







前言:
简单看了一下glusterfs,使用单节点构造glusterfs环境,导出的路径是是本地SSD在分区上。用qemu挂载glusterfs上的卷,用FIO测试IOPS,测试结果不理想。
大致分析了一下,怀疑fuse会导致性能下降。
分析:
1,libfuse & fuse
为了方便测试和便于分析问题,使用了libfuse。代码地址https://github.com/libfuse/libfuse
编译libfuse比较麻烦,不支持Makefile,需要用meson编译,而且meson的版本要求比较高,不能用apt-get直接安装。操作方法就是下载高版本的meson包,在meson包里面执行python3 setup.py install。
除了用户态的libfuse之外,还需要kernel支持。作者在Ubuntu1804上测试,fuse已经被编译到kernel中。在config文件(内核配置文件即ls /boot/config-uname -r)中CONFIG_FUSE_FS。如果是kmod的方式编译,执行modprobe fuse。
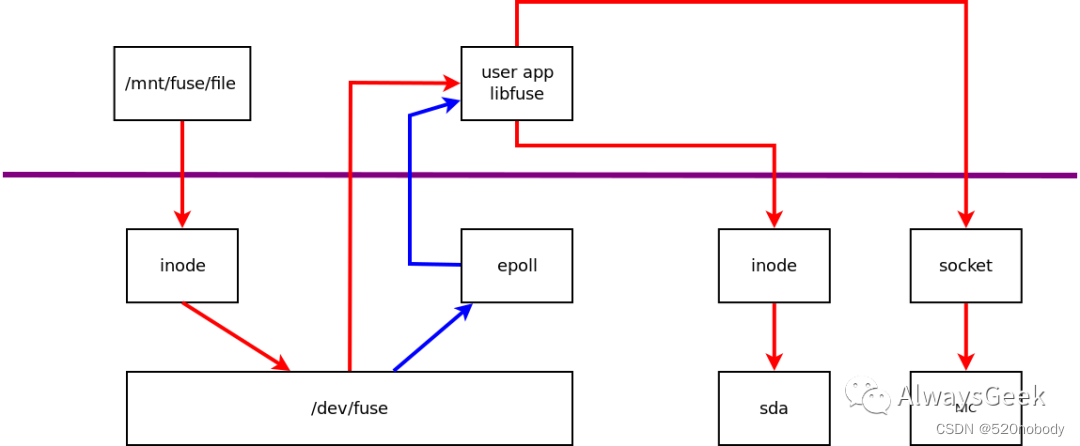
上图所示,红色数据流表示一个write请求,蓝色数据流表示事件的通知。
/mnt/fuse/是通过fuse挂载的目录,file是/mnt/fuse/的一个文件。
那么,整个过程:
a,用户写/mnt/fuse/file
b,/mnt/fuse通过fuse挂载,写file则找到对应的inode
c,向inode写数据,就会继续向后端写
d,fuse的后端并不是类似磁盘那样的后端。它把file的写请求数据拆分(为什么需要拆分呢?因为fuse最多使用32个page,也就是32*4K这么多),准备好,通知其他用户进程来读
e,用户态的user app,得到了event通知之后,从fuse读取出来数据。读取到的数据包括两部分:fuse使用的80bytes的控制字段,加上真正的数据
f,user app通过libfuse来解码控制字段的数据,判断出来是写请求。对于这样的数据,可以选择继续写向某个文件,或者通过socket写向远端
显然,相比于正常的写,路径变长了:
a,多了两次内存copy
b,user app异步通知
c,32个page的限制,会导致一次前端请求变成多次后端请求
d,fuse的协议成本,fuse使用另外的80bytes作为控制字段,数据传输变多了,也需要额外的CPU时间来decode控制字段,再根据decode结果,对应不同的处理
2,内存拷贝
虽说多了两次内存拷贝,会有时间消耗,但是,实际上消耗并没有那么夸张。作者写了一段测试代码:
#include <linux/kernel.h>
#include <linux/string.h>
#include <linux/gfp.h>
#include <linux/highmem.h>
#include <linux/module.h>
static int __init test_memcpy_init(void)
{
struct page *spage, *dpage;
char *saddr, *daddr;
int loop;
u64 start_time, delta;
spage = alloc_page(GFP_KERNEL | __GFP_ZERO);
if (spage == NULL) {
printk("test_memcpy_init alloc_page failed\n");
return -1;
}
saddr = kmap_atomic(spage);
dpage = alloc_page(GFP_KERNEL);
if (spage == NULL) {
printk("test_memcpy_init alloc_page failed\n");
goto unmap_free_spage;
}
daddr = kmap_atomic(dpage);
start_time = ktime_get_ns();
for (loop = 0; loop < 1000; loop++) {
memcpy(daddr, saddr, 4096);
}
delta = ktime_get_ns() - start_time;
printk("run memcpy %d times, total time : %lu ns, average time : %lu ns\n",
loop, delta, delta / loop);
if (daddr) {
kunmap_atomic(daddr);
}
if (dpage) {
__free_page(dpage);
}
unmap_free_spage:
if (saddr) {
kunmap_atomic(saddr);
}
if (spage) {
__free_page(spage);
}
out:
return 0;
}
static void __exit test_memcpy_exit(void)
{
printk(“test_memcpy_exit\n”);
}
module_init(test_memcpy_init);
module_exit(test_memcpy_exit);
MODULE_LICENSE(“GPL”);
MODULE_AUTHOR(“zhenwei pi p_ace@126.com”);
执行的结果来看,在E5-2650 V3上,拷贝一个page的平均时间大约150ns。其实并没有想象的那么夸张。
3,32 pages
在libfuse中,提供的example中有passthrough。正好用来实验后端写本地盘的场景。
从前端写入文件,strace -f dd if=/dev/zero of=/mnt/fuse/file bs=1M count=1,从strace的结果来看,是一次写入了1M的。
用strace -f -p PID来分析后端,
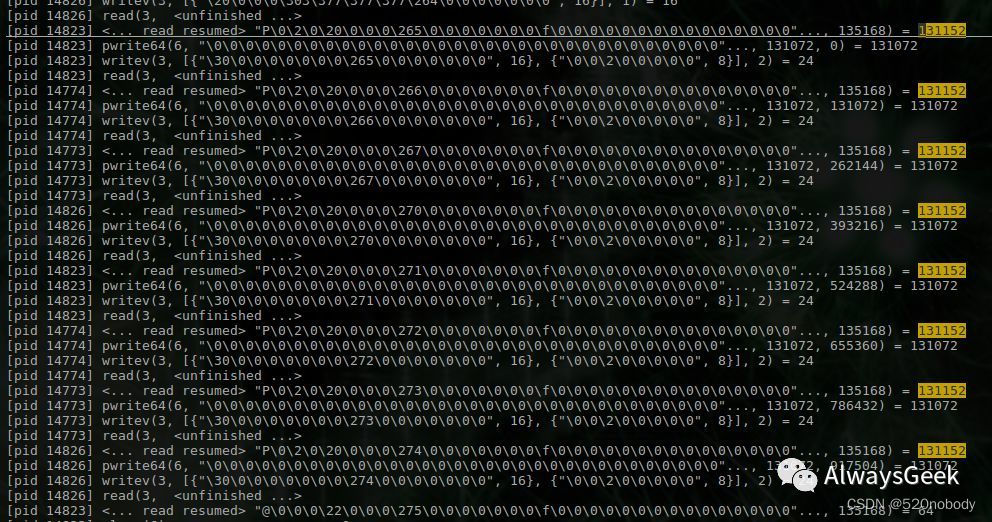
从上面的trace可以发现,passthrough每次从kernel读到的数据长度131152字节,然后向后端写131072字节(刚好32 × 4K)。
从fuse读取到的131152 – 131072 = 80。结合libfuse的代码,刚好就是从fuse读取到的数据控制字段的长度。上面的8次读,刚好是32 × 4K × 8 = 1M
32 pages的问题,影响最大的还是把前端的1次1M写请求,转化成了后端的8次读请求。
4,fio benchmark
可以预期,经过fuse的passthrough之后,性能会下降。看看到底会下降多少吧。测试的SSD是INTEL SSDSC2BB48。fio.conf如下:
[global]
runtime=120
group_reporting
[randwrite]
filename=/mnt/fuse/data
rw=randwrite
ioengine=libaio
direct=1
size=10G
iodepth=64
numjobs=1
blocksize=4K
randrepeat=0
thread=1
测试结果,不经过fuse的随机写性能57.5K,经过fuse下降到22.9k。不经过fuse的随机读70.8K,经过fuse下降到28.1k。
5,qemu + glusterfs
在本地搭建glusterfs;重新编译qemu,需要打开glusterfs的编译选项。
虚拟机启动后,挂载磁盘到qemu,libvirt使用的xml如下,
使用fio测试,测试结果大约10k左右。这里可能还可以继续优化配置,但是作者没有尝试,但是猜测性能应该不会超过上文的passthrough。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









