






7.10 使用Pandas
pandas是一个广泛使用、处理表格数据的包,可以处理不同的格式。pandas是arcgispro-py3默认安装的部分,pandas的名字来源于panel data,在统计学中描述多个时间段的观测到的数据集。
与其他的任何包一样,pandas也需要在脚本导入:import pandas as pd。pandas最重要的数据结构是DataFrame。Pandas DataFrame是用于存储值的二维结构,基本上是一个有行和列的表,列有名称(Fields),行有index,可以创建DataFrame,可以通过Nunpy数组或者CSV转换。
使用Pandas读取CSV文件可以使用read_csv()函数完成,这个函数返回DataFrame对象。
import pandas as pd
df = pd.read_csv("health.csv")
可以通过print的方式来查看内容,可以只打印前几行,使用head()方法,默认情况下打印前五行,但是可以设置参数:print(df.head(10))
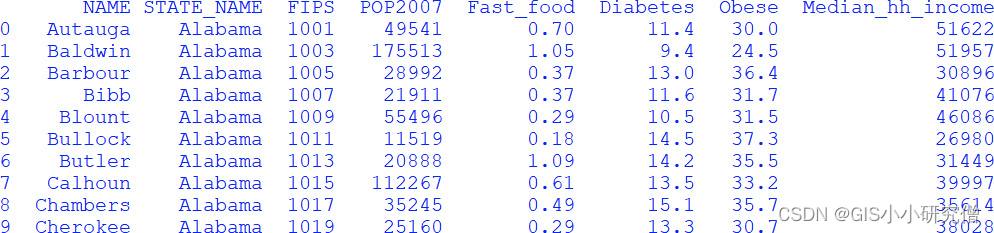
也可以使用tail函数打印后面的几行,或者使用sample()随机打印几行。这个示例说明了dataframe的基本情况,DataFrame由行列构成,列名是从输入文件的标题行获得的,行的索引编号从0开始。
选择要使用的特殊的列可以通过将列的名称指定为列表来完成,如下所示:
df[["FIPS", "Diabetes"]]
这里需要两个括号,外面的括号表示选择列,里面的括号指定列名。要处理结果,可以将结果分配给指定的新的DataFrame:
small_df = df[["FIPS", "Diabetes"]]
print(small_df.head())
可以通过更改列名的列表的方式来更改列的顺序,如下所示:
new_df = df[["FIPS", "Median_hh_income", "Diabetes"]]
print(new_df.head())
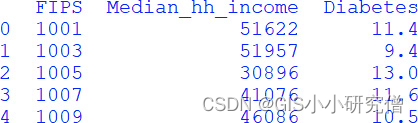
DataFrame是一个二维数组结构,但是如果只有一列的话,那就是一维数组结构,在Pandas,这种结构就叫做Pandas系列。可以通过从另一个 源 读取数据,也可以从现有的数据框种仅仅选择一列,创新Pandas Series,如下所示;
import pandas as pd
df = pd.read_csv("health.csv")
s = df["Diabetes"]
print(s.head())

Pandas Series是一个一维的数据结构,如列表或者一维Numpy数组,如图所示打印输出行有一个索引,列有名称,但是只有一个列就没有显示作为header。
选择和重新排序列是指Pandas的一个常用的任务,常用的另外的一个任务是更改特定的值,例如原始数据包含每个县的记录,要是想获取仅一个装的的行的数据框,可以使用以下表达式:
STATE_NAME == "Florida"
这个代码返回True或False的值,就像SQL语句一样。下面的代码使用此表达式来 filter 过滤 数据,并将结果存储为新的DataFrame对象。为了清晰起见,整个代码如下所示:
import pandas as pd
df = pd.read_csv("health.csv")
fl_df = df[df.STATE_NAME == "Florida"]
print(fl_df.head())

最后一个例子说明了Pandas处理数据时的效率,只需要几行就可以读取CSV文件的值并且根据值去更改数据,同时可以去计数、描述性统计或者集合等。以下代码使用特定列的最大值去过滤记录:
import pandas as pd
df = pd.read_csv("health.csv")
print(df.loc[df["Obese"].idxmax()])
在此示例中,df[“Obese”].idxmax()返回列名Obese具有最大值的行的索引,df.loc[]返回该索引的行。结果如下所示:

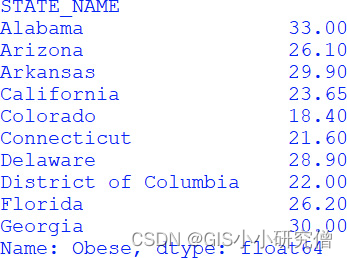
以下脚本按照 不同的state确定Obese列的中值,
import pandas as pd
df = pd.read_csv("health.csv")
new_df = df.groupby("STATE_NAME").median()["Obese"]
print(new_df.head(10))
在这个实例中,groupby(“STATE_NAME”)根据列名称STATE_NAME聚合数据,median()方法根据聚合确定每个列的中值,[“Obese”]仅选择感兴趣的列进行打印。
结果打印了每个州的 中值。
可以使用Pandas处理很多任务,可以读取包括Numpy数组、txt、CSV、EXCEL、JSON、HTML、SQL tables等的格式,学会pandas可以较少的使用单独的包或者模块,如openpyxl 、csv等函数使用pandas就可以不再使用。
7.11 Using Matplotlib for data visualization
最广泛使用的可视化库就是Matplotlib,其功能与matlab的绘图功能有一定的可比性。Matplotlib包含了pyplot模块,也有许多其他的模块用于各种功能等。本节说明了使用Matplotlib.pyplot创建基本图形。
第一步时先导入:import matplotlib.pyplot as plt,Matplotlib严重依赖于numpy,因此:import numpy as np,但是有时候不依靠numpy,并非所有的代码都需要numpy。
创建基本的图形可以使用pyplot模块的plot函数,2D绘图的基本代码是:
plot(x, y, <format>)
X和Y的值可以从现有的数据种获取,但也可以作为列表直接在函数中输入。格式的参数可以使用颜色、样式标记、线条样式代码的字符串。格式的参数是可以选择的,默认的是"b-",表示蓝色的线。下面的例子使用green的圆圈创建散点图:
plt.plot([1, 2, 3, 4, 5], [2, 4, 3, 5, 4], "go")
可以使用Python列表输入图的值,但是内部的序列都可以转换为NumPy数组,不需要 import NumPy,除非是专门使用NumPy数组作为输入。最后的分析步骤是使用show展示图形:
plt.show()
完整的代码,并保存:
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4, 5], [2, 4, 3, 5, 4], "go")
plt.show()
plt.savefig("demoplot.png")
结果如图:
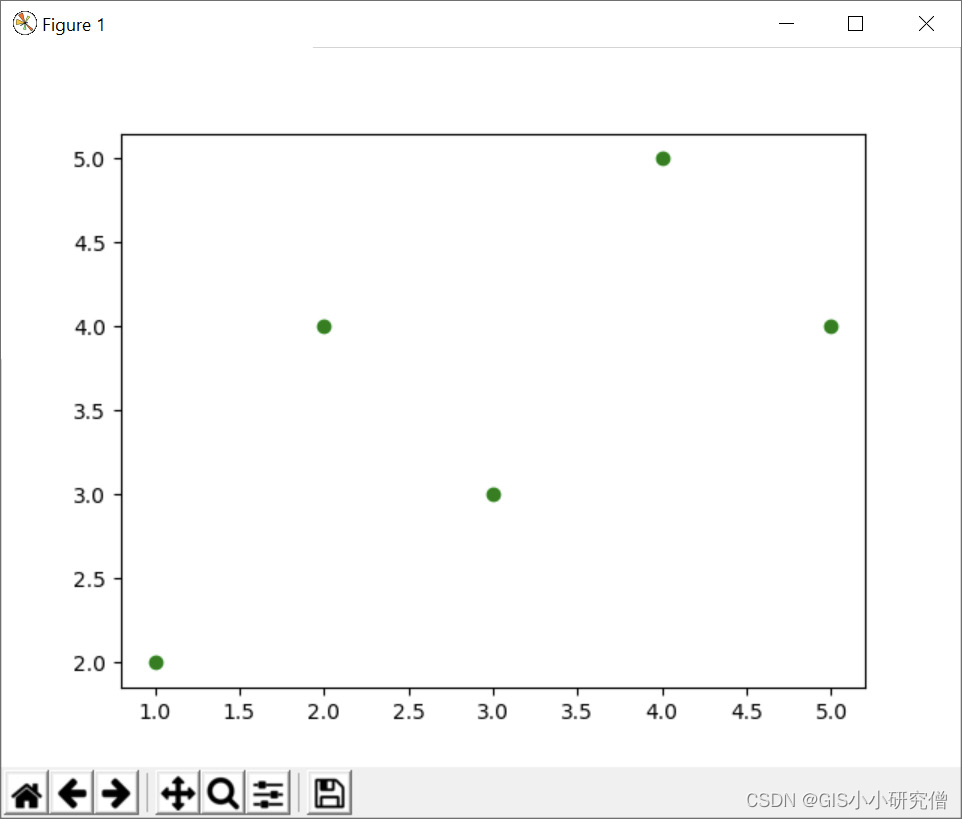
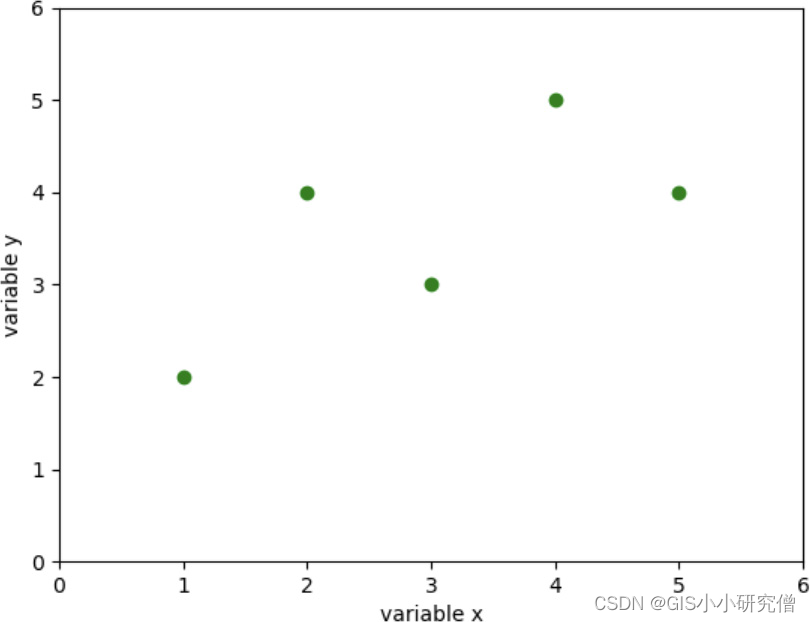
在Python IDE中,figure查看器的性质有所不同,但本身是相同的。 也可以将其保存到本地,而不是显示figure,如下所示:plt.savefig("demoplot.png") 。可以通过许多细节来控制figure的显示,axis()函数以列表的形式来控制X和Y轴的值,[xmin, xmax, ymin, ymax] 如下所示:
plt.axis([0, 6, 0, 6])
这些代码在创建figure后,保存figure前使用。可以使用xlabel()和ylabel()函数添加坐标轴的标签:
plt.xlabel("variable x")
plt.ylabel("variable y")
完整的代码如下所示:
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4, 5], [2, 4, 3, 5, 4], "go")
plt.axis([0, 6, 0, 6])
plt.xlabel("variable x")
plt.ylabel("variable y")
plt.savefig("demoplot.png")
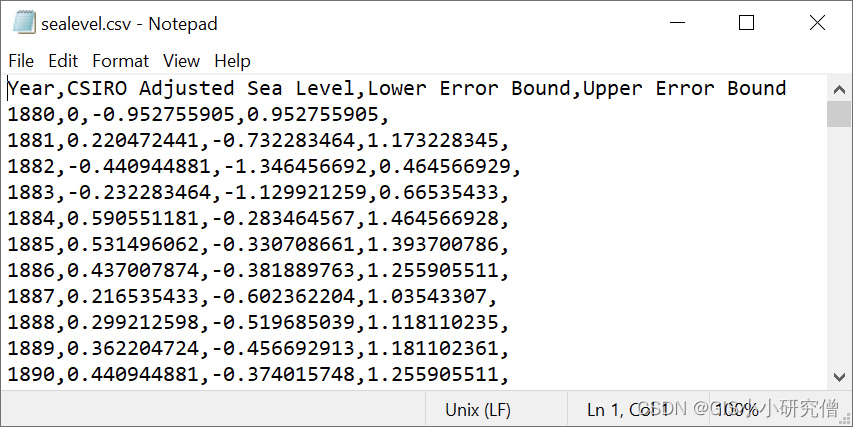
虽然数据值可以作为列表或NumPy数组直接输入到脚本中,但从现有数据源读取值更为典型。考虑一个全球平均海平面上升时间序列的示例CSV文件(来源:CSIRO,2015) 数据包括年和海平面的值,单位为英寸。
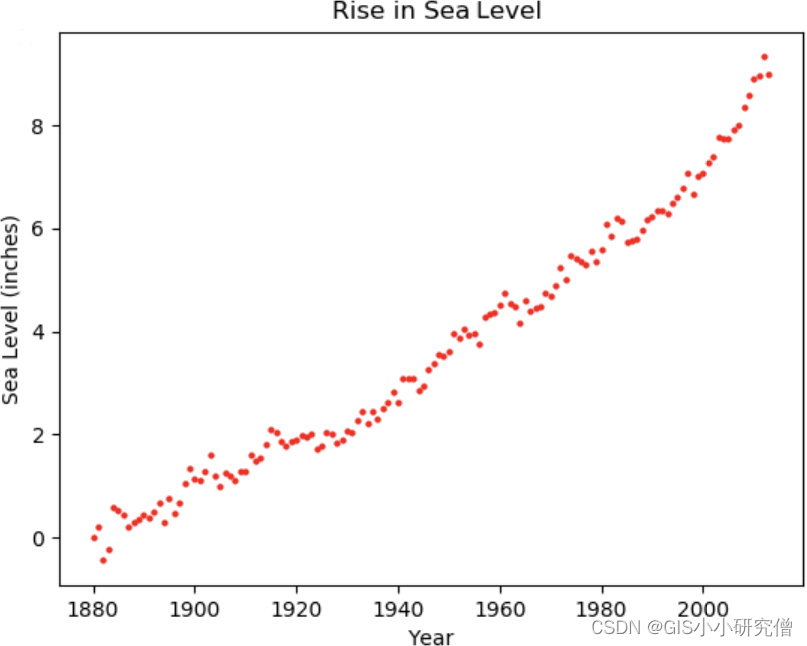
在下面的代码示例中,Pandas用于读取CSV 文件的内容。每个感兴趣的变量都创建为Pandas Series,这是一个类似列表的值序列。Matplotlib用于在两个变量之间创建散点图,包括轴标签和标题,plot()函数的marksize参数根据观察次数设置适当的大小,代码如下:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("sealevel.csv")
year = df["Year"]
sea_levels = df["CSIRO Adjusted Sea Level"]
plt.plot(year, sea_levels, "ro", markersize=2.0)
plt.xlabel("Year")
plt.ylabel("Sea Level (inches)")
plt.title("Rise in Sea Level")
plt.savefig("sealevel.png")
Matplotlib包含创建许多其他类型图形的功能。熟悉这些可能性的最佳方法之一是查看Matplotlib主页上的示例库。https://matplotlib.org/
每个示例都链接到完整的代码以创建特定的 示例,源代码可以作为Python脚本文件(.py)或Jupyter Notebook Ale(.ipynb)下载。
Points to remember
Python标准库包括几个在地理处理脚本中广泛使用的附加模块,还有许多其他第三方软件包可以添加以支持Python中的GIS工作流。
使用FTP传输文件可以在Python中使用ftplib模块实现自动化。常见的任务包括导航到正确的目录、读取目录中的文件以及将文件下载到本地计算机。
ZIP 文件被广泛用于压缩、组织和传输GIS数据集。Python中的zipfile模块可以检查ZIP 文件的内容,从ZIP 文件中提取文件,并创建新的ZIP文件。
XML 文件广泛用于存储数据集。几个不同的模块和包可以解析XML文件的内容并读取感兴趣元素的内容。
访问网页内容可以使用urllib模块完成。典型的任务包括阅读特定页面的内容或使用URL下载文件。一种常用的替代方法是requests包。
使用CSV格式的表格数据可以使用CSV模块完成,而openpyxl包广泛用于Excel 文件。
JSON已经成为一种广泛使用的数据共享格式,JSON模块可以在JSON对象和Python之间进行转换。ArcGIS中的一些工具和ArcPy中的函数也可用于处理JSON对象。
使用NumPy包支持的NumPy数组数据结构有助于快速处理大型数据集。NumPy数组也广泛用于数据分析和可视化的其他包中。有几种工具可用于在ArcGIS和NumPy阵列中的空间数据集之间进行转换。
Pandas已成为Python中处理表格数据的广泛使用的包。Pandas中的DataFrame数据结构对于从不同格式读取数据和处理数据以进行进一步分析是有效的。
Matplotlib提供了一整套使用Python创建专业质量图形的工具。
许多其他软件包可以扩展脚本的功能。















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









