






Linux服务器背景:
CPUS: 40
MEMORY: 127.6 GB
MACHINE: x86_64 (2199 Mhz)
Linux Kernel: 4.4.121
TASKS: 19411
其实这不算大型服务器,我见过大型的一般内存4T起步,300多个cpu.
故障背景:
客户发现系统卡死,手动触发了kdump.
使用下面命令发现有3092个D状态进程。
crash> ps | grep UN | wc -l
3092
小编头一回碰到这么多进程变成D状态,第一感觉应该就是死锁导致。
于是:
crash> ps | grep UN > UN (导入UN文件慢慢玩)
发现UN里面有大量的ps、sudo这样的进程。
于是挑了一个ps进程查看它的堆栈:
crash> bt 50486
PID: 50486 TASK: ffff881171480c80 CPU: 18 COMMAND: “ps”
#0 [ffff8810d1d9bce0] schedule at ffffffff815f353d
#1 [ffff8810d1d9bd40] rwsem_down_read_failed at ffffffff815f61ea
#2 [ffff8810d1d9bd98] call_rwsem_down_read_failed at ffffffff813271d4
#3 [ffff8810d1d9bde0] down_read at ffffffff815f58b3
#4 [ffff8810d1d9bde8] proc_pid_cmdline_read at ffffffff8126c5e8
#5 [ffff8810d1d9be70] __vfs_read at ffffffff81202fd6
#6 [ffff8810d1d9bee8] vfs_read at ffffffff8120360a
#7 [ffff8810d1d9bf18] sys_read at ffffffff81204382
先看下proc_pid_cmdline_read 函数源码:
static ssize_t proc_pid_cmdline_read(struct file *file, char __user *buf,
size_t _count, loff_t *pos)
{
...
tsk = get_proc_task(file_inode(file));
if (!tsk)
return -ESRCH;
mm = get_task_mm(tsk);
down_read(&mm->mmap_sem);
...
}
void __sched down_read(struct rw_semaphore *sem)
从源码中知道 ps命令是在查询某个进程的状态时,执行down_read()没有获取到要查询进程struct mm_struct上的sem(读写锁)
所以下面开始汇编几个函数,先找到sem的值:
crash> dis proc_pid_cmdline_read
…
0xffffffff8126c5d7 <proc_pid_cmdline_read+135>: lea 0x68(%r15),%rax
0xffffffff8126c5db <proc_pid_cmdline_read+139>: mov %rax,%rdi
0xffffffff8126c5de <proc_pid_cmdline_read+142>: mov %rax,0x18(%rsp)
0xffffffff8126c5e3 <proc_pid_cmdline_read+147>: callq 0xffffffff815f58a0 <down_read>
crash> dis down_read
0xffffffff815f58a0 <down_read>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff815f58a5 <down_read+5>: mov %rdi,%rax
0xffffffff815f58a8 <down_read+8>: lock incq (%rax)
0xffffffff815f58ac <down_read+12>: jns 0xffffffff815f58b3 <down_read+19>
0xffffffff815f58ae <down_read+14>: callq 0xffffffff813271c0 <call_rwsem_down_read_failed>
0xffffffff815f58b3 <down_read+19>: retq
crash> dis call_rwsem_down_read_failed
0xffffffff813271c0 <call_rwsem_down_read_failed>: push %rdi
0xffffffff813271c1 <call_rwsem_down_read_failed+1>: push %rsi
0xffffffff813271c2 <call_rwsem_down_read_failed+2>: push %rcx
0xffffffff813271c3 <call_rwsem_down_read_failed+3>: push %r8
0xffffffff813271c5 <call_rwsem_down_read_failed+5>: push %r9
0xffffffff813271c7 <call_rwsem_down_read_failed+7>: push %r10
0xffffffff813271c9 <call_rwsem_down_read_failed+9>: push %r11
0xffffffff813271cb <call_rwsem_down_read_failed+11>: push %rdx
0xffffffff813271cc <call_rwsem_down_read_failed+12>: mov %rax,%rdi
0xffffffff813271cf <call_rwsem_down_read_failed+15>: callq 0xffffffff815f6100 <rwsem_down_read_failed>
发现call_rwsem_down_read_failed() 中push %rdi ,%rdi就是 down_read()的参数,也就是sem的值。
下面把call_rwsem_down_read_failed()的堆栈读出来找参数:
crash> rd ffff8810d1d9bd98 -e ffff8810d1d9bde0
ffff8810d1d9bd98: ffffffff813271d4 ffff880000000000 .q2…
ffff8810d1d9bda8: 0000000000024200 ffff88203f0226f0 .B…&.? …
ffff8810d1d9bdb8: 00000000004037ae 0000000000000078 .7@…x…
ffff8810d1d9bdc8: 0000000000000000 0000000000000020 … …
ffff8810d1d9bdd8: ffff88203c8fc0a8
发现 ffff88203c8fc0a8 就是sem的值,
crash> whatis -o mm_struct
…
[100] spinlock_t page_table_lock;
[104] struct rw_semaphore mmap_sem; (offset 0x68)
所以
mm_struct-> ffff88203c8fc040 (0xffff88203c8fc0a8 - 0x64)
所以马上就能知道ps命令在查询哪个进程时不能获取到sem锁。
crash> struct mm_struct.owner,mm_users ffff88203c8fc040
owner = 0xffff881f17b044c0
mm_users = {
counter = 3952
crash> struct task_struct.comm,pid 0xffff881f17b044c0
comm = “hmsserver\000st\000\000\000”
pid = 21909
发现那个进程是21909,知道了是这个进程,有没有用呢,看天意了,先查询它的堆栈再说:
crash> bt 21909
PID: 21909 TASK: ffff881f17b044c0 CPU: 15 COMMAND: “hmsserver”
#0 [ffff881f2ab43dd0] schedule at ffffffff815f353d
#1 [ffff881f2ab43e30] rwsem_down_read_failed at ffffffff815f61ea
#2 [ffff881f2ab43e80] call_rwsem_down_read_failed at ffffffff813271d4
#3 [ffff881f2ab43ec8] down_read at ffffffff815f58b3
#4 [ffff881f2ab43ed0] __do_page_fault at ffffffff81066d31
#5 [ffff881f2ab43f28] do_page_fault at ffffffff81066dcb
#6 [ffff881f2ab43f50] page_fault at ffffffff815fa822
发现并没有什么用,它自己都没能获取到sem锁.
这样就放弃吗? 生活还得继续,再说客户也不答应啊:)
从读写锁 rw_semaphore 开始柯南侦探模式:
crash> struct rw_semaphore -x ffff88203c8fc0a8
struct rw_semaphore {
count = 0xffffffff00000001,
wait_list = {
next = 0xffff880ee85bfe10,
prev = 0xffff88117aa67d50
},
…
owner = 0x0
}
发现 owner = 0x0 , 说明是一个读者持有了这把锁,这又增加了难度,
crash> struct -o rw_semaphore
struct rw_semaphore {
[0] long count;
[8] struct list_head wait_list;
[24] raw_spinlock_t wait_lock;
[28] struct optimistic_spin_queue osq;
[32] struct task_struct *owner;
}
这样,然后我就把所有等待这个锁的进程全部找出来,把持有sem锁地址
ffff88203c8fc0a8( rw_sema phore )的进程也全部找出来,第一个输出结果有2947个进程,第二个的结果有3032个进程。一般持有这个sem锁的进程在3032-2947的进程上,我找了好几个小时都没看出端倪,好吧,下班吧,难搞哦。
crash> list rwsem_waiter.list -s rwsem_waiter.task,type -h 0xffff880ee85bfe10
crash> search -t ffff88203c8fc0a8
从上面的分析来看,完全找不到线索,而且进程特别特别多,但是小编也没放弃,吃这碗饭,也没办法:)
于是看下sudo进程,找出一个sudo进程(sudo和ps看起来功能就完全没交叉):
PID: 22216 TASK: ffff8810ec908e80 CPU: 15 COMMAND: “sudo”
#0 [ffff880f1d09fc78] schedule at ffffffff815f353d
#1 [ffff880f1d09fcd8] schedule_preempt_disabled at ffffffff815f3e2e
#2 [ffff880f1d09fce8] __mutex_lock_slowpath at ffffffff815f5665
#3 [ffff880f1d09fd48] mutex_lock at ffffffff815f56f3
#4 [ffff880f1d09fd58] rtnetlink_rcv at ffffffff81512135
#5 [ffff880f1d09fd68] netlink_unicast at ffffffff815331c3
#6 [ffff880f1d09fda0] netlink_sendmsg at ffffffff815335b3
#7 [ffff880f1d09fe10] sock_sendmsg at ffffffff814e6cc6
#8 [ffff880f1d09fe28] SYSC_sendto at ffffffff814e70f7
#9 [ffff880f1d09ff50] entry_SYSCALL_64_fastpath at ffffffff815f7683
这里又弄出mutex_lock,真是一波未平,一波又起。
用同样的方法找mutex_waiter的地址
void __sched mutex_lock(struct mutex *lock)
crash> rd -SS ffff880f1d09fce8 -e ffff880f1d09fd48
ffff880f1d09fce8: __mutex_lock_slowpath+149 ffff880126b63cf0
ffff880f1d09fcf8: ffff880fd53f7cf0 [ffff8810ec908e80:task_struct]
ffff880f1d09fd08: 00000000024000c0 0000000000000180
ffff880f1d09fd18: rtnl_mutex [ffff8810d2971800:kmalloc-256]
ffff880f1d09fd28: 0000000000000014 0000000000000000
ffff880f1d09fd38: 0000000000000000 [ffff8810a00ba000:kmalloc-2048]
从堆栈来看 ffff880fd53f7cf0 就是mutex_waiter, rtnl_mu tex 就是mutex_lock的参数。
这样有些眉目了,在内核源码中找到 rtnl_mutex 是在下面文件中调用。
net/core/rtnetlink.c:
void rtnl_lock(void)
{
mutex_lock(&rtnl_mutex);
}
所以看下mutex的owner是谁?
crash> struct mutex 0xffffffff81f0a180
struct mutex {
count = {
counter = -143
},
…
},
wait_list = {
next = 0xffff880f077d3dd0,
prev = 0xffff88020545fcf0
},
owner = 0xffff88103e4dc300,
…
}
crash> struct task_struct.pid,comm 0xffff88103e4dc300
pid = 26299
comm = “kworker/7:2\000\000\000\000”
owner找到了,是kworker/7:2进程,看下它的堆栈,发现是i40e内核驱动模块持有了mutex锁。
crash> bt 26299
PID: 26299 TASK: ffff88103e4dc300 CPU: 7 COMMAND: “kworker/7:2”
#0 [ffff880f4235fba8] schedule at ffffffff815f353d
#1 [ffff880f4235fc08] schedule_timeout at ffffffff815f63e1
#2 [ffff880f4235fcb0] msleep at ffffffff810ee599
#3 [ffff880f4235fcc0] napi_disable at ffffffff814fd4be
#4 [ffff880f4235fcd8] i40e_down at ffffffffa0628ab9 [i40e]
#5 [ffff880f4235fd10] i40e_vsi_close at ffffffffa0628b73 [i40e]
#6 [ffff880f4235fd30] i40e_close at ffffffffa0628ef1 [i40e]
#7 [ffff880f4235fd38] i40e_pf_quiesce_all_vsi at ffffffffa0628c8a [i40e]
#8 [ffff880f4235fd50] i40e_prep_for_reset at ffffffffa0628d81 [i40e]
#9 [ffff880f4235fd70] i40e_do_reset at ffffffffa062ccf3 [i40e]
#10 [ffff880f4235fd90] i40e_service_task at ffffffffa062ead2 [i40e]
#11 [ffff880f4235fe38] process_one_work at ffffffff81097984
#12 [ffff880f4235fe78] worker_thread at ffffffff81098566
#13 [ffff880f4235fed0] kthread at ffffffff8109da59
#14 [ffff880f4235ff50] ret_from_fork at ffffffff815f7aaf
接下来查看内核i40e驱动代码:
i40e_service_task
i40e_reset_subtask
(rtnl_lock) i40e_do_reset
i40e_quiesce_vsi
vsi->netdev->netdev_ops->ndo_stop(vsi->netdev);
发现在 i40e_reset_subtask 确实持有了锁.
list mutex_waiter.list -s mutex_waiter.task -h 0xffff880f077d3dd0 > mutex_list-0xffff880f077d3dd0
因为在上面发现 i40e_reset_subtask 函数持有了 rtnl_lock (mutex锁),
所以看下这部分源码:
static void i40e_reset_subtask(struct i40e_pf *pf)
{
u32 reset_flags = 0;
rtnl_lock();
...
if (reset_flags &&
!test_bit(__I40E_DOWN, &pf->state) &&
!test_bit(__I40E_CONFIG_BUSY, &pf->state))
i40e_do_reset(pf, reset_flags);
unlock:
rtnl_unlock();
}
发现确实调用 i40e_do_reset 之后 schedule()切换走了。
void __rtnl_unlock(void)
{
mutex_unlock(&rtnl_mutex);
}
void rtnl_unlock(void)
{
/* This fellow will unlock it for us. */
netdev_run_todo();
}
至此已经知道有问题的代码就在 i40e_reset_subtask ()函数中,
于是就从内核仓库中看看,这个bug有没有人已经修复了:
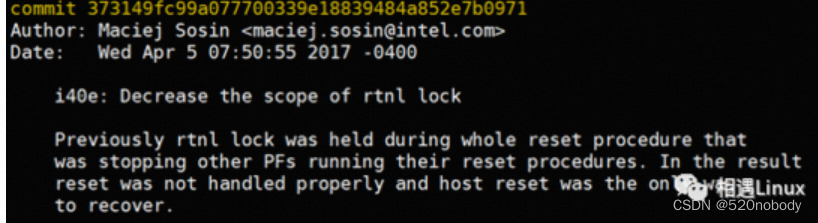
tig blame drivers/net/ethernet/intel/i40e/i40e_main.c
可以看到相关的commit ID 是373149f 或者dfc4ff6
分别看下:
git show 373149f
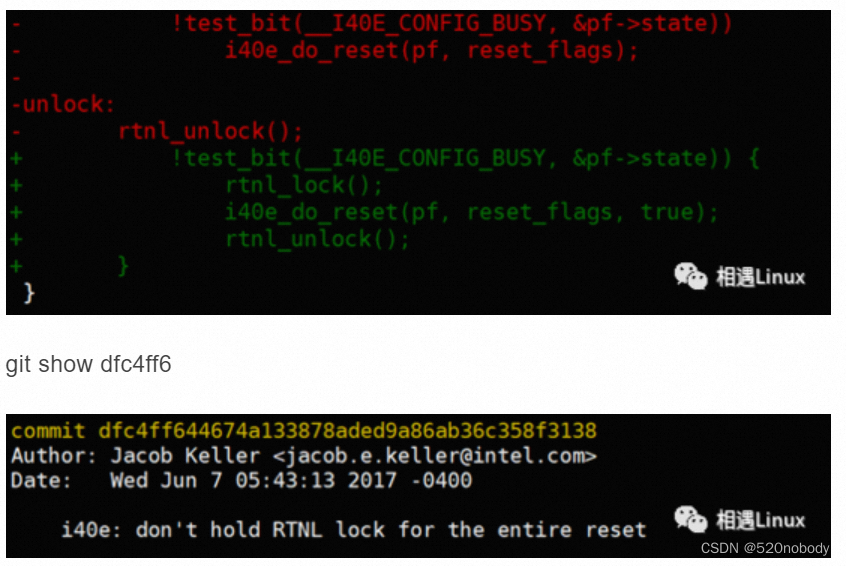
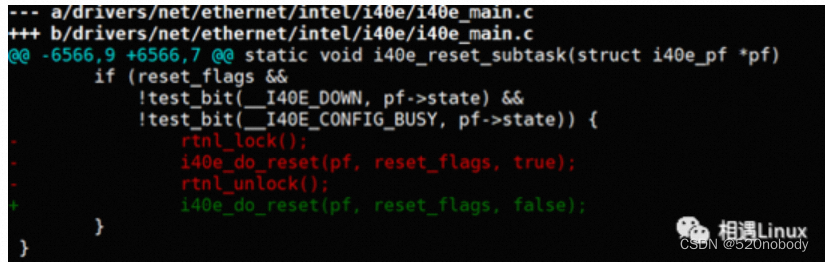
发现commit ID dfc4ff6已经修复了这个问题。
这样看起来分析完了,也解决了,但是有人会问,那些ps的进程与这个好像没有关系,现在看起来确实是,但是一定有个进程与ps堆栈中的sem锁有关,也与mutex锁有关,不过UN的进程实在太多,也没必要再分析了。
此公众号会分享更多实际解决案例。
如果有人对这个案例感兴趣,可以加我微信googuu,发30元红包(红包换知识),到时候我可以视频详细分享一下,一直有效.
以上所述就是小编给大家介绍的《crash工具分析大型Linux服务器死锁实战》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
本文来源:码农网
本文链接:https://www.codercto.com/a/106337.html














 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









