









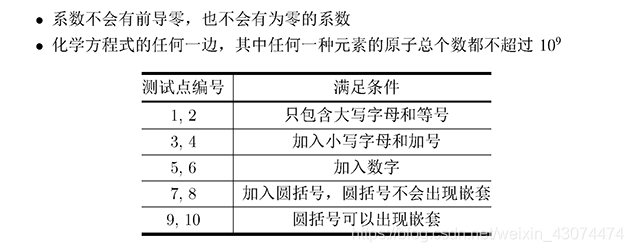
思路分析
每输入一个方程式即处理一个方程式,这样可以减少存储开销。对输入的方程式,将其进行多次切分,首先以“=”为界限,将方程式切分为左半部分和右半部分。此操作在主函数中进行。再对这两部分,以“+”为界限分别进行切割,此时切割出来的称为基本项。此操作在如下函数中进行。
void ProcessExpr(string expr,char side)
对每一个基本项进行处理,首先提取出基本项的系数,比如说4Na(Au(CN)2)的系数是4,Na(OH)2的系数是1,。将系数分离出来之后,得到的就是化学式,上面给出的两个基本项提取系数后得到的化学式分别为Na(Au(CN)2)和NA(OH)2。再遍历化学式的每一个字符,分为如下几种情况。
若当前遍历到的字符是大写字母,则判断下一个字符是否为小写字母,从而得到原子式。之后再提取该原子的下标。
若当前遍历到的字符是’(’,则进入递归处理函数。递归的操作是若遇到’)‘则结束当前函数,若遇到’('则继续进行递归,遇到大写字母则提取其原子式。
本程序的关键就是对括号情况的处理,把括号问题解决之后,其余的就都是一些细节问题了。
#include <iostream>
#include<string>
#include<vector>
#include<stack>
#include<map>
#include<algorithm>
using namespace std;
map<string, int> ma1, ma2;//分别存储方程式的左边和右边的原子
//分离出系数来并存放在coef中
void GetCoef(string formula,int & coef,int & index) {
string temp = formula.substr(index);
size_t indx = 0;
try {
coef = stoi(temp, &indx, 10);
index += indx;
}
catch (exception e) { coef = 1; }
}
//处理括号的情况
void ProcessBra(string formula,map<string,int> & bracketMap,int & index) {
while (true) {
string atom = string(1, formula[index]);
index++;
if (atom == "(") {
map<string, int> inBra;//存放括号里的原子
ProcessBra(formula, inBra,index);
int num;//括号的下标
GetCoef(formula, num, index);
for (auto i = inBra.begin(); i != inBra.end(); i++) {
//将内层括号中的原子乘以括号的下标之后加到bracketMap中
bracketMap[(*i).first] += (*i).second * num;
}
}
else if (atom == ")") {
return;
}
else {
if (formula[index] >= 'a' && formula[index] <= 'z') {
atom += string(1, formula[index]);
index++;
}
int subscript;//紧跟原子的下标
GetCoef(formula, subscript, index);
bracketMap[atom] += subscript;
}
}
}
//处理方程式的每一项
void ProcessFormula(string coefFormula,char side) {
int coef = 1;//系数
int index = 0;//处理当前项时的索引
GetCoef(coefFormula, coef, index);
string formula = coefFormula.substr(index);
index = 0;
map<string, int> tempMap;//存放当前项的原子
string atom;
while (index < formula.size()) {
atom = formula.substr(index, 1);
index++;
if (atom == "(") {
map<string, int> inBra;
ProcessBra(formula,inBra, index);
int num;//求括号的下标
GetCoef(formula, num, index);
for (auto i = inBra.begin(); i != inBra.end(); i++) {
//将括号中的原子乘以括号的下标之后加到tempMap中
tempMap[(*i).first] += (*i).second * num;
}
}
else {
if (formula[index] >= 'a' && formula[index] <= 'z') {//判断紧邻的下一个字符是否为小写字母
atom += formula[index];
index++;
}
int num;
GetCoef(formula, num, index);
tempMap[atom] += num;
}
}
for (auto i = tempMap.begin(); i != tempMap.end(); i++) {
if(side =='l')//如果是方程式的左侧,则更新ma1,否则更新ma2
ma1[(*i).first] += (*i).second *coef;
else
ma2[(*i).first] += (*i).second *coef;
}
}
//将方程式的每一项拆分开
void ProcessExpr(string expr,char side) {
int start = 0, end;//充当切分方程时的索引值
string coefFormula;//系数和分子式
while (true) {
end = expr.find('+', start);
if (end == -1) {//只剩下最后一项
coefFormula = expr.substr(start);
ProcessFormula(coefFormula, side);
break;
}
coefFormula = expr.substr(start, end - start);
ProcessFormula(coefFormula,side);
start = end + 1;
}
}
int main()
{
int n;
string equation;//输入的方程式
string left, right;//将方程式以‘=’为界限,分为左半部分和右半部分
cin >> n;
for (int i = 0; i < n; i++) {
ma1.clear(), ma2.clear();
cin >> equation;
int position = equation.find('=', 0);
left = equation.substr(0, position);
right = equation.substr(position+1);
ProcessExpr(left, 'l');
ProcessExpr(right, 'r');
if (ma1 != ma2)
puts("N");
else
puts("Y");
}
}
上面给出的源码在CCF系统中经过测试是一百分,但这并不是我最初的代码。刚开始时我是用的结构体存储的原子,对括号的处理也没有采用递归,而是采用了一种栈的思想。比如说化学式Na(Au2(O(CN3)2S)3,在对其每个字符进行遍历时,当遍历到’(’,则把它的位置入栈,遍历到’)’,则弹出栈顶元素,因为没分离出一个原子,就把它顺序的存储到结构体数组中,因此这样就可以定位到括号内的原子。之后再提取括号的下标,让括号内的每个原子的原子数都乘以下标。当时按照这种方法写出的程序却之后90分,找了好长时间也没发现问题在那儿,下面给出源码,还望大神指正。
#include <iostream>
#include<string>
#include<vector>
#include<stack>
#include<algorithm>
using namespace std;
struct Atom {
string name;
int amount;
};
Atom atomL[1000],atomR[1000];//方程左侧的原子和右侧的原子
int countL = 0, countR = 0;//方程式左边的元素种类数和右边的元素种类数
void AddToLeft(Atom a) {
int i;
for ( i = 0; i < countL; i++) {
if (a.name == atomL[i].name) {
atomL[i].amount += a.amount;
break;
}
}
if (i == countL) {
atomL[i].name = a.name;
atomL[i].amount = a.amount;
countL++;
}
}
void AddToRight(Atom a) {
int i;
for (i = 0; i < countR; i++) {
if (a.name == atomR[i].name) {
atomR[i].amount += a.amount;
break;
}
}
if (i == countR) {
atomR[i].name = a.name;
atomR[i].amount = a.amount;
countR++;
}
}
//处理方程式的每一项
void ProcessFormula(string coefFormula,char side) {
size_t indx = 0;//字符串进行数值转换时,存放转换过程中第一个不被接受的字符的索引
int coef = 1;//系数
string formula;//分子式
try {
coef = stoi(coefFormula,&indx,10);
}
catch (exception e){}
formula = coefFormula.substr(indx);
vector<Atom> formulaAtom;//当前分子式所含的原子
stack<int> bracket;//存放左括号的位置
int index = 0;//处理分子式时的索引
int count = 0;//记录有多少种原子
string atom;
while (index < formula.size()) {
atom = formula.substr(index, 1);
index++;
if (atom == "(") {
bracket.push(count);
}
else if (atom == ")") {
string temp = formula.substr(index);
int num = 1;
try {
num = stoi(temp, &indx, 10);
index += indx;
}
catch (exception e) {}
if (num != 1) {
for (int i = bracket.top(); i < count; i++) {
formulaAtom[i].amount *= num;
}
bracket.pop();
}
}
else {
string str;
str = formula.substr(index, 1);
if (str[0] >= 'a'&&str[0] <= 'z') {//判断紧邻的下一个字符是否为小写字母
atom += str;
index++;
}
string temp = formula.substr(index);
int num = 1;
try {
num = stoi(temp, &indx, 10);
index += indx;
}
catch (exception e) {}
Atom tempAtom = { atom,num };
formulaAtom.push_back(tempAtom);
count++;
}
}
for (int i = 0; i < count; i++) {
formulaAtom[i].amount *= coef;
if (side == 'l')
AddToLeft(formulaAtom[i]);
else
AddToRight(formulaAtom[i]);
}
}
//将方程式的每一项拆分开
void ProcessExpr(string expr,char side) {
int start = 0, end;//充当切分方程时的索引值
string coefFormula;//系数和分子式
while (true) {
end = expr.find('+', start);
if (end == -1) {//只剩下最后一项
coefFormula = expr.substr(start);
ProcessFormula(coefFormula, side);
break;
}
coefFormula = expr.substr(start, end - start);
ProcessFormula(coefFormula,side);
start = end + 1;
}
}
bool compare(Atom a1, Atom a2) {
if (a1.name < a2.name)
return true;
else return false;
}
//判断方程是否配平
bool Judge() {
if (countL == countR) {
sort(atomL, atomL + countL,compare);
sort(atomR, atomR + countR,compare);
for (int i = 0; i < countL; i++) {
if (atomL[i].name != atomR[i].name || atomL[i].amount != atomR[i].amount)
return false;
}
return true;
}
else
return false;
}
int main()
{
int n;
cin >> n;
char result[100];//存放最后的判断结果
for (int i = 0; i < n; i++) {
countL = countR = 0;
string equation;
cin >> equation;
string left, right;//将方程式以‘=’为界限,分为左半部分和右半部分
int position = equation.find('=', 0);
left = equation.substr(0, position);
right = equation.substr(position+1);
ProcessExpr(left, 'l');
ProcessExpr(right, 'r');
if (Judge())
result[i] = 'Y';
else
result[i] = 'N';
}
for (int i = 0; i < n; i++)
cout << result[i] << endl;
}
附测试用例
H2+O2=H2O
2H2+O2=2H2O
H2+Cl2=2NaCl
H2+Cl2=2HCl
CH4+2O2=CO2+2H2O
CaCl2+2AgNO3=Ca(NO3)2+2AgCl
3Ba(OH)2+2H3PO4=6H2O+Ba3(PO4)2
3Ba(OH)2+2H3PO4=Ba3(PO4)2+6H2O
4Zn+10HNO3=4Zn(NO3)2+NH4NO3+3H2O
4Au+8NaCN+2H2O+O2=4Na(Au(CN)2)+4NaOH
Cu+As=Cs+Au














 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









