







一、CAP定理的引入
在过去,因为信息处理的业务量不大,所以信息系统使用单机版数据库已足够满足应用需求,该架构简单描述为:一台服务器或小型机部署数据库系统软件,一台磁盘阵列上作为存储系统用来存储数据库系统产生的格式化的数据文件,为了保障高可用能力,一般会部署两台数据库服务器,见以下示意图:
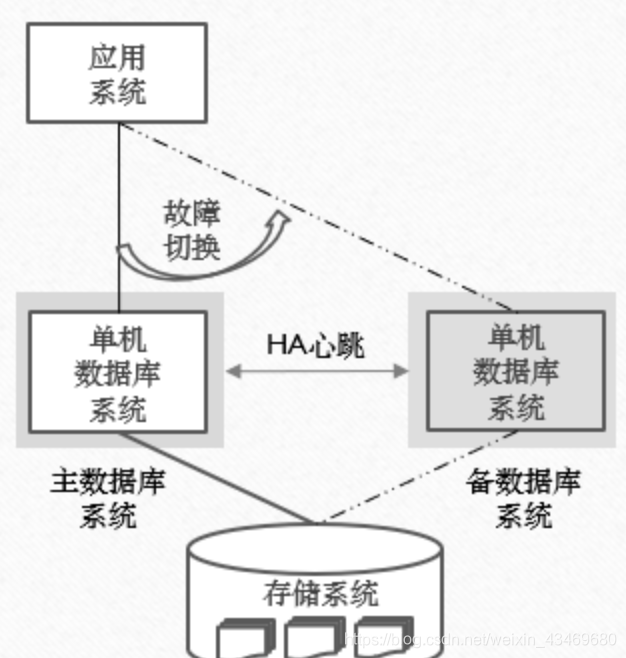
单机版数据库系统在两台服务器上部署两套,一套为主数据库系统,另一个为备数据库系统,备数据库系统不工作,上层的应用系统通过主数据库系统来访问和处理数据,主备两套数据库系统之间通过心跳检测技术探测对方的工作状态,一旦主数据库系统不工作,那么备数据库系统立刻启动,替代主数据库系统对应用系统提供数据库服务。
随着大数据时代、移动互联网业务的兴起,信息系统要处理的业务量呈现爆炸式的增长,主要体现在数据处理业务的数量增大,存储的数据量增多以及处理性能要求增快,传统单机版的数据库系统就很难支撑如此之大的业务量了,出现了瓶颈,所以分布式数据库技术就出现了,它巧妙的把单机版的数据库系统通过软件组成一套集群,把存储的数据按照一定的规则打撒到集群中各个数据库系统来存储,同时上层的应用提交过来的业务处理请求也分散到集群的各个数据库系统上来处理,那么就可以承载更大的数据量存储和更多的业务处理,并且能通过增加数据库节点数量来提升数据库集群的处理能力,满足未来业务增长的需求,如下图所示,由多台数据库系统组成集群,来支撑更大的业务量和更多的存储量。
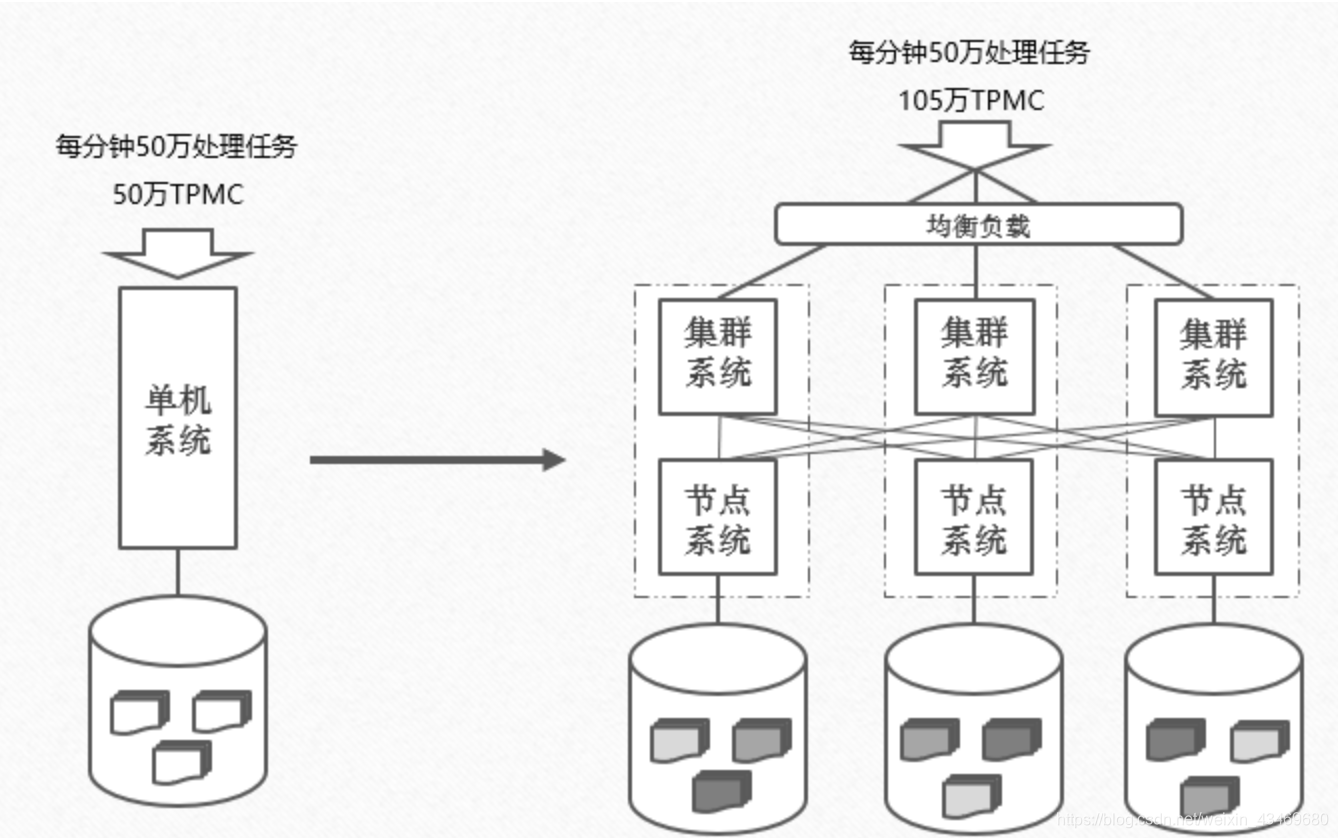
但是分布式数据库系统的每个数据库节点上所存储的只是完整数据的一部分,如果这台机器不工作了或者磁盘坏掉,就会出现不能提供服务或者数据丢失的情况,因此,为了保障系统的可用性和容错能力,对每节点存储的数据要在集群两外两台节点上有相同的副本存储,这样就有效的保障了数据的安全,但相比单机系统所带来的问题就是维护的数据副本量至少增多了2份,数据写入主本之后需要向副本同步来保持一致性,但网络也可能会出现故障,出现了故障数据不能向副本同步,上层的应用能不能访问数据是一个需要考虑的问题,因为,对分布式系统产生了一个CAP原理来合理的解释并做出了响应的规则约定。
二、CAP原理的解释
1、CAP的定义
CAP是“一致性(Consistency)、可用性(Availability)以及分区容忍性(Partition Tolerance)”的缩写,接下来就来详细的阐述一下CAP原理。
1)C 即一致性(Consistency)
一致性就是要求分布式系统要保障,一旦数据写入到分布式存储系统之后,所有访问数据的请求不管是访问分布式存储的那个节点上,查到到该写入的数据都是一致的,不能出现3个副本中有的副本有该条数据,有的副本没有该条数据(插入问题),更不能是有的副本该条数据和另外一个副本该条数据是不一样的(更新问题)。
2)A 即可用性(Availability)
可用性就是要求分布式系统要保障,一旦数据写入到分布式存储系统之后,所有访问该数据的请求都可以正常响应,不管该数据能不能查到,又或者该条数据查出来的一不一致,不能出现查询该数据时出现长期等待或者报错的发生。
3)P 即分区容忍性 (Partition Tolerance)
分区容忍性时要求分布式系统要保障,一旦数据写入到分布式存储系统的主本文件后,因为网络的的问题无法同步到副本的时候,系统依然能够对外提供服务,网络在分布式系统来讲是不敢绝对保障的,如果因为网络问题,导致写入数据无法向副本同步,这时候就是分区的情况出现,但网络的绝对的可靠从科学角度上来讲是无法做到的,因此,所有分布式系统必须是满足“P”的存在,不然就只能使用单机系统来解决,那就不是分布式系统了。
因此,综上所述,分布式系统基本上所有的都必须满足“P”,在“A”和“C”之间来选择,要么是AP,要么是CP
2、AP的解释
首先分布式系统是允许P的存在,当分布式集群中网络故障导致数据不一致,那么整个分布式系统可以对外提供服务,当一个数据写入到主本的时候,因为网络问题未能向副本及时同步,那么这条数据在主副本之间出现了不一致的情况,但A的要求就是保证可用性为前提,虽然数据不一致,当查询该条数据的请求过来时,访问主本能查到数据,访问副本不能查到数据,这种情况都是正常状态。
当前,互联网电商的购物车后台的数据库就是AP原则的数据库,为了满足高可用性能,购物车里面的数据有时候能够查到,有时候不能查到都正常,只要最后结账时的账单能够一致就可以了(这就给足了数据短暂不一致的时间,但大幅提高的性能)。
3、CP的解释
同样,分布式系统是允许P的存在,当分布式集群中网络故障导致数据不一致,那么整个分布式系统可以对外提供服务,当一个数据写入到主本的时候,因为网络问题未能向副本及时同步,那么这条数据在主副本之间出现了不一致的情况,但C的要求就是保证该条数据必须一致才能够访问,所有在该条数据没有完全在3个副本完全同步时,该条数据是不允许被访问到的,这就要求写入该条数据必须要等3个副本都必须完全写入成功后才能够被访问,这就造成数据写入性能要比AP的差,但相对换来的是数据的高度一致。
4、AC的解释
CA系统指的是,系统保证强一致性和整体可用性,但是不保证Partition tolerance。这里“不保证Partition tolerance”,应该理解成“没有网络分区”还是“有网络分区,没有容忍机制”呢?网上有很多不同的观点:
观点一:理解成一个的操作范围,即CA是在没有网络分区的情况下的操作
观点二:牺牲一部分功能,比如写操作,以保证强一致性,但是似乎A受到了一定程度的影响
观点三:单机系统
但是,一般来讲,在现实情况下,网络分区是一定存在的,所以在系统实现的时候必须要考虑Partition tolerance,基于此,我们要实现的就是CP或者AP了。
三、CAP原理的总结
总上所述,CAP原理定义的就是3个原则在分布式存储系统中只能满足其中两个,无法全部都满足,因为要求网络绝对的可靠是不可能的,因此,所有的分布式系统都必须满足P,然后AP和CP之间做出抉择,是保性能牺牲一致(AP),或者是保一致牺牲性能(CP)要根据实际的应用场景来确定。
四、类比
kafka 官网AC 配置AP或者CP
Kafka,当今非常流行的一个高可用消息中间件open source。其实,就像其Logo中提到的,Kafka是一个分布式的流式计算机平台,只是说在很多场景下,我们只把它用作消息中间件。
那么,Kafka作为一个分布式消息中间件,满足CAP理论吗?如果满足的话,满足哪两个特性呢,CA、AP或者CP?
如果你在网上搜索Kafka CAP,你可能会发现Kafka的开发人员申明Kafka是CA系统。
原因是,Kafka设计是运行在一个数据中心,网络分区问题基本不会发生,所以是CA系统。
但是,现实情况是,即使运行在一个数据中心,网络问题理论上也是存在的,所以这是一个必须要考虑的点。那么,Kafka是AP还是CP系统呢?
其实,Kafka提供了一些配置,用户可以根据具体的业务需求,进行不同的配置,使得Kafka满足AP或者CP,或者它们之间的一种平衡。
定制配置
比如下面这种配置,就保证强一致性,使得Kafka满足CP。任意写入一条数据,都需要等到replicate到所有节点之后才返回ack;接下来,在任意节点都可以消费到这条数据,即是在有节点宕机的情况下,包括主节点。
replication.factor = 3
min.insync.replicas = 3
acks = all
而下面的配置,就主要保证可用性,使得Kafka满足AP。对于任意写入一条数据,当主节点commmit了之后就返回ack;如果主节点在数据被replicate到从节点之前就宕机,这时,重新选举之后,消费端就读不到这条数据。这种配置,保证了availability,但是损失了consistency。
replication.factor = 3
min.insync.replicas = 3
acks = 1
还有一种配置是公认比较推荐的一种配置,基于这种配置,损失了一定的consistency和availability,使得Kafka满足的是一种介于AP和CP之间的一种平衡状态。因为,在这种配置下,可以在容忍一个节点(包括主节点)宕机的情况下,任然保证数据强一致性和整体可用性;但是,有两个节点宕机的情况,就整体不可用了。
replication.factor = 3
min.insync.replicas = 2
acks = all
对于这种配置,其实Kafka不光可以容忍一个节点宕机,同时也可以容忍这个节点和其它节点产生网络分区,它们都可以看成是Kafka的容错(Fault tolerance)机制。
除了上面的几个常用配置项,下面这个配置项也跟consistency和availability相关。这个配置项的作用是控制,在所有节点宕机之后,如果有一个节点之前不是在ISR列表里面,启动起来之后是否可以成为leader。当设置成默认值false时,表示不可以,因为这个节点的数据很可能不是最新的,如果它成为了主节点,那么就可能导致一些数据丢失,从而损失consistency,但是却可以保证availability。如果设置成true,则相反。这个配置项让用户可以基于自己的业务需要,在consistency和availability之间做一个选择。
unclean.leader.election.enable=false
最后,其实不光是Kafka,还有很多其它的系统(特别是一些基于分布式共识算法的数据存储系统,比如:zookeeper),也不是严格的AP或者CP系统。所以,我们没有必要严格地用CAP来讨论或者以此为guideline来构建一个分布式存储系统,没有太大的意义。关于这一点,这里推荐两篇文章,大家可以参考:
https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/
2
除了Partition tolerance,我们可能还经常听到Fault tolerance(容错)和Latency tolerance(网络延迟容忍),它们其实都是指程序在应对某些情况时的容忍能力,从highlevel来讲,这是一个系统resilience的体现。比如Latency tolerance,当网络延迟比较大的时候,应用程序可以实现一些fallback逻辑,以此来提高用户的响应时间。对于应用程序端的容错处理,业界有一些很流行的open source,比如说Hystrix和resilience4j。
References
https://en.wikipedia.org/wiki/CAP_theorem
https://kafka.apache.org/documentation/
https://stackoverflow.com/questions/51375187/why-kafka-is-not-p-in-cap-theorem
https://aphyr.com/posts/293-jepsen-kafka















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











