



 本文深入探讨Kubernetes架构,包括etcd作为关键值存储的作用、API服务器的职责、控制器管理器和调度器的工作原理,以及如何确保集群高可用性和安全性。
本文深入探讨Kubernetes架构,包括etcd作为关键值存储的作用、API服务器的职责、控制器管理器和调度器的工作原理,以及如何确保集群高可用性和安全性。
架构
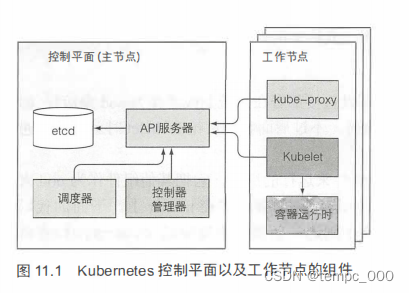
etcd
- etcd是一个响应快、 分布式、以及一致的key-value存储 。存储集群状态与元数据。
- 唯一能直接和etcd 通信的是Kubemetes的API服务器。
- 所有的Kubernetes 包含一个metadata.resourceVersion宇段 ,当更新对象时,客户端需要返回该值到API服务器。如果版本值与etcd中存储的不匹配,API服务器会拒绝该更新。(mvcc)
好处:增强乐观锁系统、验证系统的健壮性;并且,通过把实际存储机制从其他组件抽离,降低系统的耦合。
问题:形成以API服务器为中心的集中式架构。
etcd中以key-value对的形式存储元数据
其中key的形式是包含 / 的命名系统(类似文件系统)。
value是JSON格式的pod定义

API服务器
API服务器对CRUD作验证通过:认证,授权准入插件确保插入数据的合法性,通过资源验证,对资源进行规格化。
API服务器仅进行写入资源的操作,并启动控制器及相关组件。
控制平面通过消息订阅的方式,订阅相关消息
etcd成功写入资源时,会向API服务器发送通知消息。API服务器会向监听者发送消息通知。即,API服务器只完成转发etcd(还有其他)的通知消息的功能,而不在写入数据时通知消息订阅者。
调度器
调度器做的是通过 API 服务器更新 pod的定义。API服务器通知kubelet。由kubelet完成本节点的pod创建删除。
pod定义改成什么?
调度算法:
- 筛选符合资源要求的,按优先级分配
- 符合业务要求的调度
- 多调度器,在pod里指定调度器
控制器管理器
由于调度器只管向API服务器更新pod的定义,调度器无法保证最终集群最终向指定方向收敛。而收敛功能由控制器完成。
对于每种具体资源均实现相应控制器。控制器同样通过订阅API服务器相关通知,当收集到可能会改变所控制资源的通知时,控制器根据自身规则,发布对应的控制操作。API服务器收到相应操作后同样仅通知kubelet。最终有kubelet来完成资源创建删除。
显然实际上控制器也不能保证,对相应资源的控制一定被实际实现了(因为控制器也只是向API服务器发送了通知消息,最终还得kubelet完成具体操作,这一点和调度器一样)。所以控制器仍然需要定期执行重列举操作来确保不会丢掉什么。
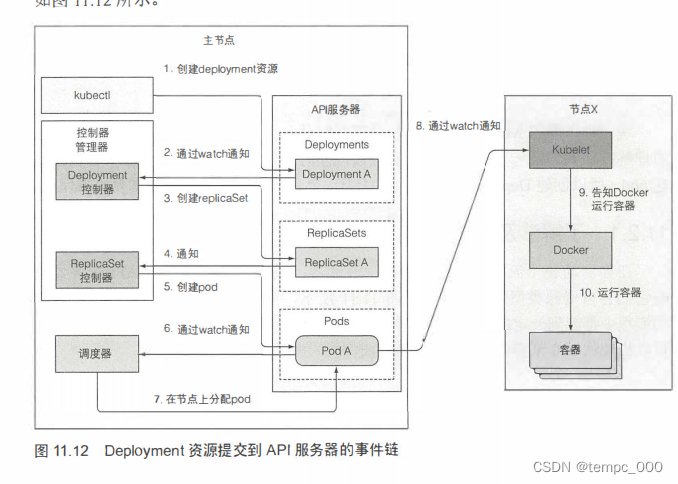
代理
服务终端的代理,客户端通过API服务器链接到代理,代理最终连接到服务。
跨pod网络
通过一个暂停的基础设施容器(k8s的容积是层级结构的,建立在底层容器的上层容器,可以共用底层容器的一些资源)
全局IP地址唯一性:
三层网络结构保证
1.所有节点的根网络 2.每个节点都有的一个底层容器 3.各个pod的eth0
容器网络接口保证
使用kube-proxy。确保每个目的地为kube-proxy的IP/端口对的数据包在kube-proxy被解析,目的地址被修改为pod的IP,这样数据包就会被重定向到支持服务的一个pod。
kube-proxy监控API 对Service和Endpoint 对象的更改,以保证可以重定向到正确的pod
集群高可用
- 分布式存储etcd,通过多备份,大多数投票(?)保证了少部分服务宕机情况下,系统仍然可用。
- API服务器通过分布式存储etcd系统完成分布式高可用。数据存储在分布式存储中。API服务的接收经过负载均衡
- 控制器和调度器的高可用性,通过领导者选举完成高可用。多个副本保证仅一个领导者可写。通过API服务器的endpoint资源,巧妙地避免了控制器和调度器领导者选举的网络消耗。通过向同一个endpoint资源写入自身的编号,保证只有一个领导者。
- endpoint资源通过mvcc来保证并发写的一致性。(etcd如何实现的一致性?可能存在短时间的不一致或降低了性能)
集群内节点和网络安全
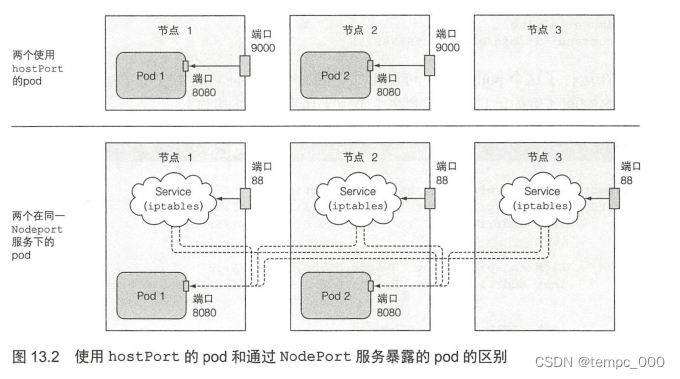
对于一个使用 hostPort的pod,到达宿主节点的端口的连接会被直接转发到 pod 的对应端口上:然而在 Node Port 服务中,到达宿主节点的端口的连接将被转发到随机选取的 pod上(这个 pod 可能在其他节点上)。另外一个区别是,对于使用 hostPort pod,仅有运行了这类 pod 的节点会绑定对应的端口;而 Node Port 类型的服务会在所有的节点上绑定端口,即使这个节点上没有运行对应的 pod。
集群的资源分配
以CPU与内存为例。分配分为request资源与limit资源。
request资源用于资源请求时候使用。调度器根据pod的总资源,与pod已经调度的容器占用的资源,计算pod剩余的资源。需要pod剩余资源大于即将调度的pod,才能成功调度pod。
limit资源。用于限制该容器的最大资源数量(注意,pod中所以容器的limit资源总和是可以超出pod的资源总量的)。当容器的CPU占用不会超过limit限制。容器的内存占用超过limit时候,容器会因为OOM被杀死并根据一定策略重启。
由于pod只能获取节点的CPU核数与最大内存(大坑)。所以一些应用(应用设置了通过最大内存百分比使用资源)会很快超过limit的限制(因为应用的最大内存百分比算的是节点的最大内存,而不是pod的,但是limit算的是pod的)。因此应用会因为OOM被杀死(CPU也会出现类似的问题)。
pod 划分为 QoS 等级(其实就是request与limit的相对大小关系)
• BestEffort pod的request与limit均未设置 最佳适配型(适配节点需要、调度)
• Guaranteed pod以及pod里面的容器所有的资源均设置了request与limit资源;并且资源的request与limit相同 担保型(申请多少用多少,有且仅有)
• Burstable 可以获得request的资源,且可以获得额外资源 可燃型(一定范围可动态伸缩?)(除上面两种之外,即request小于limit,保证request且不超过limit)
超卖杀死顺序
BestEffort-Burstable-Guaranteed
guaranteed类型只有在系统需要资源的时候才会被杀死
相同类型下:优先杀死内存实际使用量占内存申请量比例更高的pod(即先杀死内存快用完了的pod)
ResourceQuota 与 LimitRange联合控制pod以及容器的资源创建与使用
污点
NoSchedule 表示如果 pod 没有容忍这些污点, pod 则不能被调度到包含 这些污点的节点上。
PreferNoSchedule 是 NoSchedule 的一个宽松的版本, 表示尽量阻止pod 被调度到这个节点上, 但是如果没有其他节点可以调度, pod 依然会被调度到这个节点上。
NoExecute 不同于 NoSchedule 以及 PreferNoSchedule, 后两者只在调度期间起作用, 而 NoExecute 也会影响正在节点上运行着的 pod。 如果在一个节点上添加了 NoExecute 污点, 那些在该节点上运行着的 pod, 如果没有容忍这个 NoExecute 污点, 将会从这个节点去除。
安全机制

















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









