









Hadoop:MapReduce之倒排索引
前言
本案例有一定门槛,需要一点Java基础,Hadoop入门级知识,涉及Maven管理,pom配置文件,Maven打包,Linux虚拟机的使用,Hadoop集群,若阅读期间感觉吃力请自行补课。当然有疑问,也欢迎评论留意或私信我。
一、案例要求
1) 实现倒排索引效果:统计每个单词在不同文件中的出现次数;查看下方的案例说明;
2) 输入:自己编辑几个文件,例如 a.txt,b.txt,c.txt。
每个文件的内容为若干行单词,单词之间以空格分开,
并将这些文件上传到 hdfs 的/reversed 目录下;例如a.txt的内容:
hadoop google scau
map hadoop reduce
hive hello hbase
3) 编写程序实现单词的倒排索引效果;
4) 分区要求:以 A-M 字母开头(包含小写)的单词出现
在 0 区;以 N-Z 字母开头的单词出现在 1 区;其余开
头的单词出现在 2 区;
5) 单词的输出形式:hadoop a.txt->2,b.txt->1,其中
hadoop 是单词(也作为输出的 key),”
a.txt->2,b.txt->1”表示输出的 value,即表示
hadoop 单词在 a.txt 文件中出现次数为 2,在 b.txt
文件中出现次数为 1;
案例说明:
第一次 MapReduce,统计各文档中不同单词的出现次数;SCAU
输出结果(K,V)的形式示例(可以自定义,默认以\t 分
隔)如下:
hadoop->a.txt 2
hadoop->b.txt 1
map->a.txt 1
map->b.txt 1
第二次 MapReduce,将以上结果(路径)作为输入,处理后
输出倒排索引;
输出结果(K,V)的形式为:
hadoop a.txt->2,b.txt->1
map a.txt->1,b.txt->1
其他:根据 context 获取文件名:
FileSplit inputSplit = (FileSplit)
context.getInputSplit();
Path path = inputSplit.getPath();
String filename = path.getName();
二、实现过程
1.IntelliJ IDEA 创建Maven工程
项目层次结构如图:
2.完整代码
ReversedMapper.java
package reversedindex;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ReversedMapper extends Mapper<LongWritable, Text,Text,Text> {
private Text outKey = new Text();
private Text outValue = new Text("1");
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit)context.getInputSplit();
String fileName = inputSplit.getPath().getName();
String[] words = value.toString().split(" ");
for (String word : words) {
outKey.set(word+"->"+fileName);
context.write(outKey,outValue);
}
}
}
ReversedCombiner.java
package reversedindex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReversedCombiner extends Reducer<Text,Text,Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (Text value : values) {
count+=Integer.parseInt(value.toString());
}
String[] words = key.toString().split("->");
outKey.set(words[0]);
outValue.set(words[1]+"->"+count);
context.write(outKey,outValue);
}
}
ReversedPartitioner.java
package reversedindex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ReversedPartitioner extends Partitioner<Text,Text> {
@Override
public int getPartition(Text text, Text text2, int i) {
char head = Character.toLowerCase(text.toString().charAt(0));
if(head>='a'&& head<='m')
return 0;
else if(head>'m'&& head<='z')
return 1;
else
return 2;
}
}
ReversedReducer.java
package reversedindex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReversedReducer extends Reducer<Text,Text, Text,Text> {
private Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder stringBuilder = new StringBuilder();
for (Text value : values) {
stringBuilder.append(value.toString()).append(",");
}
String outStr = stringBuilder.substring(0,stringBuilder.length()-1);
outValue.set(outStr);
context.write(key,outValue);
}
}
ReversedIndex.java
package reversedindex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReversedIndex{
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(ReversedIndex.class);
job.setMapperClass(ReversedMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReversedReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setCombinerClass(ReversedCombiner.class);
job.setPartitionerClass(ReversedPartitioner.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>MapReduceExp3</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop.version>3.1.3</hadoop.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.Maven打包
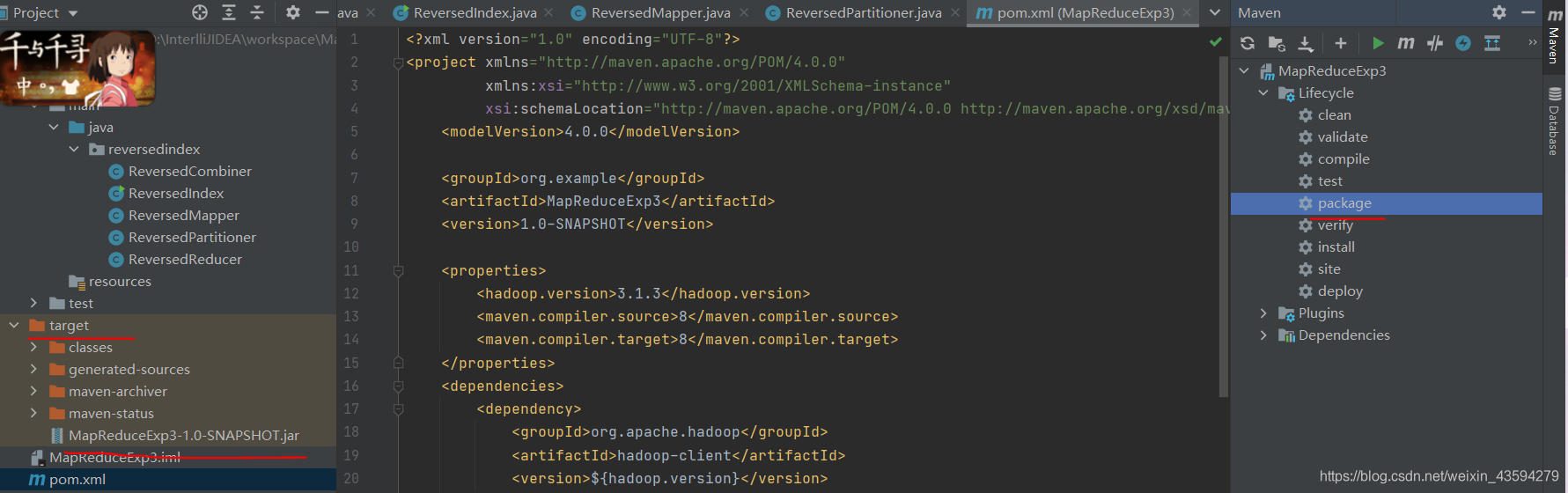
如图所示,在右侧点击Maven的package进行打包,打包结果会在左侧的target文件夹中输出。最终需要的只是标红的Jar包。
4.Hadoop集群运行
前序的配置步骤此处跳过,将本地Jar包发送到主节点主机自选的文件夹,然后开启start-dfs.sh和start-yarn.sh开启hdfs和yarn集群,在hdfs里新建reversed文件夹,通过浏览器localhost:9870打开hdfs可视化网页,竟然文件夹管理上传a.txt,b.txt等到reversed文件夹里。
主节点主机上执行:hadoop jar 指定jar包 项目java目录开始的主类路径 /reversed 不存在的输出文件夹
本案例指令供参考对照 :
hadoop jar MapReduceExp3-1.0-SNAPSHOT.jar reversedindex.ReversedIndex /reversed /reversed_out
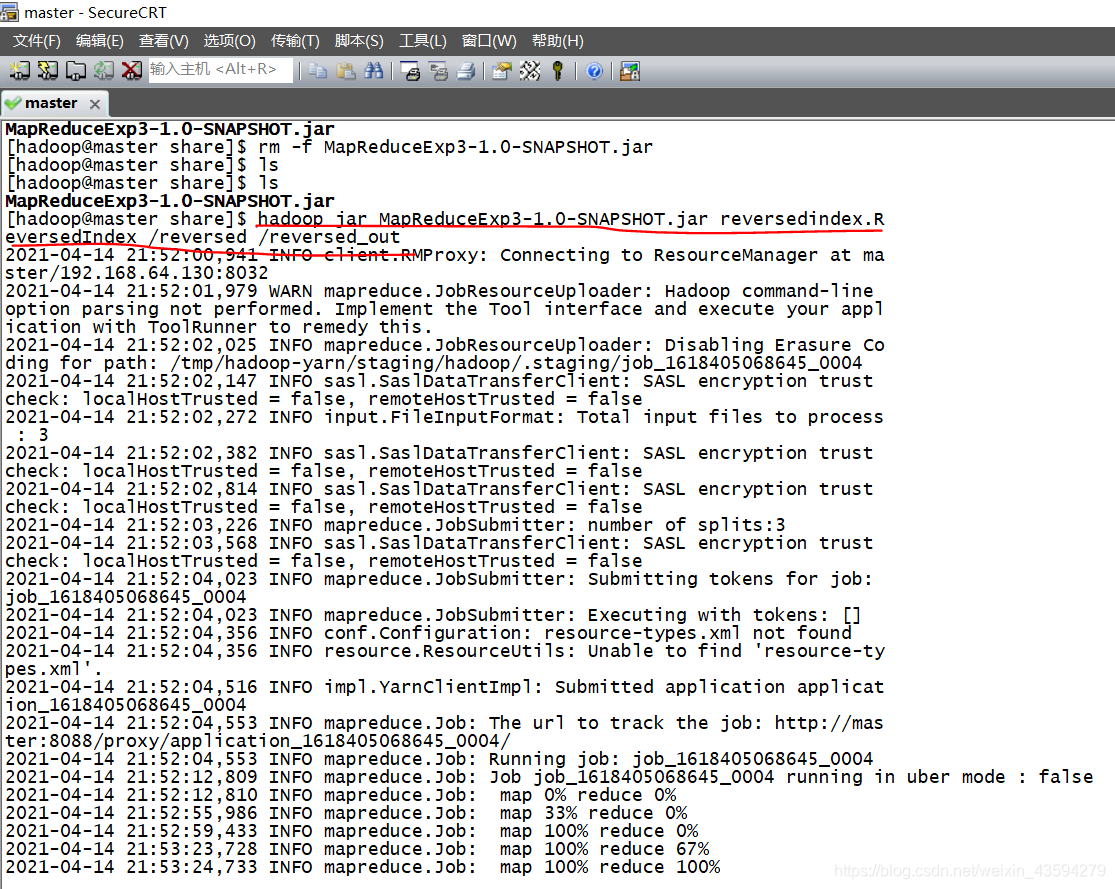
运行完毕后可在hdfs可视化页面查看reversed_out文件夹中的结果。
推荐Hadoop学习视频
黑马的课程,亲测很不错:https://www.bilibili.com/video/BV1JT4y1g7nM
解决本案例的视频讲解,适合快速入门:
Hadoop之MapReduce实战-倒排索引(上)https://www.bilibili.com/video/BV1Vt411v7jH
MapReduce实战-倒排索引(下):https://www.bilibili.com/video/BV1Lt411v7nZ














 2511
2511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









