







《红楼梦》
1.人物出场统计

import jieba
f=open('F:/2级python/test/T10/sucai/红楼梦.txt','r',encoding='utf-8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print('{0:<10}{1:>5}'.format(word,count))
运行结果:
宝玉 3748
什么 1613
一个 1451
贾母 1228
我们 1220
那里 1174
凤姐 1100
王夫人 1011
你们 1009
如今 999
说道 973
知道 967
老太太 966
起来 949
姑娘 941
从结果可以看出并不是都是人物名称,对此,需对代码进行加工:
2. 加工:
引入排除词库excludes
代码:
import jieba
f=open('F:/2级python/test/T10/sucai/红楼梦.txt','r',encoding='utf-8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
excludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
for word in excludes:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(5):
word,count=items[i]
print('{0:<10}{1:>5}'.format(word,count))
运行结果:
宝玉 3748
贾母 1228
凤姐 1100
王夫人 1011
贾琏 670
总结:
可以看出:宝玉出现次数最多,贾母,凤姐,王夫人等出现次数也不少,频率也差不多 从排除词库可看出:作者喜欢用“我们”,“你们”,“姑娘”,“奶奶”等。因此,如果只通过人物名称来判断出场次数似乎不太好。本文将不在此完善该问题。
3.
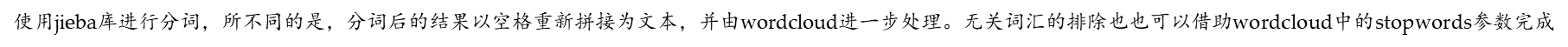
#3人物出场词云
import jieba
from wordcloud import WordCloud
#读文本文件
f=open('F:/2级python/test/T10/sucai/红楼梦.txt','r',encoding='utf-8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
newtxt=' '.join(words)
excludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
wc=WordCloud(background_color='white',font_path='msyh.ttc',height=600,width=800,\
max_words=200,max_font_size=80,stopwords=excludes)
wordcloud=wc.generate(newtxt)
wordcloud.to_file('F:/2级python/test/T10/tmp/红楼梦基本词云.png')
运行结果:


import jieba
from wordcloud import WordCloud
#读文本文件
f=open('F:/2级python/test/T10/sucai/红楼梦.txt','r',encoding='utf-8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
newtxt=' '.join(words)
excludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
wc=WordCloud(background_color='white',font_path='msyh.ttc',height=400,width=200,\
max_words=5,max_font_size=80,stopwords=excludes)
wordcloud=wc.generate(newtxt)
wordcloud.to_file('F:/2级python/test/T10/tmp/红楼梦基本词云.png')
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









