







Bert在文本多分类任务中的使用(干货)
写在前面: 自2018年来,Bert在多个NLP领域都取得了颠覆性的成绩,诸如词性标注、问答系统等等。它本身采用的依然是Transform的机制,但是对于文本它是双向编码表示,,也就是Bert的全称: Bidirectional Encoder Representations from Transformers。现在对于Bert的使用和衍生变种很多很多,比如 Bert as service(可部署到服务器上,方便快捷版的Bert)、 Bert-NER(用来做实体识别)、 Bert-utils(句向量的引入)等等。实际上,针对很多人来说,我们仅仅是使用者、而不需要发费过多的时间在这上面去研究原理, 实用至上。
本文介绍的是文本的多分类问题,旨在为大家提供一种快速上手复杂神经模型的思路,其他可以类比。
一、从无到有第一步
假设现在你需要解决一个文本的多分类问题,如新闻文章划分(军事?体育?财经?)或者网上政务留言文本分类后交给各个部门(环境保护部门?民政部门?工商管理部门?),列举这些例子就是为了说明文本分类在很多领域都很重要,我们常说:“聚类、分类、关联能解决99%的数据挖掘问题”,灵活转化问题才是最重要的。扯远了哈,你已经明确你有一个文本多分类的问题,第一步就是收集分类的手段,而不要考虑文本,这样做的好处一会再说。把问题拆解开来,分类手段有啥?(百度即可),哦!决策树、朴素贝叶斯、SVM、高级点的LightGBM、神经网络等都可以,把它们记录下来,熟悉它们的使用方法(输入输出很重要),适应的范围和优缺点,原理的话,学有余力你可以学习。最快的方法是找代码直接看直接调通。
加入文本二字,你自然就会想到,文本是字符,上述这些方法的输入都是数值(向量)。好了,恭喜你,你已经在走那些大神走过的路了。文本编码有啥方法呀?问问度娘(或者来CSDN也可~ _~),词袋模型,one-hot模型,TF-IDF方法,word2vec(2 = to,英文中的通假字了解一下)等等,映入眼帘,当然,你肯定还会看到Bert的身影,别着急,一步一步来。同样的方法,你把每种方法的实现、优缺点等搞懂,你就知道适合你的任务的编码方式是啥了。
总结一下,第一步你需要做的就是不停的查、不停的下载代码、调代码。很简单对吧,但是并非如此哦,你可能一步一步陷入某个理论中不能自拔,查完这个发现不懂就去查另一个,套娃既视感,做正确的选择很重要。
二、搭配起来作比较
很神奇吧,你现在知道文本的编码有那么多、分类的方法有那么多,即便筛选掉那些你觉得肯定对你任务不合适的方法,这样排列组合的形式还是有很多。那么对任务上下游方法进行搭配就很重要了。谁也不会知道那个效果好,那就多搭配搭配试一试,比较各个模型组合起来的效果。对于分类问题比较好的衡量标准就是F-Score和准确率,一般来说准确率用的可能要多一些。但是在竞赛中F-Score是更为常见的。
这里可以回答为啥我们要把问题分开考虑了,因为想要你的模型比别人效果好,必须要有创新,而直接关联的去查找文本多分类的资料,你得到的只能是别人用过的。你可能会说,你只追求效果好,那也行,但是如果你要写论文的化,你就知道这个有多重要了。
针对那些需要写论文等文字资料的童鞋,推荐一下几个绘制图标的好工具:
- processon:在线绘制流程图,在每一章的开头给一幅“本章架构图”,很加分;
- echarts:不想循规蹈矩的用excel绘制统计图表,echarts这款很适合你,简单JavaScript语法很容易上手,而且官网上给出了许多实例,改改数据就能用。
三、言归正传扯代码
前面说的都是铺垫,在很多你不熟悉的领域都是很好的思路,技术更新那么快,快速上手你需要技巧的~
下面我就来介绍我在某一次文本分类任务中的使用的bert-util+传统分类模型,并且我也会在接下来介绍一些Bert原生分类器的原理和方法。
1.Bert-util详解
这里插几句,说下我为啥选择Bert-util。在最开始我使用的也是Bert-master(就是谷歌给的那一款),天啊!我发现Bert只能截断指定长度的文本,比如一个文本1000个汉字,受限于max_position_embeddings
注意这个是直接截断的!直接截断的!万一信息量文档后面集中分布,那该咋办,(╯▽╰),我也不知道。我在网上找到这个Bert-util,标题说的是“一行代码生成句向量”,但是实际使用的过程中发现还是不行,这个弊端并没有被作者修正。我不知道用“ 弊端”这个词对不对,因为它本身可能并不适合文档级别的文本
那我为啥还选择Bert-util呢?
很显然的是,Bert-util能够很好完成输入一个文本序列给出一个向量。你会问Bert-master不行吗?也可以,但是他是通过【CLS】实现的,说白了他是给每一个字一个向量,但是【CLS】作为一个特殊字符,本身不具有语义的特征,通过Bert内在机制,【CLS】对应的向量本身是可以作为这个序列特征的文本表示。你可以理解为Bert将序列的全部信息给了【CLS】,万千宠爱集于一身,O(∩_∩)O~
选择了Bert-util是一种偶然,为了解决Bert的弊端却没有解决,但是Bert-util代码很容易理解,易于与下面的传统分类方法结合。
下面怼代码了,做好准备:
A:下载Bert-util代码(上面给了链接),下载Bert的中文模型(谷歌给咱跑的不用白不用,高性能机器上也要一周):https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
添加到Bert-util的目录中。(下图展示了位置,请自行忽略我自己产生的垃圾数据)
切记不要修改中文模型的任何文件,包括文件名。
B:把中文模型的文件路径添加进去,在args.py文件中。

C:新建一个run.py文件,写入以下内容:
from bert.extrac_feature import BertVector
bv = BertVector()
print(bv.encode(['我爱你中国!']))
注意输入格式是列表,尤其是在你批量传入的时候。
D:批量的时候要保存向量以便于后续的下游的传统分类任务,在extract_feature.py中修改如下:
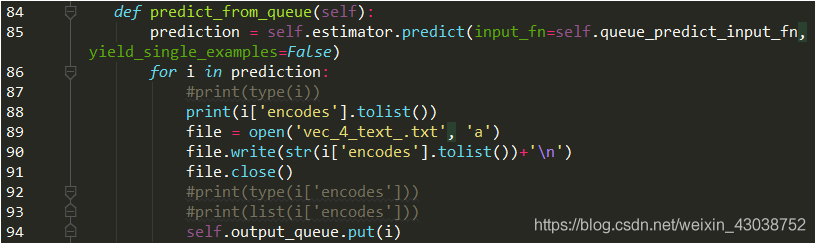
这里我是保存到一个txt里,其实就是要遍历prediction,你想咋保存就咋保存吧。
E:这里你就可以跑你新建的run.py了,注意第一次运行时会新建一个tmp/result/graph文本,它保存了模型的一些参数等信息。注意如果你不调整参数的话,第二次就可以直接使用这个了。但是,一旦调整了参数就必须把tem文件夹直接删除,或者重命名也可以。
F:调参是一个很玄学的事情。bert-util的调参在args.py和modeling.py中,每个参数的具体含义都是很显而易见的。这个模型运行代价不是很大,一般的笔记本就能跑,调参就自己试一试吧,一般batch_size设为32比较好,学习率尽可能低,一般到十万分位。温馨提示,调参时注意记录,无论是写论文还是指导下一步调参都很重要。
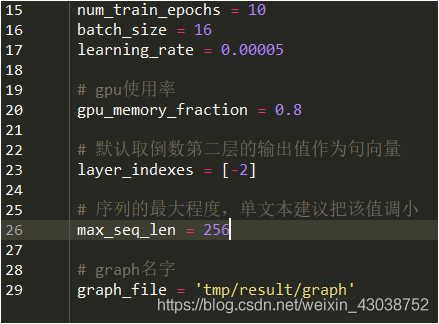
(args.py)

(modeling.py)
2.下游的传统分类手段
(1)基于概率模型的朴素贝叶斯分类器:朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器。优点在于数据集较小的情况下的仍旧可以处理多类别问题使用于标称数据。面对Bert生成的序列向量,朴素贝叶斯并没有很好的处理能力,主要原因是:其一,Bert生成向量的各维度是连续属性;其二,Bert生成向量各个维度并不是完全独立的。因此这种分类方法在原理上来讲不会具有很好的分类效果;
(2)基于网络结构的SVM分类方法:支持向量机的思想来源于感知机,是一种简单的浅层神经网络。但SVM较一般的神经网络具有更好的解释性和更完美的数学理论支撑。SVM的目的在于寻求划分各类的超平面。当然,支持向量机可实现非线性分类,利用核函数将数据抽象到更高维的空间,进而将非线性问题转换为线性问题;
(3)基于树模型的LightGBM分类器:LightGBM是对一般决策树模型和梯度提升决策树模型XGBoost的一种改进。内部使用Histogram的决策树算法和带有深度限制的Leaf-wise的叶子生长策略,主要优势在于更快的训练效率、低内存占用以及适用大规模并行化数据处理。(来自我的某篇小论文)
代码实现我都不好意思说,为啥呢?因为Sklearn里封装的太棒了,当然LightGBM要单独安装使用。
分享以下Sklearn的中文文档,你想做的它都有:https://www.cntofu.com/book/170/index.html
传统分类器也有调参的过程,祝君好运!O(∩_∩)O
3.Bert原生的分类器
bert本身就具有很好的分类器,也就是基于【CLS】进行分类,“CLS”本身就是classify的缩写。如何使用一查一大堆。不再赘述了。一般来说,Bert原生的分类器分类的准确性比较高,其实他就是在网络后通过Fine-Tuning机制添加少量的神经网络层,一般都有softmax层,这个大家可以了解一下。
好了,这篇扯得有点多,也有点乱,不过大家按照这个来,你完全可以完成一个文本的(多)分类任务,并且你可以按照这个思路完成任何你不熟悉的领域。
关于我的代码就不给了,需要私我,我常在哦!有问题也可以留言评论,欢迎交流,一起进步!
————————END——————————














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









