








论文链接:https://arxiv.org/pdf/2106.08062.pdf![]() http://SSMix: Saliency-Based Span Mixup for Text Classification论文代码:
http://SSMix: Saliency-Based Span Mixup for Text Classification论文代码:
https://github.com/clovaai/ssmix![]() https://github.com/clovaai/ssmix
https://github.com/clovaai/ssmix
目录
1、Abstract
在计算机视觉任务中,mixup数据增强已被证明是有效的。但文本是由长度可变的离散标记组成,将mixup应用于NLP任务仍然存在一定障碍。
这一篇文章提出一种新的混合方法(SSMix),通过在输入文本上进行操作,而不是在隐藏向量上操作。SSMix通过基于广度的mixup保持两个原始文本的局部性,并根据显著性信息保留更多与预测相关的标记。
实验验证在文本分类基准上优于隐藏层混合方法,包括文本蕴涵、情感分类和问题类型分类。
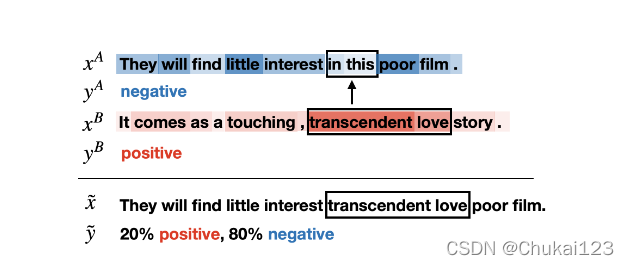
和
分别标记为negative和positive。其中颜色越深表示对相应单词的贡献越大。从
中选出贡献值最小的单词,并用
中贡献值最大的单词替换它。输出结果为
=mixup(
,
)。同时设置了一个mixup比例
,图1中
设置为0.2,因为序列的总长度为10,替换了两个单词,2/10=0.2。
SSMix方法具体流程:
(1)首先,将连续标记的范围替换为另一个文本中的范围来进行合成,以保留混合文本中两个源文本的位置;
(2)根据显著性信息选择要替换的范围和要替换的范围,以使混合文本包含与输出预测更相关的标记,这在语义上可能很重要。
2、SSMix
基于显著性信息将一个文本中的部分段替换为另一个文本中的部分段从而合成一个新的文本。具体示意图如图1所示。
3、Saliency
显著性度量数据的每个部分(本文为token)如何影响最终的预测,一般是采用基于梯度的方法计算显著性;本文通过计算分类损失相对于输入嵌入
的梯度,并使用其大小s作为显著性:
然后使用L2-norm获得梯度向量的大小,然后将梯度向量作为每个token的显著性;
4、Mixing text
文本数据和
是离散的序列,采用显著性得分,
中长度为
的最不显著性区域表示为
,对于
中长度为
的最显著性区域表示为
。其中
表示之前的mixup比(混合比);
最终的输出为:
,其中
和
是原始文本
中分别位于
的左侧和右侧的token;
5、same span length
将原始跨度和替换跨度
的长度设置为相同大小,主要是考虑到不同的跨度长度将导致冗余和不明确的混合变化,并且计算不同跨度之间的混合比过于复杂。在跨度长度相同的情况下,本文的方法使得显著性的效果最好;由于SSMix不限制token的位置,可以选择最显著的跨度,并在其他文本上用最不显著的跨度替换它;
6、Mixing label
将标签的混合比设置为
,这个混合比与之前的
不同。
的标签设置为
,
算法1显示了如何利用原始样本计算增强样本的mixup损失;根据每个样本的原始目标标签计算增强输出Logits的交叉损失,并通过加权和将其组合;
应用SSMix与分类数据集的标签总数无关,在任何数据集上,输出标签比例都是通过两个标签的线性组合来计算的。

7、Paired sentence tasks
对于需要一对文本作为输入的任务,如文本隐含推理和相似性分类。SSMix以成对的方式进行混合,通过聚合每个mixup结果中的标记计数来计算mixup比例。对于给定样本:
合成的新样本为:
其中mixup的混合比为:
其中ps和qs为每个mixup操作中的替换片段。
具体过程如下图所示:

在这个例子中:
为 "Fun for only children."
为 "Fun for adults and children."
为 "Problems in data synthesis."
为 "Issues in data synthesis."
=(1+1)/(5+6)=2/11
0.18。
剩下都是实验结果部分,本文就不再赘述,重点关注方法部分。感兴趣的可以看原论文。















 9293
9293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











