







flume采集数据实例
flume下载
链接: https://pan.baidu.com/s/1YaHDTFOzEuSJykGyv8YBKg
提取码: rej8
案例使用文件下载:
链接: https://pan.baidu.com/s/12rMp76_W1fLvOwW9_hvfGg
提取码: u3v5
使用Flume的关键就是写配置文件
1)配置Source
2)配置Channel
3)配置Sinks
4)将以上三种组件串联起来
安装flume
解压flumne压缩包到指定目录内
进入到flumne的conf目录下
复制flume-env.sh.template --> flume-env.sh
修改flume-env.sh文件:
export JAVA_HOME=/opt/java8
export JAVA_OPTS="-Xms2048m -Xmx2048m -Dcom.sun.management.jmxremote"
安装 nc–telnet
[root@hadoop001 conf]# mkdir jobkb09
[root@hadoop001 conf]# yum install -y nc //“瑞士军刀”
[root@hadoop001 conf]# yum list telnet*
[root@hadoop001 conf]# yum -y install telnet-server.*
[root@hadoop001 conf]# yum -y install telnet.*
测试tenet连接
测试:
server端:
nc -lk 7777
client端:
telnet localhost 7777
1.监控 telnet输入 采集数据
编写 agent 配置文件 netcat-flume-logger.conf
cd /opt/flume160/conf/jobkb09
vi netcat-flume-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=7777
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
测试:
//启动flume agent
[root@hadoop001 conf]# ./bin/flume-ng agent --name a1 --conf ./conf/ --conf-file ./conf/jobkb09/netcat-flume-logger.conf -Dflume.root.logger=INFO,console
//启动被监听端口
[root@hadoop001 conf]# telnet localhost 7777
输入:
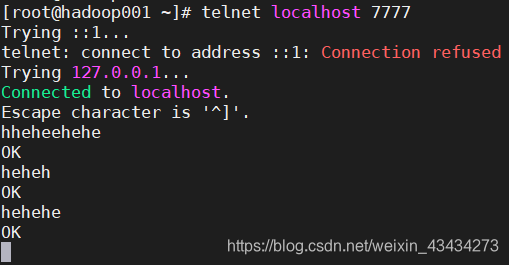
内容打印在flume控制台:
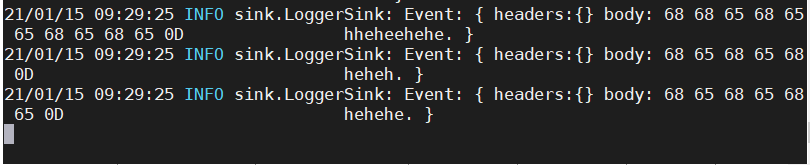
2.监控 文件末尾变动内容 采集数据
编写 agent 配置文件 file-flume-logger.conf
[root@hadoop001 flume160]# vi ./conf/jobkb09/file-flume-logger.conf
a2.sources=r1
a2.channels=c1
a2.sinks=k1
a2.sources.r1.type=exec
a2.sources.r1.command=tail -f /opt/bigdata/flume160/conf/jobkb09/tmp/tmp.txt
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
a2.channels.c1.transactionCapacity=1000
a2.sinks.k1.type=logger
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
测试:
//启动flume agent a2
[root@hadoop001 flume160]# ./bin/flume-ng agent --name a2 --conf ./conf/ --conf-file ./conf/jobkb09/file-flume-logger.conf -Dflume.root.logger=INFO,console
//命令行输入:
[root@hadoop001 ~]# echo hedfsfsda >> /opt/flume160/conf/jobkb09/tmp/tmp.txt
如图即为成功
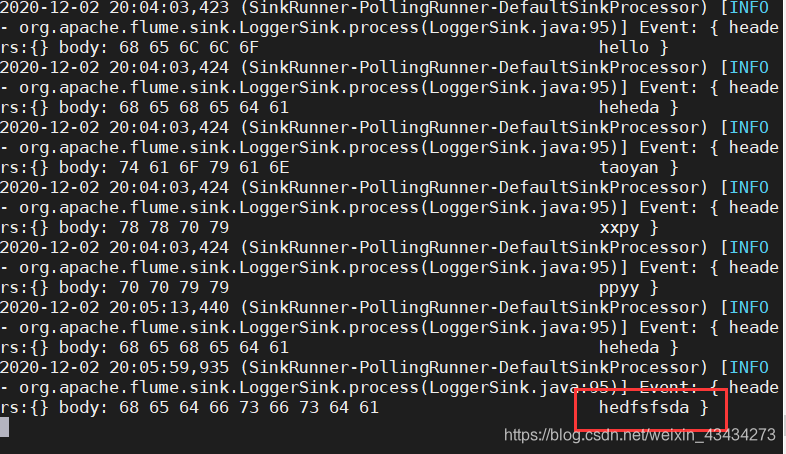
3.监控 复制的指定路径文件 采集数据
创建文件夹
cd /opt/flume160/conf/jobkb09
mkdir dataSourceFile //数据资源文件夹
mkdir checkPointFile //检查点文件夹
mkdir dataChannelFile //datachannel文件夹
mkdir tmp/ //用来存放要处理的文件
cd /opt/flume160/conf/jobkb09
编写 agent 配置文件 events-flume-logger.conf
vi events-flume-logger.conf
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/events
events.sources.eventsSource.deserializer=LINE
events.sources.eventsSource.deserializer.maxLineLength=10000
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flume160/conf/jobkb09/checkPointFile/events
events.channels.eventsChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/events
events.sinks.eventsSink.type=logger
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
测试:
cd /opt/flume160/conf/jobkb09
//创建文件夹
mkdir -p dataSourceFile/events //数据资源文件夹
mkdir -p checkPointFile/events //检查点文件夹
mkdir -p dataChannelFile/events //datachannel文件夹
//启动flume agent events
[root@hadoop001 flume160]# ./bin/flume-ng events --name a2 --conf ./conf/ --conf-file ./conf/jobkb09/events-flume-logger.conf -Dflume.root.logger=INFO,console
[root@hadoop001 tmp]#cp ./events.csv /opt/bigdata/flume160/conf/jobkb09/dataSourceFile/events/events_2020-11-30.csv
4.监控 复制的指定路径文件 采集数据到hdfs
cd /opt/flume160/conf/jobkb09
mkdir -p dataSourceFile/userFriend //数据资源文件夹
mkdir -p checkPointFile/userFriend //检查点文件夹
mkdir -p dataChannelFile/userFriend //datachannel文件夹
vi userfriend-flume-hdfs.conf
编写 agent 配置文件 userfriend-flume-hdfs.conf
user_friend.sources=userFriendSource
user_friend.channels=userFriendChannel
user_friend.sinks=userFriendSink
user_friend.sources.userFriendSource.type=spooldir
user_friend.sources.userFriendSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/userFriend
user_friend.sources.userFriendSource.deserializer=LINE
user_friend.sources.userFriendSource.deserializer.maxLineLength=320000
user_friend.sources.userFriendSource.includePattern=userFriend_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
user_friend.channels.userFriendChannel.type=file
user_friend.channels.userFriendChannel.checkpointDir=/opt/bigdata/flume160/conf/jobkb09/checkPointFile/userFriend
user_friend.channels.userFriendChannel.dataDirs=/opt/bigdata/flume160/conf/jobkb09/dataChannelFile/userFriend
user_friend.sinks.userFriendSink.type=hdfs
user_friend.sinks.userFriendSink.hdfs.fileType=DataStream
user_friend.sinks.userFriendSink.hdfs.filePrefix=userFriend
user_friend.sinks.userFriendSink.hdfs.fileSuffix=.csv
user_friend.sinks.userFriendSink.hdfs.path=hdfs://192.168.116.60:9000/kb09file/user/userFriend/%Y-%m-%d
user_friend.sinks.userFriendSink.hdfs.useLocalTimeStamp=true
user_friend.sinks.userFriendSink.hdfs.batchSize=640
user_friend.sinks.userFriendSink.hdfs.rollInterval=20
user_friend.sinks.userFriendSink.hdfs.rollCount=0
user_friend.sinks.userFriendSink.hdfs.rollSize=120000000
user_friend.sources.userFriendSource.channels=userFriendChannel
user_friend.sinks.userFriendSink.channel=userFriendChannel
测试:
//启动flume agent user_friend
[root@hadoop001 flume160]# ./bin/flume-ng agent --name user_friend --conf ./conf/ --conf-file ./conf/jobkb09/userfriend-flume-hdfs.conf -Dflume.root.logger=INFO,console
//执行复制操作
[root@hadoop001 jobkb09]# cp ./user_friends.csv /opt/flume160/conf/jobkb09/dataSourceFile/userFriend/userFriend_2020-11-30.csv
查看hdfs 如下图即成功
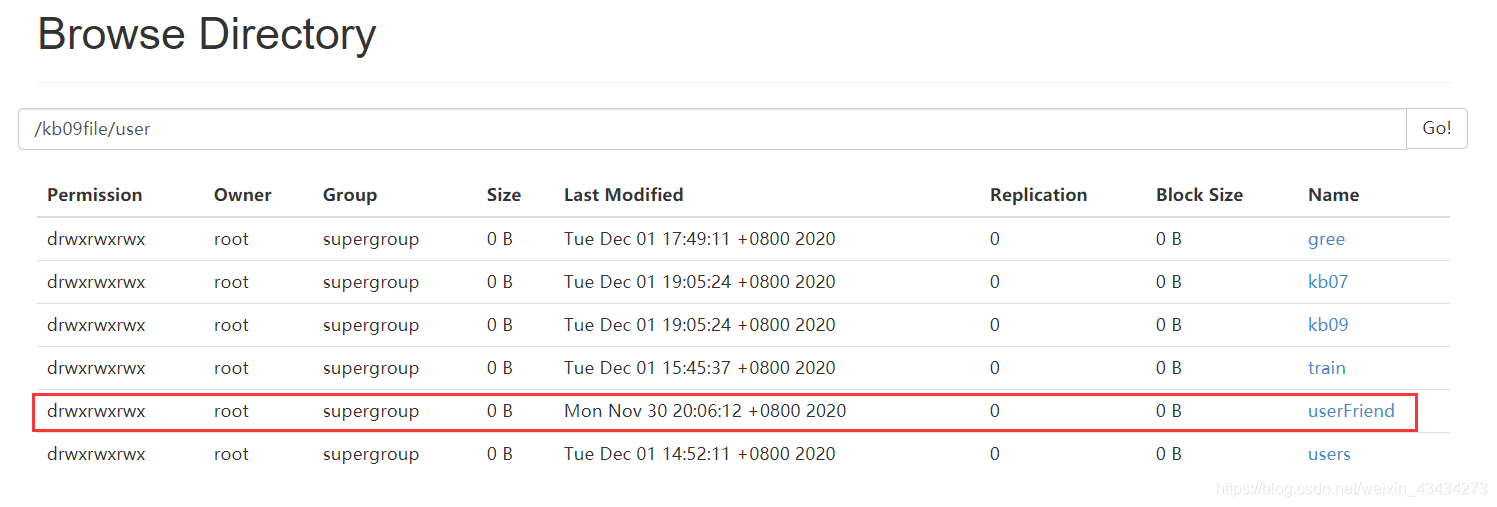


5.监控 复制的指定路径文件 并过滤去掉第一行 采集数据到hdfs
编写 agent 配置文件 userfriend-flume-hdfs.conf
[root@hadoop001 flume160]# vi ./conf/jobkb09/user-flume-hdfs.conf
users.sources=userSource
users.channels=userChannel
users.sinks=userSink
users.sources.userSource.type=spooldir
users.sources.userSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/user
users.sources.userSource.includePattern=users_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
users.sources.userSource.deserialize=LINE
users.sources.userSource.deserialize=maxLineLength=10000
users.sources.userSource.interceptors=head_filter
users.sources.userSource.interceptors.head_filter.type=regex_filter
users.sources.userSource.interceptors.head_filter.regex=^user_id*
users.sources.userSource.interceptors.head_filter.excludeEvents=true
users.channels.userChannel.type=file
users.channels.userChannel.checkpointDir=/opt/flume160/conf/jobkb09/checkPointFile/user
users.channels.userChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/user
users.sinks.userSink.type=hdfs
users.sinks.userSink.hdfs.fileType=DataStream
users.sinks.userSink.hdfs.filePrefix=users
users.sinks.userSink.hdfs.fileSuffix=.csv
users.sinks.userSink.hdfs.path=hdfs://192.168.116.60:9000/kb09file/user/users/%Y-%m-%d
users.sinks.userSink.hdfs.useLocalTimeStamp=true
users.sinks.userSink.hdfs.batchSize=640
users.sinks.userSink.hdfs.rollCount=0
users.sinks.userSink.hdfs.rollSize=120000000
users.sinks.userSink.hdfs.rollInterval=20
users.sources.userSource.channels=userChannel
users.sinks.userSink.channel=userChannel
测试:
//启动flume agent user_friend
[root@hadoop001 flume160]# ./bin/flume-ng agent --name users --conf ./conf/ --conf-file
./conf/jobkb09/user-flume-hdfs.conf -Dflume.root.logger=INFO,console
//执行复制操作
[root@hadoop001 jobkb09]# cp users.csv /opt/flume160/conf/jobkb09/dataSourceFile/user/users_2020-12-01.csv
查看hdfs文件
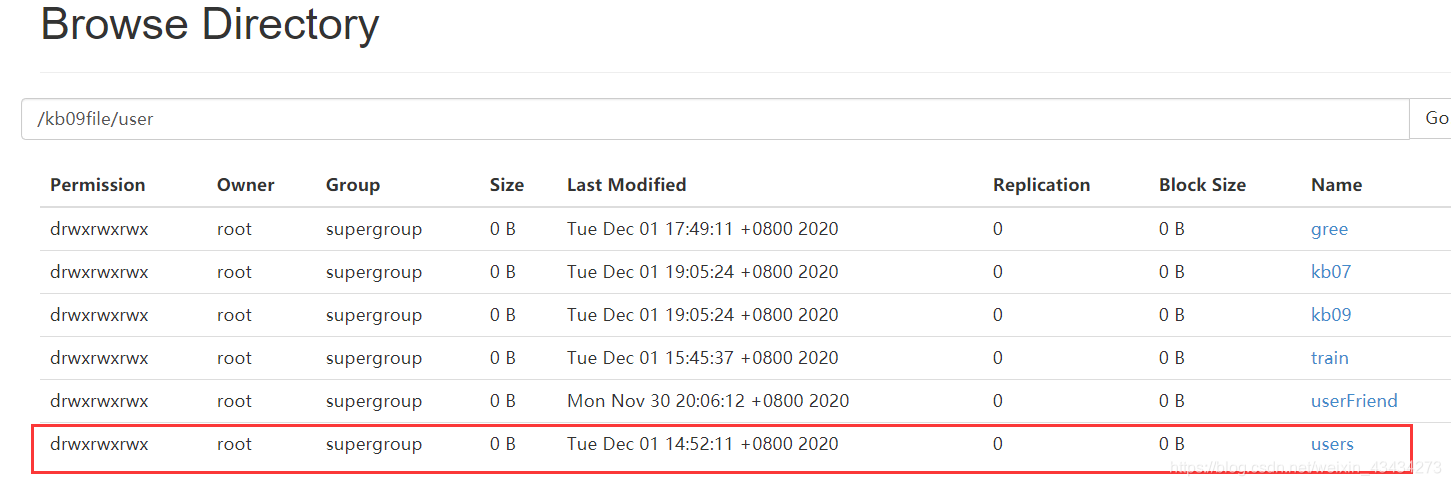


下载下来看一下:第一行没了已经过滤完成
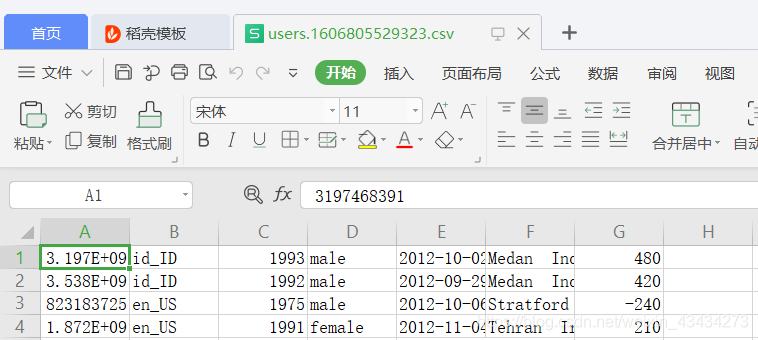
对比看一下users.csv源文件前6行:第一行具有列名
[root@hadoop001 tmp]# head -n 6 users.csv
user_id,locale,birthyear,gender,joinedAt,location,timezone
3197468391,id_ID,1993,male,2012-10-02T06:40:55.524Z,Medan Indonesia,480
3537982273,id_ID,1992,male,2012-09-29T18:03:12.111Z,Medan Indonesia,420
823183725,en_US,1975,male,2012-10-06T03:14:07.149Z,Stratford Ontario,-240
1872223848,en_US,1991,female,2012-11-04T08:59:43.783Z,Tehran Iran,210
3429017717,id_ID,1995,female,2012-09-10T16:06:53.132Z,,420














 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









