







1.说说有哪些常见的集合?
集合相关类和接口都在java.util中,主要分为3种:List(列表),Map(映射),Set(集)
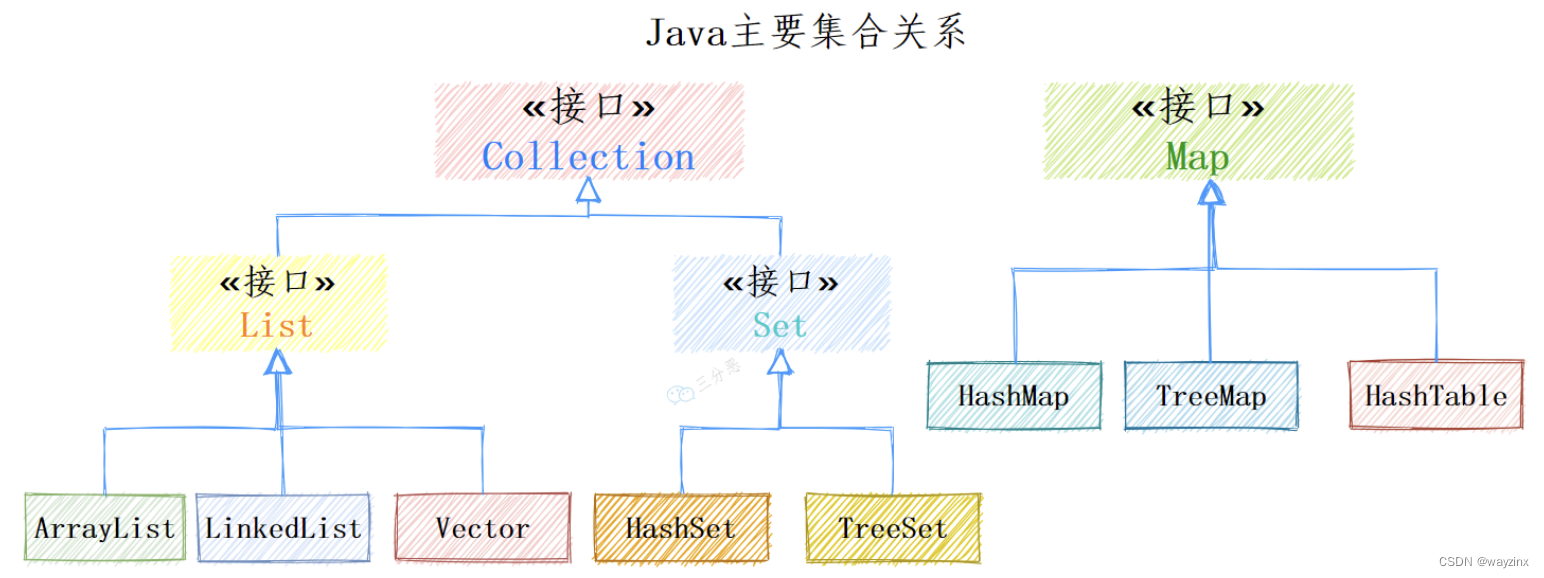
其中Collection是集合List、Set的父接口,它主要有两个子接口:
List:存储的元素有序,可重复。Set:存储的元素不无序,不可重复。
Map是另外的接口,是键值对映射结构的集合。
List
ArrayList 和 LinkedList 有什么区别?
- ArrayList 基于数组实现
- LinkedList 基于双向链表实现
(2) 多数情况下,ArrayList 更利于查找,LinkedList 更利于增删
-
ArrayList 基于数组实现,get(int index)可以直接通过数组下标获取,时间复杂度是 O(1);LinkedList 基于链表实现,get(int index)需要遍历链表,时间复杂度是 O(n);当然,get(E element)这种查找,两种集合都需要遍历,时间复杂度都是 O(n)。
-
ArrayList 增删如果是数组末尾的位置,直接插入或者删除就可以了,但是如果插入中间的位置,就需要把插入位置后的元素都向前或者向后移动,甚至还有可能触发扩容;双向链表的插入和删除只需要改变前驱节点、后继节点和插入节点的指向就行了,不需要移动元素。
ArrayList 的扩容机制了解吗?
ArrayList 是基于数组的集合,数组的容量是在定义的时候确定的,如果数组满了,再插入,就会数组溢出。所以在插入时候,会先检查是否需要扩容,如果当前容量+1 超过数组长度,就会进行扩容。
ArrayList 的扩容是创建一个1.5 倍的新数组,然后把原数组的值拷贝过去。
Map
能说一下 HashMap 的数据结构吗?
JDK1.7 的数据结构是数组+链表
JDK1.8 的数据结构是数组+链表+红黑树。
数据结构示意图如下:
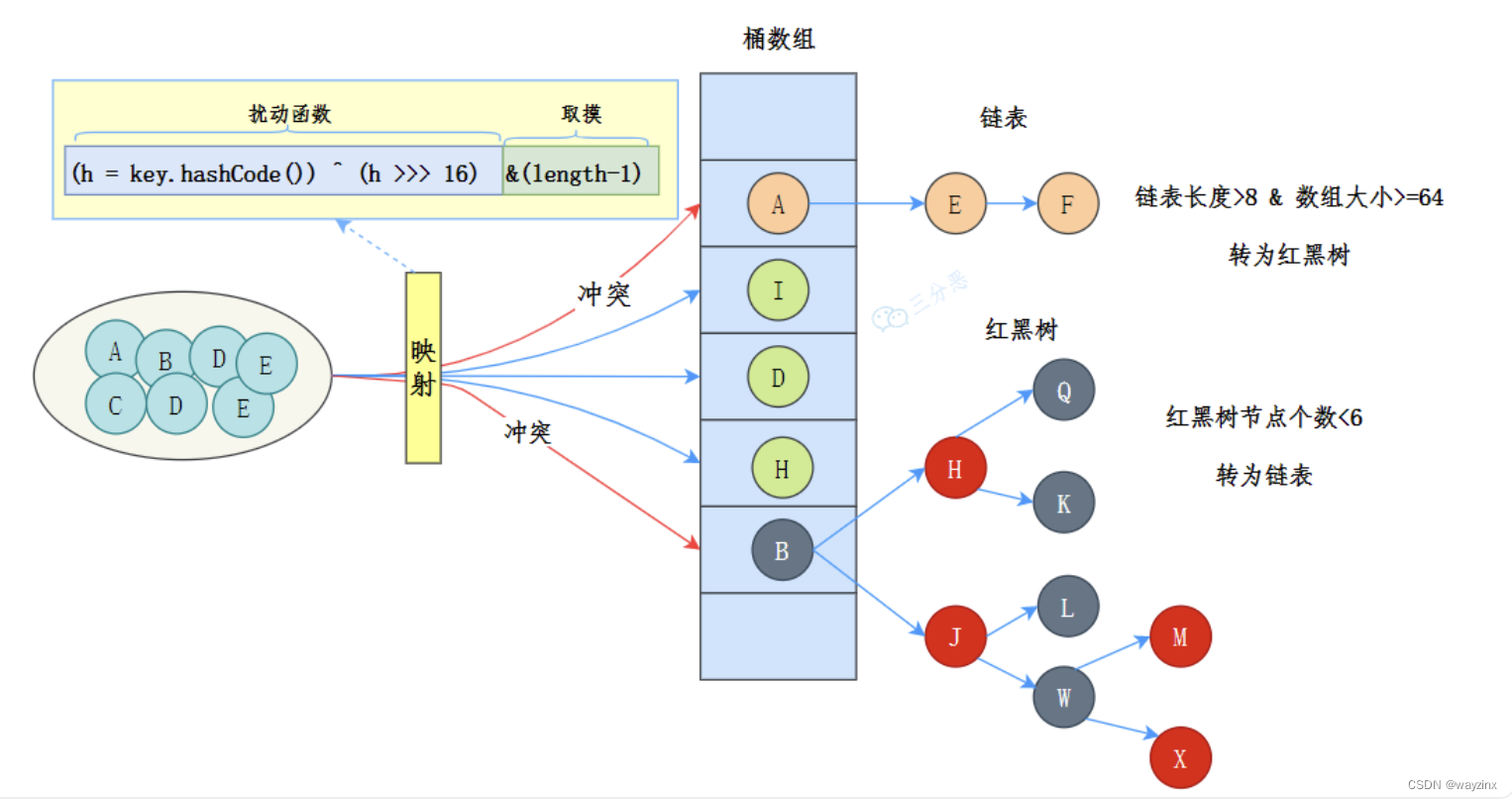
其中,桶数组是用来存储数据元素,链表是用来解决冲突,红黑树是为了提高查询的效率。
- 数据元素通过映射关系,也就是散列函数,映射到桶数组对应索引的位置
- 如果发生冲突,从冲突的位置拉一个链表,插入冲突的元素
- 如果链表长度>8&数组大小>=64,链表转为红黑树
- 如果红黑树节点个数<6 ,转为链表
你对红黑树了解多少?为什么不用二叉树/平衡树呢?
红黑树本质上是一种二叉查找树,为了保持平衡,它又在二叉查找树的基础上增加了一些规则:
- 每个节点要么是红色,要么是黑色;
- 根节点永远是黑色的;
- 所有的叶子节点都是是黑色的(注意这里说叶子节点其实是图中的 NULL 节点);
- 每个红色节点的两个子节点一定都是黑色;
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
之所以不用二叉树:
红黑树是一种平衡的二叉树,插入、删除、查找的最坏时间复杂度都为 O(logn),避免了二叉树最坏情况下的 O(n)时间复杂度。
之所以不用平衡二叉树:
平衡二叉树是比红黑树更严格的平衡树,为了保持保持平衡,需要旋转的次数更多,也就是说平衡二叉树保持平衡的效率更低,所以平衡二叉树插入和删除的效率比红黑树要低。
红黑树怎么保持平衡的知道吗?
红黑树有两种方式保持平衡:旋转和染色。
HashMap 的 put 流程知道吗?
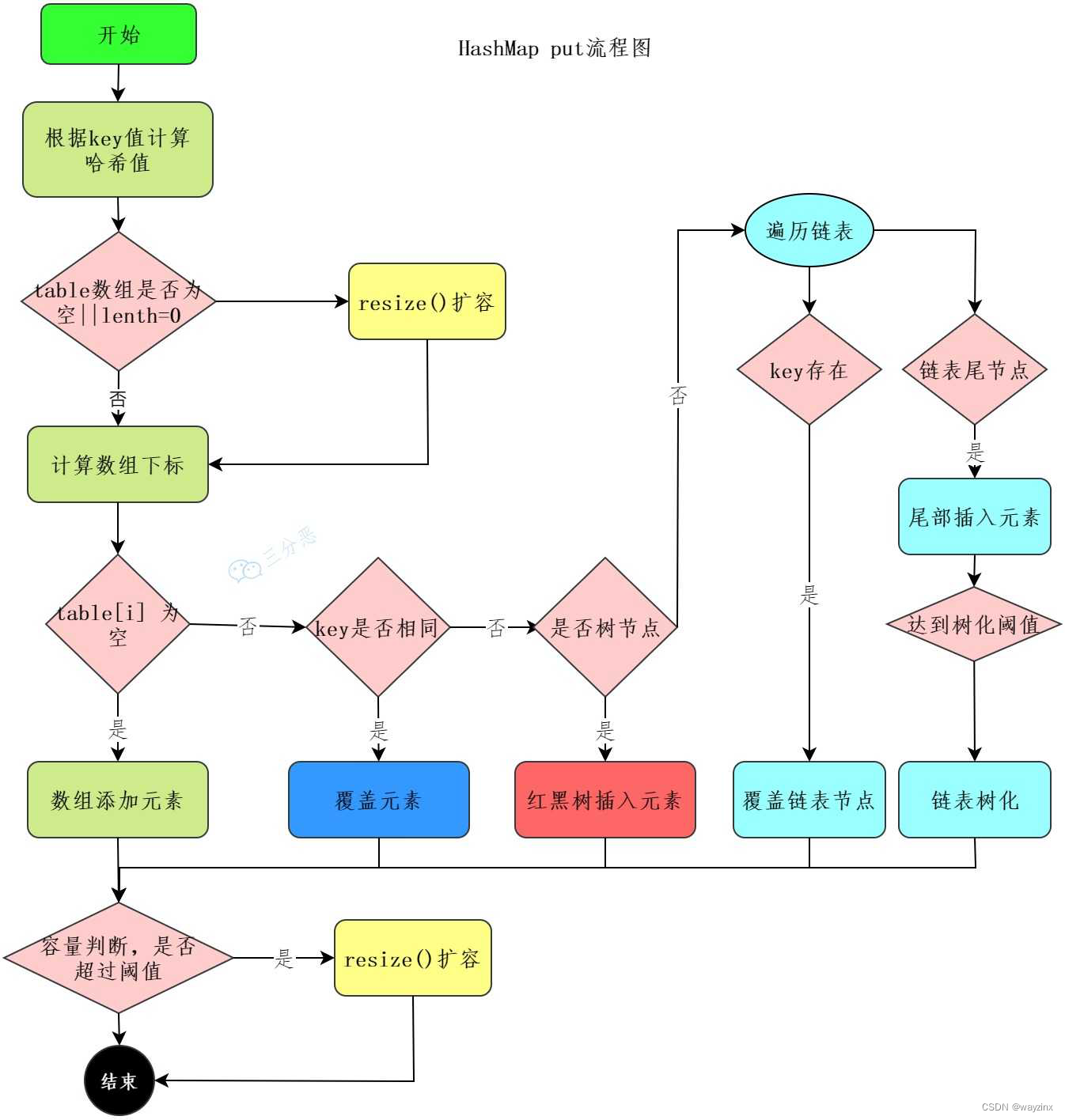
1.首先进行哈希值的扰动,获取一个新的哈希值。(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
2.判断 tab 是否位空或者长度为 0,如果是则进行扩容操作。
3.根据哈希值计算下标,如果对应小标正好没有存放数据,则直接插入即可否则需要覆盖。tab[i = (n - 1) & hash])
4.判断 tab[i]是否为树节点,否则向链表中插入数据,是则向树中插入节点。
5.如果链表中插入节点的时候,链表长度大于等于 8,则需要把链表转换为红黑树。treeifyBin(tab, hash);
6.最后所有元素处理完成后,判断是否超过阈值;threshold,超过则扩容。
HashMap 怎么查找元素的呢?
- 使用扰动函数,获取新的哈希值
- 计算数组下标,获取节点
- 当前节点和 key 匹配,直接返回
- 否则,当前节点是否为树节点,查找红黑树
- 否则,遍历链表查找















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









