







第一周总结
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
贡献
- 利用深度学习融合 2D 和 3D 信息,提出一个事实在线的 3D 的 MOT 系统
- 贡献了一个 2D+3D 的数据集,此方法作为他们 benchmark 的 baseline
- 效果比较不错
方法:
2D 和 3D 融合的多模态 tracking
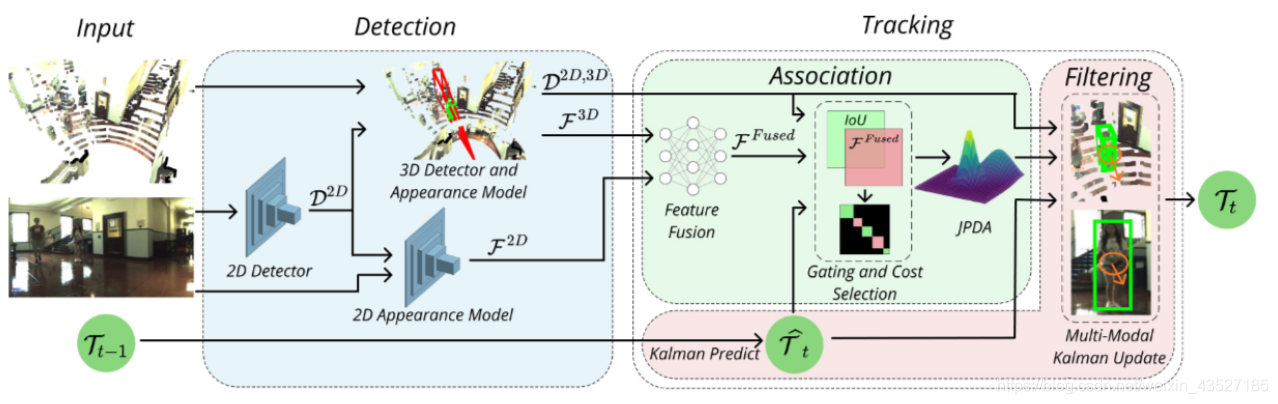
2D detection: Mask R-CNN
2D appearance: reID 方法,对于人的特征:[Aligned-ReID: Surpassing human-level perfor- mance in person re-identification];对于车的特征:[Vehicle re-identification with the space-time prior]
3D detection and appearance: F-pointnet,截取 2D 的 detection 结果的锥形点云进行 3D 的 detection,作者认为 F-pointnet 之所以能检测出物体,说明学到了形状信息,特征就选取倒 数第二层的 feature 作为 appearance
Feature fusion: 将 2D 和 3D 的特征 concat 起来,利用 triplet loss 和 semi-hard negative mining 对 FC layers 进行训练。(截止目前,该模块还未开源)
Data association: 构造 appearance 和 3D IoU 两个 cost matrix,通过一种 entropy measure 的方 法来选择我需要哪个 cost matrix,对每一个 track 的 gating 范围内的 detection 进行 JPDA 式 的关联
Filter: 没细看,也是传统方法
A Baseline for 3D Multi-Object Tracking
贡献:
- 简单但精准的 3D MOT baseline,并且很实时
- 提出一个新的 3D MOT 的评价标准
- KITTI benchmark 上准且快(已不是 sota) 方法:纯点云的 3D tracking
方法:
纯LiDAR(或者Pseudo-LiDAR)的 3D tracking
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









