




 本文介绍了Spark中RDD的概念及其依赖关系,包括窄依赖和宽依赖的特点与区别。详细解释了依赖如何帮助Spark在数据丢失时进行高效恢复,并探讨了shuffle操作在宽依赖中的作用。
本文介绍了Spark中RDD的概念及其依赖关系,包括窄依赖和宽依赖的特点与区别。详细解释了依赖如何帮助Spark在数据丢失时进行高效恢复,并探讨了shuffle操作在宽依赖中的作用。
依赖(血缘)的作用
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统,依赖)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
spark的宽窄依赖
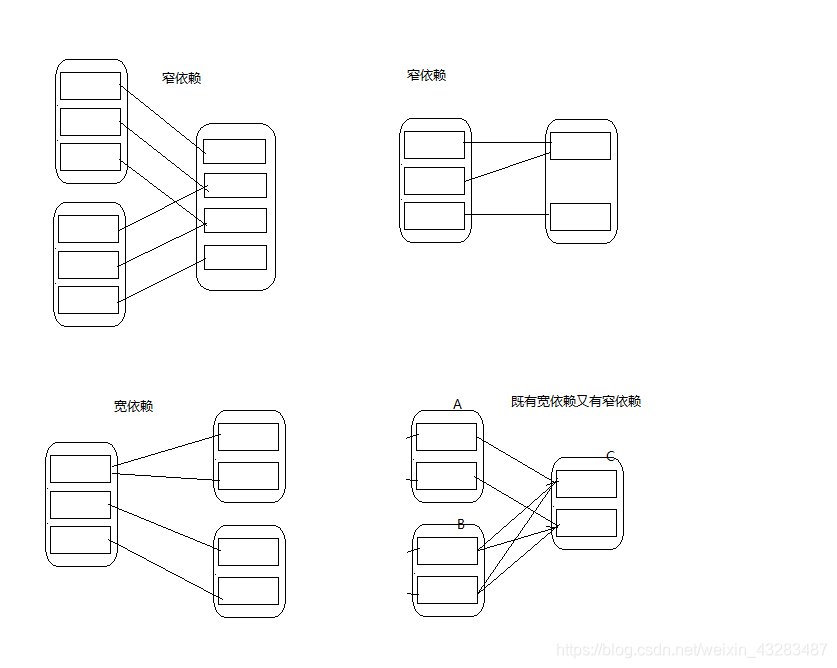
RDD和依赖的父RDD关系有两种,就是宽依赖和窄依赖
- 宽依赖: 多个子RDD的partition会依赖同一个父RDD的partition
- 窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个Partition使用 (独生子女)
当某个节点故障,spark对数据进行重新计算’
- 窄依赖: 一个父RDD值对应一个子RDD的分区,只需要计算和丢失的子RDD对应的父RDD即可,这个重算对数据利用率100%
- 宽依赖: 一部分数据用于恢复丢失的RDD,而另外的对应其他未丢失的部分,照成了多余的计算
spark shuffle
算子之间发生宽依赖


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











