






yolox代码
yolox结构瞄一眼
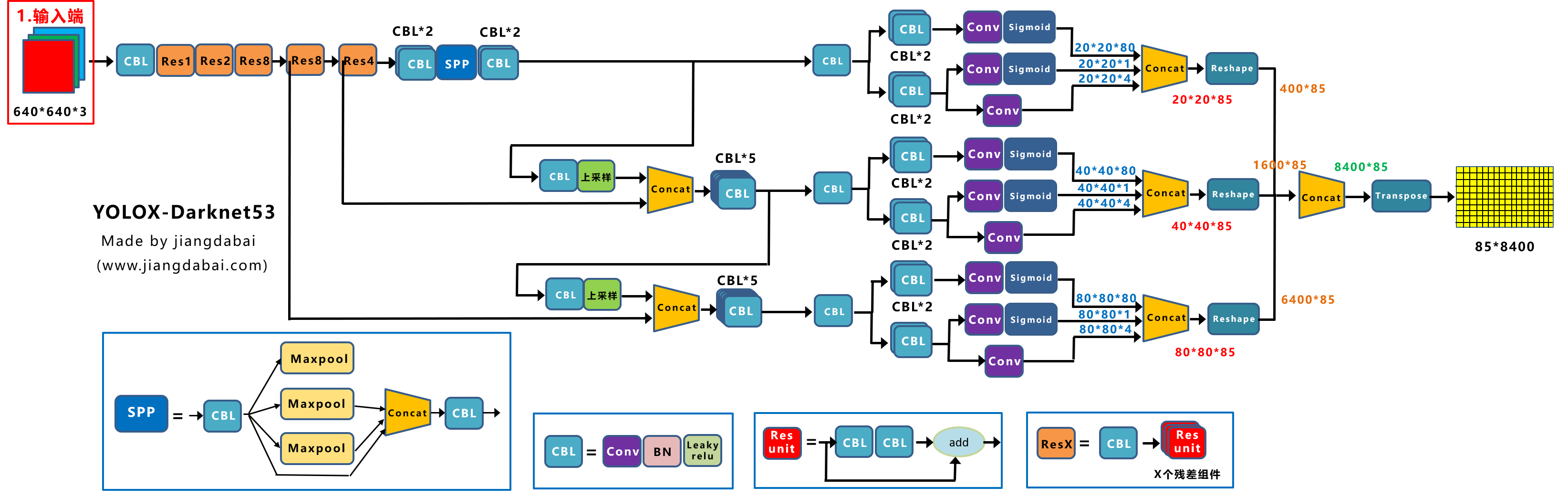
net.py代码
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import torch
from torch import nn
class SiLU(nn.Module):
@staticmethod
def forward(x):
#静态方法
return x * torch.sigmoid(x)
def get_activation(name="silu", inplace=True):
#根据name,构造module
if name == "silu":
module = SiLU()
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class Focus(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
#标准卷积组合块CBA
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
#4块区域,stride=2
patch_top_left = x[..., ::2, ::2]
patch_bot_left = x[..., 1::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_right = x[..., 1::2, 1::2]
#cat 堆叠
x = torch.cat((patch_top_left, patch_bot_left, patch_top_right, patch_bot_right,), dim=1,)
return self.conv(x)
class BaseConv(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):
super().__init__()
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=ksize, stride=stride, padding=pad, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001, momentum=0.03)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):#不经过bn操作
return self.act(self.conv(x))
class DWConv(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(in_channels, in_channels, ksize=ksize, stride=stride, groups=in_channels, act=act,) #不扩展通道,进行宽高信息混合
self.pconv = BaseConv(in_channels, out_channels, ksize=1, stride=1, groups=1, act=act) #pointwise进行通道上的信息混合
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class SPPBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2) for ks in kernel_sizes])
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
#--------------------------------------------------#
# 残差结构的构建,小的残差结构
#--------------------------------------------------#
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, in_channels, out_channels, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
#--------------------------------------------------#
# 利用1x1卷积进行通道数的缩减。缩减率一般是50%
#--------------------------------------------------#
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
#--------------------------------------------------#
# 利用3x3卷积进行通道数的拓张。并且完成特征提取
#--------------------------------------------------#
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class CSPLayer(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion)
#--------------------------------------------------#
# 主干部分的初次卷积
#--------------------------------------------------#
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
#--------------------------------------------------#
# 大的残差边部分的初次卷积
#--------------------------------------------------#
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
#-----------------------------------------------#
# 对堆叠的结果进行卷积的处理
#-----------------------------------------------#
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
#--------------------------------------------------#
# 根据循环的次数构建上述Bottleneck残差结构
#--------------------------------------------------#
module_list = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act) for _ in range(n)]
self.m = nn.Sequential(*module_list)
def forward(self, x):
#-------------------------------#
# x_1是主干部分
#-------------------------------#
x_1 = self.conv1(x)
#-------------------------------#
# x_2是大的残差边部分
#-------------------------------#
x_2 = self.conv2(x)
#-----------------------------------------------#
# 主干部分利用残差结构堆叠继续进行特征提取
#-----------------------------------------------#
x_1 = self.m(x_1)
#-----------------------------------------------#
# 主干部分和大的残差边部分进行堆叠
#-----------------------------------------------#
x = torch.cat((x_1, x_2), dim=1)
#-----------------------------------------------#
# 对堆叠的结果进行卷积的处理
#-----------------------------------------------#
return self.conv3(x)
class CSPDarknet(nn.Module):
def __init__(self, dep_mul, wid_mul, out_features=("dark3", "dark4", "dark5"), depthwise=False, act="silu",):
super().__init__()
assert out_features, "please provide output features of Darknet"
self.out_features = out_features
Conv = DWConv if depthwise else BaseConv
#-----------------------------------------------#
# 输入图片是640, 640, 3
# 初始的基本通道是64
#-----------------------------------------------#
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
#-----------------------------------------------#
# 利用focus网络结构进行特征提取
# 640, 640, 3 -> 320, 320, 12 -> 320, 320, 64
#-----------------------------------------------#
self.stem = Focus(3, base_channels, ksize=3, act=act)
#-----------------------------------------------#
# 完成卷积之后,320, 320, 64 -> 160, 160, 128
# 完成CSPlayer之后,160, 160, 128 -> 160, 160, 128
#-----------------------------------------------#
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2, act=act),
CSPLayer(base_channels * 2, base_channels * 2, n=base_depth, depthwise=depthwise, act=act),
)
#-----------------------------------------------#
# 完成卷积之后,160, 160, 128 -> 80, 80, 256
# 完成CSPlayer之后,80, 80, 256 -> 80, 80, 256
#-----------------------------------------------#
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act),
CSPLayer(base_channels * 4, base_channels * 4, n=base_depth * 3, depthwise=depthwise, act=act),
)
#-----------------------------------------------#
# 完成卷积之后,80, 80, 256 -> 40, 40, 512
# 完成CSPlayer之后,40, 40, 512 -> 40, 40, 512
#-----------------------------------------------#
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2, act=act),
CSPLayer(base_channels * 8, base_channels * 8, n=base_depth * 3, depthwise=depthwise, act=act),
)
#-----------------------------------------------#
# 完成卷积之后,40, 40, 512 -> 20, 20, 1024
# 完成SPP之后,20, 20, 1024 -> 20, 20, 1024
# 完成CSPlayer之后,20, 20, 1024 -> 20, 20, 1024
#-----------------------------------------------#
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act),
SPPBottleneck(base_channels * 16, base_channels * 16, activation=act),
CSPLayer(base_channels * 16, base_channels * 16, n=base_depth, shortcut=False, depthwise=depthwise, act=act),
)
def forward(self, x):
outputs = {}
x = self.stem(x)
outputs["stem"] = x
x = self.dark2(x)
outputs["dark2"] = x
#-----------------------------------------------#
# dark3的输出为80, 80, 256,是一个有效特征层
#-----------------------------------------------#
x = self.dark3(x)
outputs["dark3"] = x
#-----------------------------------------------#
# dark4的输出为40, 40, 512,是一个有效特征层
#-----------------------------------------------#
x = self.dark4(x)
outputs["dark4"] = x
#-----------------------------------------------#
# dark5的输出为20, 20, 1024,是一个有效特征层
#-----------------------------------------------#
x = self.dark5(x)
outputs["dark5"] = x
return {k: v for k, v in outputs.items() if k in self.out_features}
if __name__ == '__main__':
print(CSPDarknet(1, 1))
常规conv
height: h
width:w
stride: sd
padding :p
kernel size : ksize
卷积核大小为: h * w *1
卷积需要做多少次:nums = [(h - k + 2 * p) / sd ] * [(w - k + 2 * p) / sd]
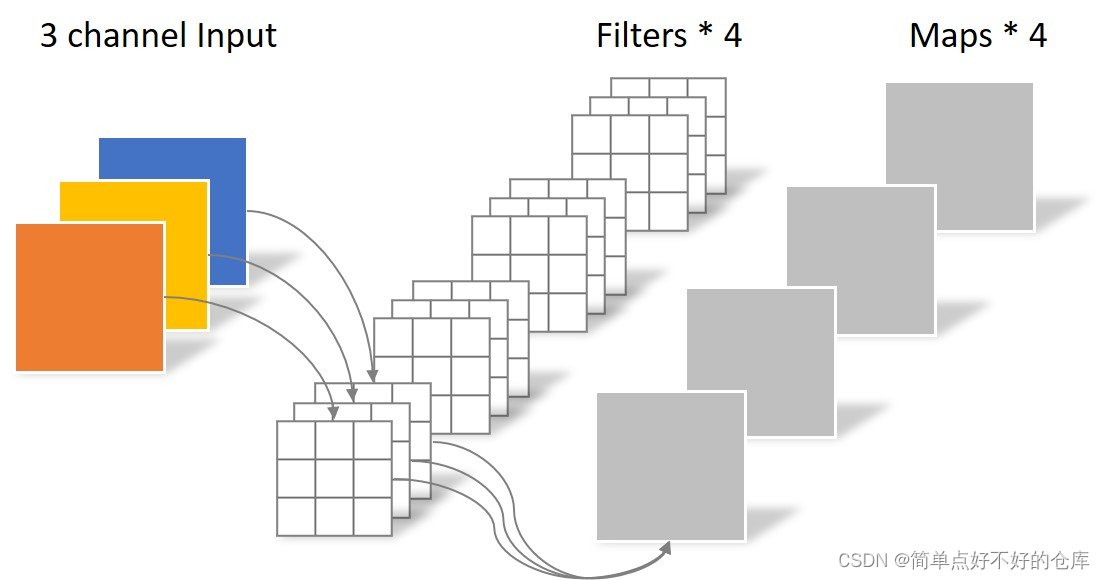
计算量:((in_channels * ksize * ksize) * nums ) * out_channels
DWConv
第一步
height: h
width:w
stride: sd
padding :p
kernel size : ksize
卷积核大小为: h * w *1
卷积需要做多少次:nums = [(h - k + 2 * p) / sd ] * [(w - k + 2 * p) / sd]
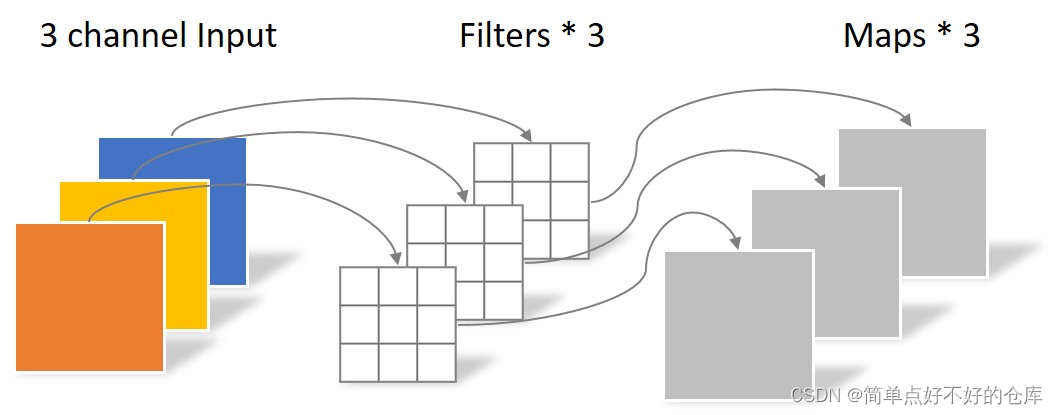
in_channles = out_channels
计算量: in_channels * (ksize * ksize * 1) * nums
第二步
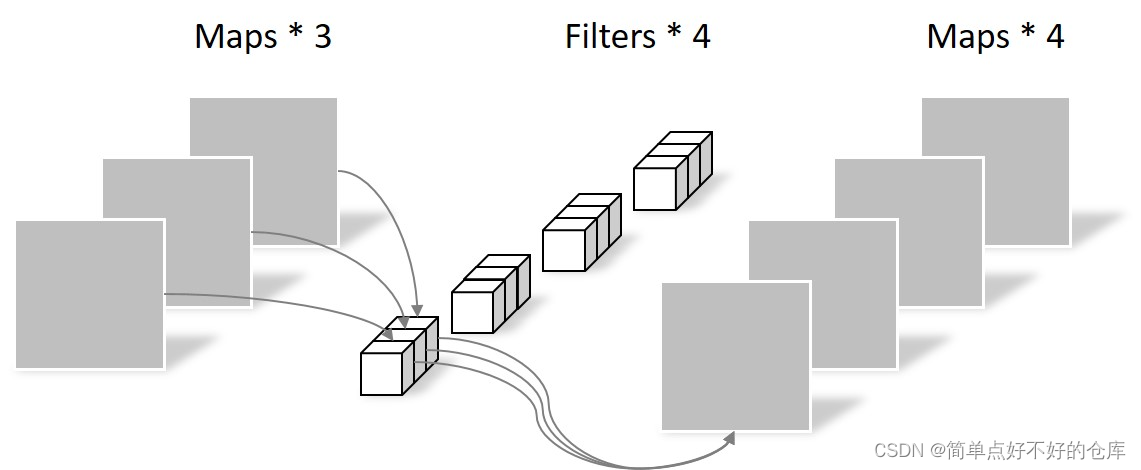
一次整图卷积次数: nums1 = (h + 2 * p) * (w + 2 * p)
计算量: nums1 * (1 * 1 * in_channels) * out_channels
CBA一套
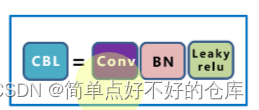
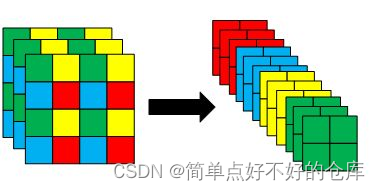
Focus
降维提取 + 拓展通道
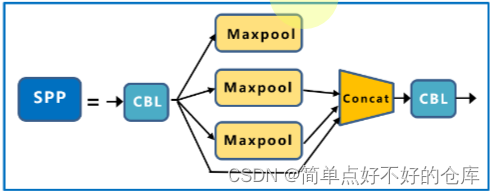
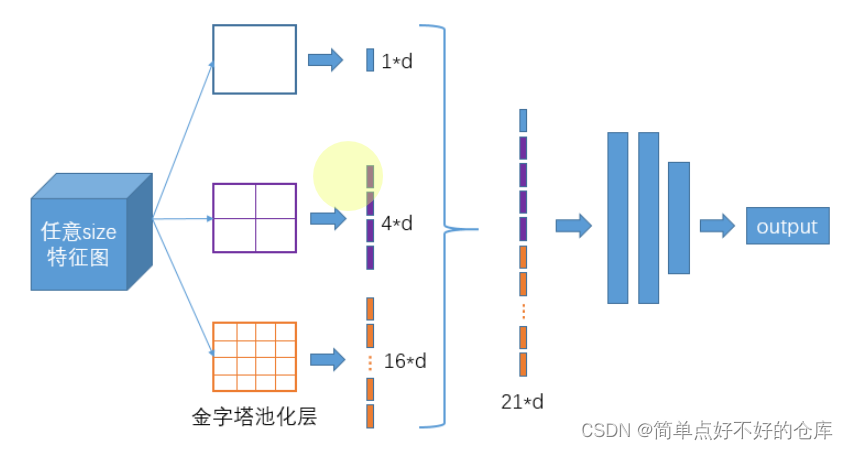
SPP
不同pooling的堆叠,堆叠不同视野
CSPDarknet
通道分成部分+残差设计
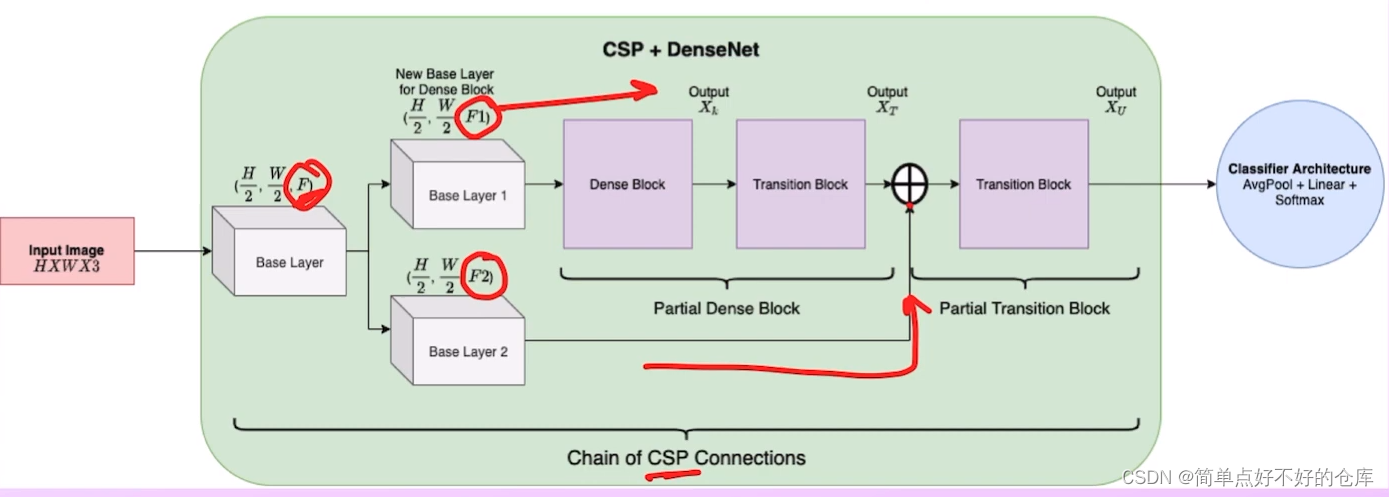
FPN
分辨率和语义的关系:
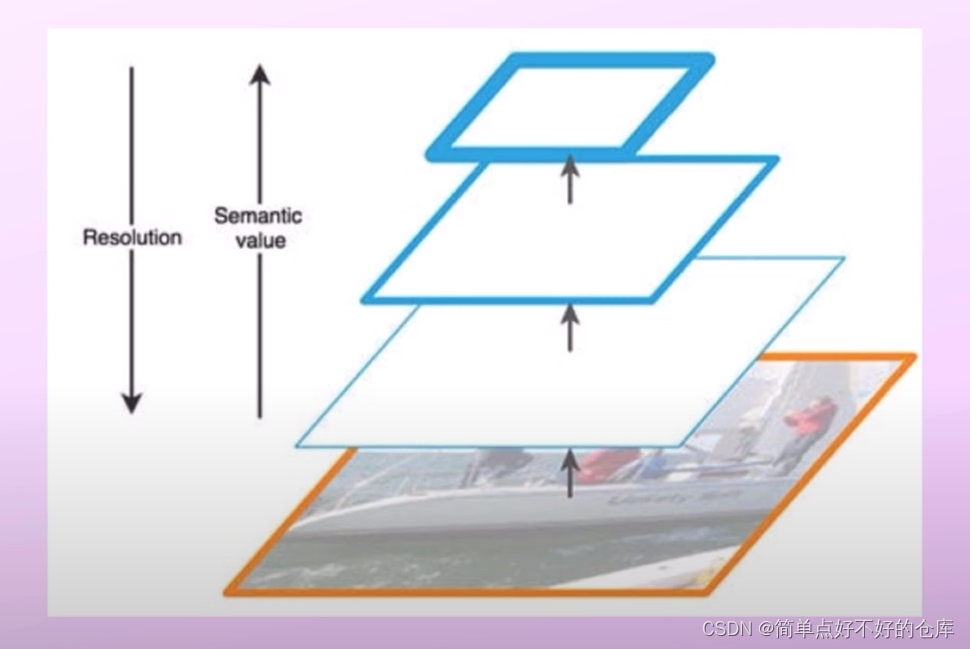
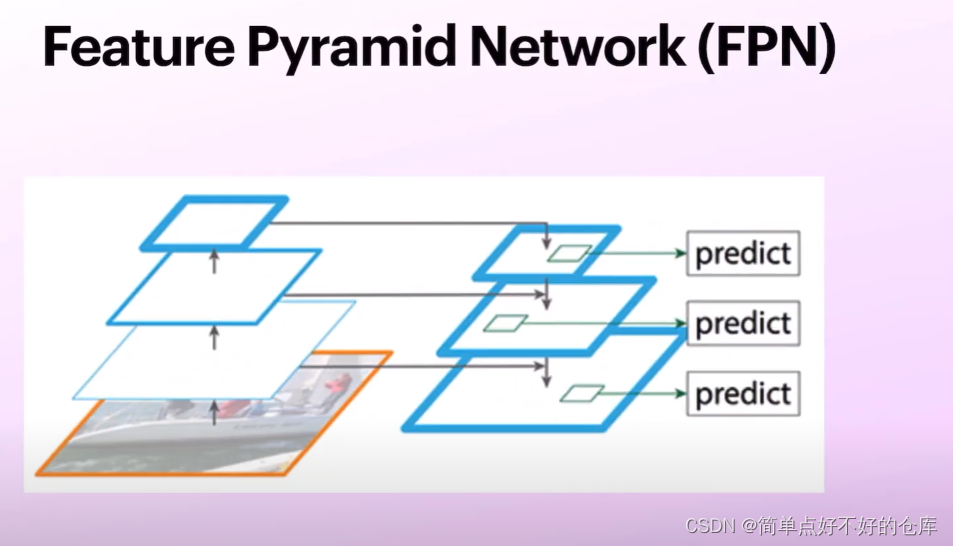
高层次低分辨率但是高语义
融合低分辨率位置信息和高语义信息
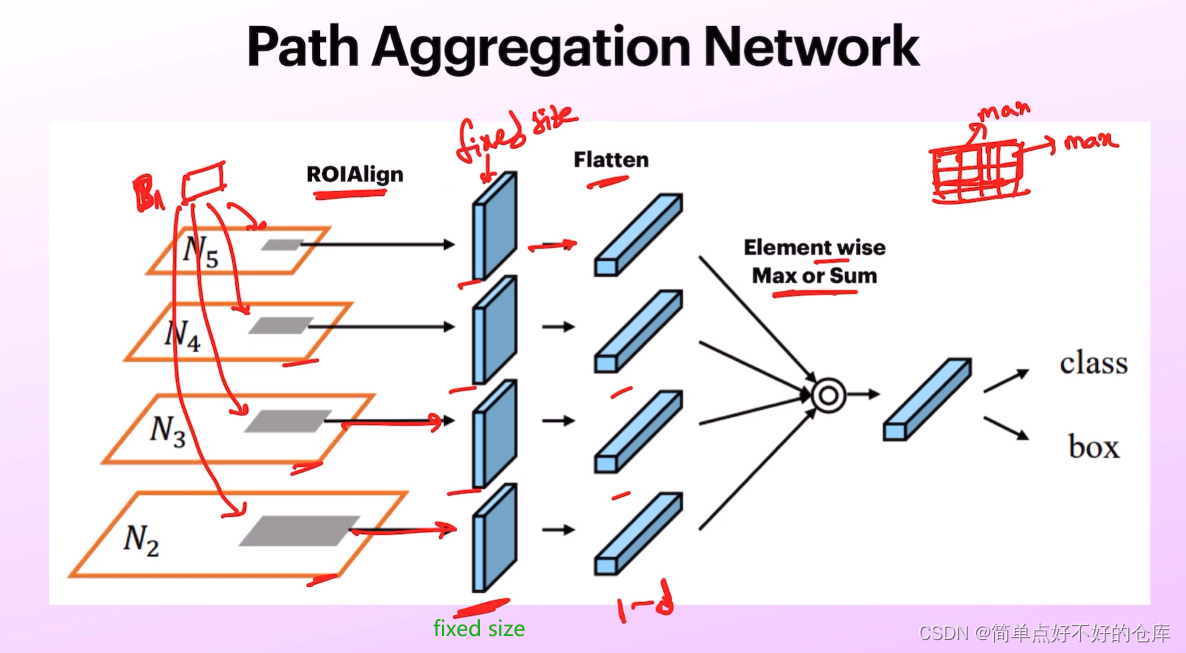
PAN
path segmentation network
多一条信息流路径,更短的流动路径
左边可能100层,右边可能<10层
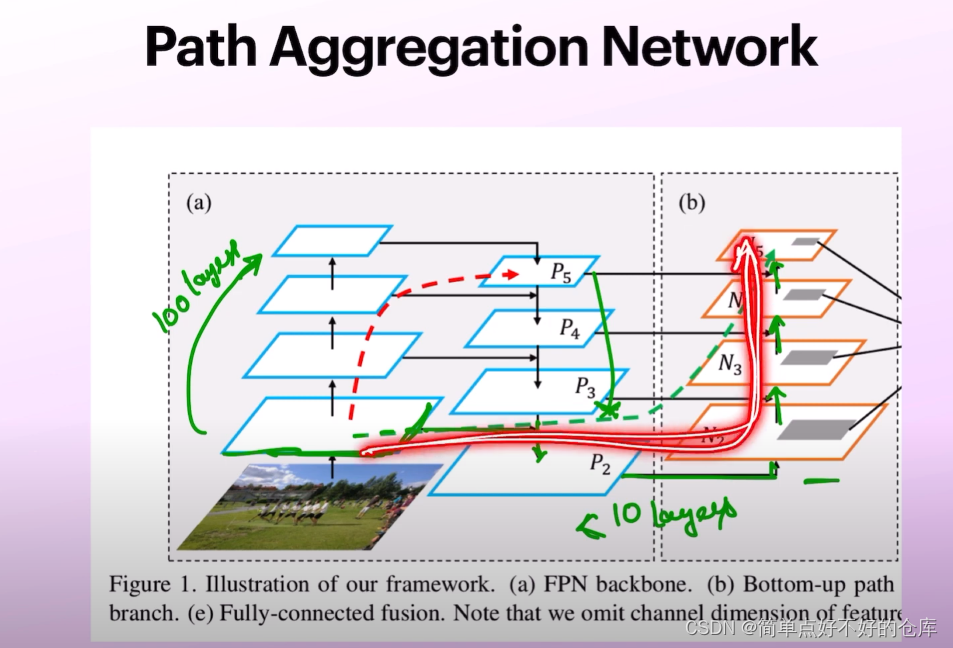
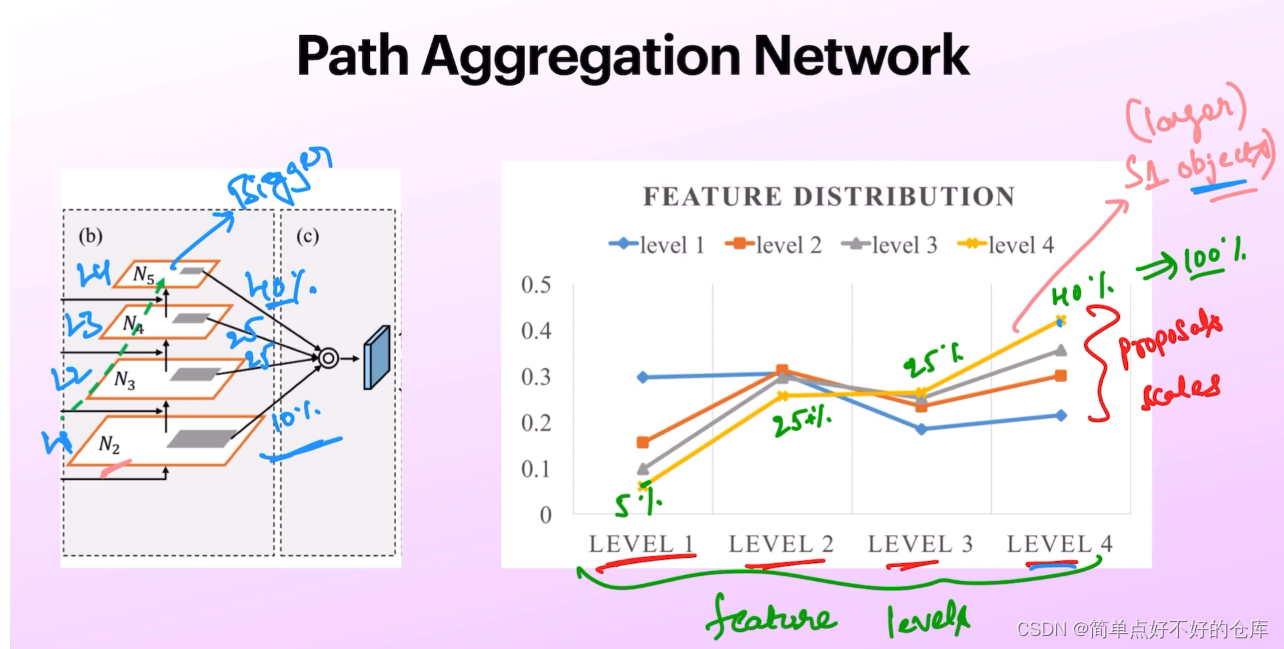
不同层的信息参考度不同
class YOLOPAFPN(nn.Module):
def __init__(self, depth = 1.0, width = 1.0, in_features = ("dark3", "dark4", "dark5"), in_channels = [256, 512, 1024], depthwise = False, act = "silu"):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.backbone = CSPDarknet(depth, width, depthwise = depthwise, act = act)
self.in_features = in_features
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
self.reduce_conv1 = BaseConv(int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
self.bu_conv2 = Conv(int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act)
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
self.bu_conv1 = Conv(int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act)
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 1024
#-------------------------------------------#
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
def forward(self, input):
out_features = self.backbone.forward(input)
[feat1, feat2, feat3] = [out_features[f] for f in self.in_features]
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
P5 = self.lateral_conv0(feat3)
#-------------------------------------------#
# 20, 20, 512 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.upsample(P5)
#-------------------------------------------#
# 40, 40, 512 + 40, 40, 512 -> 40, 40, 1024
#-------------------------------------------#
P5_upsample = torch.cat([P5_upsample, feat2], 1)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.C3_p4(P5_upsample)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
P4 = self.reduce_conv1(P5_upsample)
#-------------------------------------------#
# 40, 40, 256 -> 80, 80, 256
#-------------------------------------------#
P4_upsample = self.upsample(P4)
#-------------------------------------------#
# 80, 80, 256 + 80, 80, 256 -> 80, 80, 512
#-------------------------------------------#
P4_upsample = torch.cat([P4_upsample, feat1], 1)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
P3_out = self.C3_p3(P4_upsample)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
P3_downsample = self.bu_conv2(P3_out)
#-------------------------------------------#
# 40, 40, 256 + 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P3_downsample = torch.cat([P3_downsample, P4], 1)
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P4_out = self.C3_n3(P3_downsample)
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
P4_downsample = self.bu_conv1(P4_out)
#-------------------------------------------#
# 20, 20, 512 + 20, 20, 512 -> 20, 20, 1024
#-------------------------------------------#
P4_downsample = torch.cat([P4_downsample, P5], 1)
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 1024
#-------------------------------------------#
P5_out = self.C3_n4(P4_downsample)
return (P3_out, P4_out, P5_out)
decoupled predict head
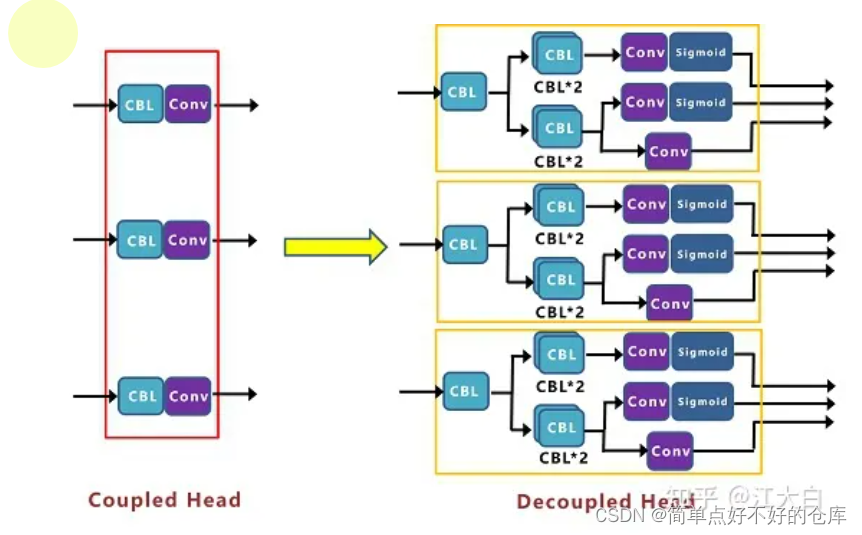
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import torch
import torch.nn as nn
from .darknet import BaseConv, CSPDarknet, CSPLayer, DWConv
class YOLOXHead(nn.Module):
'''预测头类'''
def __init__(self, num_classes, width = 1.0, in_channels = [256, 512, 1024], act = "silu", depthwise = False,):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
self.cls_preds = nn.ModuleList()
self.reg_preds = nn.ModuleList()
self.obj_preds = nn.ModuleList()
self.stems = nn.ModuleList()
for i in range(len(in_channels)):
self.stems.append(BaseConv(in_channels = int(in_channels[i] * width), out_channels = int(256 * width), ksize = 1, stride = 1, act = act))
self.cls_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
]))
self.cls_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = num_classes, kernel_size = 1, stride = 1, padding = 0)
)
self.reg_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act)
]))
self.reg_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = 4, kernel_size = 1, stride = 1, padding = 0)
)
self.obj_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = 1, kernel_size = 1, stride = 1, padding = 0)
)
def forward(self, inputs):
#---------------------------------------------------#
# inputs输入
# P3_out 80, 80, 256
# P4_out 40, 40, 512
# P5_out 20, 20, 1024
#---------------------------------------------------#
outputs = []
for k, x in enumerate(inputs):
#---------------------------------------------------#
# 利用1x1卷积进行通道整合
#---------------------------------------------------#
x = self.stems[k](x)
#---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
#---------------------------------------------------#
cls_feat = self.cls_convs[k](x)
#---------------------------------------------------#
# 判断特征点所属的种类
# 80, 80, num_classes
# 40, 40, num_classes
# 20, 20, num_classes
#---------------------------------------------------#
cls_output = self.cls_preds[k](cls_feat)
#---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
#---------------------------------------------------#
reg_feat = self.reg_convs[k](x)
#---------------------------------------------------#
# 特征点的回归系数
# reg_pred 80, 80, 4
# reg_pred 40, 40, 4
# reg_pred 20, 20, 4
#---------------------------------------------------#
reg_output = self.reg_preds[k](reg_feat)
#---------------------------------------------------#
# 判断特征点是否有对应的物体
# obj_pred 80, 80, 1
# obj_pred 40, 40, 1
# obj_pred 20, 20, 1
#---------------------------------------------------#
obj_output = self.obj_preds[k](reg_feat)
output = torch.cat([reg_output, obj_output, cls_output], 1)
outputs.append(output)
return outputs
class YOLOPAFPN(nn.Module):
'''fpn提取特征'''
def __init__(self, depth = 1.0, width = 1.0, in_features = ("dark3", "dark4", "dark5"), in_channels = [256, 512, 1024], depthwise = False, act = "silu"):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.backbone = CSPDarknet(depth, width, depthwise = depthwise, act = act)
self.in_features = in_features
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
self.reduce_conv1 = BaseConv(int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
self.bu_conv2 = Conv(int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act)
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
self.bu_conv1 = Conv(int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act)
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 1024
#-------------------------------------------#
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
def forward(self, input):
out_features = self.backbone.forward(input)
[feat1, feat2, feat3] = [out_features[f] for f in self.in_features]
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
P5 = self.lateral_conv0(feat3)
#-------------------------------------------#
# 20, 20, 512 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.upsample(P5)
#-------------------------------------------#
# 40, 40, 512 + 40, 40, 512 -> 40, 40, 1024
#-------------------------------------------#
P5_upsample = torch.cat([P5_upsample, feat2], 1)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.C3_p4(P5_upsample)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
P4 = self.reduce_conv1(P5_upsample)
#-------------------------------------------#
# 40, 40, 256 -> 80, 80, 256
#-------------------------------------------#
P4_upsample = self.upsample(P4)
#-------------------------------------------#
# 80, 80, 256 + 80, 80, 256 -> 80, 80, 512
#-------------------------------------------#
P4_upsample = torch.cat([P4_upsample, feat1], 1)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
P3_out = self.C3_p3(P4_upsample)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
P3_downsample = self.bu_conv2(P3_out)
#-------------------------------------------#
# 40, 40, 256 + 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P3_downsample = torch.cat([P3_downsample, P4], 1)
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P4_out = self.C3_n3(P3_downsample)
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
P4_downsample = self.bu_conv1(P4_out)
#-------------------------------------------#
# 20, 20, 512 + 20, 20, 512 -> 20, 20, 1024
#-------------------------------------------#
P4_downsample = torch.cat([P4_downsample, P5], 1)
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 1024
#-------------------------------------------#
P5_out = self.C3_n4(P4_downsample)
return (P3_out, P4_out, P5_out)
class YoloBody(nn.Module):
def __init__(self, num_classes, phi):
super().__init__()
depth_dict = {'nano': 0.33, 'tiny': 0.33, 's' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,}
width_dict = {'nano': 0.25, 'tiny': 0.375, 's' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,}
depth, width = depth_dict[phi], width_dict[phi]
depthwise = True if phi == 'nano' else False
self.backbone = YOLOPAFPN(depth, width, depthwise=depthwise)
self.head = YOLOXHead(num_classes, width, depthwise=depthwise)
def forward(self, x):
fpn_outs = self.backbone.forward(x)
outputs = self.head.forward(fpn_outs)
return outputs
loss/training
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import math
from copy import deepcopy
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
class IOUloss(nn.Module):
def __init__(self, reduction="none", loss_type="iou"):
super(IOUloss, self).__init__()
self.reduction = reduction
self.loss_type = loss_type
def forward(self, pred, target):
assert pred.shape[0] == target.shape[0]
pred = pred.view(-1, 4)
target = target.view(-1, 4)
tl = torch.max(
(pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
)
br = torch.min(
(pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
)
area_p = torch.prod(pred[:, 2:], 1)
area_g = torch.prod(target[:, 2:], 1)
en = (tl < br).type(tl.type()).prod(dim=1)
area_i = torch.prod(br - tl, 1) * en
area_u = area_p + area_g - area_i
iou = (area_i) / (area_u + 1e-16)
if self.loss_type == "iou":
loss = 1 - iou ** 2
elif self.loss_type == "giou":
c_tl = torch.min(
(pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
)
c_br = torch.max(
(pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
)
area_c = torch.prod(c_br - c_tl, 1)
giou = iou - (area_c - area_u) / area_c.clamp(1e-16)
loss = 1 - giou.clamp(min=-1.0, max=1.0)
if self.reduction == "mean":
loss = loss.mean()
elif self.reduction == "sum":
loss = loss.sum()
return loss
class YOLOLoss(nn.Module):
def __init__(self, num_classes, fp16, strides=[8, 16, 32]):
super().__init__()
self.num_classes = num_classes
self.strides = strides
self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none")
self.iou_loss = IOUloss(reduction="none")
self.grids = [torch.zeros(1)] * len(strides)
self.fp16 = fp16
def forward(self, inputs, labels=None):
outputs = []
x_shifts = []
y_shifts = []
expanded_strides = []
#-----------------------------------------------#
# inputs [[batch_size, num_classes + 5, 20, 20]
# [batch_size, num_classes + 5, 40, 40]
# [batch_size, num_classes + 5, 80, 80]]
# outputs [[batch_size, 400, num_classes + 5]
# [batch_size, 1600, num_classes + 5]
# [batch_size, 6400, num_classes + 5]]
# x_shifts [[batch_size, 400]
# [batch_size, 1600]
# [batch_size, 6400]]
#-----------------------------------------------#
for k, (stride, output) in enumerate(zip(self.strides, inputs)):
output, grid = self.get_output_and_grid(output, k, stride)
x_shifts.append(grid[:, :, 0])
y_shifts.append(grid[:, :, 1])
expanded_strides.append(torch.ones_like(grid[:, :, 0]) * stride)
outputs.append(output)
return self.get_losses(x_shifts, y_shifts, expanded_strides, labels, torch.cat(outputs, 1))
def get_output_and_grid(self, output, k, stride):
grid = self.grids[k]
hsize, wsize = output.shape[-2:]
if grid.shape[2:4] != output.shape[2:4]:
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
grid = torch.stack((xv, yv), 2).view(1, hsize, wsize, 2).type(output.type())
self.grids[k] = grid
grid = grid.view(1, -1, 2)
output = output.flatten(start_dim=2).permute(0, 2, 1)
output[..., :2] = (output[..., :2] + grid.type_as(output)) * stride
output[..., 2:4] = torch.exp(output[..., 2:4]) * stride
return output, grid
def get_losses(self, x_shifts, y_shifts, expanded_strides, labels, outputs):
#-----------------------------------------------#
# [batch, n_anchors_all, 4]
#-----------------------------------------------#
bbox_preds = outputs[:, :, :4]
#-----------------------------------------------#
# [batch, n_anchors_all, 1]
#-----------------------------------------------#
obj_preds = outputs[:, :, 4:5]
#-----------------------------------------------#
# [batch, n_anchors_all, n_cls]
#-----------------------------------------------#
cls_preds = outputs[:, :, 5:]
total_num_anchors = outputs.shape[1]
#-----------------------------------------------#
# x_shifts [1, n_anchors_all]
# y_shifts [1, n_anchors_all]
# expanded_strides [1, n_anchors_all]
#-----------------------------------------------#
x_shifts = torch.cat(x_shifts, 1).type_as(outputs)
y_shifts = torch.cat(y_shifts, 1).type_as(outputs)
expanded_strides = torch.cat(expanded_strides, 1).type_as(outputs)
cls_targets = []
reg_targets = []
obj_targets = []
fg_masks = []
num_fg = 0.0
for batch_idx in range(outputs.shape[0]):
num_gt = len(labels[batch_idx])
if num_gt == 0:
cls_target = outputs.new_zeros((0, self.num_classes))
reg_target = outputs.new_zeros((0, 4))
obj_target = outputs.new_zeros((total_num_anchors, 1))
fg_mask = outputs.new_zeros(total_num_anchors).bool()
else:
#-----------------------------------------------#
# gt_bboxes_per_image [num_gt, num_classes]
# gt_classes [num_gt]
# bboxes_preds_per_image [n_anchors_all, 4]
# cls_preds_per_image [n_anchors_all, num_classes]
# obj_preds_per_image [n_anchors_all, 1]
#-----------------------------------------------#
gt_bboxes_per_image = labels[batch_idx][..., :4].type_as(outputs)
gt_classes = labels[batch_idx][..., 4].type_as(outputs)
bboxes_preds_per_image = bbox_preds[batch_idx]
cls_preds_per_image = cls_preds[batch_idx]
obj_preds_per_image = obj_preds[batch_idx]
gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg_img = self.get_assignments(
num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes, bboxes_preds_per_image, cls_preds_per_image, obj_preds_per_image,
expanded_strides, x_shifts, y_shifts,
)
torch.cuda.empty_cache()
num_fg += num_fg_img
cls_target = F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes).float() * pred_ious_this_matching.unsqueeze(-1)
obj_target = fg_mask.unsqueeze(-1)
reg_target = gt_bboxes_per_image[matched_gt_inds]
cls_targets.append(cls_target)
reg_targets.append(reg_target)
obj_targets.append(obj_target.type(cls_target.type()))
fg_masks.append(fg_mask)
cls_targets = torch.cat(cls_targets, 0)
reg_targets = torch.cat(reg_targets, 0)
obj_targets = torch.cat(obj_targets, 0)
fg_masks = torch.cat(fg_masks, 0)
num_fg = max(num_fg, 1)
loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)).sum()
loss_obj = (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)).sum()
loss_cls = (self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)).sum()
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls
return loss / num_fg
@torch.no_grad()
def get_assignments(self, num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes, bboxes_preds_per_image, cls_preds_per_image, obj_preds_per_image, expanded_strides, x_shifts, y_shifts):
#-------------------------------------------------------#
# fg_mask [n_anchors_all]
# is_in_boxes_and_center [num_gt, len(fg_mask)]
#-------------------------------------------------------#
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt)
#-------------------------------------------------------#
# fg_mask [n_anchors_all]
# bboxes_preds_per_image [fg_mask, 4]
# cls_preds_ [fg_mask, num_classes]
# obj_preds_ [fg_mask, 1]
#-------------------------------------------------------#
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]
cls_preds_ = cls_preds_per_image[fg_mask]
obj_preds_ = obj_preds_per_image[fg_mask]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
#-------------------------------------------------------#
# pair_wise_ious [num_gt, fg_mask]
#-------------------------------------------------------#
pair_wise_ious = self.bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
#-------------------------------------------------------#
# cls_preds_ [num_gt, fg_mask, num_classes]
# gt_cls_per_image [num_gt, fg_mask, num_classes]
#-------------------------------------------------------#
if self.fp16:
with torch.cuda.amp.autocast(enabled=False):
cls_preds_ = cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
gt_cls_per_image = F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, num_in_boxes_anchor, 1)
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1)
else:
cls_preds_ = cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
gt_cls_per_image = F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, num_in_boxes_anchor, 1)
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1)
del cls_preds_
cost = pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000.0 * (~is_in_boxes_and_center).float()
num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
return gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg
def bboxes_iou(self, bboxes_a, bboxes_b, xyxy=True):
if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:
raise IndexError
if xyxy:
tl = torch.max(bboxes_a[:, None, :2], bboxes_b[:, :2])
br = torch.min(bboxes_a[:, None, 2:], bboxes_b[:, 2:])
area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)
area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)
else:
tl = torch.max(
(bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),
(bboxes_b[:, :2] - bboxes_b[:, 2:] / 2),
)
br = torch.min(
(bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),
(bboxes_b[:, :2] + bboxes_b[:, 2:] / 2),
)
area_a = torch.prod(bboxes_a[:, 2:], 1)
area_b = torch.prod(bboxes_b[:, 2:], 1)
en = (tl < br).type(tl.type()).prod(dim=2)
area_i = torch.prod(br - tl, 2) * en
return area_i / (area_a[:, None] + area_b - area_i)
def get_in_boxes_info(self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt, center_radius = 2.5):
#-------------------------------------------------------#
# expanded_strides_per_image [n_anchors_all]
# x_centers_per_image [num_gt, n_anchors_all]
# x_centers_per_image [num_gt, n_anchors_all]
#-------------------------------------------------------#
expanded_strides_per_image = expanded_strides[0]
x_centers_per_image = ((x_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)
y_centers_per_image = ((y_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)
#-------------------------------------------------------#
# gt_bboxes_per_image_x [num_gt, n_anchors_all]
#-------------------------------------------------------#
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)
#-------------------------------------------------------#
# bbox_deltas [num_gt, n_anchors_all, 4]
#-------------------------------------------------------#
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2)
#-------------------------------------------------------#
# is_in_boxes [num_gt, n_anchors_all]
# is_in_boxes_all [n_anchors_all]
#-------------------------------------------------------#
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
#-------------------------------------------------------#
# center_deltas [num_gt, n_anchors_all, 4]
#-------------------------------------------------------#
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
#-------------------------------------------------------#
# is_in_centers [num_gt, n_anchors_all]
# is_in_centers_all [n_anchors_all]
#-------------------------------------------------------#
is_in_centers = center_deltas.min(dim=-1).values > 0.0
is_in_centers_all = is_in_centers.sum(dim=0) > 0
#-------------------------------------------------------#
# is_in_boxes_anchor [n_anchors_all]
# is_in_boxes_and_center [num_gt, is_in_boxes_anchor]
#-------------------------------------------------------#
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all
is_in_boxes_and_center = is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]
return is_in_boxes_anchor, is_in_boxes_and_center
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
#-------------------------------------------------------#
# cost [num_gt, fg_mask]
# pair_wise_ious [num_gt, fg_mask]
# gt_classes [num_gt]
# fg_mask [n_anchors_all]
# matching_matrix [num_gt, fg_mask]
#-------------------------------------------------------#
matching_matrix = torch.zeros_like(cost)
#------------------------------------------------------------#
# 选取iou最大的n_candidate_k个点
# 然后求和,判断应该有多少点用于该框预测
# topk_ious [num_gt, n_candidate_k]
# dynamic_ks [num_gt]
# matching_matrix [num_gt, fg_mask]
#------------------------------------------------------------#
n_candidate_k = min(10, pair_wise_ious.size(1))
topk_ious, _ = torch.topk(pair_wise_ious, n_candidate_k, dim=1)
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
for gt_idx in range(num_gt):
#------------------------------------------------------------#
# 给每个真实框选取最小的动态k个点
#------------------------------------------------------------#
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0
del topk_ious, dynamic_ks, pos_idx
#------------------------------------------------------------#
# anchor_matching_gt [fg_mask]
#------------------------------------------------------------#
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
#------------------------------------------------------------#
# 当某一个特征点指向多个真实框的时候
# 选取cost最小的真实框。
#------------------------------------------------------------#
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
#------------------------------------------------------------#
# fg_mask_inboxes [fg_mask]
# num_fg为正样本的特征点个数
#------------------------------------------------------------#
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
num_fg = fg_mask_inboxes.sum().item()
#------------------------------------------------------------#
# 对fg_mask进行更新
#------------------------------------------------------------#
fg_mask[fg_mask.clone()] = fg_mask_inboxes
#------------------------------------------------------------#
# 获得特征点对应的物品种类
#------------------------------------------------------------#
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
def is_parallel(model):
# Returns True if model is of type DP or DDP
return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
def de_parallel(model):
# De-parallelize a model: returns single-GPU model if model is of type DP or DDP
return model.module if is_parallel(model) else model
def copy_attr(a, b, include=(), exclude=()):
# Copy attributes from b to a, options to only include [...] and to exclude [...]
for k, v in b.__dict__.items():
if (len(include) and k not in include) or k.startswith('_') or k in exclude:
continue
else:
setattr(a, k, v)
class ModelEMA:
""" Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
Keeps a moving average of everything in the model state_dict (parameters and buffers)
For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
"""
def __init__(self, model, decay=0.9999, tau=2000, updates=0):
# Create EMA
self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
# if next(model.parameters()).device.type != 'cpu':
# self.ema.half() # FP16 EMA
self.updates = updates # number of EMA updates
self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
# Update EMA parameters
with torch.no_grad():
self.updates += 1
d = self.decay(self.updates)
msd = de_parallel(model).state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point:
v *= d
v += (1 - d) * msd[k].detach()
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
# Update EMA attributes
copy_attr(self.ema, model, include, exclude)
def weights_init(net, init_type='normal', init_gain = 0.02):
def init_func(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and classname.find('Conv') != -1:
if init_type == 'normal':
torch.nn.init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
torch.nn.init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
torch.nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
torch.nn.init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
print('initialize network with %s type' % init_type)
net.apply(init_func)
def get_lr_scheduler(lr_decay_type, lr, min_lr, total_iters, warmup_iters_ratio = 0.05, warmup_lr_ratio = 0.1, no_aug_iter_ratio = 0.05, step_num = 10):
def yolox_warm_cos_lr(lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter, iters):
if iters <= warmup_total_iters:
# lr = (lr - warmup_lr_start) * iters / float(warmup_total_iters) + warmup_lr_start
lr = (lr - warmup_lr_start) * pow(iters / float(warmup_total_iters), 2) + warmup_lr_start
elif iters >= total_iters - no_aug_iter:
lr = min_lr
else:
lr = min_lr + 0.5 * (lr - min_lr) * (
1.0 + math.cos(math.pi* (iters - warmup_total_iters) / (total_iters - warmup_total_iters - no_aug_iter))
)
return lr
def step_lr(lr, decay_rate, step_size, iters):
if step_size < 1:
raise ValueError("step_size must above 1.")
n = iters // step_size
out_lr = lr * decay_rate ** n
return out_lr
if lr_decay_type == "cos":
warmup_total_iters = min(max(warmup_iters_ratio * total_iters, 1), 3)
warmup_lr_start = max(warmup_lr_ratio * lr, 1e-6)
no_aug_iter = min(max(no_aug_iter_ratio * total_iters, 1), 15)
func = partial(yolox_warm_cos_lr ,lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter)
else:
decay_rate = (min_lr / lr) ** (1 / (step_num - 1))
step_size = total_iters / step_num
func = partial(step_lr, lr, decay_rate, step_size)
return func
def set_optimizer_lr(optimizer, lr_scheduler_func, epoch):
lr = lr_scheduler_func(epoch)
for param_group in optimizer.param_groups:
param_group['lr'] = lr


















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











