







 本文介绍了B+树作为多叉树的一种变体,如何通过将索引与业务数据分离,减少I/O次数并提高单次I/O的有效性,以提升数据库查询性能。B+树的非叶子节点仅存储索引,叶子节点包含索引与业务数据,优化了磁盘数据读取,适合大规模数据存储。
本文介绍了B+树作为多叉树的一种变体,如何通过将索引与业务数据分离,减少I/O次数并提高单次I/O的有效性,以提升数据库查询性能。B+树的非叶子节点仅存储索引,叶子节点包含索引与业务数据,优化了磁盘数据读取,适合大规模数据存储。
多叉树——B-tree

每个节点维护两个数据,并指向最多 3 个子节点。如图 3 个子节点的数据分别为:小于 17, 17 ~ 35 ,大于 35。
假设,从上图中查找 10 这个数,步骤如下:
-
找到根节点,对比 10 与 17 和 35 的大小,发现 10 < 17 在左子节点,也就是第 2 层节点;
-
从根节点的指针,找到左子节点,对比 10 与 8 和 12 的大小,发现
8 < 10 < 12,数据在当前节点的中间子节点,也就是第 3 层节点; -
通过上步节点的指针,找到中间子节点(第 3 层节点),对比 10 与 9 和 10 的大小,发现
9 < 10 == 10,因此找到当前节点的第二数即为结果。
加上忽略的 12 个数据,从 26 个数据中查找一个数字 10,仅仅用了 log3(26)≈ 3次,而如果用平衡二叉树,则需要log2(26)≈ 5 次,事实证明,多叉树确实可以再次提高查找性能。
多叉树是在二分查找树的基础上,增加单个节点的数据存储数量,同时增加了树的子节点数,一次计算可以把查找范围缩小更多。
优点:二叉平衡树的基础上,使加载一次节点,可以加载更多路径数据,同时把查询范围缩减到更小。
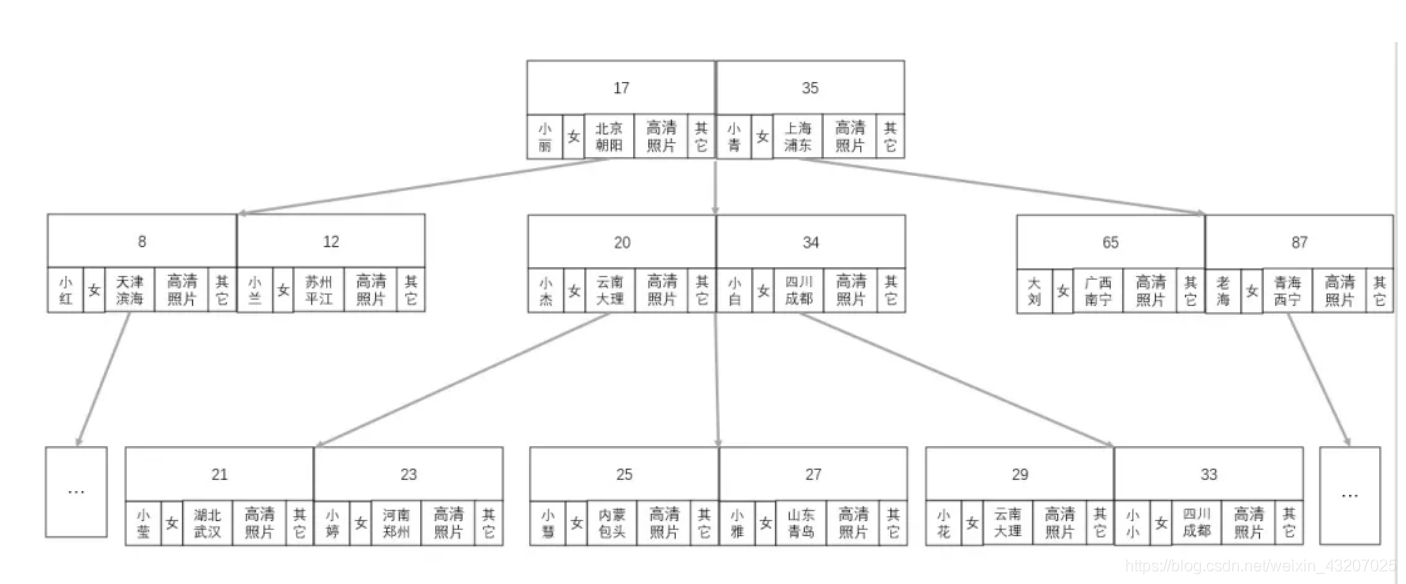
缺点:业务数据的大小可能远远超过了索引数据的大小,每次为了查找对比计算,需要把数据加载到内存以及 CPU 高速缓存中时,都要把索引数据和无关的业务数据全部查出来。本来一次就可以把所有索引数据加载进来,现在却要多次才能加载完。如果所对比的节点不是所查的数据,那么这些加载进内存的业务数据就毫无用处,全部抛弃。
多叉树——B+tree
鉴于磁盘 I/O 的性能问题,以及每次 I/O 获取数据量上限所限,提高索引本身 I/O 的方法最好是,减少 I/O 次数和每次获取有用的数据。
B-tree 已经大大改进了树家族的性能,它把多个数据集中存储在一个节点中,本身就可能减少了 I/O 次数或者寻道次数。
但是仍然有一个致命的缺陷,那就是它的索引数据与业务绑定在一块,而业务数据的大小很有可能远远超过了索引数据,这会大大减小一次 I/O 有用数据的获取,间接的增加 I/O 次数去获取有用的索引数据。
因为业务数据才是我们查询最终的目的,但是它又是在「二分」查找中途过程无用的数据,因此,如果只把业务数据存储在最终查询到的那个节点是不是就可以了?
B+tree 横空出世,B+ 树就是为了拆分索引数据与业务数据的平衡多叉树。
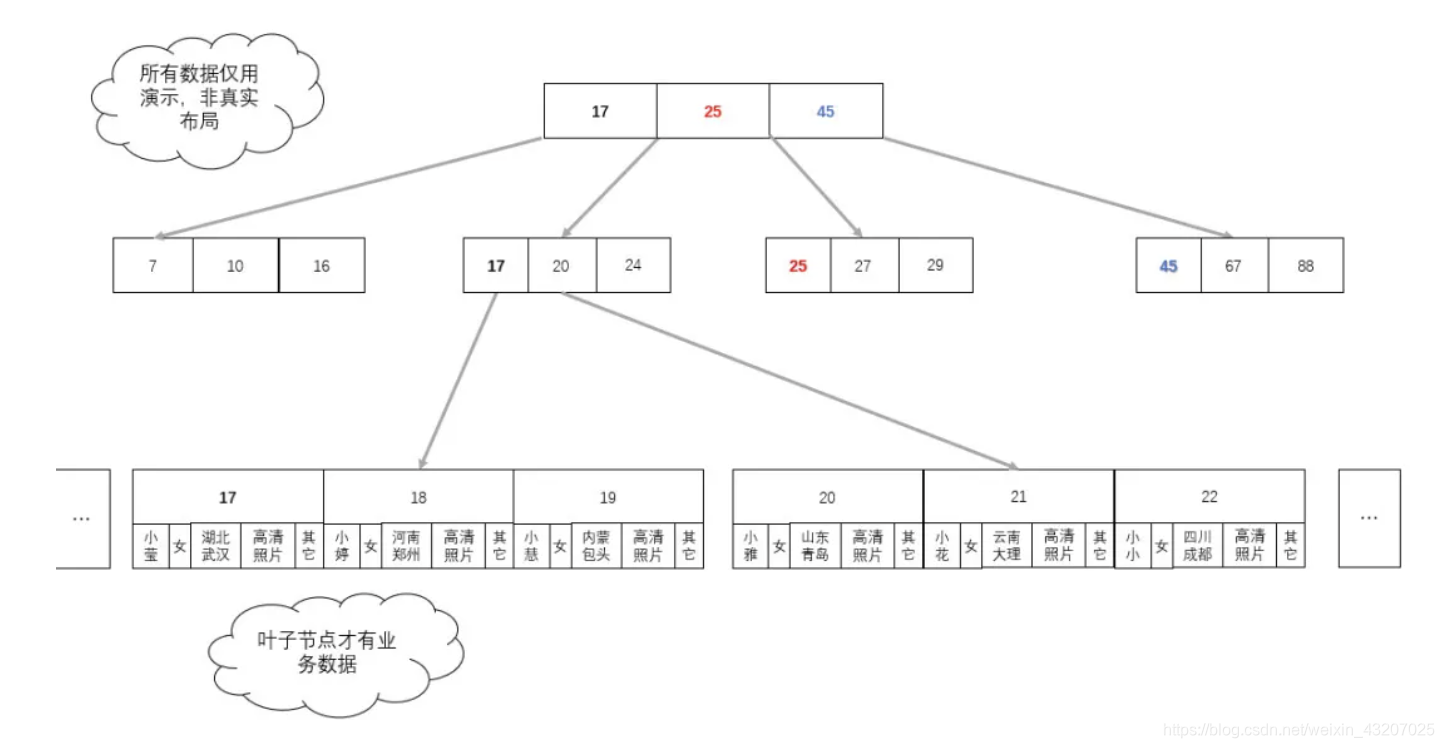
B+ 树中,非叶子节点只保存索引数据,叶子节点保存索引数据与业务数据。这样即保证了叶子节点的简约干净,数据量大大减小,又保证了最终能查到对应的业务数。既提高了单次 I/O 数据的有效性,又减少了 I/O 次数,还实现了业务。
但是,在数据中索引与数据是分离的,不像示例那样的?
如图:我们只需要把真实的业务数据,换成数据所在地址就可以了,此时,业务数据所在的地址在 B+ 树中充当业务数据。
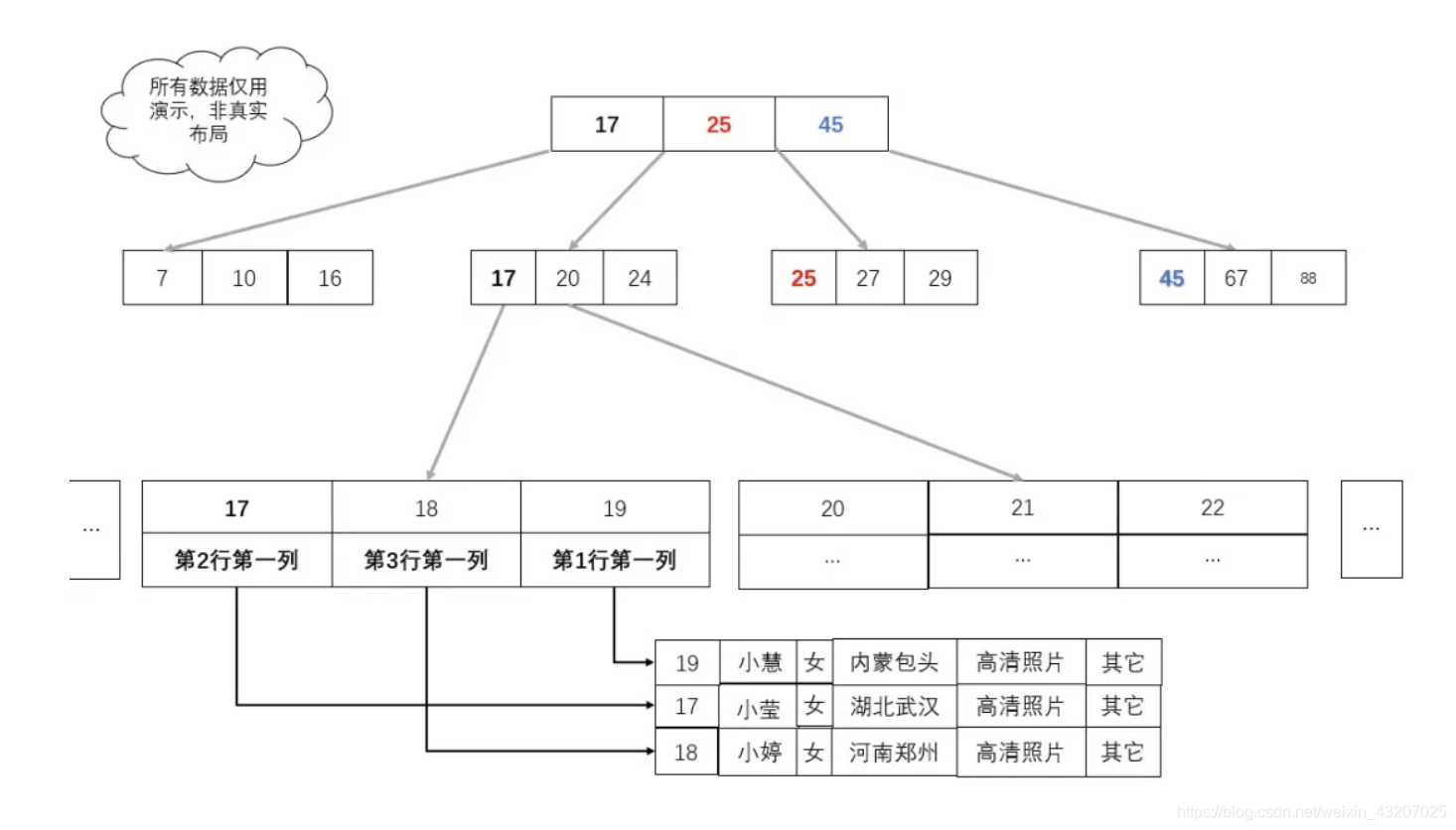
总结:
-
数据存储在磁盘( SSD 跟 CPU 性能也不在一个量级),而磁盘处理数据很慢;
-
提高磁盘性能主要通过减少 I/O 次数,以及单次 I/O 有效数据量;
-
索引通过多阶(一个节点保存多个数据,指向多个子节点)使树的结构更矮胖,从而减少 I/O 次数;
-
索引通过 B+ 树,把业务数据与索引数据分离,来提高单次 I/O 有效数据量,从而减少 I/O 次数;
-
索引通过树数据的有序和「二分查找」(多阶树可以假设为多分查找),大大缩小查询范围;
-
索引针对的是单个字段或部分字段,数据量本身比一条记录的数据量要少的多,这样即使通过扫描的方式查询索引也比扫描数据库表本身快的多;

















 3151
3151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









