







目录
PROBLEM
现有工作不能充分注意到不同items与用户主要兴趣的相关性.
SOLUTION
同时考虑当前session用户的长短期偏好,应用修正的自监督机制评估item在当前session的重要性,以预测用户的长期偏好,短期偏好则由当前session最后交互item表示.
APPROACH
Framework
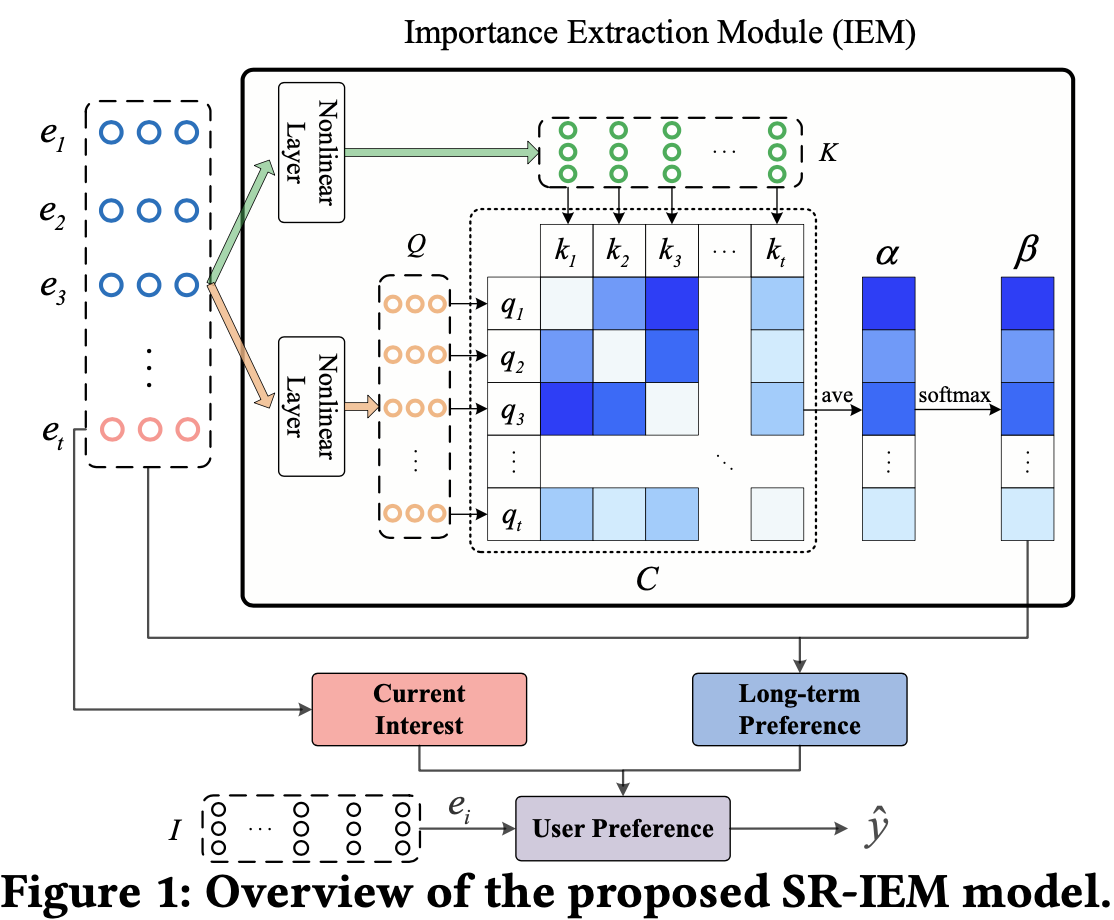
Importance extraction
将item embedding
E
=
{
e
1
,
e
2
,
…
,
e
t
}
E=\{e_1,e_2,\dots,e_t\}
E={e1,e2,…,et}通过非线性函数转换到不同空间以生成
q
u
e
r
y
Q
query \ Q
query Q和
k
e
y
K
key \ K
key K:
Q
=
sigmoid
(
W
q
E
)
,
K
=
sigmoid
(
W
k
E
)
(1,2)
\begin{aligned} Q&=\text{sigmoid}(W_qE), \\ K&=\text{sigmoid}(W_kE) \tag{1,2} \end{aligned}
QK=sigmoid(WqE),=sigmoid(WkE)(1,2)
其中
W
q
E
∈
R
d
×
l
W_qE \in \mathbb{R}^{d \times l}
WqE∈Rd×l和
W
k
E
∈
R
d
×
l
W_kE \in \mathbb{R}^{d \times l}
WkE∈Rd×l是可训练的参数,
l
l
l是注意力机制的维度.
通过引入
q
u
e
r
y
Q
query \ Q
query Q和
k
e
y
K
key \ K
key K的关联矩阵
C
C
C计算每两个item间的相似度:
C
=
sigmoid
(
Q
K
T
)
d
(3)
C=\frac{\text{sigmoid}(QK^T)}{\sqrt{d}} \tag{3}
C=dsigmoid(QKT)(3)
将session内一个item和其他items间的平均相似度作为该item重要性,为避免
q
u
e
r
y
Q
query \ Q
query Q和
k
e
y
K
key \ K
key K相同向量的高匹配得分,采取将关联矩阵
C
C
C的对角元素mask的操作,则每个item
i
i
i的重要性得分
α
i
\alpha_i
αi:
α
i
=
1
t
∑
j
=
1
,
j
≠
i
t
C
i
j
(4)
\alpha_i=\frac{1}{t}\sum_{j=1,j \ne i}^{t}C_{ij} \tag{4}
αi=t1j=1,j=i∑tCij(4)
其中
C
i
j
∈
C
C_{ij} \in C
Cij∈C.
归一化得分,最终当前session的items的重要性表示为:
β
=
softmax
(
α
)
(5)
\beta=\text{softmax}(\alpha) \tag{5}
β=softmax(α)(5)
Preference fusion
用户长期偏好表示:
z
l
=
∑
i
=
1
t
β
i
e
i
(6)
z_l=\sum_{i=1}^t \beta_i e_i \tag{6}
zl=i=1∑tβiei(6)
用户短期偏好由最后一个item表示,即
z
s
=
e
t
z_s=e_t
zs=et.
用户最终偏好表示:
z
h
=
W
0
[
z
l
;
z
s
]
(7)
z_h=W_0[z_l;z_s] \tag{7}
zh=W0[zl;zs](7)
其中
W
0
∈
R
d
×
2
d
W_0 \in \mathbb{R}^{d \times 2d}
W0∈Rd×2d将拼接表示从
R
2
d
\mathbb{R}^{2d}
R2d转换到
R
d
\mathbb{R}^d
Rd.
Item recommendation
对于每一item
v
i
v_i
vi,用户的偏好得分为:
z
i
^
=
z
h
T
e
i
(8)
\hat{z_i}=z_h^Te_i \tag{8}
zi^=zhTei(8)
归一化得分:
y
^
=
softmax
(
z
^
)
(9)
\hat{y}=\text{softmax}(\hat{z}) \tag{9}
y^=softmax(z^)(9)
交叉熵作为优化目标:
L
(
y
^
=
−
∑
i
=
1
n
y
i
log
(
y
^
i
)
+
(
1
−
y
i
)
log
(
1
−
y
^
i
)
(10)
L(\hat{y}=-\sum_{i=1}^ny_i\log (\hat{y}_i)+(1-y_i)\log (1- \hat{y}_i) \tag{10}
L(y^=−i=1∑nyilog(y^i)+(1−yi)log(1−y^i)(10)
EXPERIMENTS
Overall performance
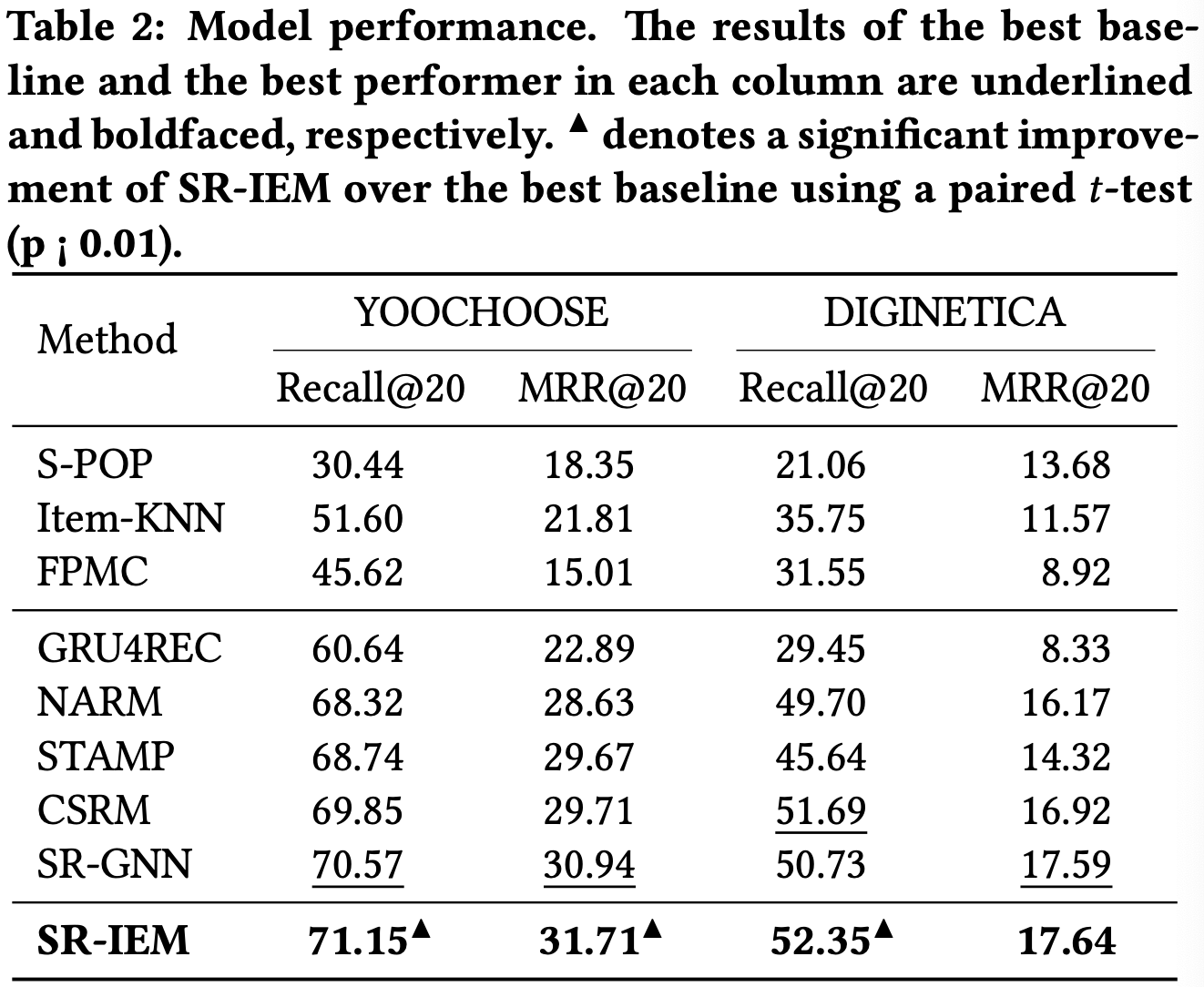
Impact of session length
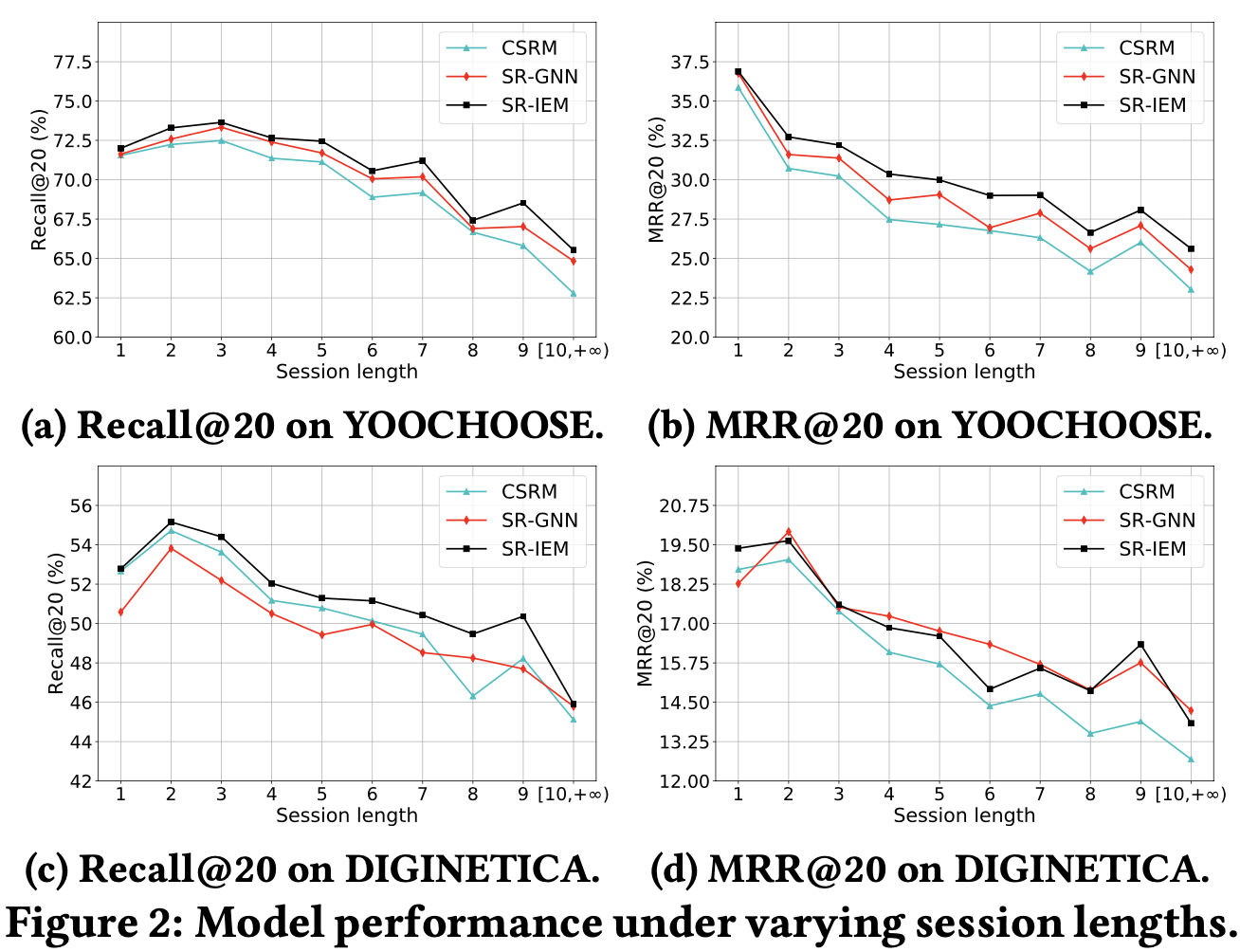
Analysis on importance extraction module















 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









