





**第一章 xml文件**
1.1什么是xml文件
(1)xml是课扩展表示语言,就是开发者在符合xml命名规则的基础之上,可以根据自己的需要定义自己的标签。
1.2xml文件的作用
主要是用来储存数据
1.3解析xml文件的方法
DOM、DOM4J、SAX
**第二章 DOM4J解析xml文件**
2.1导入DOM4J.jar包
dom4j-1.6.1.jar
2.2DOM4J常用的对象
SAXReader:读取xml文件到Document树结构文件对象。
Document:是一个xml文档对象树,类比Html文档对象。
Element:元素节点。通过Document对象可以查找单个元素。
2.3DOM4J解析步骤
第一步:创建解析器
SAXReader reader = new SAXReader();
第二步:通过Document对象:通过解析器reader方 法获取
Document doc = new Document(“studentInfo.xml”);
第三步:获取xml根节点
Element root = doc.getRootElement();
第四步:遍历解析子节点
2.4实例一 使用DOM4J解析xml文件
准备students.xml文件
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXParserTest {
public static void main(String[] args) {
try {
//创建解析工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//创建解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//通过解析器的parser方法
saxParser.parse(“conf/Persons.xml”,new MyDefaultHandler());
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyDefaultHandler extends DefaultHandler{
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.println("<" + qName +">");
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("<" + qName + ">");
}
}
执行结果:
**第四章 使用DOM4J的xPath解析xml文件**
4.1XPath语法
xpath使用路径表达式来选取xml文档中的节点或节点集。节点是通过沿着路径或者步来选取的。
实例一:
下面列出了最有用的路径表达式:
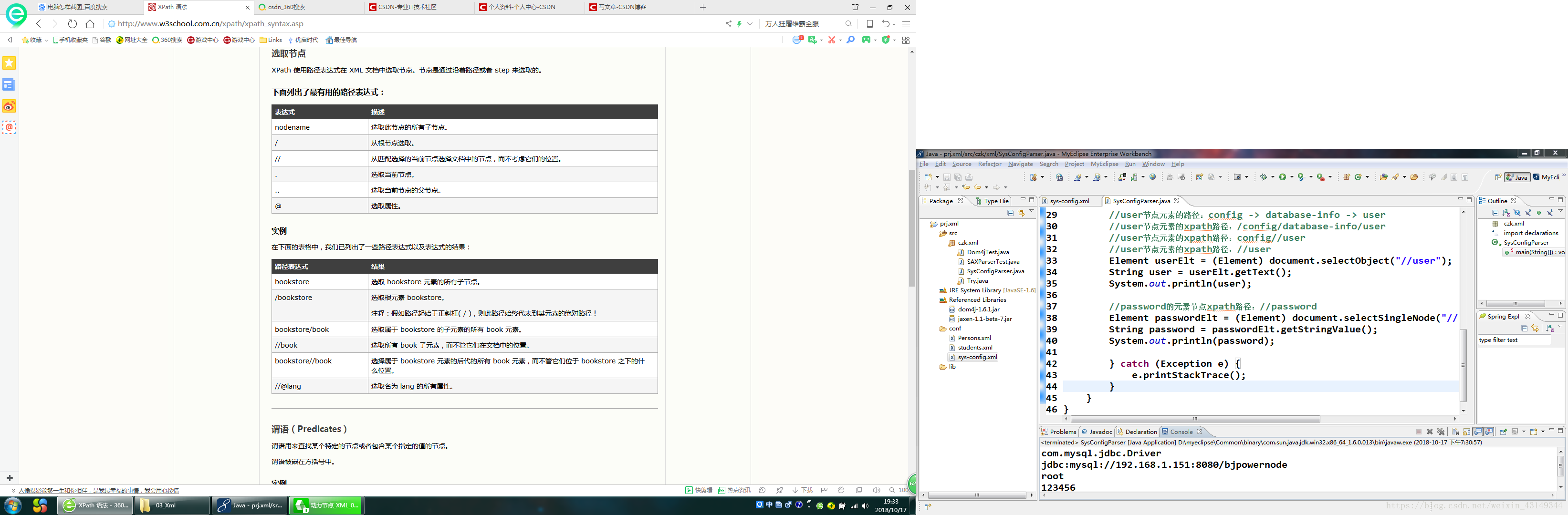
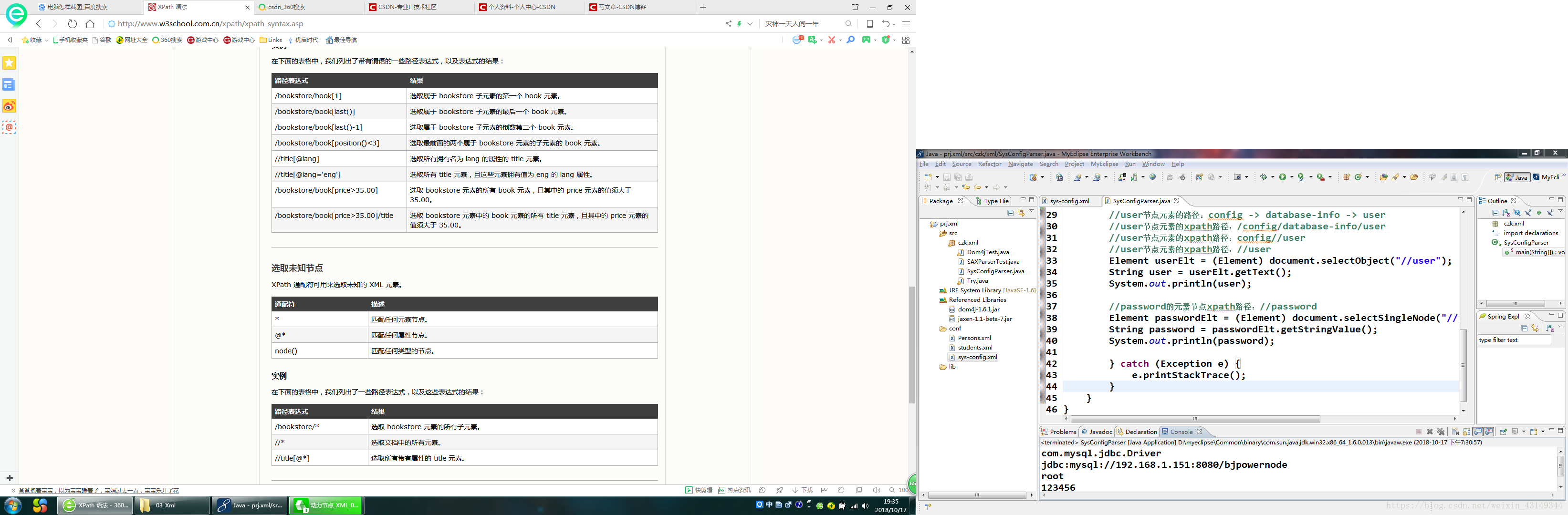
用DOM4J的xpath解析xml文件的代码如下:
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class SysConfigParser {
public static void main(String[] args) {
try {
//创建解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将文件读取到内存中,生成一个Document对象树
Document document = reader.read("conf/sys-config.xml");
//driver-name节点元素路径:config -> database-info -> driver-name
//driver-name节点元素的xpath路径:/config/database-info/driver-name
Element driverNameElt = (Element) document.selectSingleNode("/config/database-info/driver-name");
//获取drivernameElt节点元素对象的文本内容
String driverName = driverNameElt.getStringValue();
System.out.println(driverName);
//url节点元素路径:config -> database-info -> url
//url节点元素的xpath路径:/config/database-info/url
//url节点元素的xpath路径:config//url
//url节点元素的xpath路径://url
Element urlElt = (Element) document.selectSingleNode("config//url");
String url = urlElt.getStringValue();
System.out.println(url);
//user节点元素的路径:config -> database-info -> user
//user节点元素的xpath路径:/config/database-info/user
//user节点元素的xpath路径:config//user
//user节点元素的xpath路径://user
Element userElt = (Element) document.selectObject("//user");
String user = userElt.getText();
System.out.println(user);
//password的元素节点xpath路径://password
Element passwordElt = (Element) document.selectSingleNode("//password");
String password = passwordElt.getStringValue();
System.out.println(password);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
com.mysql.jdbc.Driver
jdbc:mysql://192.168.1.151:8080/bjpowernode
root
123456
实例二:
xml文件为:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class serverParser {
public static void main(String[] args) {
try {
//创建解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将文件读取到内存中,生成一个document对象树
Document document = reader.read("conf/server.xml");
//获取connector节点元素对象的xpath路径:/server/service/connector
//获取connector节点元素对象的xpath路径:server//connector
//获取connector节点元素对象的xpath路径://connector
Element connectorElt = (Element) document.selectSingleNode("//connector");
//获取connector节点元素对象的port属性对象
Attribute portAttr = connectorElt.attribute("port");
//获取port属性对象的值
String port1 = portAttr.getStringValue();
String port2 = connectorElt.attributeValue("port");
//输出值
System.out.println(port1);
System.out.println(port2);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
8080
8080
第五章 用xpath解析xml文件
准备xml文件
<?xml version="1.0" encoding="UTF-8"?>代码如下:
package czk.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Element;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
public class MyXPathTest {
public static void main(String[] args) {
try {
//创建解析工厂
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder = documentBuilderFactory.newDocumentBuilder();
//通过解析器读取文件,生成一个Document对象树
Document document = builder.parse("conf/bookstore.xml");
//创建XPath对象
XPath xPath = XPathFactory.newInstance().newXPath();
//1.获取bookstore节点下book属性category值为web下的第二个title节点的文本内容
//bookstore -> book [@category = 'web'][2] -> title
//XPath路径:/bookstore/book[@category = 'web'][2]/title/text()
String titleXpath = "/bookstore/book[@category = 'web'][2]/title/text()";
String titleValue = (String) xPath.evaluate(titleXpath,document,XPathConstants.STRING);
System.out.println(titleValue);
//2.获取bookstore节点下book属性category值为web的title属性为en的节点内容
//bookstore ->book[@category='web'] -> title[@lang='en']
//XPath路径:/bookstore/book[@category='web']/title[@lang='en']/text()
String titlelangXpath = "/bookstore/book[@category='web']/title[@lang='en']/text()";
String titlelang = (String) xPath.evaluate(titlelangXpath, document, XPathConstants.STRING);
System.out.println(titlelang);
//3.获取bookstore下book属性category值为cooking的title的lang属性的值
//bookstore -> book[@category='cooking'] -> title ->@lang
//XPath路径:/bookstore/book[@category='cooking']/title/@lang
String titleLangAttrXpath = "/bookstore/book[@category='cooking']/title/@lang";
String titleLangAttrValue = (String) xPath.evaluate(titleLangAttrXpath, document, XPathConstants.STRING);
System.out.println(titleLangAttrValue);
//4.获取bookstore节点下所有book的节点集合
NodeList booklist = (NodeList) xPath.evaluate("/bookstore/book", document, XPathConstants.NODESET);
//开始遍历booklist
for(int i = 0;i < booklist.getLength();i++){
Element bookElt = (Element) booklist.item(i);
String titleValue01 = (String) xPath.evaluate("title", bookElt, XPathConstants.STRING);
String authorValue = (String) xPath.evaluate("author", bookElt, XPathConstants.STRING);
String year = (String) xPath.evaluate("year", bookElt, XPathConstants.STRING);
String price = (String) xPath.evaluate("price", bookElt, XPathConstants.STRING);
System.out.println(titleValue01 +" " + authorValue + " " + year + " " + price);
System.out.println("--------------------");
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}














 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









