







以下链接是个人关于FSA-Net(头部姿态估算) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 文末附带 \color{blue}{文末附带} 文末附带 公众号 − \color{blue}{公众号 -} 公众号− 海量资源。 \color{blue}{ 海量资源}。 海量资源。
姿态估计1-00:FSA-Net(头部姿态估算)-目录-史上最新无死角讲解
大家通过前面的链接,应该都拿到论文了,那么下面就为大家翻译一下论文把。
Abstract(摘要)
我们提出了一种,只需要单张RGB图像,就能对头部姿态进行估算的方法。之前的一些方法,如基于深度图或者关键点进行估算的方法,需要比较多的计算量。我们的方法采用的是soft stagewise regression(后续有详细讲解—就是把回归问题,转化为一个分类问题来看待)。
现在一些特征聚合方法,会把输入特征当做一个整体来看大,这样会忽略一些在空间上的联系,我们提出了一种fine-grained structure mapping的方法,在聚合之前,对特征进行分组,特征空间上的联系。通过利用空间上的可学习特征,以及不可学习特征可以得到不同的模型,并且他们能够很好的互补。
实验表明…,叽里呱啦一堆吹逼的,总的来说,精度比较高,速度比较快,可以实时,只需要一张RGB图像就可以估算姿态,模型大小为5M左右。
1. Introduction(介绍)
面部建模一直是个比较受关注的计算机视觉问题,相关的大数据集以及不同面部分析算法,都被提出有好些年,比如人脸识别,人脸检测,年龄估算,头部姿态估计等,我们的方法是头部姿态估算,可以辅助人脸识别,表情识别,注意力检测等。
从单张RGB图片,进行头部姿态估算,是现在技术面临的一个挑战。头部姿态的估算主要包含了yaw(偏航角-左右偏转角度), pitch(俯仰角-上下偏转角度)以及 roll(翻滚角-不好解释,自行百度)。从一张图片进行姿态估算,需要去学习图片的3D以及2D的信息。一些模型使用多模态的方法,如使用深度图,或者使用时序信息(视频多帧图片)。使用深度图,其会丢失2D的信息,并且采集深度图,需要特定的摄像头,不能被很广泛的使用。使用时序图,由于其采用循环网络,计算的消耗量是十分巨大的。
还有一些单张RGB图片估算的方法,利用关键点进行头部姿态匹配,这样需要添加一个关键点检测的模型,也同样增大了模型的复杂度,受到内存资源的限制,不能被广泛的应用。
这篇论文提出的FSA-Net,从单张RGB图像就可进行姿态估算,其不需要人脸关键点的提供,直接对人脸的姿态进行回归,我们提出的这种方法使用的是 soft stagewise regression(把一个回归问题当做一个分类问题看待,进行递归计算—后续详细讲解)策略。
1.为了获得多个尺度的信息,也和平常的一些方法一样,对网络的多个层,进行特征图映射。
2.为了提高精准度,网络需要去学习对回归更具影响的特征。目前最先进的一些aggregation/pooling方法,如胶囊网络以及NetVLAD方法。他们能够蒸馏获得更加具有意义的特征。
我们这个方法的关键点在于,将特征图像素级特征进行分组,然后一起编码成一组带有空间信息的特征,读起来有点绕口是把,简单说,就是对特征图进行分组。编码之后获得的特征,当做aggregation(聚合)的材料,就是对那编码之后的特征进行提炼。
这种方法,是为找个像素特征比较细微(fine-grained)的映射,从而形成更具有以及的局部特征。
这种fine-grained structure mapping可以理解为比较灵活,比较全面的pooling操作。传统卷积的pooling操作,现在局部范围内,或者一个具有带变性的特征,如max pooling。这样的操作是一个预定义的操作,其不考虑到数据的信息以及影响。我们的方法更加灵活,能够获得更加全面的空间信息
我们采用了可学习和不可学习的重要性测量方法(后面有详细介绍),并且这两种方法可以互补,形成一个鲁棒性更加好的方法。
2. Related work
Landmark-based methods找到人脸的关键点,然后在进行姿态估算。
Methods with different modalities 多模态识别,如基于视频时序,或者深度图。
Multi-task methods多任务方法联合使用,如在进行性别识别的时候同时完成姿态识别。
这些方法,不仅计算量比较大,人工标注也会比较复杂。
Attention我们的方法,不要任何附加的技术,能够端到端的进行训练。相比于其他的注意力集中方法(如:CBAM ,Attentional Pooling),有以下的不同点。
1.其他的注意力集中方法针对的是分类问题,而我们针对的是回归问题。
2.他们的方法只能产生一个或者两个空间热图,而我们的可以生成多个空间attention,能够更加灵活的去提炼回归值。最后,我们的方法还考虑到了对尺度信息的问题。
3. Method
这个片段,主要讲述以下问题、
1.对头部姿态估计进行描述
2.介绍soft stagewise regression并且把他应用于头部姿态估算
3.FSA-Net中,比较重要的两个成分,即scoring function与fine-grained structure。
4.详细的对结构进行解释
3.1. Problem formulation
基于图片的头部姿态估算,我们给定一组训练的面部图像,表示为
{
x
n
∣
n
=
1
,
n
=
2
,
,
,
,
N
}
\{x_n|n=1,n=2,,,,N\}
{xn∣n=1,n=2,,,,N},其对应的姿态用向量
y
n
y_n
yn表示,这里的N表示的是图片的数目。每个姿态向量
y
n
y_n
yn都是一个3D向量,其分别表示 yaw, pitch, roll。目标是找个一个公式
F
F
F,如
y
~
=
F
(
x
)
\tilde{y}=F(x)
y~=F(x),表示的是图片
x
x
x经过网络预测的头部姿态是
y
~
\tilde{y}
y~,
y
y
y表示的真实姿态,也就是标签,我们使用平均绝对值误差的方法进行优化,如下:
J
(
X
)
=
1
N
=
∑
n
=
1
N
∣
∣
y
n
~
−
y
n
∣
∣
1
J(X)=\frac {1}{N}=\sum_{n=1}^N|| \tilde{y_n}-y_n||_1
J(X)=N1=n=1∑N∣∣yn~−yn∣∣1
3.2. SSR-Net-MD
我们的方案是简历在SSR-Net上面,他一种对单张图片进行年龄估算的方法,受到DEX的启发,SSR-Net把回归问题当做一个分类问题来处理,通过把年龄分成不同的几个阶段(bins),每个阶段都当做一个类别来看待。网络输出的概率,就是年龄分布的概率。然后计算他们的期望值,就是最后估算的年龄值。为了减少模型的参数,同时又提高模型的精准度,SSR-Net采用了一种coarse-to-fine strategy(由粗到细)的方法。
怎么为大家说比较好呢,举个例子吧。假设我们猜测脸年龄为0~99。
如果没有使用由粗到细的方法,就需要这个样子,我们把0~99分成3个阶段,那么阶段区间就是[0,33],[33,66],[66,99]。网络在预测的时候,预测每个类别的概率,然后计算期望值。可以明显的看到,这样的精确度太低了,为了提高精确度,我们可以分成多个阶段,如9个,则阶段区间就变成了[{0,11},{11,22},{22,33},{33,44}…{88,99},然后让网络估算每个阶段的概率,再计算期望值,可以看到精度明显提高了,但是模型的参数也明显增大了,因为原来3分类的问题,转化成了9分类,参数当然会增加。
那么采用由粗到细的方法是怎么样子呢?这里涉及到一个参数K,表示K折,他的意义是什么?K如果等于1,划分的和前面的一样,0~99分成3个阶段,那么阶段区间就是{0,33}, {33,66}, {66,99}。这里的K=1,也就是我们进行了1折,下面呢我们还要进行k=2,即对区间这么划分呢?{[0,11],[11,22],[22,33]}, {[33,44],[44,55],[55,66]}, {[33,44],[44,55],[55,66]}。这里大家要注意一下[]括号和{}括号。
进行对比可以发现,前面的九分类,是对整体进行9分类,后面的分类,是先对整体进行一个3分类,然后每个类在进行一个3分类,有什么好处?叫好像你去猜测一个人的年龄,可以一口气断定他为33到34岁之间,也可以这样去猜测,从他面貌来看大概在30-35,到底是三十几呢?在参考一下其他的信息,得到33到35。可以明显的感觉到,第一种方式没有第二种方式更加巧妙。那么在计算方面怎么对比呢? 注意哈,计算参数的时候是用加法,不是乘法,第二种方法进行了两个 3 分类 \color{red}{注意哈,计算参数的时候是用加法,不是乘法,第二种方法进行了两个3分类} 注意哈,计算参数的时候是用加法,不是乘法,第二种方法进行了两个3分类, 是 3 + 3 , 当然也可以是 2 × 3 。但是不能用 3 × 3 去计算 \color{red}{是3+3,当然也可以是2\times3。但是不能用3\times3去计算} 是3+3,当然也可以是2×3。但是不能用3×3去计算
上面的例子,是进行了K=2折,把{0,33},细分成了{[0,11],[11,22],[22,33]},当然还可以3折,把[0,11]或者[11,22]以及[22,33]继续细分下去,精确度会越来越高。还有一个变量要提到,那就是stage的数目,如进行第K=1折的时候,我们把他分成了3个区间,这里的3就是对应的stage数目。
明白了算法的思想,我们还是回过头来看公式,论文的计算期望值的公式如下:
y
~
=
∑
k
=
1
K
p
⃗
k
⋅
u
⃗
k
\tilde{y} = \sum_{k=1}^K \vec{p}^k·\vec{u}^k
y~=k=1∑Kpk⋅uk
这里K,表示就是K折的意思,
u
u
u表示相应阶年龄,或者角度的值(一般是中间值)。为了更好的去表示这个
u
u
u,又提出了
η
η
η(中心偏移量)以及
Δ
\Delta
Δ(对bins的宽度进行缩放),因此
u
u
u使用
η
η
η以及
Δ
\Delta
Δ进行代替,我们需要网络去学习预测这三个变量。也就是我们提供输入图片给网络,网络输出K个集合的参数
{
p
⃗
,
η
⃗
,
Δ
}
k
=
1
K
{\{\vec{p} ,\vec{η},\Delta \}}_{k=1}^K
{p,η,Δ}k=1K。大家看起来或许不是很明朗,看看这个博客:
论文阅读-年龄估计_SSRNet:https://blog.csdn.net/oukohou/article/details/102676855
如果还是不懂,也没有关系,等分析代码的时候,大家就明白了。这里和年龄估算不同的是,FSA-Net是对姿态进行估算,他有3个数值,是一个矢量,而非一个像年龄一样的标量。我们使用我们提出的feature aggregation,对SSR-Net进行了改进。
3.3. Overview of FSA-Net
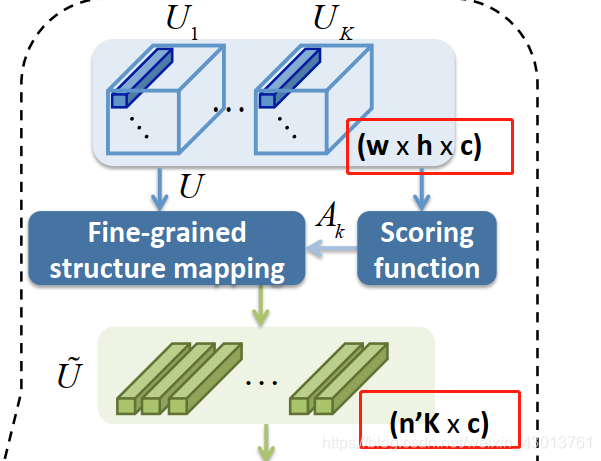
下图是对FSA-Net结构的描述,
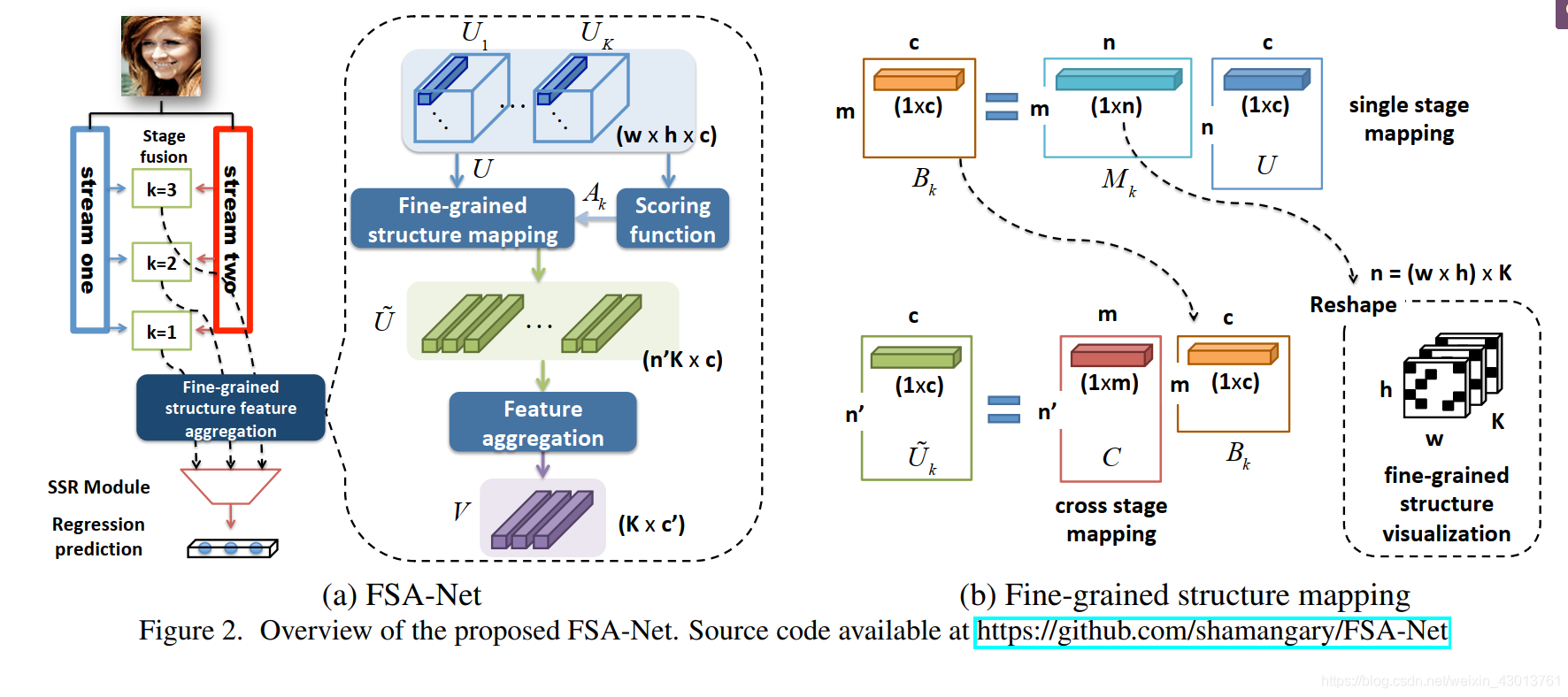
输入图片需要经过两个streams,可以看到我们的K=3,即表示进行了3折计算。每个stream分别会在K=3,和K=2,以及K=1处分别提出特征,然后进行融合。总的来说,下面这两个streams:
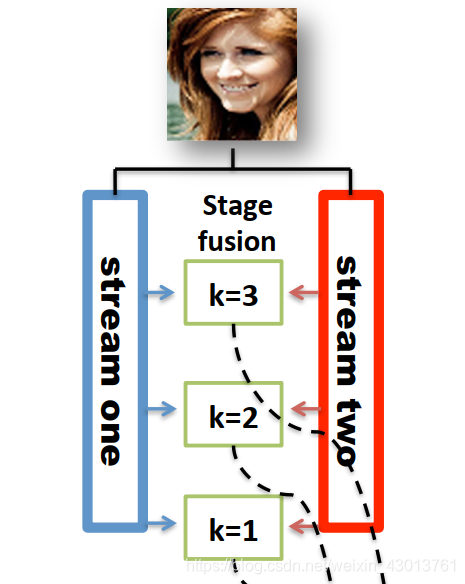
每个stream出来3个特征图,然后两两配对,通过1x1的卷积进行融合,输出C(源码默认为64)通道的特征图。然后进行池化操作。变成
w
×
h
×
c
w\times h\times c
w×h×c的特征图。在图中使用
U
k
U_k
Uk,分别表示每个K折处获得的特征图。
U
k
U_k
Uk可以看做是一个网格的特征图,每个网格都是c维度的空间向量,代表了一定的空间局部信息。然后把
U
k
U_k
Uk送入到映射模块中,最终产生k个c’维度的特征向量,这k个c’维度的特征向量的向量用于姿态的预测。也就是利用他们去获得
{
p
⃗
,
η
⃗
,
Δ
}
k
=
1
K
{\{\vec{p} ,\vec{η},\Delta \}}_{k=1}^K
{p,η,Δ}k=1K参数。
给出K个
w
×
h
×
c
w\times h\times c
w×h×c大小的特征图,aggregation 模型的的任务就是对他们进行提炼,也就是下图的这个过程:
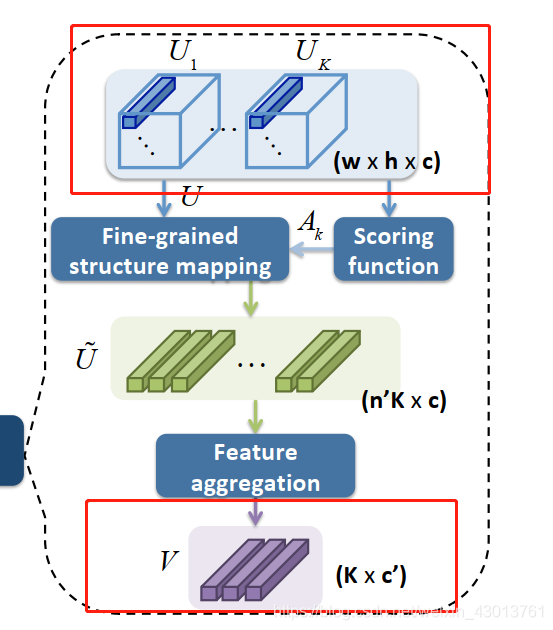
简单的说,就是从
U
k
U_k
Uk提取更加有用的信息,获得更加小的,K个维度为c’的特征向量。现在存在的的aggregation 聚合方法,主要有capsule和
NetVLAD两种,但是原本的这两种方法,都是直接从一个比较大的,整体的特征进行提炼,这样会忽略特征在空间上的一些信息。我们对其进行了改善,在进行特征提炼(aggregation)之前,我们对输入的特征进行了分组。
为了有效的特征图
U
k
U_k
Uk进行分组,我们采用了注意力机制,即后面介绍的 scoring function,其通过 scoring function先计算得到一个
A
k
A_k
Ak,下一步把
A
k
A_k
Ak和
U
k
U_k
Uk一起送入到fine-grained structure
mapping module。这个模型主要是,从通过权重加权的特征图中,抽取到n’个c维度的特征向量(即上图中的
U
~
\tilde U
U~)。然后再把这些向量喂食到feature aggregation(上图可以看到)模型中。最后获得V(K个c’维度的特征向量),我们利用这些特征向量去生成
{
p
⃗
,
η
⃗
,
Δ
}
k
=
1
K
{\{\vec{p} ,\vec{η},\Delta \}}_{k=1}^K
{p,η,Δ}k=1K集合,再通过SSR计算获得yaw, pitch,roll。
3.4. Scoring function
为了更好的获得分组特征如下:
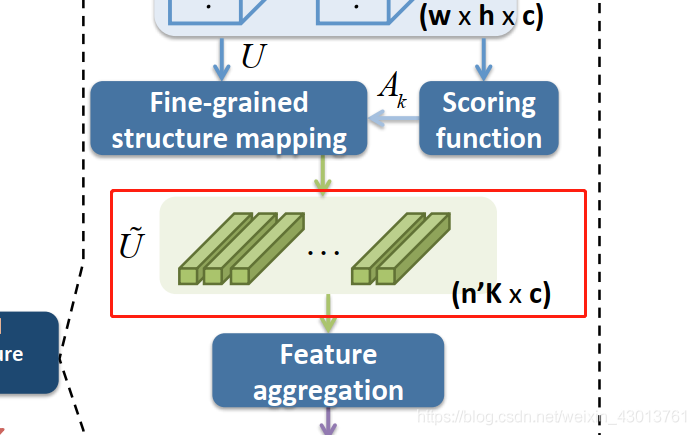
我们加入Scoring function注意力机制,对
w
×
h
×
c
w\times h\times c
w×h×c大小的特征图
U
k
U_k
Uk进行像素级别的重要性评分。给出像素集合
u
=
(
u
1
,
,
,
,
u
c
)
u=(u_1,,,,u_c)
u=(u1,,,,uc),设计一个
Φ
(
u
)
\Phi(u)
Φ(u)去测量每个像素的重要性,得到attention map
A
k
A_k
Ak,这里的
A
k
(
i
,
j
)
=
Φ
(
U
k
(
i
,
j
)
)
A_k^(i,j)=\Phi(U_k{(i,j)})
Ak(i,j)=Φ(Uk(i,j)),我们采用了3个方法去实现Scoring function,如下:
1.对每个大小为 w × h × c w\times h\times c w×h×c的 U k U_k Uk特征图,进行1x1的卷积,获得对应的attention map A k A_k Ak,公式为 Φ ( u ) \Phi(u) Φ(u) = σ ( w ⋅ u ) \sigma(w·u) σ(w⋅u) ,这里的 σ \sigma σ是sigmoid函数,W是需要通过数据学习到的权重。这种方法容易出现过拟合的现象。
2.采用方差的方法,其计算其重要性,公式为 Φ ( u ) \Phi(u) Φ(u) = ∑ i = 1 c ( u i − u ) 2 \sum_{i=1}^{c}(u_i-u)^2 ∑i=1c(ui−u)2 ,这里的 u u u= 1 c ∑ i = 1 c u i \frac{1}{c} \sum_{i=1}^{c} u_i c1∑i=1cui(就是对每个c维度的向量,求平局值)。注意这种方式是不需要学习的
3. Φ ( u ) \Phi(u) Φ(u)=1,相当于没有Scoring function功能。
其上的几种方法可以起到互补的作用,融合使用可以增加模型的鲁棒性。
3.5. Fine-grained structure mapping
通过前面的步骤,我们获得 U k U_k Uk以及 A k A_k Ak之后,下个步骤就是把它送入到fine-grained structure mapping,去提取 U ~ \tilde U U~。首先我们把特征图 u k u_k uk扁平成一个第一维度为n= w × h × K w\times h\times K w×h×K的矩阵,即 U ∈ R n × c U\in \mathbb{R}^{n\times c} U∈Rn×c。换句话说, U U U是一个2维的矩阵,包含了所有K则中,每个像素级别,c维度的特征向量。
现在我们要找到一个映射参数S_k,作用是什么呢?我们先来看看下图:
这映射关系,要满足
U
U
U到
U
~
\tilde U
U~的转换,即把矩阵
U
U
U[n=w x h x k, c]转化为
U
~
\tilde U
U~[n’K,c],集合
S
k
S_k
Sk书写如下:
U
~
=
S
k
U
\tilde U = S_kU
U~=SkU
可以很明显的知道,
S
k
∈
R
n
′
×
n
S_k\in\mathbb{R}^{n'\times n}
Sk∈Rn′×n,也就是说n’个有代表性的特征向量,是由n个像素级别的特征向量,通过线性转换关系得来的。这个转过的过程中,会进行维度缩减。我们还可以把
S
k
S_k
Sk分解成两个矩阵参数去学习:
S
k
=
C
M
k
S_k=CM_k
Sk=CMk
这里的
C
∈
R
n
′
×
m
C\in\mathbb{R}^{n'\times m}
C∈Rn′×m,
M
k
∈
R
m
′
×
n
M_k\in\mathbb{R}^{m'\times n}
Mk∈Rm′×n,其上的公式中,
C
C
C参数对于所有K折处的特征都是共享的,但是对于
M
k
M_k
Mk并非是共享的,也就是对于每个折处的特征向量,都有对应的一个
M
k
M_k
Mk,这里不太好讲解,我们在源码中去寻找答案。
C
C
C,
M
k
M_k
Mk计算公式如下:
M
k
=
σ
(
f
M
(
A
k
)
)
M_k = \sigma(f_M(A_k))
Mk=σ(fM(Ak))
C
=
σ
(
f
c
(
A
)
)
C= \sigma(f_c(A))
C=σ(fc(A))
其上的表示sigmoid函数,
f
M
f_M
fM和
f
c
f_c
fc都表示全连接层,
A
=
[
A
1
,
A
2
,
.
.
.
.
.
A
k
]
A=[A_1,A_2,.....A_k]
A=[A1,A2,.....Ak],是所有的attention maps链接起来。从这里我们可以知道
M
k
M_k
Mk和
C
C
C是和
A
k
A_k
Ak息息相关的,这样就把注意力集中机制利用了起来。把
S
k
S_k
Sk分解成
f
M
f_M
fM和
f
c
f_c
fc,不仅减少了参数,还使训练更加的稳定,更进一步,我们还对
S
k
S_k
Sk的每一行进行了
L
1
L_1
L1正则化。
M k ∈ R m ′ × n M_k\in\mathbb{R}^{m'\times n} Mk∈Rm′×n,其中 n = w × h × c n=w\times h\times c n=w×h×c,可以知道每个 M k M_k Mk都可以折叠成 w × h w\times h w×h的特征图。因此个 M k M_k Mk的每一行,都可以看做装载了比较细微的空间信息,这是他能够很好作为姿态估计的一个重点。
最后我们链接来自 U k U_k Uk的所有特征 U ~ 1 , U ~ 2 . . . . . . U ~ 3 \tilde U_1,\tilde U_2......\tilde U_3 U~1,U~2......U~3形成 U ~ ∈ R ( K ⋅ n ′ ) × c \tilde U \in\mathbb{R}^{(K·n')\times c} U~∈R(K⋅n′)×c。然后把 U ~ \tilde U U~送入到 aggregation 模型,得到 V ∈ R K × c ’ V\in\mathbb{R}^{K\times c’} V∈RK×c’。在进行SSR计算,即for stage-wise regression得到估算的姿态。
好了,今天我感觉累了,翻译也不是一个轻松的事情哈,主要指公司和数学符号难打,很多不知道,还要百度查。我们下篇再见啊,我会把剩下的都翻译完!

















 4178
4178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











