







前几天在机器之心看到推送,说是有研究者推出了一种新的梯度优化的方法,标题蛮有噱头的:
直接对梯度下手,阿里达摩院提出新型优化方法,一行代码即可替换现有优化器
听起来很厉害的样子。后来去读了一下paper,发现核心思想还真就一行代码,但是这一行代码背后的理论性值得细细品味。论文代码已开源:
论文地址
Github地址
接下来对这篇paper,尤其是那一行代码背后的数学原理做一个理解。
1.综述
Gradient descent一直以来是训练Deep Neural Networks一个至关重要的环节,也是DL当初诞生的灵感来源,它直接影响到了模型的收敛速度,对梯度处理得是否中肯、漂亮,决定了这个模型最后施展出来的效果是否符合预期。由于神经网络本身的特点,随着模型层数的增加,梯度下降变得越来越困难(梯度消失、梯度爆炸、无法收敛等),如何缓解(暂时没办法解决)这些问题也是DL面临的一个很大的挑战。
对于梯度的研究,近几年来也是提出了许许多多的方法。论文一开始综述了当前领域内对于Gradient的处理的种种角度:SGDM、Adam、BN、WN、WS…,并指出了各类方法存在的长短处。这里,把paper中综述的方法罗列一下:

脑图链接
对于梯度的处理,最原始的方法,也就是从训练数量的角度考虑有三种:
- SGD(随机梯度下降):每次采样一个训练样本进行反向传播。拟合速度快,但是震荡明显。
- BGD(批量梯度下降):每次采样一批训练样本,计算代价的平均反向传播。稳健,但是速度缓慢。
- MBGD(小批量梯度下降):前面两者的结合,每次采样小批量的样本训练。比较常用的一种。
从标准化的角度,可以标准化两个对象:网络激活值 、网络权重.
前者的方法主要有:Batch Normalize、Layer Normalize、Instance Normalize、Group Normalize。后者有Weight normalization、weight standardization。其中,BN和WN分别是这两个角度的代表:
- Batch Normalize(批量归一):通过对每一层的激活值进行归一化操作,例如均值、方差标准化,人为地引入噪音,使得模型训练更加平滑、鲁棒。但是比较依赖于Batch的大小,而且不适用于序列化的RNN,在计算的中间存储上开销过大。
- Weight normalization(权重标准化):讲模型的权重 W 解耦成两个重参数 n 、v 分别代表权重的大小和方向。这样在反向传播的过程中梯度将会被投射到与 W 近乎垂直的方向上,起到矫正和自我稳定的作用。具体细节可以参考下面这篇博客:
模型优化之Weight Normalization
另外一个角度,也是研究成果最为突出的就是优化算法。它经历了从Momentum --> RMSProp、AdaGrad --> Adam的转变。大致可以把优化算法归为三类:
- Momentum (一阶动量):利用物理上动量和惯性的思维,在计算梯度的时候引入动量因子 γ ,梯度有 γ 的比例保持之前下降的“速度”,1-γ 的比例施加当前真正的梯度作为“加速度”。直观上就是利用了用指数加权平均代替普通的平均值,让梯度产生类似于矢量震荡相消的效果。
- Adaptive(二阶动量):和Momentum 的思路一样,都是想让梯度变得更加平稳。只不过将动量平方得到二阶动量,如果说一阶是利用了矢量的相互作用,产生相悖抵消的话,二阶动量就是对梯度震荡大的维度施加了更多惩罚,可以看作是一种 标量数值削减。换个角度,如果把这个惩罚当成是施加在学习率α上的,震荡越剧烈,对应的学习率会被削减越多,所以二阶动量也可以理解成是一种自适应( Adaptive)学习率的方法。
- Adaptive+Momentum (一阶+二阶):如果说上述两种方法分别利用了矢量和标量来平滑梯度,那么类似于Adam、Nadam的优化算法就是将上述两个放到了一起,同时利用一阶动量、二阶动量,在某些任务上产生的效果明显更优。
有关于优化算法更多细节可以参考下面这篇博客:
一个框架带你看懂优化算法之异同
其他优化器包括AdamW等,详见这篇博客的整理:
优化方法总结
另外,其他一些方法,例如激活函数的选择(active functions),梯度修剪(gradient clipping)等都或多或少能够起到作用。
不管是上述哪种方法,归根结底都是为了能够让梯度下降变得更加顺利,或者说能够使得对梯度的处理能够更加地优雅。上述的方法都是在考虑如何使用梯度(优化算法),或者是如何避免梯度出现问题(标准化),而梯度中心化则直接把问题的矛头指向了梯度本身,也就是对于模型计算出来的梯度,考虑能不能先进行一些处理,再进行接下来的各种操作,能够让下游的工作变得更加顺利?
因此,梯度中心化说白了,就是在把梯度喂给下游优化器之前,先对其进行一步中心化,使得模型的权重得到规范化,因此它可以看作是一种对梯度的预处理。
2.公式
paper随后用了很少的篇幅把Gradient Centralization数学上的表达过了一遍。Gradient Centralization的核心就一个函数 :

∇wiL 表示的是梯度,下标 i 代表这个是梯度矩阵里第 i 列的列向量,公式里的 µ∇wiL 的计算公式如下:

上面这两个公式的含义很简单,对于每一个梯度矩阵的第 i 列向量 ∇wiL,求出这个列向量中每个元素的平均值 µ∇wiL ,最后把这个均值从列向量中剔除,对每个列向量都进行这样的一步中心化,得到中心化之后的梯度矩阵。
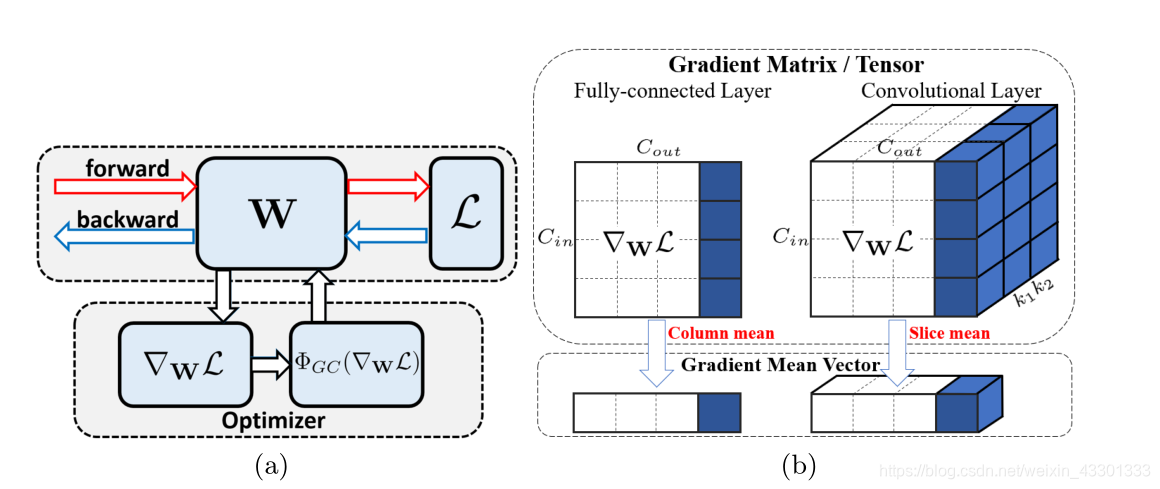
梯度 ∇wL 就是经过这样一层预处理,之后再进行backward的,下图(a)就是为了说明这点。(b)图是梯度中心化在全连接层和卷积层产生效果的可视化,其含义就是对梯度矩阵的每一个列向量剔除了均值。
这一步看起来让人匪夷所思,应该说是简单地让人一头雾水。它为什么可以带来平滑模型的效果呢?它的原理又是怎样的?
3.原理解析
首先把上面这两个公式再重新写一遍;
由于参数 µ∇wiL 表示的是列方向上的均值,因此根据矩阵的运算原理,可以把上面的两个公式合并之后,提出一个因子 P ,写成更加简洁的矩阵运算的形式:

假设梯度矩阵形状是M * M的,上面公式里的 P 代表一个和梯度矩阵形状一致的矩阵。其计算如下:

I 代表M * M单位矩阵,e 则是一个M * 1的单位向量,单位向量范数为1,因此 e 中每个元素大小都为 1/√M 。
而之所以要把 P 单独从公式里挑出来,是因为 P 这个矩阵背后有着很好的性质和含义。
paper里采用了两种角度来解释 P 的作用。
3.1 权重空间规范化(Weight space regularization)
首先观察一下 P 的定义:单位矩阵和单位向量的线性组合,直观上就可以察觉到 P 是一个对称矩阵。而且根据矩阵乘法的性质,可以得到结论:

另外,P 还具有另外一个很重要的性质:

上面这个公式也可以很简单地得到证明,那么就可以自然的得到下面这个结论:

如果把等式左边三个成分中 P ∇WL 看作是一个整体,那么其表示的含义就是 P ∇WL 必定存在于一个和 e 正交的平面内,而这都是拜 P 所赐,因为 P 本身具有的性质就是和 e正交。这时候再把P 和 ∇WL 拆开,P ∇WL 就可以看成梯度矩阵 ∇WL 在 P 所在平面上的投射。
完整的一句话就是:P 是一个中间矩阵,它代表了一个和单位向量 e 正交的平面,P ∇WL 就是将梯度投射到了这个超平面上。
而这个特性带来的好处是显而易见的。假设当前已经执行了 t 次梯度下降的迭代,每次迭代均使用了梯度中心化的方法处理,Wt 表示第t个时间步的权重,W 看作是初始权重,为了便于理解,直接把高维的权重 Wt 和 W 看成是向量。根据我们上面得到的结论,可以知道:

也就是说对于任何一个时间步 t ,其权重的变化空间将会一直滞留在这个超平面上。paper里面的配图可以很直观地体现这一点:

正是由于P ∇WL 把梯度投射到了与e正交的超平面,使得我们每次迭代更新的梯度都是这样一个特定空间内的张量,梯度逃不出这个超平面,权重 W 自然也就会永远滞留在这个平面内,而不是四面八方乱跑乱窜,大大提升了梯度下降的稳定性。
所以paper里面形容,梯度中心化给目标函数加了一层隐含的限制(latent objective function),能够起到规范化解空间的作用,因为解——也就是模型权重 W 永远都逃不出这个超平面。
3.2 输出空间规范化(Output feature space regularization)
梯度中心化的另一个好处就是可以让输出变得更加稳定、鲁棒。假设现在进行第 t+1 轮梯度的更新,如果采用梯度中心化可以写出下面这个式子:

把t 个时间步展开,再提出 P :

而且我们已知 P 具有下面的性质:

这里假设此时输入的特征向量为 X 和 X + γ1,代表输入在 γ1 这个常数的范围内震荡,为了能够体现模型对于具有γ1浮动输入的适应能力,我们可以让这两个输入经过模型运算之后做一个差值,那么就有下面的推理:

最终可以得到结论:

也就是说,如果采用了梯度中心化的方法,那么对于具有γ1震荡程度的输入X,输出的震荡程度将只与γ1和初始W0有关,而与任何一个时间步的梯度无关。由于将W0标准化为0均值是一件非常简单的事情,因此采用了梯度中心化,某种意义上挖掘了权重初始化的效益。而这也就给了模型很好的鲁棒性和抗干扰能力。
4. 总结
论文提出了一种纯数学上的优化方法,实现简单的同时具有很好的理论证明,个人觉得这也是paper的优势之一。有关于作者是怎么想出列向量剔除均值这一灵感的,个人猜测最初的灵感应该也是从超平面投射这个角度出发的,BN、WS也有类似的概念在,而且有关于这方面理论其实之前很多工作都做过铺垫。总之,tool box里多了这样一个小器件未尝不是一件好事。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









