







参考https://blog.csdn.net/m0_37870649/article/details/80979809
df_Apurchase_by_UID_Gender=data.groupby(['User_ID','Gender']).agg({'Purchase':np.mean}).reset_index()
print(df_Apurchase_by_UID_Gender.head())
#表示对数据data(DataFrame数据结构)按’User_ID’和’Gender’分组,并计算’Purchase’的均值
reset_index()表示重新设置行索引
输出:
User_ID Gender Purchase
0 1000001 F 9808.264706
1 1000002 M 10662.539474
2 1000003 M 11780.517241
3 1000004 M 15845.153846
4 1000005 M 7745.292453
这里agg()一般用于针对某列使用agg()时进行不同的统计运算
例如:
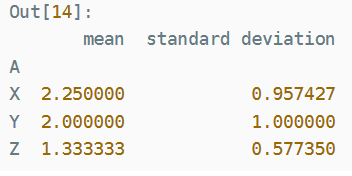
df.groupby('A')['B'].agg({'mean':np.mean, 'standard deviation': np.std})
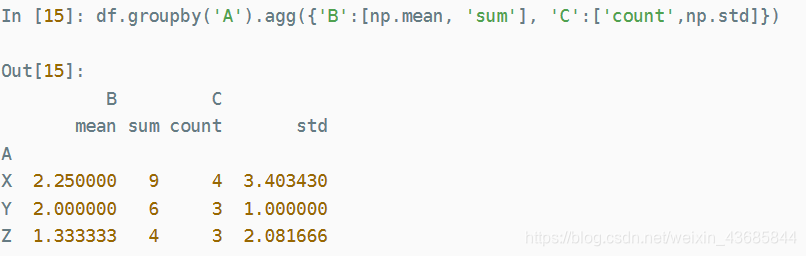
也可以针对不同的列应用多种不同的统计方法














 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









