









文章目录
- 2018
- 2019
- 2020
- Interactive Image Segmentation with First Click Attention(CVPR)
- f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
- DISIR: DEEP IMAGE SEGMENTATION WITH INTERACTIVE REFINEMENT(ISPRS)
- Interactive Object Segmentation with Inside-Outside Guidance
- Getting to 99% Accuracy in Interactive Segmentation
- 2021
2018
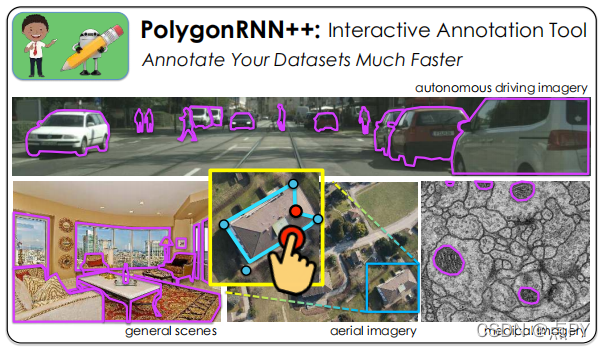
Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++(CVPR)
code: https://github.com/fidler-lab/polyrnn-pp-pytorch
摘要: 用对象掩码手动标记数据集是非常耗时的。在这项工作中,我们遵循[4]NN[4]的想法,使用循环中的人交互地生成对象的多边形注释。我们对该模型进行了几个重要的改进:1)我们设计了一个新的CNN编码器架构,2)展示了如何通过强化学习有效地训练模型,3)使用图神经网络显著提高输出分辨率,允许模型准确地标注图像中的高分辨率对象。对城市景观数据集[8]的广泛评估表明,我们的模型,我们称之为Polyon-RNN++,在自动(平均IoU绝对提高10%和16%)和交互模式(需要注释者减少50%的点击)方面都显著优于原始模型。我们进一步分析了跨域的场景,其中我们的模型在一个数据集上进行训练,并在来自不同域的领域的数据集上进行默认使用。结果表明,多边形-RNN++具有强大的泛化能力,比现有的像素级方法有了显著的改进。通过使用简单的在线微调,我们进一步实现了对新数据集的注释时间的高度减少,向即将在实践中使用的交互式注释工具又迈进了一步。
2019
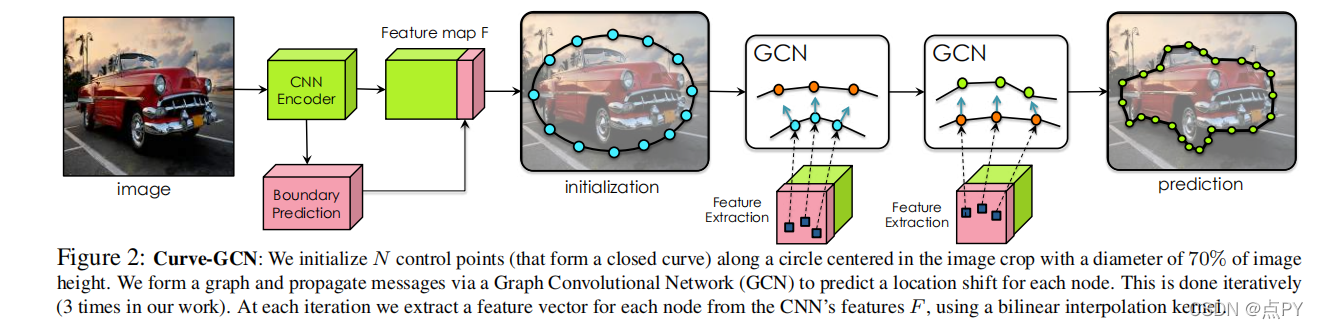
Fast Interactive Object Annotation with Curve-GCN
code: https://github.com/fidler-lab/curve-gcn
通过跟踪对象的边界来手动标记对象是一个费力的过程。在[7,2]中,作者提出了poogeRNN,它使用CNN-RNN架构以循环的方式生成多边形注释,允许通过循环中的人进行交互式校正。我们提出了一个新的框架,通过使用图卷积网络(GCN)同时预测所有的顶点,来减轻polugeRNN的序列性质。我们的模型是从端到端进行训练的。它支持通过多边形或样条注释对象,促进基于线和曲面对象的标记效率。我们表明,Curve-GCN在自动模式下优于所有现有的方法,包括强大的PSP-DeepLab[8,23],并且在交互模式下明显比Polyon-RNN++更有效。我们的模型自动运行速度为29.3ms,交互模式下为2.6ms,比多边形-RNN++快10倍和100倍。

2020
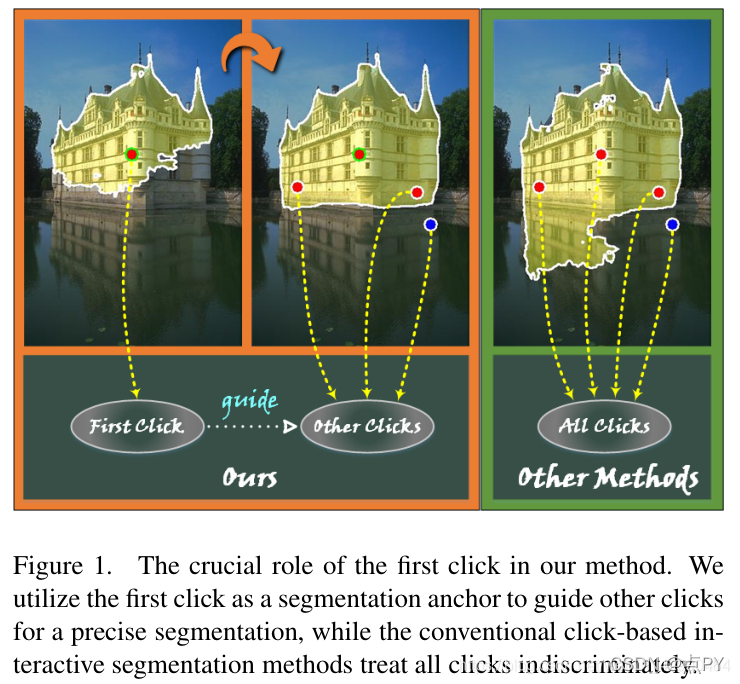
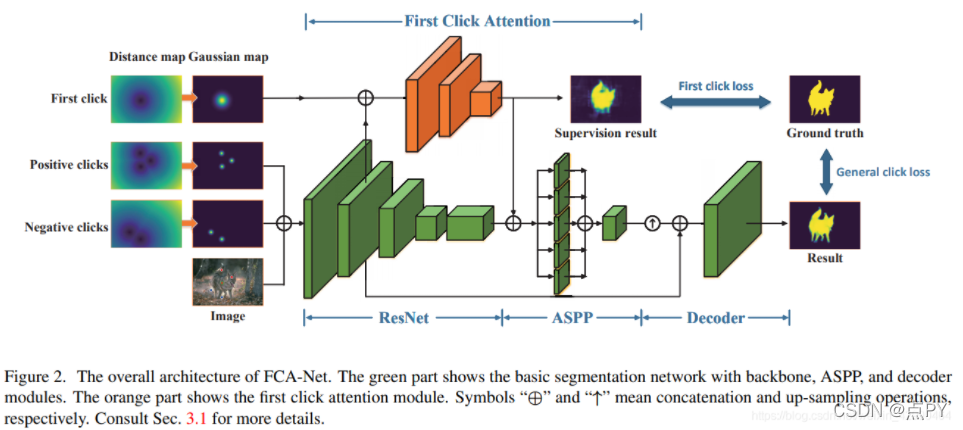
Interactive Image Segmentation with First Click Attention(CVPR)
code: https://github.com/frazerlin/fcanet
摘要
在交互式图像分割任务中,用户首先点击一个点对目标物体的主体进行分割,然后在错误标记的区域迭代提供更多的点,以实现精确的分割。现有的方法不加区别地对待所有的交互点,忽略第一次点击和其他点击之间的区别。在本文中,我们演示了第一次点击对于提供目标对象的位置和主体信息的关键作用。为了更好地利用这一特性,提出了一个名为First Click Attention Network (FCA-Net)的深度框架。
f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
code: https://github.com/saic-vul/fbrs_interactive_segmentation
深度神经网络已成为交互式分割的主流方法。正如我们在实验中所展示的,对于一些图像,经过训练的网络只需点击几次就能提供准确的分割结果,而对于一些未知对象,即使有大量的用户输入也不能获得令人满意的结果。最近提出的反向传播细化方案(BRS)[15]引入了一个交互式分割的优化问题,在硬情况下具有显著更好的性能。与此同时,BRS需要多次前后运行通过一个深度网络,与其他方法相比,每次点击的计算预算显著增加。我们提出了f-BRS(特征反向传播细化方案),它解决了一个关于辅助变量而不是网络输入的优化问题,并且只需要对网络的一小部分进行向前运行和向后传递。在GrabCut、伯克利、davis和SBD数据集上进行的实验表明,与原始的BRS[15]相比,每次点击的时间要少一个数量级。

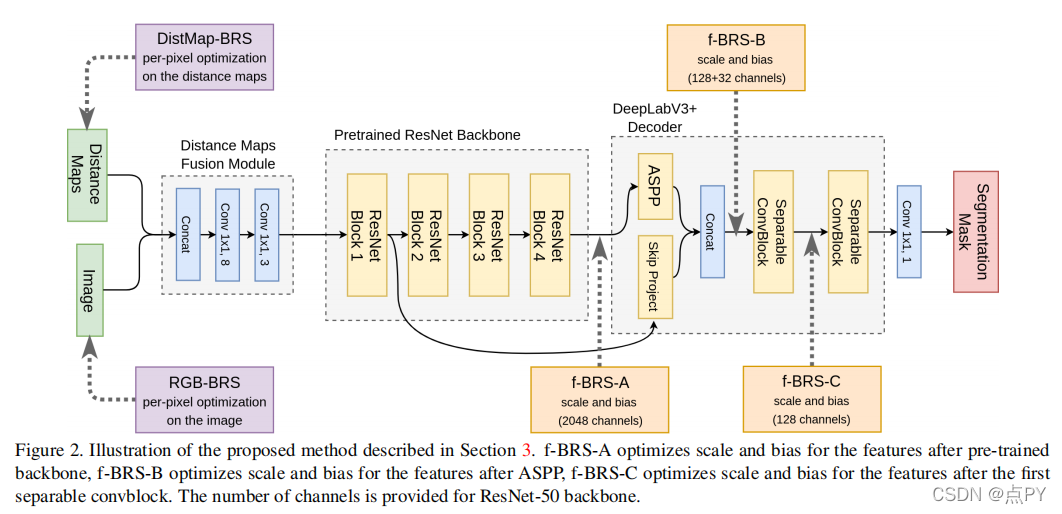
DISIR: DEEP IMAGE SEGMENTATION WITH INTERACTIVE REFINEMENT(ISPRS)
code: https://github.com/delair-ai/DISIR
摘要: 本文提出了一种交互式的多类航空图像分割方法。准确地说,它是基于一个同时利用RGB图像和注释的深度神经网络。从仅基于图像的初始输出开始,我们的网络然后使用图像和用户注释的连接来交互式地细化这个分割映射。重要的是,用户注释修改了网络的输入,而不是它的权重,从而实现了一个快速和平滑的过程。通过在两个公共空中数据集上的实验,我们发现用户注释是非常有益的:每次点击可以纠正大约5000个像素。我们分析了我们的框架的不同方面的影响,如注释的表示、训练数据的量或网络架构。
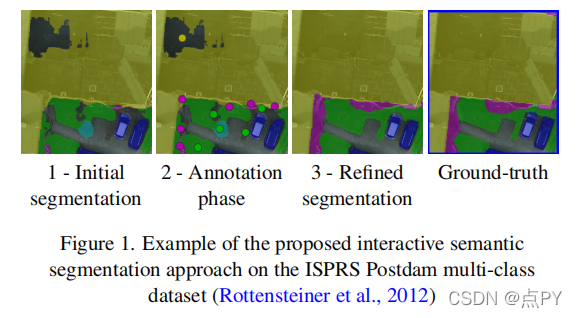
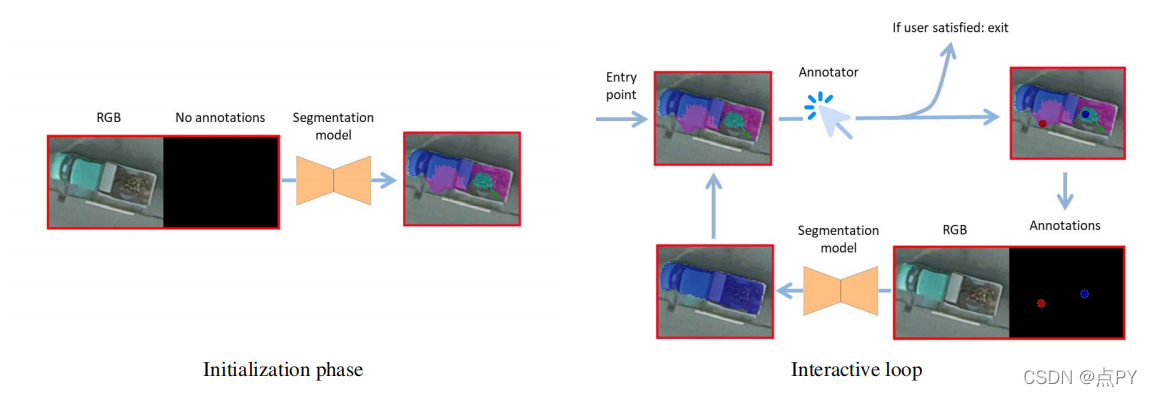
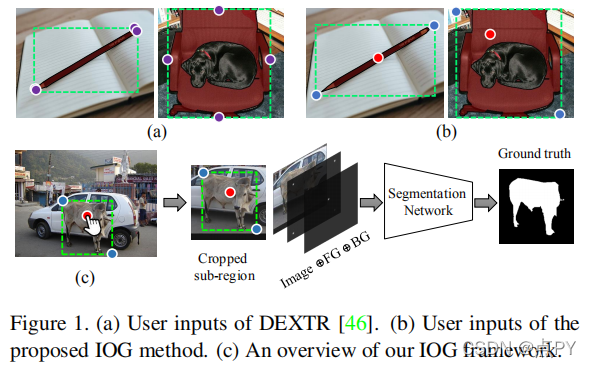
Interactive Object Segmentation with Inside-Outside Guidance
code: https://github.com/shiyinzhang/Inside-Outside-Guidance
摘要: 本文探讨了如何在最小化人工交互成本的同时获取精确的目标分割掩模。为了实现这一点,我们在这项工作中提出了一种内外指导(IOG)方法。具体地说,我们利用了在对象中心附近点击的一个内部点,以及在包含目标对象的紧密边界框的对称街角位置(左上角和右下角或右上角和左下角)上的两个外部点。这将导致总共一次前景点击和四次背景点击的分割。我们的IOG的优点是四方面的:1)这两个外部的点可以帮助消除来自其他物体或背景的干扰;2)内部的点可以帮助消除边界框内不相关的区域;3)内部和外部点很容易识别,减少了最先进的DEXTR在标记一些极端样本时引起的混淆;4)我们的方法自然支持额外的点击注释以进行进一步修正。尽管它很简单,但我们的IOG不仅在几个流行的基准测试上实现了最先进的性能,而且在不进行微调的情况下展示了强大的不同领域,如街景、航空图像和医学图像的泛化能力,而不进行微调。此外,我们还提出了一个简单的两阶段解决方案,使我们的IOG能够从现有的数据集中使用ImageNet和开放图像等现成的边界框生成高质量的实例分割掩码,展示了我们的IOG作为注释工具的优越性。
Getting to 99% Accuracy in Interactive Segmentation
code: https://github.com/marcoforte/fba_matting
摘要
交互式对象裁剪工具是图像编辑工作流的基石。最近,基于深度学习的交互式分割算法在处理复杂图像方面取得了重大进展,粗略的二值选择通常只需点击几下就可以获得。然而,一旦达到了这种粗略的选择,深度学习技术往往会趋于稳定。在这项工作中,我们将这个平台解释为当前算法无法充分利用每个用户交互,也解释为当前训练/测试数据集的局限性。
我们提出了一种新的交互式架构和一种新的训练方案,两者都是为了更好地利用用户工作流。我们还表明,通过引入一个专门为复杂对象边界设计的合成训练数据集,可以进一步获得显著的改进。全面的实验支持了我们的方法,我们的网络达到了最先进的性能。
2021
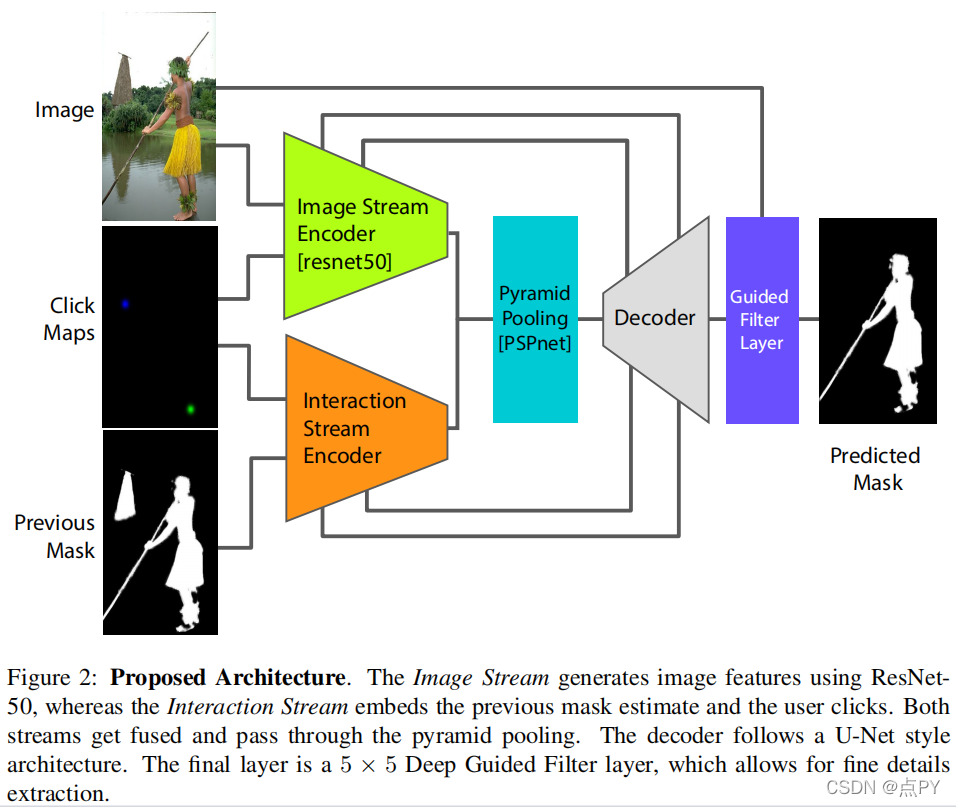
Quality-Aware Memory Network for Interactive Volumetric Image Segmentation
code: https://github.com/0liliulei/Mem3D
摘要
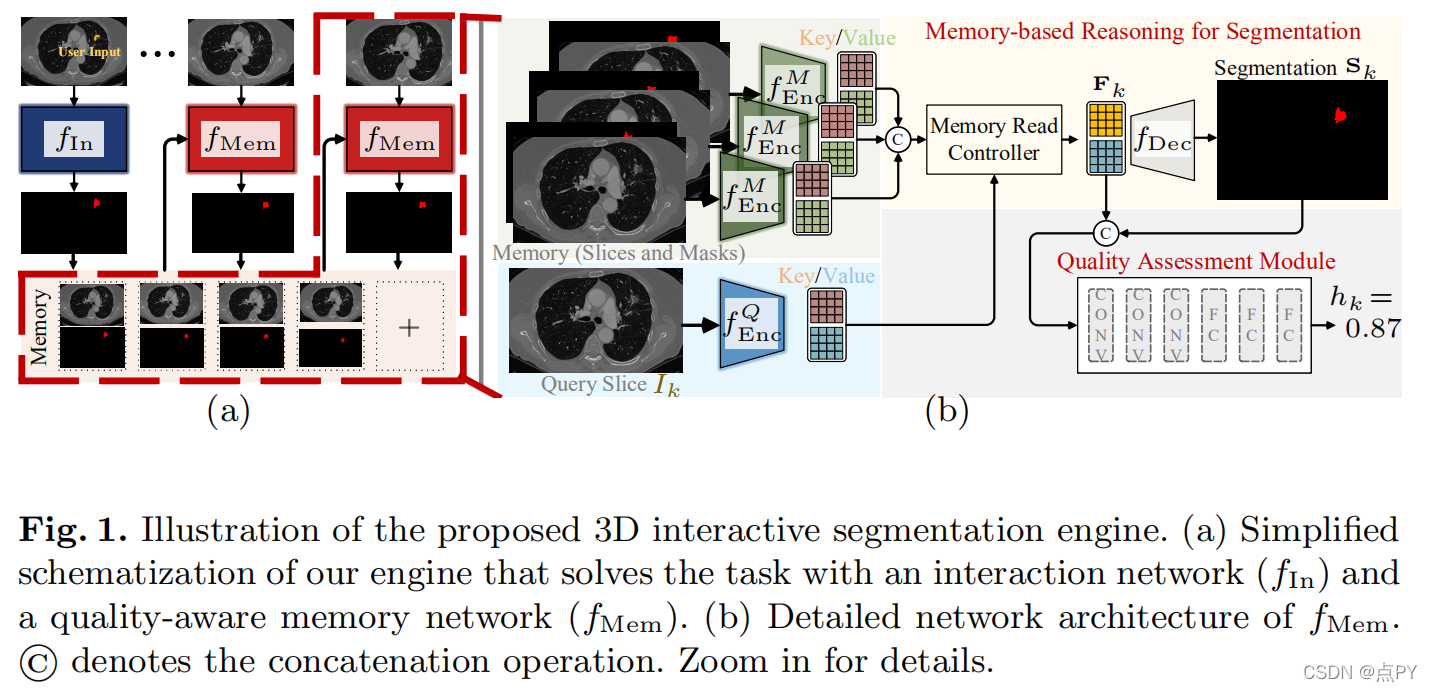
尽管最近自动医学图像分割技术的进展,全自动结果通常不能满足临床应用,通常需要进一步细化。在这项工作中,我们提出了一个质量感知记忆网络的交互式分割的三维医学图像。在任意切片上的用户引导下,首先利用交互网络获得初始的二维分割。质量感知记忆网络随后在整个体积上双向传播初始分割估计。基于其他切片的附加用户指导的后续细化可以以相同的方式合并。为了进一步促进交互分割,引入了一个质量评估模块,根据每个切片当前的分割质量建议下一个分割切片。该网络有两个吸引人的特点:1)记忆增强网络提供了快速编码过去分割信息的能力,这些信息将用于其他切片的分割;2)质量评估模块使模型能够直接估计分割预测的质量,这允许主动学习范式,用户优先标记质量最低的切片进行多轮细化。该网络产生了一个健鲁棒的交互式分割引擎,它可以很好地推广到各种类型的用户注释(例如,涂鸦、盒子)。在各种医学数据集上的实验结果表明,我们的方法与现有技术相比的优越性。
Reviving Iterative Training with Mask Guidance for Interactive Segmentation
code: https://github.com/saic-vul/ritm_interactive_segmentation
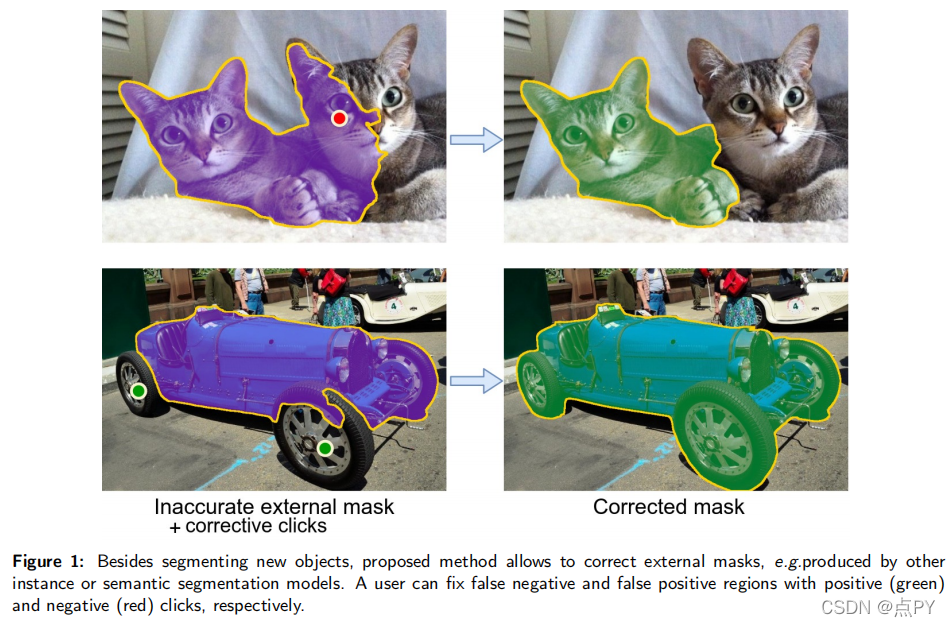
摘要: 最近关于基于点击的交互式分割的工作已经展示了通过使用各种推理时间优化方案的最新结果。与前馈方法相比,这些方法的计算成本要高得多,因为它们需要在推理过程中执行向后传递,并且很难部署在通常只支持向前传递的移动框架上。在本文中,我们广泛地评估了交互式分割的各种设计选择,并发现新的最先进的结果可以获得没有任何额外的优化方案。因此,我们提出了一个简单的前馈模型的基于点击的交互分割,使用了前面步骤的分割掩码。它不仅允许对一个全新的对象进行分割,而且还允许从一个外部掩码开始并纠正它。当分析在不同数据集上训练的模型的性能时,我们观察到训练数据集的选择极大地影响了交互分割的质量。我们发现,在COCO和高质量注释组合上训练的LVIS的模型的性能优于所有现有模型。















 4085
4085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











