






1 介绍
第二章介绍了如何创建自定义函数并调用自定义函数,这些函数可以集成为模块,模块集成为程序包。Arcpy便是程序包。
同时还介绍了如何自定义类class,通过学习自定义函数与类,可以编写更加复杂的程序。
2 函数与模块
函数是执行特定任务的代码块。 Python 包含许多内置函数,例如 help()、int()、print() 和 str()。大多数函数需要一个或多个参数,作为函数的输入。
使用函数称为调用函数。当你调用一个函数时,你给它提供了参数。考虑 print() 函数:
name = "Paul"
print(name)
print的参数为变量name
函数的结构为:
<function>(<arguments>)
包括函数名与参数,python内置了一些函数,可以进行查看:https://docs.python.org/3/library/functions.html
也可以从其他模块导入函数,通常一个模块包含多个函数。使用后import导入模块,一般的语法结构为:
import <module>
例如下面的代码使用“random”这个模块中的函数randrange,生成一个1到99的随机数
import random
random_number = random.randrange(1, 100)
print(random_number)
生成随机数的代码等已经被发布于python社区中,所以我们很多时候不需要自己写代码,需要理解自己的逻辑,然后copy代码。
现在最经常使用的模块是os模块,该模块与操作系统相关的功能。例如:os.mkdir() 函数在当前工作目录中创建一个新文件夹
import os
os.mkdir("test")
非内置函数,需要从模块导入的函数的语法结构一般如下:
import <module>
<module>.<function>(<arguments>)
必须通过import导入模块后,才能调用模块中的函数,有的函数还需要参数。
在为arcgis pro编写脚本工具时,可以使用arcpy访问arcgis pro中已经有的功能,arcpy作为程序 包,包含了多个模块、函数与类,所以在进行地理处理时,需要import arcpy。
例如可以使用arcpy中的Exists()函数确定要素类是否存在,并返回True或False。
import arcpy
print(arcpy.Exists("C:/Data/streams.shp"))
上面的代码也遵循了上面提到的语法结构,导入模块后,再调用函数并且添加了参数。
ArcPy 包括几个模块,包括数据访问模块 arcpy.da,用于描述数据、执行编辑任务和跟踪数据库的工作流。 da.Describe() 函数确定数据集的类型,以及数据集的几个属性。
例如,以下代码确定 shapefile 的几何形状类型:
import arcpy
desc = arcpy.da.Describe("C:/Data/streams.shp")
print(desc["shapeType"])
使用arcpy的一般语法结构如下:
arcpy.<module>.<function>(<arguments>)
在前面的示例代码中,Describe() 是 arcpy.da 模块的函数。
当引用一个函数时,引用它所属的模块很重要。例如,ArcPy 还包含一个 Describe() 函数。所以 arcpy.Describe() 和 arcpy.daDescribe() 都是有效的函数,但它们的工作方式不同。关于不同前一本书中也讲过了,具体可以看链接:
http://t.csdn.cn/7hmob中的第三节,描述数据的介绍
3 自定义函数
使用def关键字对函数进行定义,需要定义函数的名称或名称+参数。
def <functionname>(<arguments>):
在上面的定义语句最后,是有一个冒号,然后冒号回车后的代码要保持缩进,缩进的代码块是具体的定义。
例如下面的一个自定义函数:
def printmessage():
print("Hello world")
这个函数printmessage没有定义参数,所以可以直接调用,有的函数需要使用参数来传递值并调用。
函数定义后并不会被立即执行,只有调用或传参调用后,才会被执行。
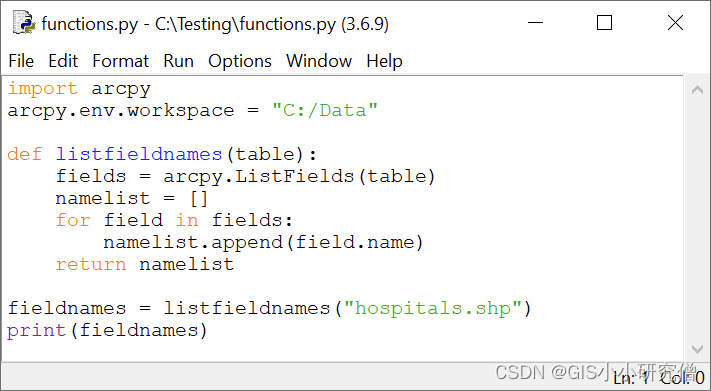
通产,自定义函数的功能会比上面复杂多,可以参考以下示例:创建一个表或要素类中所有field名称的列表。在arcpy中没有现成的函数,逻辑上是使用ListFields函数在表中创建field列表,然后使用for遍历列表获取字段名称,名称列表可以存储在列表对象中。
import arcpy
arcpy.env.workspace = "C:/Data"
fields = arcpy.ListFields("streams.shp")
namelist = []
for field in fields:
namelist.append(field.name)
关于ListFields函数详细的介绍在本专栏 6、空间数据探索 章节中第四节有详细介绍。
假设经常在同一个脚本或其他脚本中使用这些代码行。可以简单地复制代码行,将它们粘贴到需要的地方,然后进行任何必要的更改,需要将参数“streams.shp”替换为感兴趣的要素类或表。
但更好的是创建一个自定义函数来执行相同的步骤,而不是复制和粘贴整个代码。首先,您必须为函数命名,例如 listfieldnames()。
def listfieldnames():
现在可以按名称从脚本中的其他位置调用该函数。在此示例中,调用函数时,希望将值传递给函数,即表或要素类的名称。因此函数必须包含一个参数来接收这些值。
def listfieldnames(table):
def 语句后面是一个缩进的代码块,其中包含函数的作用。 <is 代码块与前面的代码行相同,但现在将要素类的硬编码值替换为函数的参数,如下所示:
def listfieldnames(table):
fields = arcpy.ListFields(table)
namelist = []
for field in fields:
namelist.append(field.name)
这个函数中没有硬编码值。 缺乏硬编码是自定义函数的典型特征,因为您希望函数可在其他脚本中重用。
最后需要的是函数传回值的方法,也称为返回值。返回值可确保该函数不仅创建名称列表,而且还返回该列表,以便任何调用该函数的代码都可以使用它。这里是使用 return 语句完成的。 完整的功能描述如下:
def listfieldnames(table):
fields = arcpy.ListFields(table)
namelist = []
for field in fields:
namelist.append(field.name)
return namelist
函数被定义后,可以在其他脚本中被调用。
fieldnames = listfieldnames("C:/Data/hospitals.shp")
运行代码会使用之前 定义的函数返回表或要素类中的 字段 名称列表。新函数 listfieldnames() 可以直接调用,因为它在同一脚本中被定义了。
一个重要方面是自定义函数 相对于调用该函数的代码的位置。 **自定义函数只有在 定义后才能调用。
先定义后调用的原则
import arcpy
arcpy.env.workspace = "C:/Data"
def listfieldnames(table):
fields = arcpy.ListFields(table)
namelist = []
for field in fields:
namelist.append(field.name)
return namelist
fieldnames = listfieldnames("hospitals.shp")
print(fieldnames)
通常,还会在代码段落中添加空行,增强可读性
示例函数使用一个名为 table 的参数,它可以将值传递给函数。一个函数可以使用多个参数,并且参数可以是可选的。 参数应排序,以便列出所需的first,然后是可选的。通过指定默认值,参数是可选的。
自定义函数可用于许多其他任务,包括使用几何对象。
接下来,解释一个示例脚本,然后将其转换为自定义函数。示例脚本计算代表河段的每个折线要素的曲折指数。在这种情况下,弯曲度被定义为表示河流段的折线的长度除以折线的 第一个和最后一个顶点之间的直线距离。相对笔直的线段具有接近 1 的弯曲度指数,而曲折线段具有更高的值,最高可达 1.5 或 2。计算可以通过使用折线对象的属性来完成,即长度、firstPoint 和 lastPoint。打印要素类中每个折线要素的弯曲度指数的脚本如下:
import arcpy
import math
arcpy.env.workspace = "C:/Data/Hydro.gdb"
fc = "streams"
with arcpy.da.SearchCursor(fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
oid = row[0]
shape = row[1]
channel = shape.length
deltaX = shape.firstPoint.X - shape.lastPoint.X
deltaY = shape.firstPoint.Y - shape.lastPoint.Y
valley = math.sqrt(pow(deltaX, 2) + pow(deltaY, 2))
si = round(channel / valley, 3)
print(f"Stream ID {oid} has a sinuosity index of {si}")
对脚本如何工作的简要说明是有序的。搜索光标用于获取唯一 ID 和每条折线的几何形状。 几何的长度属性表示折线的长度。 折线的 第一个和最后一个顶点之间的直线距离是使用几何的 firstPoint 和 lastPoint 属性计算的,它们返回一个 Point 对象。 这些顶点的 x,y 坐标用于根据勾股定理计算距离。
将两个距离分开以获得弯曲度指数,为了显示目的,将值四舍五入到小数点后三位。
脚本的结果是每个段的弯曲指数的打印输出。

计算弯曲度指数需要几行代码,这些代码可能在其他地方有用,并且此代码适用于自定义函数。自定义函数接收几何对象并返回弯曲度指数。
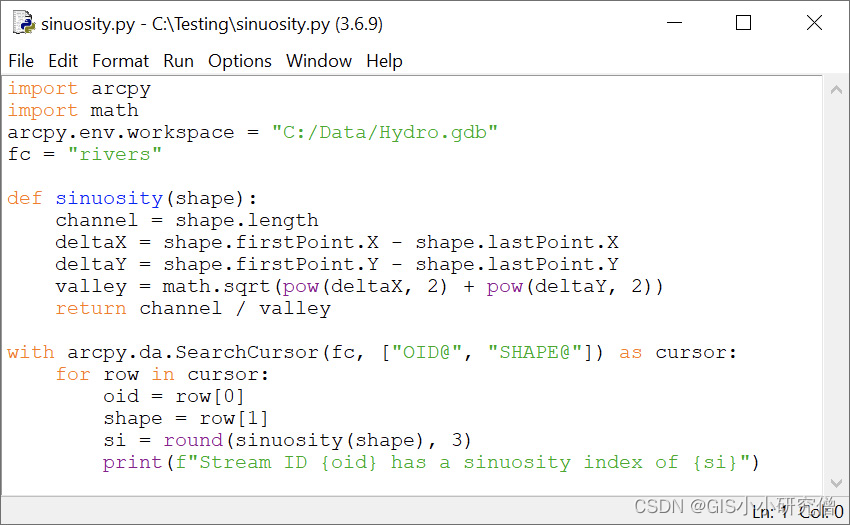
使用自定义函数的脚本如下:
import arcpy
import math
arcpy.env.workspace = "C:/Data/Hydro.gdb"
fc = "streams"
def sinuosity(shape):
channel = shape.length
deltaX = shape.firstPoint.X - shape.lastPoint.X
deltaY = shape.firstPoint.Y - shape.lastPoint.Y
valley = math.sqrt(pow(deltaX, 2) + pow(deltaY, 2))
return channel / valley
with arcpy.da.SearchCursor(fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
oid = row[0]
shape = row[1]
si = round(sinuosity(shape), 3)
print(f"Stream ID {oid} has a sinuosity index of {si}")
这个自定义函数称为 sinuosity(),唯一的参数是称为 shape 的几何对象。调用函数时,将几何对象传递给函数,并将索引作为值返回。
这个脚本使用 round() 函数返回四舍五入到指定小数位数的涂层点数。以这种方式舍入的唯一问题是任何尾随零都被丢弃 - 例如,1.300 打印为 1.3。另一种方法是使用格式代码来自定义打印格式。定义后的两行脚本使用的格式代码如下:
si = sinuosity(shape)
print(f"Stream ID {oid} has a sinuosity index of {si:.3f}")
这里的格式代码.3f 表示使用带有三位小数的涂层点编号格式化输出。 这个 格式的类型也适用于进行四舍五入 - 例如,数字 1.4567 被格式化为 1.457。
同样,通常在代码块周围添加空行,以提高可读性。
创建函数有多种好处: 如果要多次使用任务,创建函数可以减少您必须编写和管理的代码量。 执行任务的实际代码仅作为函数编写一次;从那时起,您可以根据需要调用此自定义函数。
创建函数可以减少多次迭代造成的混乱。例如,如果您想为工作空间列表中的所有地理数据库中的所有要素类创建 字段名称列表,它将快速创建一组相对复杂的嵌套 for 循环。使用创建字段 名称列表的函数会删除其中一个 for 循环并将其放置在单独的代码块中。
复杂的任务可以分解成更小的步骤。通过将每一步都分解为一个函数,复杂的任务不再显得那么复杂。精心设计的函数是组织较长脚本的好方法。
自定义函数不仅可以直接从同一个脚本调用,也可以从其他脚本调用,下一节将介绍。
20220702学习总结:
这一章前几节讲的内容都很简单,以前虽然没有使用过自定义函数,但是在arcgis中进行过很简单的自定义函数,写一个重分类的自定义函数,把不同范围i的值重新定义为一个值,当时就两三行代码,还是在arcgis的字段计算器中实现的,其实总体上大同小异。这一章很多的内容,需要前面的基础,与上一本书第六章的内容相关挺多的,还是需要不断回顾,打好基础,起码到时候知道去在哪抄,抄哪个函数。














 7145
7145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









