






“One Millisecond Face Alignment with an Ensemble of Regression Trees”使用归一法实现人脸特征检测,测试基准下达到99.38%。python中DLIB提供了各种使用方法(https://github.com/ageitgey/face_recognition#face-recognition)。
- 1.环境布置
已有环境未win10,Anaconda3,python3.6.7
①安装vs2017
(https://visualstudio.microsoft.com/zh-hans/?rr=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D5_Ryn-MeARNb9X8OwevGZ1ws1sOoXa-aqfaRbnEf0iuPHwUrSPhYk_7YfudLNNLh%26wd%3D%26eqid%3Df7742a880001b4cb000000055ad6bd7b)
enterprise2017
②安装boost
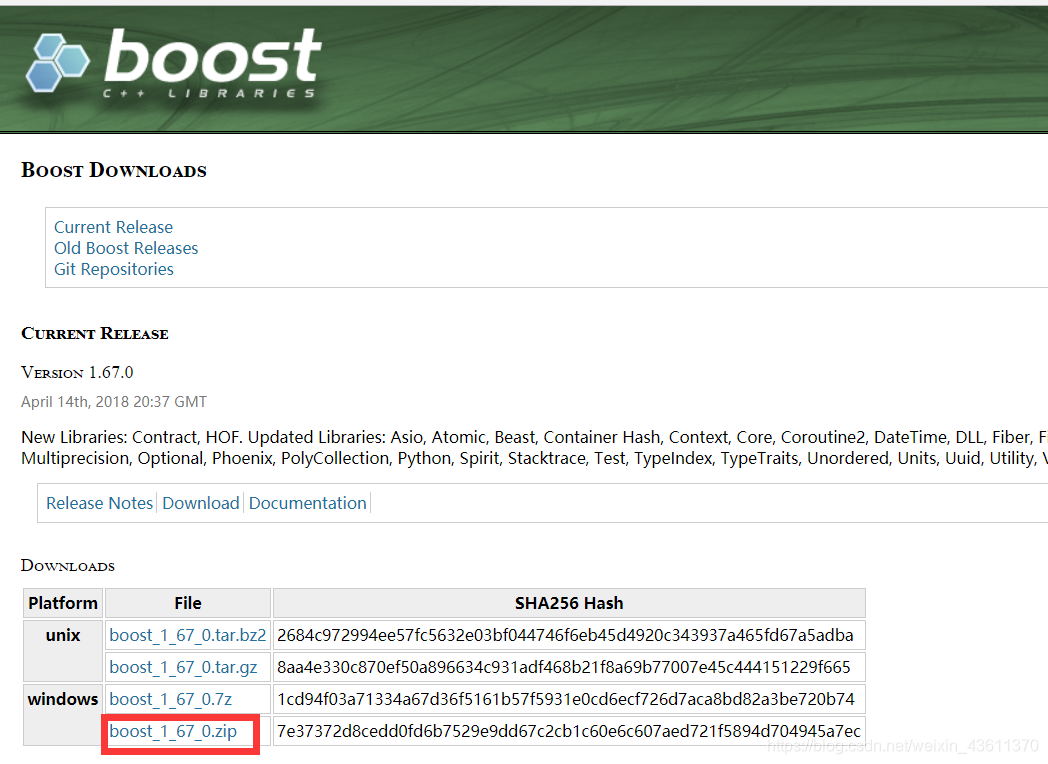
https://www.boost.org/users/download/
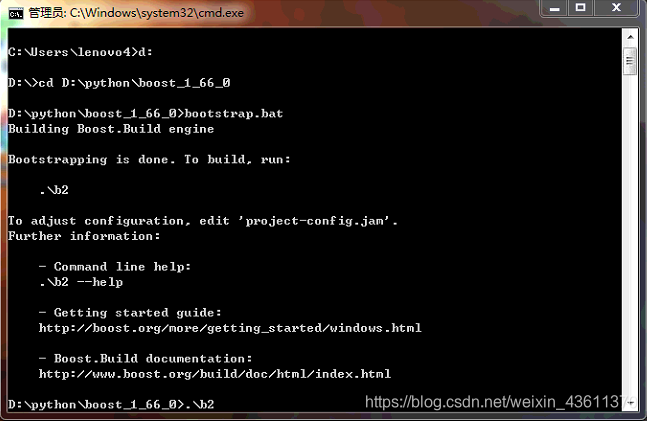
下载后解压boost压缩文件,在cmd界面中,进入boost解压目录中 输入:bootstrap.bat 回车
出现如下界面:
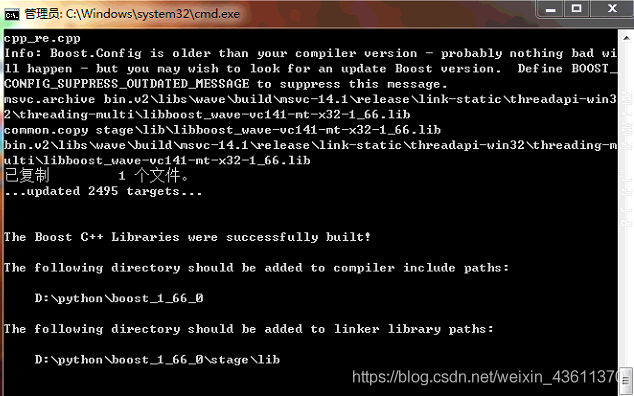
继续输入:.\b2 回车 (我编译时长1个小时)
③安装cmake
https://cmake.org/download/
进入如下页面:
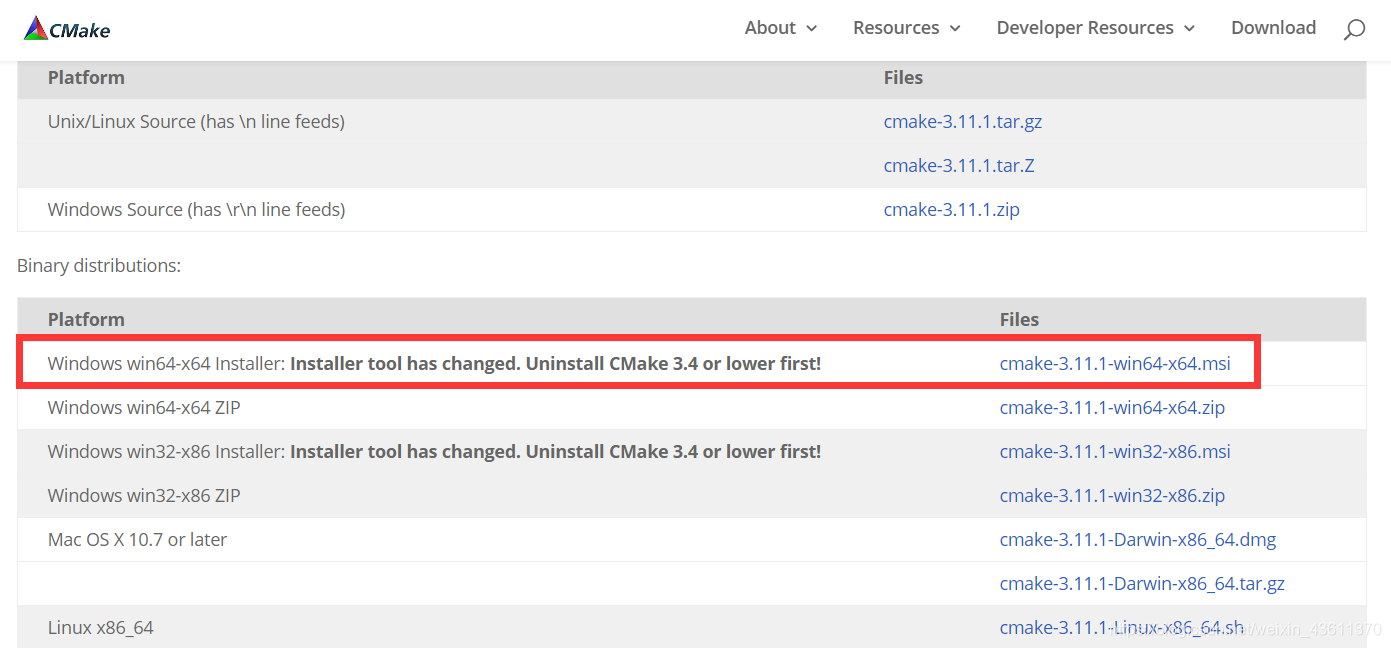
接下来安装进入如下界面:
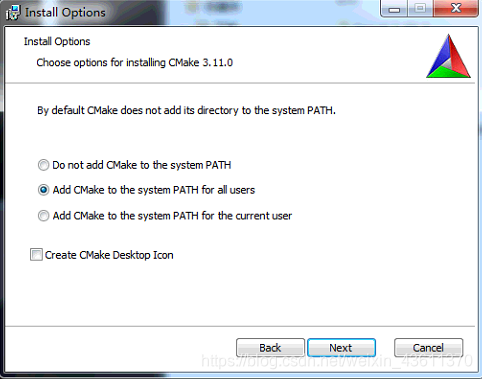
选择 Add CMake to the system PATH for all users
④安装DLIB
http://dlib.net/

解压后,重新打开cmd界面内,进入dlib的解压目录,输入:python setup.py install,也可通过Anaconda命令实现:
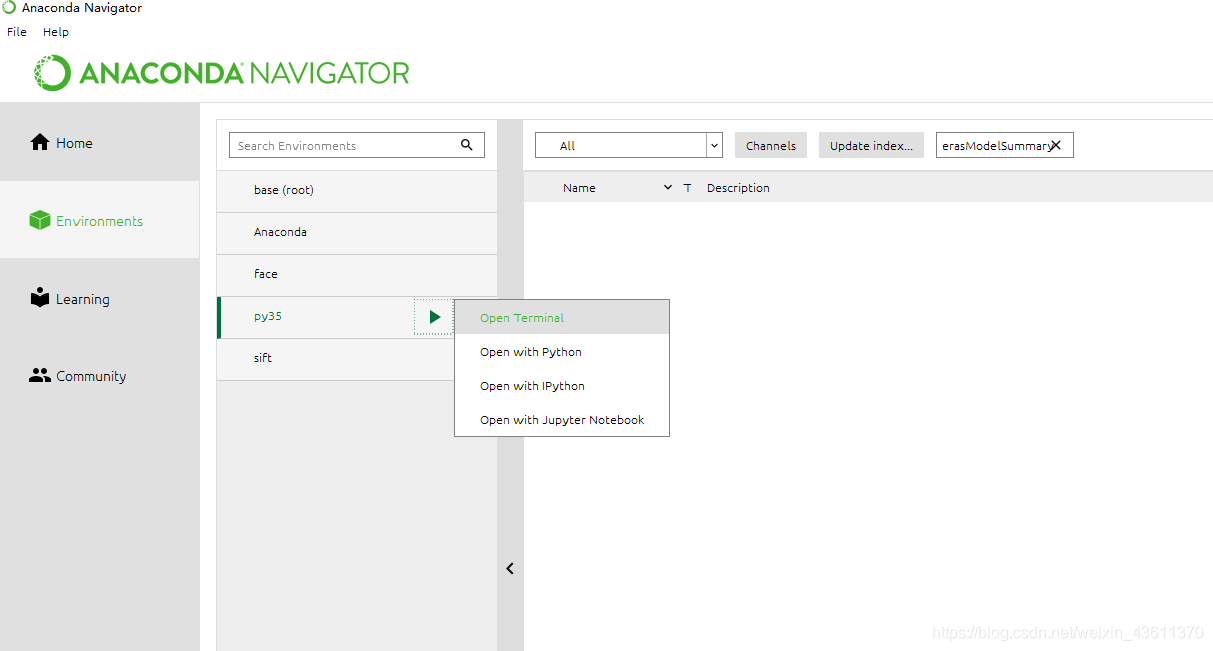
⑤安装face_recognition
pip install face_recognition
也可下载后安装
进入编辑器检验后,确定安装完成。
2.代码实现
import face_recognition
import cv2
# video_capture = cv2.VideoCapture(0) #摄像头获取视频
cap = cv2.VideoCapture(r"D:\Xu\other\S01E01.mp4") #本地获取视频
# 本地图像
hhj_image = face_recognition.load_image_file(r"D:\Xu\SIFT\faceT\timg111.jpg")
hhj_face_encoding = face_recognition.face_encodings(hhj_image)[0]
face_locations = []
face_encodings = []
face_names = []
process_this_frame = True
while True:
# 读取视频画面
# ret, frame = video_capture.read(r"D:\Xu\other\S01E01.mp4")
ret, frame = cap.read()
# 改变摄像头图像的大小,图像小,所做的计算就少
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# opencv的图像是BGR格式的,而我们需要是的RGB格式的,因此需要进行一个转换。
rgb_small_frame = small_frame[:, :, ::-1]
# Only process every other frame of video to save time
if process_this_frame:
# 根据encoding来判断是不是同一个人,是就输出true,不是为flase
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
# 默认为unknown
match = face_recognition.compare_faces([hhj_face_encoding], face_encoding)
name = "Unknown"
if match[0]:
name = "Feib"
face_names.append(name)
process_this_frame = not process_this_frame
# 将捕捉到的人脸显示出来
for (top, right, bottom, left), name in zip(face_locations, face_names):
# Scale back up face locations since the frame we detected in was scaled to 1/4 size
top *= 4
right *= 4
bottom *= 4
left *= 4
# 矩形框
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
#加上标签
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
# Display
cv2.imshow('Video', frame)
# 按Q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()














 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









