毫米的情况,都需要引起管理者的重视。尤其是在高敏感区域,应加强监测频率,并采取有效措施减少污染物排放。
BY
纯个人经验,如有帮助,请收藏点赞,如需转载,请注明出处。
微信公众号:环境猫 er
CSDN : 细节处有神明
个人博客: https://maoyu92.github.io/
















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











