







一、File文件类
1.1、常用方法
1、路径问题
- 绝对路径:该文件在硬盘上的完整路径。绝对路径一般都是以盘符开头的。
- 相对路径:相对路径就是资源文件相对于当前程序所在的路径。
- “.”:当前路径
- “…”:上一级路径
2、创建
- createNewFile():在指定位置创建一个空文件,成功就返回true,如果已存在就不创建,然后返回false。
- mkdir(): 在指定位置创建一个单级文件夹。
- mkdirs(): 在指定位置创建一个多级文件夹。
- renameTo(File dest):如果目标文件与源文件是在同一个路径下,那么renameTo的作用是重命名, 如果目标文件与源文件不是在同一个路径下,那么renameTo的作用就是剪切,而且还不能操作文件夹。
3、删除
- delete(): 删除文件或者一个空文件夹,不能删除非空文件夹,马上删除文件,返回一个布尔值。
- deleteOnExit():jvm退出时删除文件或者文件夹,用于删除临时文件,无返回值。
4、判断
- exists() :文件或文件夹是否存在。
- isFile() :是否是一个文件,如果不存在,则始终为false。
- isDirectory(): 是否是一个目录,如果不存在,则始终为false。
- isHidden() :是否是一个隐藏的文件或是否是隐藏的目录。
- isAbsolute() :测试此抽象路径名是否为绝对路径名。
5、获取
- getName(): 获取文件或文件夹的名称,不包含上级路径。
- getAbsolutePath():获取文件的绝对路径,与文件是否存在没关系
- length() :获取文件的大小(字节数),如果文件不存在则返回0L,如果是文件夹也返回0L。
- getParent(): 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回null。
- lastModified() : 获取最后一次被修改的时间。
6、文件夹相关操作
- static File[] listRoots():列出所有的根目录(Window中就是所有系统的盘符)
- list() :返回目录下的文件或者目录名,包含隐藏文件。对于文件这样操作会返回null。
- listFiles() :返回目录下的文件或者目录对象(File类实例),包含隐藏文件。对于文件这样操作会返回null。
- list(FilenameFilter filter) :返回指定当前目录中符合过滤条件的子文件或子目录。对于文件这样操作会返回null。
- listFiles(FilenameFilter filter) :返回指定当前目录中符合过滤条件的子文件或子目录。对于文件这样操作会返回null。
1.2、实战应用
二、字节流
1.1、InputStream字节输入流
1、什么是InputStream
- 定义:InputStream就是Java标准库提供的最基本的输入流,InputStream并不是一个接口,而是一个抽象类,它是所有输入流的超类。这个抽象类定义的一个最重要的方法就是int read()
2、InputStream常用子类
- FileInputStream:从文件流中读取数据
- ByteArrayInputStream:实际上是把一个byte[]数组在内存中变成一个InputStream,虽然实际应用不多
- StringBufferInputStream:把一个String对象变成一个inputstream
- ObjectInputStream:把一个Object对象变成一个inputstream,
3、常用方法
- int read():一个字节一个字节的读取
- int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数
- int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数
- close():关闭流
1.2、OutputStream字节输出流
1、常用子类
2、常用方法
- write(int b):一次性写一个字节到输出流
- write(byte[]):一次性将一个字节数组的字节写到输出流
- close():关闭流
- flush():强制把缓冲区内容输出;而不是等缓存区的数据满了才输出
- 什么情况下会使用到flush():举个栗子;小明正在开发一款在线聊天软件,当用户输入一句话后,就通过OutputStream的write()方法写入网络流。小明测试的时候发现,发送方输入后,接收方根本收不到任何信息,怎么肥四?原因就在于写入网络流是先写入内存缓冲区,等缓冲区满了才会一次性发送到网络。如果缓冲区大小是4K,则发送方要敲几千个字符后,操作系统才会把缓冲区的内容发送出去,这个时候,接收方会一次性收到大量消息。
解决办法就是每输入一句话后,立刻调用flush(),不管当前缓冲区是否已满,强迫操作系统把缓冲区的内容立刻发送出去。
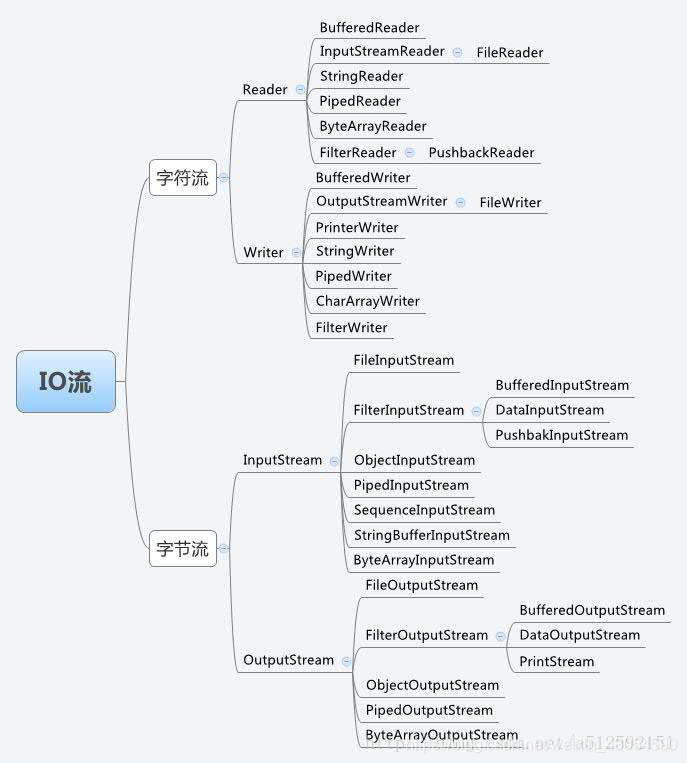
三、字符流
3.1、reader字符输入流
1、inputstream和reader对比

2、常用子类
- 见前面的IO流思维导图
3、常用方法
- int read():读入单个字符
- read(char[] cbuf, int off, int len):将字符读入数组的某一部分
- readLine(): 读取一个文本行。
- close():关闭流
4、FileWriter解决字符编码问题
- 问题:FileReader默认的编码与系统相关,例如,Windows系统的默认编码可能是GBK,打开一个UTF-8编码的文本文件就会出现乱码
- 解决方案:Reader reader = new FileReader(“src/readme.txt”, StandardCharsets.UTF_8);
3.2、writer字符输出流
1、outputstream和writer区别

2、常用方法
- write(int c):写入一个字符(0~65535)
- write(char[] c):写入字符数组的所有字符
- write(String s):写入String表示的所有字符
- close():关闭流
3.3、InputstreamReader和OutputstreamWriter
1、InputstreamReader
-
作用:除了特殊的CharArrayReader和StringReader,普通的Reader实际上是基于InputStream构造的,因为Reader需要从InputStream中读入字节流(byte),然后,根据编码设置,再转换为char就可以实现字符流。如果我们查看FileReader的源码,它在内部实际上持有一个FileInputStream。既然Reader本质上是一个基于InputStream的byte到char的转换器,那么,如果我们已经有一个InputStream,想把它转换为Reader,是完全可行的。InputStreamReader就是这样一个转换器,它可以把任何InputStream转换为Reader
-
使用:
// 持有InputStream: InputStream input = new FileInputStream("src/readme.txt"); // 变换为Reader: Reader reader = new InputStreamReader(input, "UTF-8");
2、OutputstreamWriter
-
作用:除了CharArrayWriter和StringWriter外,普通的Writer实际上是基于OutputStream构造的,它接收char,然后在内部自动转换成一个或多个byte,并写入OutputStream。因此,OutputStreamWriter就是一个将任意的OutputStream转换为Writer的转换器
-
使用:
Writer writer = new OutputStreamWriter(new FileOutputStream("readme.txt"), "UTF-8")
3.4、使用字节流和字符流实现文件的复制粘贴
import java.io.*;
/**
* 使用io流进行文件的复制粘贴
*/
public class FileCopy {
public static void main(String[] args) throws IOException {
copyAndPastByByte("./doc/index.txt","./doc/index1.txt");
copyAndPastByChar("./doc/index.txt","./doc/index2.txt");
}
/**
* 字节流实现赋值粘贴
*/
public static void copyAndPastByByte(String path,String targetPath) throws IOException {
File file = new File(path);
System.out.println(file.getCanonicalPath());
File targetFile = new File(targetPath);
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(file);
fos = new FileOutputStream(targetFile);
byte[] bytes = new byte[256];
int len = 0;
while ((len = fis.read(bytes)) != -1){
fos.write(bytes);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
fis.close();
fos.close();
}
}
/**
* 通过字符流实现文件的赋值粘贴
* @param path
*/
public static void copyAndPastByChar(String path,String targetPath) throws IOException {
File file = new File(path);
File targetFile = new File(targetPath);
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(file);
fw = new FileWriter(targetFile);
char[] c = new char[1024];
int len = 0;
while ( (len = fr.read(c)) != -1){
fw.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
fr.close();
fw.close();
}
}
}
四、filter模式
4.1、为什么在字节流和字符流中使用filter模式
1、如果我们要给FileInputStream添加缓冲功能,则可以从FileInputStream派生一个类
BufferedFileInputStream extends FileInputStream
2、如果要给FileInputStream添加计算签名的功能,类似的,也可以从FileInputStream派生一个类
DigestFileInputStream extends FileInputStream
3、如果要给FileInputStream添加加密/解密功能,还是可以从FileInputStream派生一个类
CipherFileInputStream extends FileInputStream
4、给FileInputStream添加3种功能,至少需要3个子类。这3种功能的组合,又需要更多的子类
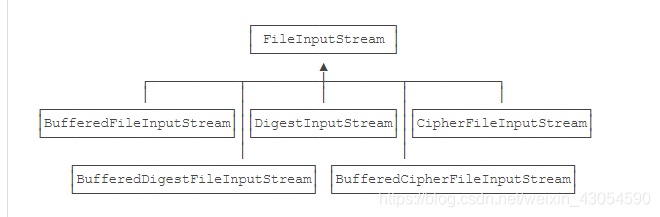
- 结论:这还只是针对FileInputStream设计,如果针对另一种InputStream设计,很快会出现子类爆炸的情况。因此,直接使用继承,为各种InputStream附加更多的功能,根本无法控制代码的复杂度,很快就会失控
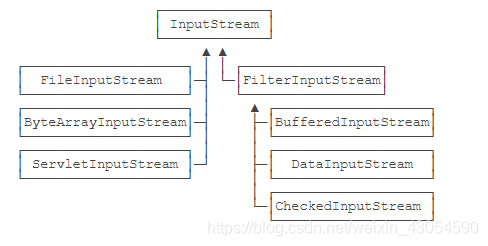
4.2、为了解决依赖继承会导致子类数量失控的问题,JDK首先将InputStream分为两大类
1、一类是直接提供数据的基础InputStream,举例:
- FileInputStream
- ByteArrayInputStream
- ServletInputStream
2、一类是提供额外附加功能的InputStream,举例:
- BufferedInputStream
- DigestInputStream
- CipherInputStream
4.3、使用filter模式
1、当我们需要给一个“基础”InputStream附加各种功能时,我们先确定这个能提供数据源的InputStream,因为我们需要的数据总得来自某个地方,例如,FileInputStream,数据来源自文件:
InputStream file = new FileInputStream("test.gz");
2、紧接着,我们希望FileInputStream能提供缓冲的功能来提高读取的效率,因此我们用BufferedInputStream包装这个InputStream,得到的包装类型是BufferedInputStream,但它仍然被视为一个InputStream
InputStream buffered = new BufferedInputStream(file);
3、最后,假设该文件已经用gzip压缩了,我们希望直接读取解压缩的内容,就可以再包装一个GZIPInputStream
InputStream gzip = new GZIPInputStream(buffered);
4、无论我们包装多少次,得到的对象始终是InputStream,我们直接用InputStream来引用它,就可以正常读取;上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)
五、对象的序列化与反序列化
5.1、序列化
1、定义
- 定义:序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
- 原因:因为序列化后可以把byte[]保存到文件中,或者把byte[]通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了
2、使用io流实现序列化
-
一个Java对象要能序列化,必须实现一个特殊的java.io.Serializable接口,它的定义如下:
public interface Serializable { } -
Serializable接口没有定义任何方法,它是一个空接口。我们把这样的空接口称为“标记接口”
-
io流序列化:
public class Main { public static void main(String[] args) throws IOException { ByteArrayOutputStream buffer = new ByteArrayOutputStream(); try (ObjectOutputStream output = new ObjectOutputStream(buffer)) { // 写入int: output.writeInt(12345); // 写入String: output.writeUTF("Hello"); // 写入Object: output.writeObject(Double.valueOf(123.456)); } System.out.println(Arrays.toString(buffer.toByteArray())); } }
5.2、反序列化
1、和ObjectOutputStream相反,ObjectInputStream负责从一个字节流读取Java对象
try (ObjectInputStream input = new ObjectInputStream(...)) {
int n = input.readInt();
String s = input.readUTF();
Double d = (Double) input.readObject();
}
2、推荐廖雪峰老师的博客
- 推荐博客:java教程














 3115
3115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









