







7.4.4 行对象
默认地,获取方法从数据库返回的“行”值是元组。调用者要负责了解查询中列的顺序,并从元组中抽取单个的值。查询的值个数增加时,或者处理数据的代码分布在一个库的不同位置时,通常比较容易的做法是使用一个对象,并用它的列名来访问值。这样一来,编辑查询时,元组内容的个数和顺序会随之改变,并且依赖于查询结果的代码也不太会出问题。
Connection对象有一个row_factory属性,允许调用代码控制所创建对象的类型来表示查询结果集中的各行。sqlite3还包括一个Row类,这个类被用作一个行工厂可以通过Row实例使用列索引或名来访问列值。
import sqlite3
db_filename = 'todo.db'
with sqlite3.connect(db_filename) as conn:
# Change the row factory to use Row.
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
cursor.execute("""
select name,description,deadline from project
where name = 'pymotw'
""")
name,description,deadline = cursor.fetchone()
print('Project details for {} ({})\n due {}'.format(
description,name,deadline))
cursor.execute("""
select id,priority,status,deadline,details from task
where project = 'pymotw' order by deadline
""")
print('\nNext 5 tasks:')
for row in cursor.fetchmany(5):
print('{:2d} [{:d}] {:<25} [{:<8}] ({})'.format(
row['id'],row['priority'],row['details'],
row['status'],row['deadline']))
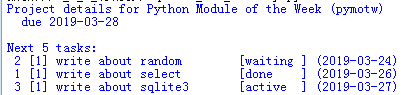
这个版本的sqlite3_select_variations.py例子被重写为使用Row实例而不是元组。打印project表中的行时仍然通过位置访问列值,不过任务的print语句使用了关键字查找,所以查询中列顺序的改变不会有任何影响。
运行结果:















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









