







Storm概念以及架构详解
一、什么是Storm?
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
二、离线计算和流式计算
2.1 离线计算
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算、Hive
2.2 流式计算
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:
将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
2.3 Storm与Hadoop的区别
不同点:
| Storm用于实时计算 | Hadoop用于离线计算 |
|---|---|
| Storm处理的数据保存在内存中,源源不断 | Hadoop处理的数据保存在文件系统中,一批一批 |
| Storm的数据通过网络传输进来 | Hadoop的数据保存在磁盘中 |
相同点:
Storm与Hadoop的编程模型相似
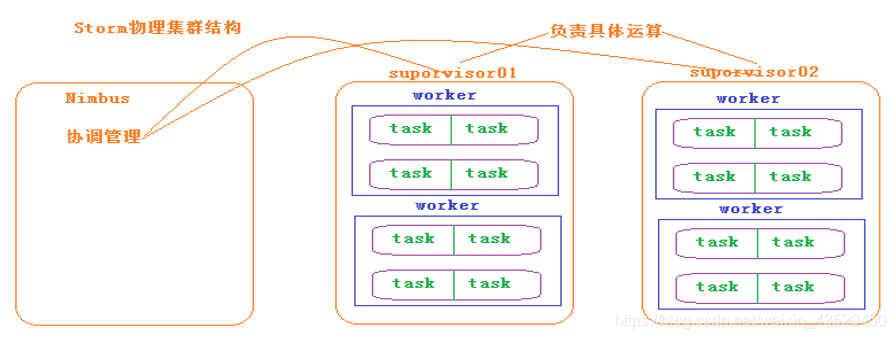
三、Storm的体系结构
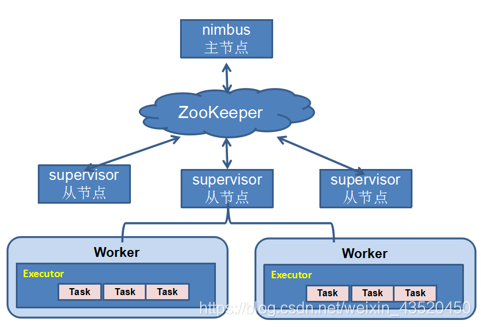
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Executor:Storm 0.8之后,Executor为Worker进程中的具体的物理线程,同一个Spout/Bolt的Task可能会共享一个物理线程,一个Executor中只能运行隶属于同一个Spout/Bolt的Task。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
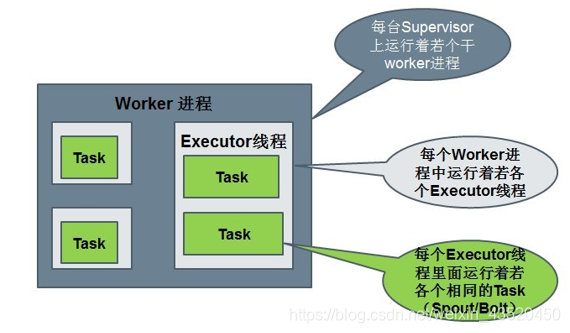
四、Storm的运行机制
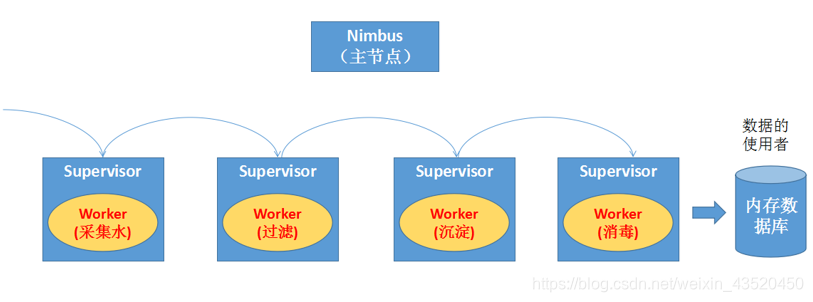
(1)整个处理流程的组织协调不用用户去关心,用户只需要去定义每一个步骤中的具体业务处理逻辑
(2)具体执行任务的角色是Worker,Worker执行任务时具体的行为则有我们定义的业务逻辑决定
五、Storm的安装配置
(1)解压:
tar -zxvf apache-storm-1.0.3.tar.gz -C ~/training/
(2)设置环境变量:

(3)编辑配置文件:
[root@bigdata111 apache-storm-1.0.3]$ vi /conf/storm.yaml
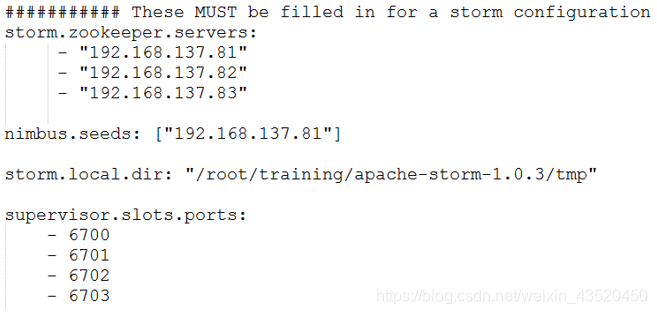
注意:
如果要搭建Storm的HA,只需要在nimbus.seeds中设置多个nimbus即可。
(4)把安装包复制到其他节点上即可。
六、启动和查看Storm
(1)在nimbus.host所属的机器上启动 nimbus服务和logviewer服务
storm nimbus &
storm logviewer &
(2)在nimbus.host所属的机器上启动ui服务
storm ui &
(3)在其它个点击上启动supervisor服务和logviewer服务
storm supervisor &
storm logviewer &
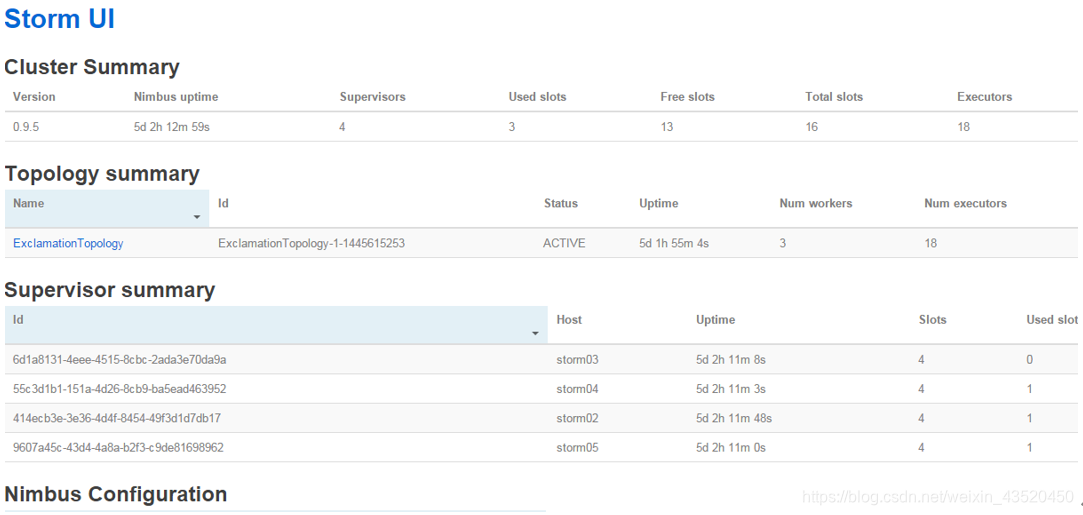
(4)查看storm集群:访问 http://bigdata111:8080,即可看到storm的ui界面
七、Storm的常用命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
(1)提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
storm jar storm-starter-topologies-1.0.3.jar org.apache.storm.starter.WordCountTopology MyWordCount1
(2)杀死任务命令格式:storm kill 【拓扑名称】 -w 10
(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
(3)停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
(4)启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
(5)重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
八、Demo演示:WordCount及流程分析
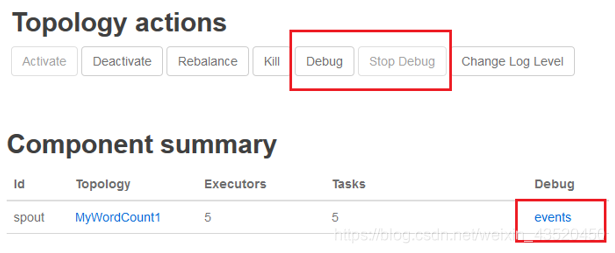
通过查看Storm UI上每个组件的events链接,可以查看Storm的每个组件(spout、blot)发送的消息。但Storm的event logger的功能默认是禁用的,需要在配置文件中设置:topology.eventlogger.executors: 1,具体说明如下:
"topology.eventlogger.executors": 0 //默认,禁用
"topology.eventlogger.executors": 1 //一个topology分配一个Event Logger.
"topology.eventlogger.executors": nil //每个worker.分配一个Event Logge
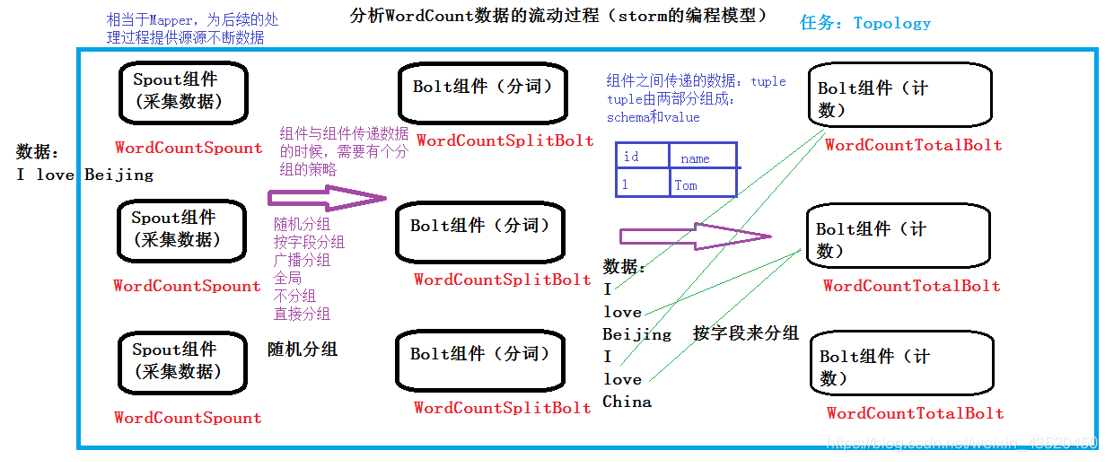
WordCount的数据流程分析:
九、Storm的编程模型
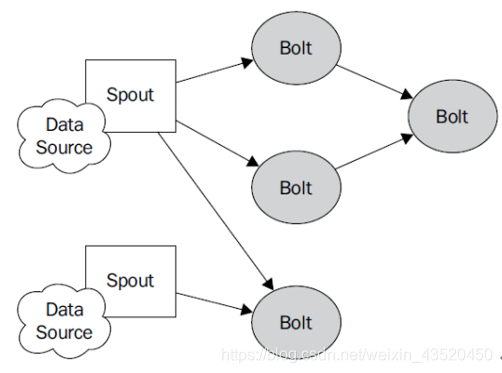
(1)Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
(2)Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
(3)Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
(4)Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
(5)Stream:表示数据的流向。
(6)StreamGroup:数据分组策略
Shuffle Grouping :随机分组,尽量均匀分布到下游Bolt中
Fields Grouping :按字段分组,按数据中field值进行分组;相同field值的Tuple被发送到相同的Task
All grouping :广播
Global grouping :全局分组,Tuple被分配到一个Bolt中的一个Task,实现事务性的Topology。
None grouping :不分组
Direct grouping :直接分组 指定分组
十、Storm编程案例:WordCount
流式计算一般架构图:

Flume:用来获取数据。
Kafka:用来临时保存数据。
Strom:用来计算数据。
Redis:是个内存数据库,用来保存结果数据。
(1)创建Spout(WordCountSpout)组件采集数据,作为整个Topology的数据源
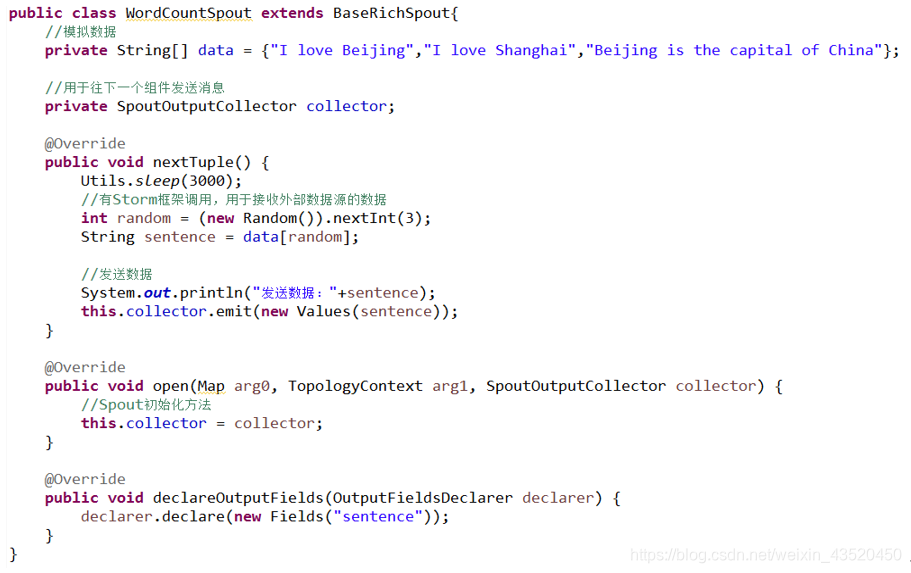
(2)创建Bolt(WordCountSplitBolt)组件进行分词操作
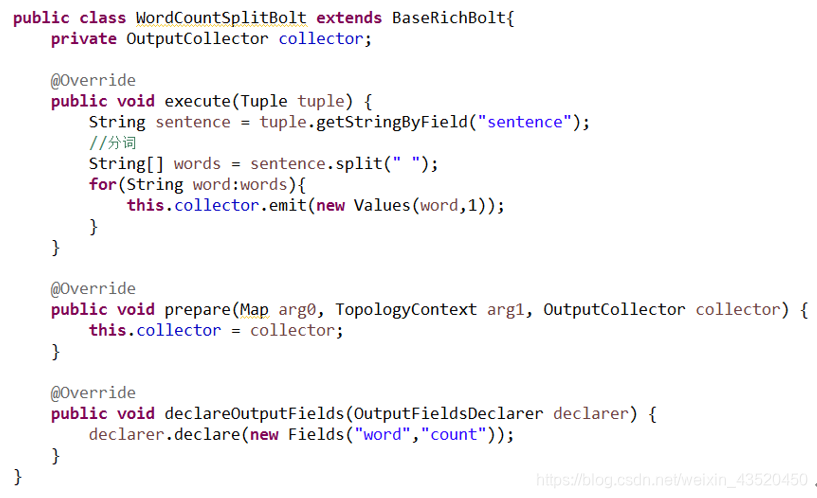
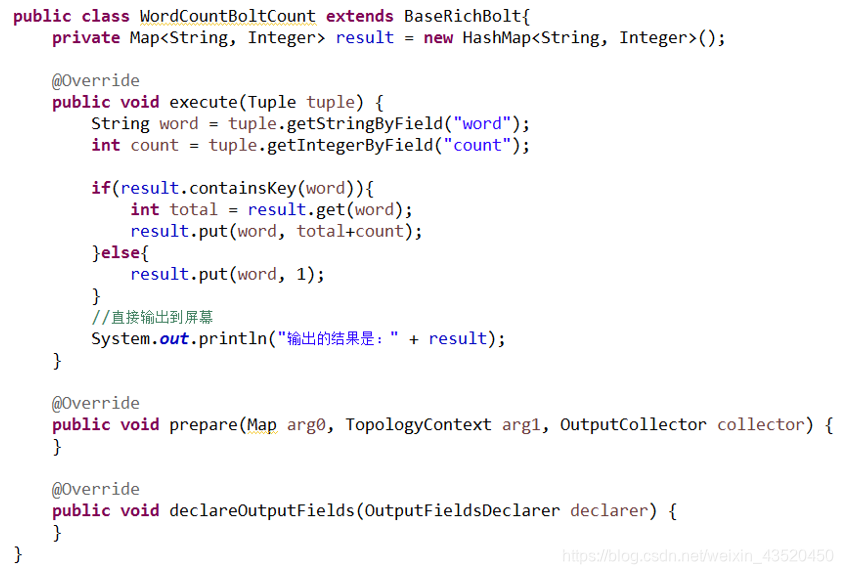
(3)创建Bolt(WordCountBoltCount)组件进行单词计数操作
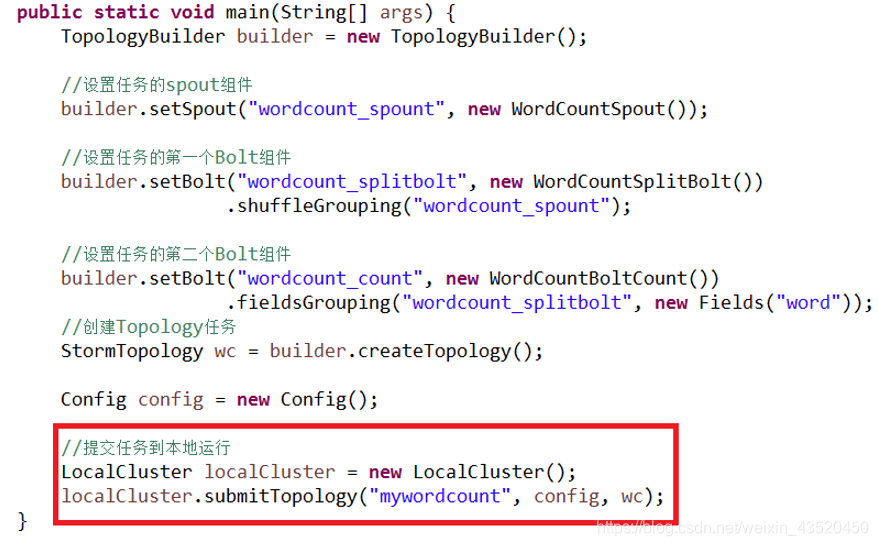
(4)创建主程序Topology(WordCountTopology),并提交到本地运行
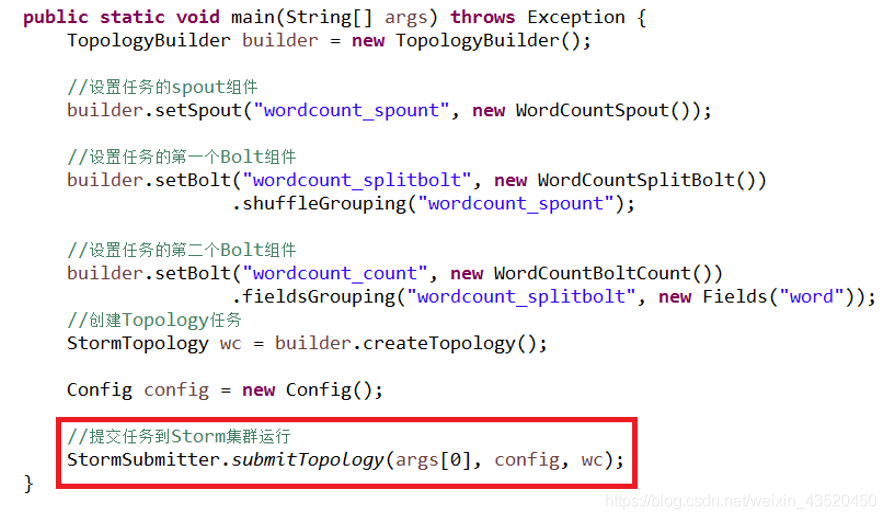
(5)也可以将主程序Topology(WordCountTopology)提交到Storm集群运行
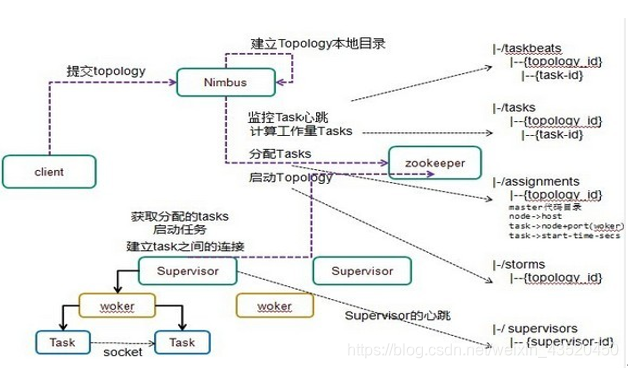
十一、Storm集群在ZK上保存的数据结构

十二、Storm集群任务提交流程
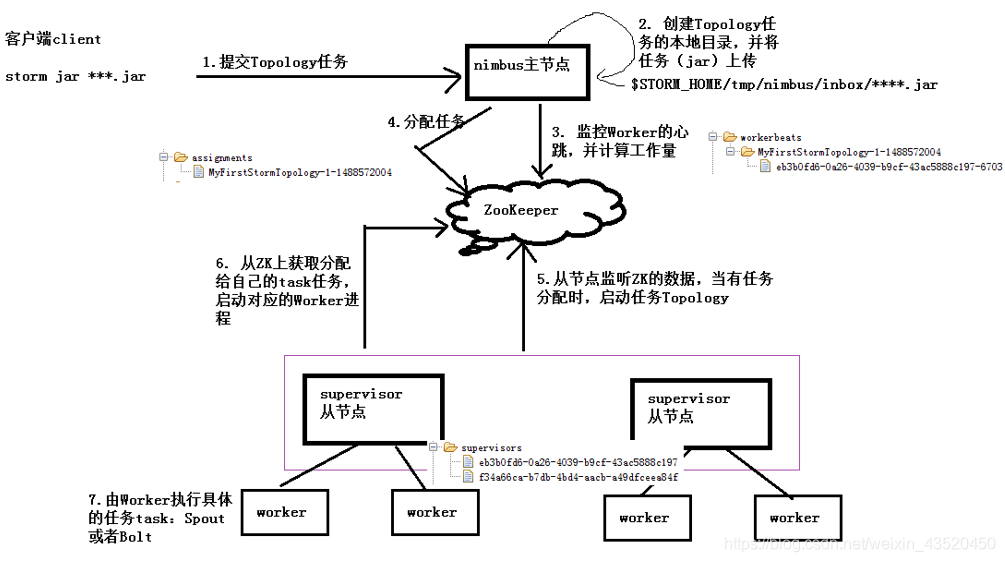
十三、Storm内部通信机制
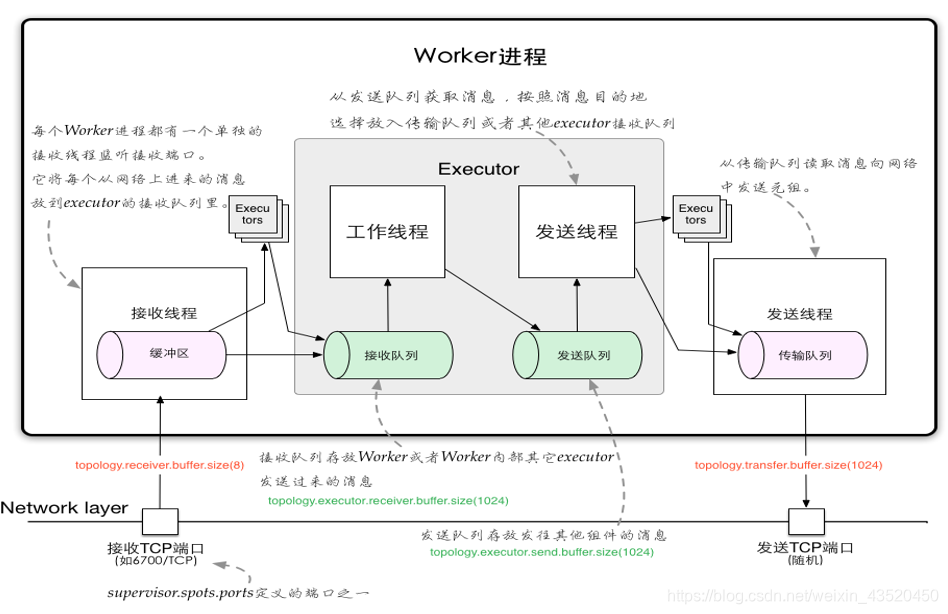
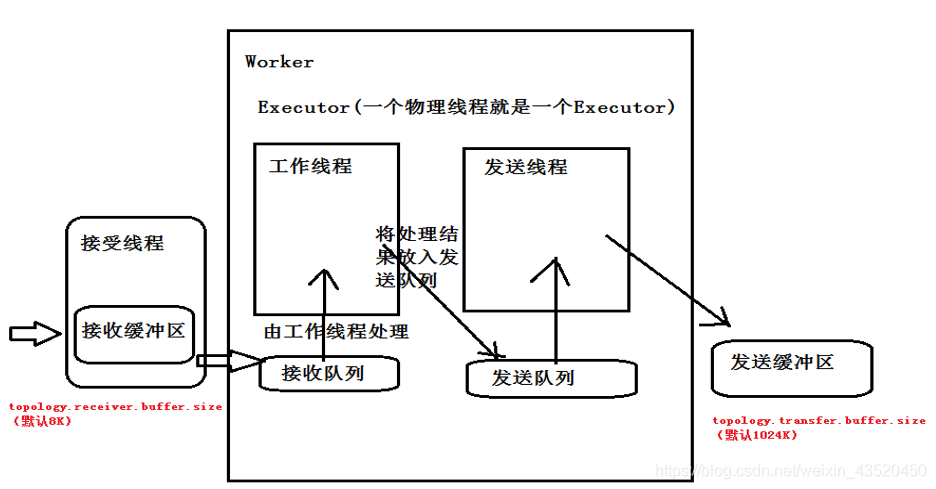














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









