







1. 编译器/编译程序
把计算机高级语言 (源语言)编写的程序(源程序)翻译成该计算机的汇编语言或机器语言(目标语言)书写的程序(目标程序)的计算机程序称为编译器(或编译程序)。
2. 图灵机
1) 什么是图灵机
图灵机(英语:Turing machine),又称确定型图灵机,是一种将人的计算行为抽象化的数学逻辑机,其更抽象的意义为一种计算模型,可以看作等价于任何有限逻辑数学过程的终极强大逻辑机器。
所谓的图灵机就是指一个抽象的机器,它有一条无限长的纸带,纸带分成了一个一个的小方格,每个方格有不同的颜色。有一个机器头在纸带上移来移去。机器头有一组内部状态,还有一些固定的程序。在每个时刻,机器头都要从当前纸带上读入一个方格信息,然后结合自己的内部状态查找程序表,根据程序输出信息到纸带方格上,并转换自己的内部状态,然后进行移动。
2) 图灵机的基本思想
图灵的基本思想是用机器来模拟人们用纸笔进行数学运算的过程,他把这样的过程看作下列两种简单的动作:
a) 在纸上写上或擦除某个符号;
b) 把注意力从纸的一处移动到另一处;
而在每个阶段,人要决定下一步的动作,依赖于(a)此人当前所关注的纸上某个位置的符号和(b)此人当前思维的状态。
3. 解释程序
工作方式:边解释边执行。
它以源程序为输入,在执行过程中不产生目标程序(代码),而是边解释边执行,即直接执行源程序中蕴含的操作。
4. 编译阶段的组合——前端与后端
-
前端(Front-End)—与目标机无关的部分
包括分析部分(词法、语法、语义分析)、中间代码生成与优化以及这部分的符号表管理错误处理。 -
后端(Back-End)—的与目标机有关部分
包括目标代码生成、与目标机有关的优化以及这部分的符号表管理和错误处理工作。
5. 编译器逻辑结构的组成
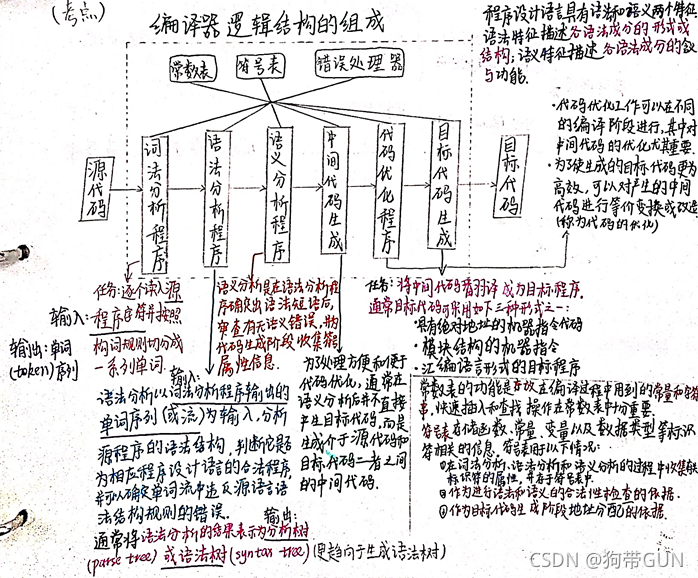
6. 词法分析器的输出
token序列,每个token包括两个方面的内容:token = 字符串(词义)+ 类型(词法)。
7. 正则表达式和有穷自动机
1) 正则表达式
- 正规表达式(也称正则表达式):是用特定的运算符及运算对象按规则构造的表达式。
- 每个正规表达式匹配(或代表、或表示)一个字符串的集合(称为正规集)。
- 正规表达式是一种技术手段:用有限的表达式去解决无限个字符串匹配的问题。
- 它是描述语言词法规则的形式化工具。
2) 从正则表达式到有限自动机
-
正规式是单词的一种描述工具。由于正规式的简洁性,趋向于用正规式来描述单词,然后构造等价的有限自动机。
-
有限自动机可以描述输入串被识别的过程,可以根据有限自动机构造词法分析程序。

-
正规式和有限自动机之间可以相互转换,它们之间存在着等价性。
8. chomsky文法
1) 分类
-
0 0 0 型文法:若文法 G G G 中任一产生式 α → β α→β α→β,都有 α ∈ ( V N ∪ V T ) + α∈(V_N∪V_T)^+ α∈(VN∪VT)+, β ∈ ( V N ∪ V T ) ∗ β∈(V_N∪V_T)^* β∈(VN∪VT)∗ ,则称 G G G 为 0 0 0 型文法。
-
1 1 1 型文法(上下文有关文法):若文法 G G G 中任一产生式 α → β α→β α→β,都有 α ∈ ( V N ∪ V T ) + α∈(V_N∪V_T)^+ α∈(VN∪VT)+, β ∈ ( V N ∪ V T ) ∗ , ∣ β ∣ ≥ ∣ α ∣ β∈(V_N∪V_T)^* , |β|≥|α| β∈(VN∪VT)∗,∣β∣≥∣α∣, 仅仅 S → ε S→ε S→ε 除外,则称 G G G 为 1 1 1 型文法。
-
2 2 2 型文法:若文法 G G G 中任一产生式 α → β α→β α→β,都有 α ∈ V N α∈V_N α∈VN, β ∈ ( V N ∪ V T ) ∗ β∈(V_N∪V_T)^* β∈(VN∪VT)∗ ,则称G为2型文法,也称为上下文无关文法。(对程序设计语言最有用)
-
3 3 3 型文法:通常,把右线性文法及左线性文法统称为 3 3 3 型文法或正规文法。
2) 文法和语言
- 0 0 0 型文法产生的语言称为0型语言,它可由图灵机识别。
- 1 1 1 型文法或上下文有关文法(CSG)产生的语言称为1型语言或上下文有关语言(CSL),它可由线性线界自动机识别。
- 2 2 2 型文法或上下文无关文法(CFG)产生的语言称为2型语言或上下文无关语言(CFL),它可由下推自动机识别。
- 3 3 3 型文法或正则(正规)文法(RG)产生的语言称为 3 3 3 型语言正则(正规)语言(RL),它可由有限自动机识别。
★
\bigstar
★ 2型文法(即上下文无关文法)是描述程序设计语言语法的形式化工具;
★
\bigstar
★ 3型文法是是描述程序设计语言词法的形式化工具。
3) 语言之间的关系
- 0 0 0 型语言包含 1 1 1 型语言。
- 1 1 1 型语言包含 2 2 2 型语言。
- 2 2 2 型语言包含 3 3 3 型语言。
9. 语法分析
1) 自上而下的语法分析(LL 、递归下降)
a) 自上而下的语法分析算法
- 已知文法 G [ S ] G[S] G[S],对任意输入串 w w w,若从文法的开始符号 S S S 出发, 能为 w w w 构造一个最左推导,则 w w w 是一个合法的句子,即 w ∈ L ( G ) w \in L(G) w∈L(G),否则 w w w 有语法错误。
- 该算法自上而下为w的分析结果建立一棵语法树。
⧫
\blacklozenge
⧫ 从文法开始符号
S
S
S 出发试图为输入符号串构造一个最左推导;
⧫
\blacklozenge
⧫ 构造最左推导的过程就是选择产生式和匹配符号串的过程;
⧫
\blacklozenge
⧫ 有时需要重复扫描词法分析输出的单词序列。
b) 递归下降分析方法
递归下降分析方法是一种自上而下的语法分析方法,该方法执行一组递归函数判断输入的单词序列是否符合语法规则。
c) 语法分析的基本步骤
- 对程序设计语言的语法规则进行形式化描述(用 2 2 2 型文法);
- 根据语言的语法描述形式,定义各种基本语法结构的抽象语法树;
- 选择一种合适的语法分析算法,并在分析程序中插入动作(…) -----语法分析程序。
d) LL(1)分析
L L ( 1 ) LL (1) LL(1) 分析方法是一种自上而下的语法分析方法:
- 第1个“ L L L”指的是由左向右地处理输入;
- 第2个“ L L L”指的是它为输入串找出一个最左推导;
- 括号中的数字 1 1 1 意味着它使用输入单词序列中的一个单词预测分析的动作。
构造 L L ( 1 ) LL(1) LL(1) 分析表的步骤:
- 求 F i r s t First First 集合;
- 求 F o l l o w Follow Follow 集合;
- 构造 L L ( 1 ) LL(1) LL(1) 分析表。
2) 自下而上的语法分析(LR)
a) 自下而上的语法分析方法
- 从输入单词序列开始,自左至右逐步进行归约,试图将其归约为文法的开始符号。
- 从输入单词序列开始,以单词作为语法树的叶节点,自底向上地构造语法分析的结果----语法树。
- 在自下而上语法分析工作的每一步,都是从当前串中选择一个子串,将它归约到某个非终结符号。
- 自下而上的语法分析算法通常采用规范归约,即规范推导的逆过程。
⧫ \blacklozenge ⧫ 规范规约的每一步是从当前的规范句型中将句柄归约为相应的非终结符。
b) LR分析概览
LR分析法是一种有效的自下而上的语法分析技术,它能适用于大部分上下文无关文法的分析,一般叫 L R ( k ) LR(k) LR(k) 分析方法,其中:
- L L L 是指自左(Left)向右分析输入单词序列;
- R R R 是指分析过程都是构造最右(Right)推导的逆过程(规范归约);
- 括号中的 k k k 是指在决定当前分析动作时向右看的单词个数。
★
\bigstar
★ 应用面广:能够通过
L
R
LR
LR 分析程序识别所有采用上下文无关文法描述的程序设计语言的语法结构;
★
\bigstar
★ 能有效实现:是无回溯的移进—归约方法;
★
\bigstar
★ 容易查错:
L
R
LR
LR 分析器能够及时发现语法错误和准确指出错误位置。
10. 运行时环境
目标代码运行时,存储空间的组织称为目标代码的运行时环境。

1) 程序执行时的存储器组织
目标代码运行时,操作系统为目标代码的运行分配的存储空间按用途可划分为下面几个部分:
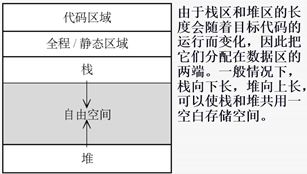
- 代码区域:目标代码的存储区域,由于代码区在执行之前是固定的,在编译时所有目标代码的地址都是可计算的,程序执行结束后代码区域内存由系统释放。
- 全程/静态区域:静态数据区用来存放那些具有绝对地址的数据和变量(如静态变量和全程变量);编译器可以确定其所占用存储空间的大小,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域,程序执行结束后由系统释放。
- 栈区:函数中的形参和在函数中定义的局部变量以及局部临时变量(C、C++、Java),这些变量分配在栈区,每次函数执行的时候会在栈中为函数的执行分配相应的存储区,而在函数执行完毕后,释放相应的存储区。
- 堆区:供用户动态申请存储空间,编译器“不需要”知道究竟得从
h
e
a
p
heap
heap 中分配多少空间,也不需要知道从
h
e
a
p
heap
heap 上分配的空间究竟需要存在多久。
在C中由 m a l l o c , f r e e malloc,free malloc,free 运算产生释放的存储空间,在C++中由 n e w new new 和 d e l e t e delete delete 运算符作用的存储空间,以及在Java中由 n e w new new 分配的存储空间都在堆中进行分配。
2) 活动记录
- 在C语言中, 采用以函数(或过程)为单位的动态存储分配方案:
当一函数被调用时,就在栈顶为该函数分配所需的数据空间(过程活动记录),当一个函数工作完毕返回时,它在栈顶的数据空间(过程活动记录)也即释放。 - 过程的活动记录(activation record, AR)是一段连续的存储区,用于存放函数的一次执行所需要的信息,当调用或激活函数时,必须为被调用函数的活动记录分配空间。
- 活动记录存放的信息至少应包括以下几个部分:

3) 堆管理
- 对于允许程序为变量在运行时动态申请和释放存储空间的语言,采用堆式分配是最有效的解决方案。
- 堆式分配的基本思想是,为运行的程序划出适当大的空间(称为堆 H e a p Heap Heap),每当程序申请空间时,就从堆的空闲区找出一块空间分配给程序,每当释放时则回收之。















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











