







日志是mysql数据库的重要组成部分,记录着数据库运行期间各种状态信息。mysql日志主要包括重做日志(redo log)、回滚日志(undo log)、二进制日志(bin log)、错误日志(error log)、慢查询日志(slow query log)、一般查询日志(general log),中继日志(relay log)。作为开发,我们重点需要关注的是二进制日志(binlog)和事务日志(包括redo log和undo log),因为他们都与事务操作息息相关。今天跟大家介绍这三种日志。
二进制日志(bin log)
基本概念
bin log由Mysql的Server层实现,是逻辑日志,记录的是sql语句的原始逻辑,记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。什么是逻辑日志,与之对应的还有一个物理日志,介绍一下基本概念:
- 逻辑日志:可以简单理解为记录的就是sql语句;
- 物理日志:因为mysql数据最终是保存在数据页中的,物理日志记录的就是数据页变更。
使用任何存储引擎的mysql数据库都会记录binlog日志,通过追加的方式写入,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。同时可设置参数expire_logs_days,在生成时间超过配置的天数之后,会被自动删除。
使用场景
在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复:
- 主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致;
- 数据恢复:通过使用mysqlbinlog工具来恢复数据。
存储格式
binlog日志有三种格式,分别为STATMENT、ROW和MIXED。在 MySQL 5.7.7之前,默认的格式是STATEMENT,MySQL 5.7.7之后,默认值是ROW。日志格式可以通过binlog-format指定。
(1)STATMENT
基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中。
- 优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO, 从而提高了性能;
- 缺点:在某些情况下会导致主从数据不一致甚至出错,比如执行sysdate()、slepp()等。
(2)ROW
基于行的复制(row-based replication, RBR),不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了。
- 优点:不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题;
- 缺点:磁盘占用会比其他两种模式大很多,在一些大表中清除大量数据时在 binlog 中会生成很多条语句,可能导致从库延迟变大,会产生大量的日志。
(3)MIXED
基于STATMENT和ROW两种模式的混合复制(mixed-based replication, MBR),根据语句来选用是 statement 还是 row 模式。一般的复制使用STATEMENT模式保存binlog,如表结构变更,如果 SQL 语句是 update 或者 delete 语句,或者对于STATEMENT模式无法复制的操作使用ROW模式保存binlog。
刷盘时机
对于InnoDB存储引擎而言,只有在事务提交时才会记录biglog,在那之前记录还在内存中。那么biglog是什么时候刷到磁盘中的呢?mysql通过sync_binlog参数控制biglog的刷盘时机,取值范围是0-N:
- 0:不去强制要求,由系统自行判断何时写入磁盘;
- 1:每次commit的时候都要将binlog写入磁盘;
- N:每N个事务,才会将binlog写入磁盘。
MySQL 5.7.7之后版本的默认值为1,但是设置一个大一些的值可以提升数据库性能,因此实际情况下也可以将值适当调大,牺牲一定的一致性来获取更好的性能。
重做日志(redo log)
基本概念
redo log由引擎层的InnoDB引擎实现,是物理日志,记录的是物理数据页修改的信息,包括两部分:
- 内存中的日志缓冲(redo log buffer),
- 磁盘上的日志文件(redo log file)。
mysql每执行一条DML语句,先将记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。这种先写日志,再写磁盘的技术就是MySQL里经常说到的WAL(Write-Ahead Logging) 技术。redo log是顺序写入指定大小的物理文件中的,是循环写入。当文件快写满时,会边擦除边刷磁盘,即擦除日志记录(redo log file)并将数据刷到磁盘中。
使用场景
事务的四大特性里面有一个是持久性,具体来说就是只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态。那么mysql是如何保证一致性的呢?最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面:
- Innodb是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
- 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差
因此mysql设计了redo log,具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。总结起来redo log的作用如下:
- 提供crash-safe 能力(崩溃恢复),确保事务的持久性;
- 利用WAL技术推迟物理数据页的刷新,从而提升数据库吞吐,有效降低了访问时延。
存储格式
(1)日志块
innodb存储引擎中,redo log以块为单位进行存储的,每个块占512字节,这称为redo log block。所以不管是log buffer中还是os buffer中以及redo log file on disk中,都是这样以512字节的块存储的。每个redo log block由3部分组成:日志块头、日志块尾和日志主体。其中日志块头占用12字节,日志块尾占用8字节,所以每个redo log block的日志主体部分只有512-12-8=492字节。
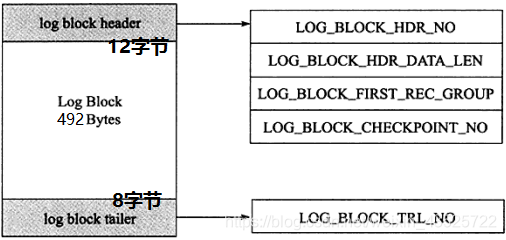
log_block_hdr_no:(4字节)该日志块在redo log buffer中的位置ID。
log_block_hdr_data_len:(2字节)该log block中已记录的log大小。写满该log block时为0x200,表示512字节。
log_block_first_rec_group:(2字节)该log block中第一个log的开始偏移位置。
lock_block_checkpoint_no:(4字节)写入检查点信息的位置。
因为redo log记录的是数据页的变化,当一个数据页产生的变化需要使用超过492字节的redo log来记录,那么就会使用多个redo log block来记录该数据页的变化。关于log block块头的第三部分 log_block_first_rec_group ,因为有时候一个数据页产生的日志量超出了一个日志块,这是需要用多个日志块来记录该页的相关日志。例如,某一数据页产生了552字节的日志量,那么需要占用两个日志块,第一个日志块占用492字节,第二个日志块需要占用60个字节,那么对于第二个日志块来说,它的第一个log的开始位置就是73字节(60+12)。如果该部分的值和 log_block_hdr_data_len 相等,则说明该log block中没有新开始的日志块,即表示该日志块用来延续前一个日志块。日志尾只有一个部分: log_block_trl_no ,该值和块头的 log_block_hdr_no 相等。上面所说的是一个日志块的内容,在redo log buffer或者redo log file on disk中,由很多log block组成。如下图:
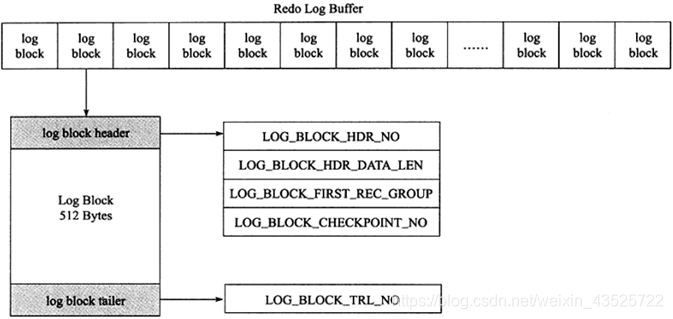
(2) log group和redo log file
log group表示的是redo log group,一个组内由多个大小完全相同的redo log file组成。组内redo log file的数量由变量 innodb_log_files_group 决定,默认值为2,即两个redo log file。这个组是一个逻辑的概念,并没有真正的文件来表示这是一个组,但是可以通过变量 innodb_log_group_home_dir 来定义组的目录,redo log file都放在这个目录下,默认是在datadir下。
mysql> show global variables like "innodb_log%";
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 8388608 |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
+-----------------------------+----------+
[root@kmli data]# ll /mydata/data/ib*
-rw-rw---- 1 mysql mysql 79691776 Mar 30 23:12 /mydata/data/ibdata1
-rw-rw---- 1 mysql mysql 50331648 Mar 30 23:12 /mydata/data/ib_logfile0
-rw-rw---- 1 mysql mysql 50331648 Mar 30 23:12 /mydata/data/ib_logfile1
可以看到在默认的数据目录下,有两个ib_logfile开头的文件,它们就是log group中的redo log file,而且它们的大小完全一致且等于变量 innodb_log_file_size 定义的值。第一个文件ibdata1是在没有开启 innodb_file_per_table 时的共享表空间文件,对应于开启 innodb_file_per_table 时的.ibd文件。在innodb将log buffer中的redo log block刷到这些log file中时,会以追加写入的方式循环轮训写入。即先在第一个log file(即ib_logfile0)的尾部追加写,直到满了之后向第二个log file(即ib_logfile1)写。当第二个log file满了会清空一部分第一个log file继续写入。如下我们定义了四个文件:
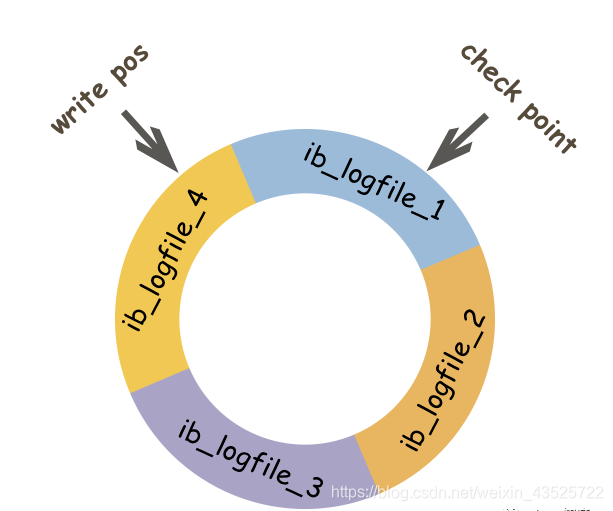
在innodb中,既有redo log需要刷盘,还有数据页也需要刷盘,redo log存在的意义主要就是降低对数据页刷盘的要求。在上图中,write pos表示redo log当前记录的LSN(逻辑序列号)位置,check point表示数据页更改记录刷盘后对应redo log所处的LSN(逻辑序列号)位置。write pos到check point之间的部分是redo log空着的部分,用于记录新的记录;check point到write pos之间是redo log待落盘的数据页更改记录。当write pos追上check point时,会先推动check point向前移动,空出位置再记录新的日志。
在每个组的第一个redo log file中,前2KB记录4个特定的部分,从2KB之后才开始记录log block。除了第一个redo log file中会记录,log group中的其他log file不会记录这2KB,但是却会腾出这2KB的空间。如下:
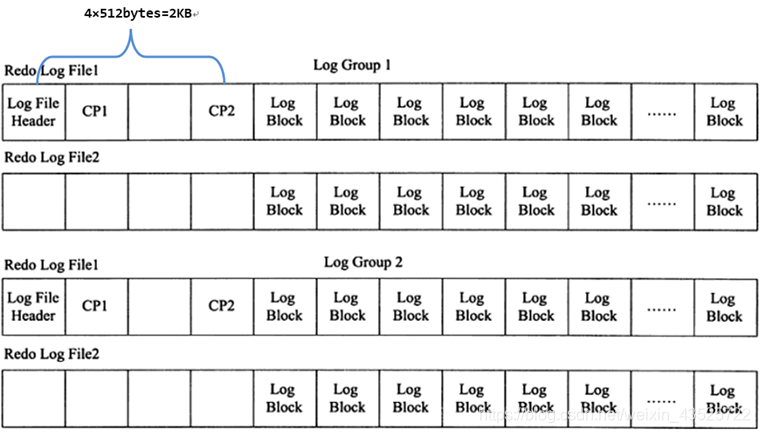
(3)redo log的格式
因为innodb存储引擎存储数据的单元是页(和SQL Server中一样),所以redo log也是基于页的格式来记录的。默认情况下,innodb的页大小是16KB(由 innodb_page_size 变量控制),一个页内可以存放非常多的log block(每个512字节),而log block中记录的又是数据页的变化。其中log block中492字节的部分是log body,该log body的格式分为4部分:
redo_log_type:占用1个字节,表示redo log的日志类型。
space:表示表空间的ID,采用压缩的方式后,占用的空间可能小于4字节。
page_no:表示页的偏移量,同样是压缩过的。
redo_log_body表示每个重做日志的数据部分,恢复时会调用相应的函数进行解析。例如insert语句和delete语句写入redo log的内容是不一样的。
如下图,分别是insert和delete大致的记录方式;
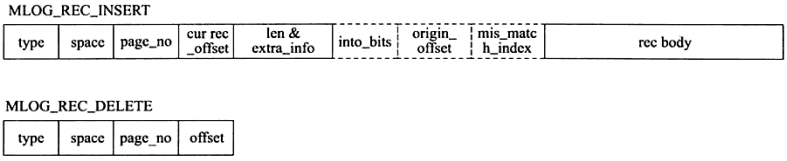
启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如binlog)要快很多。重启innodb时,首先会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从checkpoint开始恢复。还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的LSN大于日志中的LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。另外,事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次。而二进制日志不具有幂等性,多次操作会全部记录下来,在恢复的时候会多次执行二进制日志中的记录,速度就慢得多。例如,某记录中id初始值为2,通过update将值设置为了3,后来又设置成了2,在事务日志中记录的将是无变化的页,根本无需恢复;而二进制会记录下两次update操作,恢复时也将执行这两次update操作,速度比事务日志恢复更慢。
对于redo log的存储的内容其实远不止这些,里面还涉及到很多的地方,这里只是作为大家对这些概念的理解以及入门,后面还有作进一步的讲解。
刷盘时机
在计算机操作系统中,用户空间(user space)下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space)缓冲区(OS Buffer)。因此,redo log buffer写入redo log file实际上是先写入OS Buffer,然后再通过系统调用fsync()将其刷到redo log file中,过程如下:

mysql支持三种将redo log buffer写入redo log file的时机,可以通过innodb_flush_log_at_trx_commit参数配置,各参数值含义如下:
| 参数值 | 含义 |
|---|---|
| 0 | 延迟写。事务提交时不会将redo log buffer中的日志写入os buffer,而是每秒写入os buffer并调用fsync()写入到redo log file中。即大约每秒刷新数据到磁盘中,当系统崩溃时,会丢失一秒的数据 |
| 1 | 实时写,实时刷。事务每次提交都会将redo log buffer中的日志写入os bufferr并调用fsync()写入到redo log file中。这种方式即使系统崩溃也不会丢失任何数据,但因为每次提交都要写入磁盘,IO性能较差 |
| 2 | 实时写,延迟刷。事务每次提交都只会将日志写入os bufferr,然后是每秒调用fsync()将os buffer中的日志写入到redo log file |
每种方式的存储过程如下图所示:

在主从复制结构中,要保证事务的持久性和一致性,需要对日志相关变量设置为如下:
- 如果启用了二进制日志,则设置sync_binlog=1,即每提交一次事务同步写到磁盘中。
- 总是设置innodb_flush_log_at_trx_commit=1,即每提交一次事务都写到磁盘中。
上述两项变量的设置保证了:每次提交事务都写入二进制日志和事务日志,并在提交时将它们刷新到磁盘中。
总结完bin log和redo log,我们在这里做一下两者的对比:
| bin log | undo log | |
|---|---|---|
| 文件大小 | 可通过配置参数max_binlog_size设置每个binlog文件的大小 | 大小固定 |
| 实现方式 | Server层实现,所有引擎都可以使用 | InnoDB引擎实现,不是所有引擎都有 |
| 记录方式 | 追加方式,文件大小大于给定值时,记录到新文件上 | 循坏记录,写到结尾时,会回到开头写 |
| 适用场景 | 主从复制和数据恢复 | 崩溃恢复 |
回滚日志(undo log)
基本概念
undo log由引擎层的InnoDB引擎实现,是逻辑日志,记录数据修改被修改前的值。当一条数据需要更新前,会先把修改前的记录存储在undolog中,如果这个修改出现异常,则会使用undo日志来实现回滚操作,保证事务的一致性。当事务提交之后,undo log并不能立马被删除,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。但是在事务提交的时候,会将该事务对应的undo log放入到删除列表中,未来通过purge来删除。并且提交事务时,还会判断undo log分配的页是否可以重用,如果可以重用,则会分配给后面来的事务,避免为每个独立的事务分配独立的undo log页而浪费存储空间和性能。
通过undo log记录delete和update操作的结果发现:(insert操作无需分析,就是插入行而已):
- delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
- update分为两种情况:update的列是否是主键列。
- 如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。
- 如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
使用场景
数据库事务四大特性中有一个是原子性,原子性底层就是通过undo log实现的。undo log主要记录了数据的逻辑变化,比如一条INSERT语句,对应一条DELETE的undo log,对于每个UPDATE语句,对应一条相反的UPDATE的undo log,这样在发生错误时,就能回滚到事务之前的数据状态:
- 保存事务发生之前的数据的一个版本,用于回滚;
- 可以提供多版本并发控制下的读(MVCC),也即非锁定读。
存储格式
innodb存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。在以前老版本,只支持1个rollback segment,这样就只能记录1024个undo log segment。后来MySQL5.5可以支持128个rollback segment,即支持128*1024个undo操作,还可以通过变量 innodb_undo_logs (5.6版本以前该变量是 innodb_rollback_segments )自定义多少个rollback segment,默认值为128。undo log默认存放在共享表空间中。
[root@kmli data]# ll /mydata/data/ib*
-rw-rw---- 1 mysql mysql 79691776 Mar 31 01:42 /mydata/data/ibdata1
-rw-rw---- 1 mysql mysql 50331648 Mar 31 01:42 /mydata/data/ib_logfile0
-rw-rw---- 1 mysql mysql 50331648 Mar 31 01:42 /mydata/data/ib_logfile1
如果开启了 innodb_file_per_table ,将放在每个表的.ibd文件中。在MySQL5.6中,undo的存放位置还可以通过变量 innodb_undo_directory 来自定义存放目录,默认值为"."表示datadir。默认rollback segment全部写在一个文件中,但可以通过设置变量 innodb_undo_tablespaces 平均分配到多少个文件中。该变量默认值为0,即全部写入一个表空间文件。该变量为静态变量,只能在数据库示例停止状态下修改,如写入配置文件或启动时带上对应参数。但是innodb存储引擎在启动过程中提示,不建议修改为非0的值:
2010-12-08 13:16:00 7f665bfab720 InnoDB: Expected to open 3 undo tablespaces but was able
2010-12-08 13:16:00 7f665bfab720 InnoDB: to find only 0 undo tablespaces.
2010-12-08 13:16:00 7f665bfab720 InnoDB: Set the innodb_undo_tablespaces parameter to the
2010-12-08 13:16:00 7f665bfab720 InnoDB: correct value and retry. Suggested value is 0
猜你感兴趣:
MYSQL专题-绝对实用的MYSQL优化总结
MYSQL专题-MySQL事务实现原理
MYSQL专题-MVCC多版本并发控制
MYSQL专题-使用Binlog日志恢复MySQL数据
更多文章请点击:更多…














 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









