







栈 Stack
原文链接:https://www.yuque.com/huoxiangshouxiangwanghuo/ndi0dn/ga5z53
栈(Stack)
栈的基本概念
栈的定义
栈(stack)是简单的数据结构,但在计算机中使用很广泛,它的定义很简单:只允许在一端进行插入或删除操作的线性表,所以首先栈是一种线性表,其次栈限定只能在某一端进行插入和删除操作。

我们来举一个形象的例子,当我们往箱子里放一叠书的时候,先放的书在箱子最下面,后放的书在箱子上面,当我们拿书的时候,必须将后面放的书都取出来,才能看到或者拿出前面放的书。假如这个箱子的平面面积只能容纳一本书,并且所有书的面积也完全契合箱子的平面面积,放书的时候只能平着放,不能竖着放(程序员考虑的问题就比较多),那么我们就可以把这个箱子看成一个栈
接下来我们给几个定义:
- 栈顶(Top):允许进行插入删除操作的一端,也即是箱子的顶部;
- 栈底(Bottom):固定并且不允许进行插入和删除操作的一端,也就是箱子的底部;
- 空栈:不含有任何元素的空表。
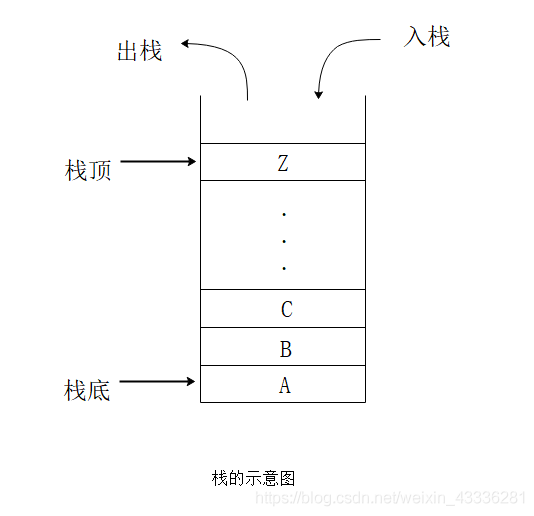
比如我们有这么一个栈,A就是最先入栈的栈底元素,Z就是最后入栈的栈顶元素,因为栈只能在栈顶进行插入和删除操作,所以进栈的顺序为A,B,C,……,Z,出栈的顺序为Z,Y,X,……,A。栈的操作特性可以概括为后进先出(Last In First Out,LIFO)。
进出栈的元素具有一个数学性质:n个不同元素进栈,出栈元素的不同排列个数为
1
n
+
1
C
2
n
n
\frac{1}{n+1}C\ ^{n}_{2n}
n+11C 2nn,被称为卡特兰(Catalan)数。
栈的基本操作
栈具有以下这些基本操作:
- init:初始化一个空栈;
- empty:判断一个栈是否为空,若为空返回true,否则返回false;
- push(x):进栈,若栈未满则将x加入并使之成为新栈顶;
- pop():出栈,若栈非空则弹出栈顶元素;
- top():访问栈顶元素;
- destroy:销毁栈并释放栈占用的存储空间
算法实现
自实现
class Stack{
private:
int num; // 栈容量
int idx; // 栈顶指针
int* data; // 栈中元素
public:
Stack(int n) {
this->num = n;
this->idx = -1;
this->data = new int[n];
}
~Stack() {
delete [] this->data;
}
bool empty() {
return this->idx == -1;
}
bool full() {
return this->idx == this->num - 1;
}
void push(int x) {
if (this->full()) {
cout << "over flow" << endl;
return;
}
this->data[++this->idx] = x;
}
void pop() {
if (this->empty()) {
cout << "under flow" << endl;
return;
}
this->idx--;
}
int top() {
if (this.empty()) {
cout << "under flow" << endl;
return;
}
return this->data[this->idx];
}
};
STL
C++的STL已经帮我们通过容器适配器(container adaptors)实现好了一个功能完善的栈结构,它使用的是特定容器类的封装对象作为底层容器,并且提供了一组特定的成员函数来访问其元素。
- top():返回一个栈顶元素的引用,类型为 T&。如果栈为空,返回值未定义。
- push(const T& obj):可以将对象副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。
- push(T&& obj):以移动对象的方式将对象压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。
- pop():弹出栈顶元素。
- size():返回栈中元素的个数。
- empty():在栈中没有元素的情况下返回 true。
- emplace():用传入的参数调用构造函数,在栈顶生成对象。
- swap(stack & other_stack):将当前栈中的元素和参数中的元素交换。参数所包含元素的类型必须和当前栈的相同。对于 stack 对象有一个特例化的全局函数 swap() 可以使用。
#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<int> intStack;
stack<float> floatStack;
stack<string> stringStack;
intStack.push(1);
intStack.push(2);
intStack.push(3);
while (!intStack.empty()) {
cout << intStack.top() << " ";
intStack.pop();
}
cout << endl;
for (int i = 0; i < 7; i++) {
intStack.push(i);
}
cout << "intStack top = " << intStack.top() << endl;
cout << "intStack size = " << intStack.size() << endl;
return 0;
}
升级操作
链栈
采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,而且不存在栈满上溢的情况。链栈通常采用单链表实现,并规定其所有操作都是在单链表的表头进行的。这里规定链栈没有头结点,head指向栈顶元素。

链表的头部作为栈顶,意味着:
- 在实现数据"入栈"操作时,需要将数据从链表的头部插入;
- 在实现数据"出栈"操作时,需要删除链表头部的首元节点;
共享栈
利用栈底位置不变的特性,我们可以让两个顺序栈共享同一片存储空间,这片存储空间不单独属于任何一个栈,某个栈需要的多一点,它就可能得到更多的存储空间,两个栈的栈底分别设置在共享空间的两端,栈顶向共享空间 的中间延伸。

两个栈的栈顶指针都指向栈顶元素,top1=-1时1号栈为空,top2=MaxSize时2号栈为空,当两个栈顶指针相邻,即top2-top1=1时,判断为栈满。

1号栈进栈时top1先+1再赋值,2号栈进栈时top2先-1再赋值,出栈则正好相反。
class ShareStack {
private:
int num; // 栈容量
int idx1; // 1号栈顶指针
int idx2; // 2号栈顶指针
int* data; // 栈中元素
public:
ShareStack(int n) {
this->num = n;
this->idx1 = -1;
this->idx2 = n;
this->data = new int[n];
}
~ShareStack() {
delete [] this->data;
}
bool s1Empty() {
return this->idx1 == -1;
}
bool s2Empty() {
return this->idx2 == this->num;
}
bool full() {
return this->idx2 - this->idx1 == 1;
}
void s1Push(int x) {
if (this->full()) {
cout << "over flow" << endl;
return;
}
this->data[++this->idx1] = x;
}
void s2Push(int x) {
if (this->full()) {
cout << "over flow" << endl;
return;
}
this->data[--this->idx2] = x;
}
void s1Pop() {
if (this->s1Empty()) {
cout << "under flow" << endl;
return;
}
this->idx1--;
}
void s2Pop() {
if (this->s2Empty()) {
cout << "under flow" << endl;
return;
}
this->idx2++;
}
int s1Top() {
if (this->s1Empty()) {
cout << "under flow" << endl;
return -1;
}
return this->data[this->idx1];
}
int s2Top() {
if (this->s2Empty()) {
cout << "under flow" << endl;
return -1;
}
return this->data[this->idx2];
}
};
共享栈是为了更有效地利用存储空间,两个栈的空间相互调节,只有在整个存储空间被占满时才发生上溢。共享栈存取数据的时间复杂度为O(1),所以对存取效率没有什么影响。
单调栈
单调栈实际上就是栈,只是利用了一些巧妙的逻辑,使得每次新元素入栈后,栈内的元素都保持有序(单调递增或单调递减)。单调栈用途不太广泛,只处理一种典型的问题,叫做 Next Greater Element。
LeetCode:496. 下一个更大元素 I
给你两个数组:nums1和nums2,返回一个与nums1等长的数组,对应索引存储着当前元素在nums2中下一个更大元素,如果没有更大的元素,就存 -1。
那么什么是下一个更大的元素呢?比如说,我们只有一个输入数组 nums = [2,1,2,4,3],数组元素对应的下一个更大的元素是 [4,2,4,-1,-1]。
解释:第一个 2 后面比 2 大的数是 4; 1 后面比 1 大的数是 2;第二个 2 后面比 2 大的数是 4; 4 后面没有比 4 大的数,填 -1;3 后面没有比 3 大的数,填 -1。
暴力的解法很好想到,就是对每个元素后面都进行扫描,找到第一个更大的元素就行了。但是暴力解法的时间复杂度是 O(n^2)。
这个问题可以这样抽象思考:把数组的元素想象成并列站立的人,元素大小想象成人的身高。这些人面对你站成一列,如何求元素「2」的 Next Greater Number 呢?很简单,如果能够看到元素「2」,那么他后面可见的第一个人就是「2」的 Next Greater Number,因为比「2」小的元素身高不够,都被「2」挡住了,第一个露出来的就是答案。
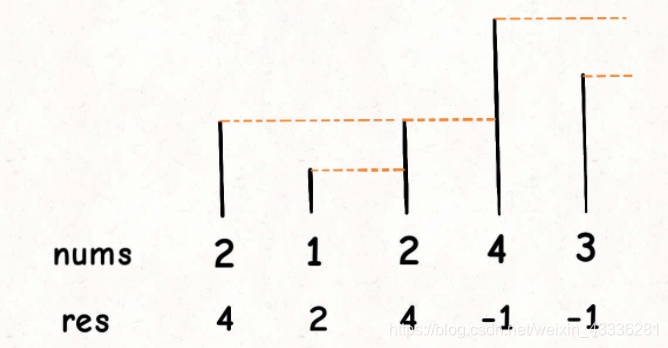
这个情景很好理解吧?输入两个数组,其实可以分段处理,首先忽略nums1,先求出nums2中的每个元素对应的下一个更大的元素,然后将这些元素放入hash map中,再遍历nums1,就能直接找出答案了。
带着这个抽象的情景,先来看下代码。
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int> s;
map<int, int> record;
for (int i = 0; i < nums2.size(); i++) {
while (!s.empty() && nums2[i] > nums2[s.top()]) {
record[nums2[s.top()]] = nums2[i];
s.pop();
}
s.push(i);
}
vector<int> ans;
for (int i = 0; i < nums1.size(); i++) {
auto ret = record.find(nums1[i]);
if (ret != record.end()) {
ans.push_back(ret -> second);
} else {
ans.push_back(-1);
}
}
return ans;
}
};
第一段就是单调栈解决问题的模板,for 循环要从前往后扫描元素,如果后来的数比栈顶数大,说明找到了下一个更大的数,否则就就绪维护一个单调递减的序列。
这个算法的时间复杂度不是那么直观,如果你看到 for 循环嵌套 while 循环,可能认为这个算法的复杂度也是 O(n^2),但是实际上这个算法的复杂度只有 O(n)。
分析它的时间复杂度,要从整体来看:总共有 n 个元素,每个元素都被 push 入栈了一次,而最多会被 pop 一次,没有任何冗余操作。所以总的计算规模是和元素规模 n 成正比的,也就是 O(n) 的复杂度。
同样是 Next Greater Number,现在假设给你的数组是个环形的,如何处理?力扣第 503 题「下一个更大元素 II」就是这个问题:
LeetCode:503. 下一个更大元素 II
比如输入一个数组 [2,1,2,4,3],你返回数组 [4,2,4,-1,4]。拥有了环形属性,最后一个元素 3 绕了一圈后找到了比自己大的元素 4。我们一般是通过 % 运算符求模(余数),来获得环形特效。
这个问题肯定还是要用单调栈的解题模板,但难点在于,比如输入是 [2,1,2,4,3],对于最后一个元素 3,如何找到元素 4 作为 Next Greater Number。
对于这种需求,常用套路就是将数组长度翻倍:
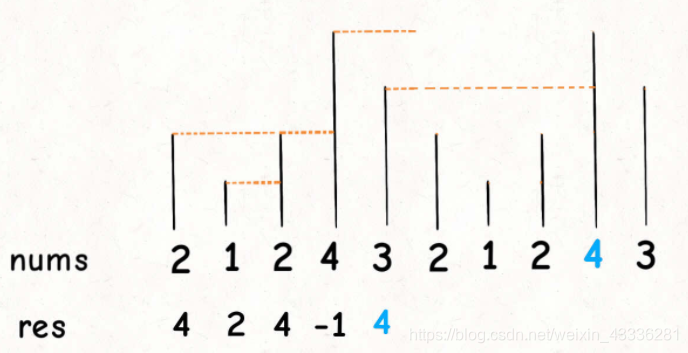
这样,元素 3 就可以找到元素 4 作为 Next Greater Number 了,而且其他的元素都可以被正确地计算。
有了思路,最简单的实现方式当然可以把这个双倍长度的数组构造出来,然后套用算法模板。但是,我们可以不用构造新数组,而是利用循环数组的技巧来模拟数组长度翻倍的效果。
直接看代码吧:
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
stack<int> s;
int n = nums.size();
vector<int> res(n, -1);
for (int i = 0; i < 2 * n; i++) {
while (!s.empty() && nums[s.top()] < nums[i % n]) {
res[s.top()] = nums[i % n];
s.pop();
}
s.push(i % n);
}
return res;
}
};
这样,就可以巧妙解决环形数组的问题,时间复杂度 O(N)。
练习题
- 设链表不带头结点,且所有操作均在表头进行,则下列最不适合作为链栈的链表是( C )。
A.只有表头结点指针,没有表尾指针的双向循环链表
B.只有表尾结点指针,没有表头指针的双向循环链表
C.只有表头结点指针,没有表尾指针的单向循环链表
D.只有表尾结点指针,没有表头指针的单向循环链表
解析: 对于双向训练链表,不管是表头指针还是表尾指针,都可以很方便地找到表头节点,方便在表头做插入或删除操作。单向循环链表通过尾指针可以很方便地找到表头节点,但通过头指针找尾节点需要遍历一次链表。对于C,插入和删除节点后,找尾节点需要花费O(n)的时间。
**
- 向一个栈顶指针为top的链栈中插入一个x结点,则执行( C )。
A. top->next=x B. x->next=top->next; top->next=x
C. x->next=top; top=x D. x->next=top, top=top->next
解析: 链栈釆用不带头结点的单链表表示时,进栈橾作在首部插入一个结点x(即x->next=top),插入完后需将top指向该插入的结点X。
- 链栈执行Pop操作,并将出栈的元素存在x中应该执行( D )。
A. x=top; top=top->next B.x=top->data
C. top=top->next; x=top->data D. x=top->data; top=top->next
解析: 这里假设栈顶指针指向的是栈顶元素,所以选D;而A中首先将top指针赋给了 x,错误;B中没有修改top指针的值;C为top指针指向栈顶元素的上一个元素时的答案。
- 若一个栈的输入序列是1, 2,3, …, n,输出序列的第一个元素是n,则第i个输出元素是( D )。
A.不确定 B. n-i C. n-i-1 D. n-i+1
解析: 第n个元素先出栈,说明前n-1个元素都已经按顺序入栈,由“先进后出”的特点可知,此时的输出序列一定是输入序列的逆序,故答案选D。
- 一个栈的输入序列为1, 2, 3, …, n,输出序列的第一个元素是i,则第j个输出元素是( D )。
A, i-j-1 B. i-j C. j-i+1 D.不确定
解析: 当第i个元素第一个出栈时,则i之前的元素可以依次排在i之后出栈,但剩余的元素可以在此时进栈并且也会排在i之前的元素出栈,所以,第j个出栈的元素是不确定的。
- 若已知一个栈的入栈序列是1,2,3,…,n,其输出序列为 p1 , p2 , p3 ,…, pn ,若p2=3,则p3为可能取值的个数是( C )。
A. n-3 B. n-2 C.n-1 D.无法确定
解析: 显然,3之后的4, 5, …, n都是P3可取的数。P1可是3之前入栈的数(1、2),也可以是4,:
(1)当P1=1时,P3可取2;
(2)当P1=2时,P3可取1;
(3)当P1=4时,P3可取除1、3、4之外的所有数。
所以P3可能的取值个数为n-1。
- 设单链表的表头指针为h,结点结构由data和next两个域构成,其中data域为字符型。试设计算法判断该链表的前n个字符是否中心对称。例如xyx、xyyx都是中心对称。
使用栈来判断链表中的数据是否中心对称。将链表的前一半元素依次进栈。在处理链表的后一半元素时,当访问到链表的一个元素后,就从栈中弹出一个元素,两个元素比较,若相等,则将链表中下一个元素与栈中再弹出的元素比较,直至链表到尾。这时若栈是空栈,则得出链表中心对称的结论;否则,当链表中的一个元素与栈中弹出元素不等时,结论为链表非中心对称,结束算法的执行。
int dc(LinkList L, int n) {
char s[n/2]; // 字符栈
int i = 1; // 记结点个数
P = L -> next; // 是链表的工作指针,指向待处理的当前元素
for{i = 0; i < n / 2; i++) { //链表前一半元素进栈
s[i] = p -> data;
p = p -> next;
}
i--; // 恢复最后的i值
if(n % 2 == 1) // 若n是奇数,后移过中心结点
p=p->next;
while(p != NULL && s[i] == p->data) { //检测是否中心对称
i--;
p = p -> next;
}
if (i == -1) // 桟为空栈
return 1; // 链表中心对称
else
return 0; // 链表不中心对称
}
算法先将“链表的前一半”元素(字符)进栈。当n为偶数时,前一半和后一半的个数相同;当n为奇数时,链表中心结点字符不必比较,移动链表指针到下一字符开始比较。比较过程中遇到不相等时,立即退出while循环,不再进行比较。
OK,栈的基本内容就讲完啦。















 3625
3625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











