







以问题推动学习之——Postgresql(1)
1、 理解group by与聚合函数
需求
将数据合成一组,根据每一组的最大数取出这一行的其它字段。
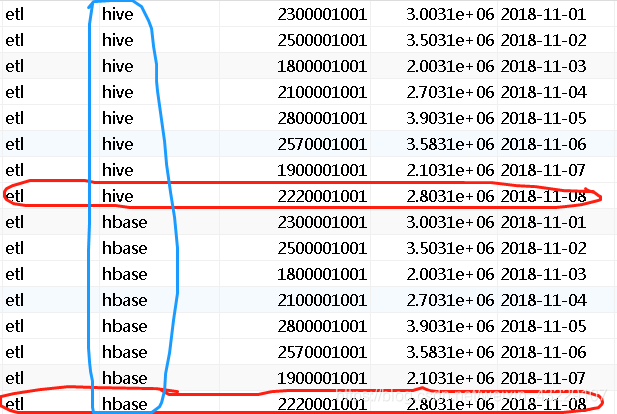
添加链接描述
如上图所示,我需要根据时间大小,取每一组(蓝色圈)最大时间这一行中的数据,即红色的两行中的某些数据。
解决
首先需要使用group by将图中蓝色圈中的字段聚合,然后使用max(时间字段)判断选出最大时间的那一行,最后根据时间将表中的其它数据取出来。
根据描述代码如下(以下代码了解大约意思就行了)
select 表的第二列, 表的第三列, 表的第四列 from (select max(第五列) as time, 第二列 from 表名 group by 第二列) as 新生成表的别名tb1 INNER JOIN 表名 ON tb1的第二列 = 表的第二列 and 表的第五列 = tb1.time;
深入理解
最开始时,我希望直接使用group by将需要数据的行找到就好了,确实很容易找到,但是select数据时,只能选择group by的数据或者使用聚合函数如max等取值,这对于需要取一些无规律的值时造成很大的麻烦。因此你需要对选择好的表再进行选择,因此使用了inner join … on … (内联)。
我们一步一步来理解我们怎么才能实现需求。
-
使用group by
select 第二列 from 表 group by 第二列;
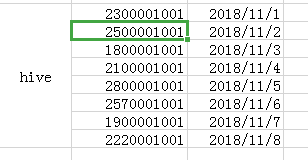
哈哈当然只有上表的第一列出现哈,没有后面两列。 -
使用聚合函数max
首先我们必须要说说为什么需要聚合函数。
如上表所示,当我们使用了group by后生成了一个虚拟表(就是上表),如果你仅仅想要取后面两列的某行,那么数据库不知道你需要哪个行,因此你需要调用函数从这一列中选出一个出来。因为我们的需求是时间最大,那么正好使用max聚合函数选出第三列的最大数。
同时我们应该明白数据库输出是一行对应一个字段,不会一对多(除非数组),因此不可能输出上表的样子。
select 第二列,max(第五列) from 表 group by 第二列;
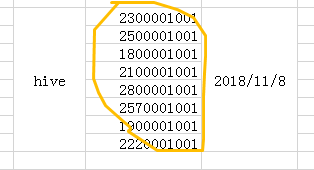
-
再次使用select
当我们找到我们需要的那一行的唯一条件后(第二列与时间列),我们可以根据这些条件再次从表中选择符合条件的行。
select 表的第二列, 表的第三列, 表的第四列 from (select max(第五列) as time, 第二列 from 表名 group by 第二列) as 新生成表的别名tb1 INNER JOIN 表名 ON tb1的第二列 = 表的第二列 and 表的第五列 = tb1.time; -
理解级联表
inner join:理解为“有效连接”,两张表中都有的数据才会显示
left join:理解为“有左显示”,比如on a.field=b.field,则显示a表中存在的全部数据及a\b中都有的数据,A中有、B没有的数据以null显示
right join:理解为“有右显示”,比如on a.field=b.field,则显示B表中存在的全部数据及a\b中都有的数据,B中有、A没有的数据以null显示
full join:理解为“全连接”,两张表中所有数据都显示,实际就是inner+(left-inner)+(right-inner)














 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









