







如果你看完这篇博客觉得不过瘾,那就回来戳“进阶版”试试手吧~:
https://blog.csdn.net/weixin_43141320/article/details/105485014
1. 按课程类别统计每个类别课程的门数,如课程代码BT001,BT002都是专业必修课。
本题使用的关系如下:
course(cno,cname,credit)
对应课程代码,课程名称,学分,其中课程代码前2位代表不同类型的课程,如
BT 代表 专业必修课,XZ 代表专业限选课。
select left(cno, 2), count(cno) from course group by left(cno, 2);
录入本题的原因是,大部分时候我们做的都是直接按照某一列的列名分组,这道题说明了可以用列里的元素分组。
2. 找出最贵的激光打印机型号和价格。
本关使用的关系为printer(model,color,type,price)
表示的含义是
model:打印机型号;
color:是否彩色, T 彩色,F 黑白
type:类型,ink-jet 表示喷墨, laser 表示激光;
price:单价
select model, price from printer where price in
(select max(price) from printer);
我自己由于一开始没有看清楚题目条件,写的是这样,然后发现有激光打印机的限制,所以换成了如下的语句:
select model, price from printer where price in
(select max(price) as price from printer group by type having type='laser');
或者这样也是对的:
select model, price from printer where price in
(select max(price) as price from printer where type='laser');
甚至还可以这样:
select model, price from
printer where price=
(select max(price) from
(select * from printer where type='laser') as a) and type='laser';
录入这道题的原因是,初学者会把重心放在“最贵”上面,想着max(price),但是这样只能选出最大的价格来,其他的信息无法选出。
这道题看起来有点麻烦,总让人想着有没有其他更高级的语句能简化它,现在来分析一下语句这么写的必然性:
确定题目的制约:找出最贵的激光打印机型号和价格。
首先看看“最贵”,最贵就要有max(price),如果仅仅是在printer里面加这个聚集函数,就会从全局选出“最贵” 的价格,这里的“最贵”不是全局最贵,而是局部最贵,即不是所有打印机的最贵,而是激光打印机的最贵。所以这里有两种方式解决:
- 分组:按照type分组,加聚集函数max(price),然后加上筛选条件:type=‘laser’。这样选出来的是type='laser’的price最贵的打印机的type和price。如下:
select type, max(price) from printer
group by type having type='laser';
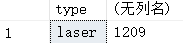
然后在全局中选出价格等于这个值的打印机的型号和价格,这里说的就是第一种方法。
这里补充一下,如果像这样select model, max(price) from printer直接结束了,是错误的,因为select 后面加了列名又有聚集函数,这是要分组的节奏哇,但是后面又木有group by,所以就报错了~所以正确的是:
select model, max(price) from printer group by model
这里的分组依据(group by后面的语句)查询不能使用聚集函数或者子查询。
但是如果仅仅只有一个聚集函数的话,没有group by 是正确的:
select max(price) from printer ;
这个实现的就是从全局中找到最大的价格。
- 筛选出type为"laser"的打印机,然后从中选出“最贵”来。
按照这样的思路我们首先将type='laser’的打印机选出来:
select * from printer where type='laser';
然后从中选出model和最大的price,说到这里,你就能够自然而然地想到这么写:
select model, max(price) from
(select * from printer where type='laser') as a group by model;
咱们看看结果:
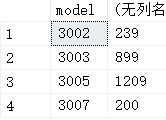
这啥?貌似不是我想要的,难道前面筛选laser打印机出错了?看看先:
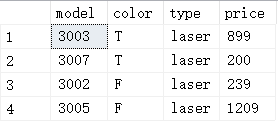
这是所有的laser打印机,对比一下,仅仅是选出了model和price,咱们现在走出死胡同,因为我们加了model作为分组依据,从每一个相同的model类中选出price最大的打印机,又因为model是唯一的,所以看上去貌似仅仅做了投影操作而已,我们前面这么写,是思维的惯性,但遗憾的是sql没办法顺着我们的惯性,如果非要依照这个思路走下去,我们只能做的是选出laser打印机最贵的价格,然后从全局中筛选出价格值等于这个的而且type是laser的打印机:
select model, price from
printer where price=(select max(price) from
(select * from printer where type='laser') as a)
and type='laser';
这样虽然实现了,然是语句看起来很繁杂,创建了两次新查询。
这里的第一个where语句之后的条件语句可以换成这样:
price in
(select max(price) as price from printer where type='laser');
也就是这道题的上面说到的第二种方法。
我从这里也学到了,因为我本以为这样写只会从全局选出最大的价格,如果最大价格的打印机刚好是laser型的就是正确的,如果不是就会出错,但是事实证明这种想法是错的。这里的where语句能够将聚集函数的范围缩小到laser类型,看来还是要多多实践~
3. 使用分组操作和聚集函数解决比较复杂的数据统计问题
关系说明:
product(maker,model,type)
maker:表示生产厂商
model:生产的产品型号
type:产品类型,有pc laptop两种
pc(model,speed,ram,hd,price)
表示型号,速度,内存大小,硬盘大小,价格
laptop(model,speed,ram,hd,screen,price)
表示型号,速度,内存大小,硬盘大小,屏幕大小和价格
- [1] 查询在一种或两种电脑(含PC和laptop)中出现过的硬盘的容量。
首先利用如下语句创建视图V_test:
create view V_test as
select product.maker,product.model,product.type,pc.price,pc.hd,pc.speed
from product join pc on product.model=pc.model
union
select product.maker,product.model,product.type,laptop.price,laptop.hd,laptop.speed
from product join laptop on product.model=laptop.model
对于初学者来说,在掌握不够全面的情况下,难以想到超越现学知识实现需要,比如在写sql语句的时候就陷在以为只能写子查询来实现目的,但是子查询的缺点是,这一句用了下一句就不能用了,所以这里创建视图可以很好的解决这一问题。
本问的意思是,电脑的硬盘容量不同,但是不同的电脑可能容量相同,这里要求选出具有相同硬盘容量的 电脑数目 不超过3个的这个容量值。
select hd from v_test group by hd having count(model)<3

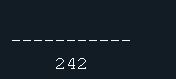
- [2] 统计各生产厂商生产的电脑(不区分pc和laptop)的平均处理速度的最大值。
select max(avg_speed) from
(select maker, avg(speed) as avg_speed from V_test group by maker)
as a;
- [3] 统计出各厂商生产价格高于1000的产品数量,不用区分是pc还是laptop
select maker, count(model)
from (select * from V_test where price > 1000) a group by maker;
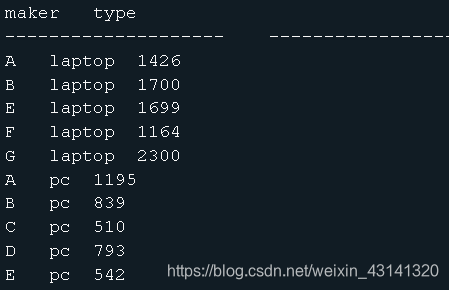
- [4] 分别统计各厂商生产的pc,laptop的平均价格。
方法一:
select maker, 'laptop' as type, avg(price) from
(select * from V_test where type='laptop') a group by maker
union all
select maker, 'pc' as type, avg(price) from
(select * from V_test where type='pc') b group by maker;
方法二:
select maker, type, avg(price) from
(select * from V_test) a group by maker, type;
看看方法一和方法二的区别,先说方法一,通过方法一,我学会了两个地方:
- 首先发现最终的输出结果属性行只有两个,还有一个没有名字,可能一开始你会这么写:
select maker, type, avg(price) from
(select * from V_test where type='laptop') a group by maker
但是不对啊,因为你用的是maker分组,而且求的是价格的平均值,你说这个type是谁的type?所以这样不对,这个是受限于你的分组对象,这里选择的是用maker分组,所以最后的出来的结果关系除了avg(price)之外不能有其他的内容了,这里的方法一给了我启发,可以使用这种方法来增加一列:
select maker, 'laptop' as type, avg(price) from
(select * from V_test where type='laptop') a group by maker
不过增加的一列内容是一样的。
- 第二个启发是,union和union all除了是否去重的区别之外,还有如下的区别,我不多说,一张图胜过一切:
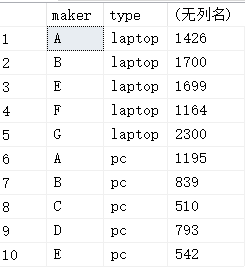
上面是union all的结果,看看下面union的结果:
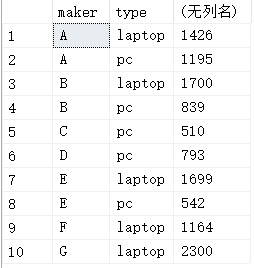
可以看出,union all的结果将R和S分开了,但是union将R和S混在了一起。
当然这一切一切的折腾都是建立在你不知道分组还可以多元素分组的前提下,方法二是利用maker和type两个元素分组的结果。
4.使用left/right函数作为分组条件
关系:benke
内容:

- 计数表中以不同字母开头的人数:
select left(name, 1), count(id) from benke group by left(name, 1);
结果:

这也说明了大小写对sql无影响。
- 以名字“J”开头的人数:
select count(id) from benke where left(name, 1)='J';
结果:

这里需要注意的地方:
group by后面加条件不能使用where 而只能使用having ;
如果在select 之后既有聚集函数,也有列名,那么后面一定要有group by语句,没有的话就是错的。如:
select max(price), model from V_test; -- 非法
select max(price), model from V_test group by model; -- 合法
交并差之后的子查询可以作为新查询,但是在使用的时候要将这个子查询用括号括起来而且重命名:
select * from
(select id from benke
union
select id from yanjiu) as a;














 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









