




 本文详细介绍了R语言中的基本数据结构,包括向量、列表、矩阵、数组和数据框。向量支持多种类型元素,如数值、字符、逻辑等,并提供了创建、运算和统计方法。列表可以容纳不同类型元素,矩阵适用于线性代数运算,数组是多维数据存储,数据框类似表格数据,各列数据类型一致。此外,还讨论了向量和列表的索引以及矩阵的运算。这些基础知识对于理解和使用R语言至关重要。
本文详细介绍了R语言中的基本数据结构,包括向量、列表、矩阵、数组和数据框。向量支持多种类型元素,如数值、字符、逻辑等,并提供了创建、运算和统计方法。列表可以容纳不同类型元素,矩阵适用于线性代数运算,数组是多维数据存储,数据框类似表格数据,各列数据类型一致。此外,还讨论了向量和列表的索引以及矩阵的运算。这些基础知识对于理解和使用R语言至关重要。
文章目录
1 基本数据结构
在使用任何编程语言进行编程时,都需要使用各种变量来存储信息, 变量只是保留值的存储位置。 这意味着,当你创建一个变量时,必须在内存中保留一些空间来存储它们。我们可能需要存储各种数据类型的信息,如字符,宽字符,整数,浮点,双浮点,布尔等。基于变量的数据类型,操作系统分配相应内存并决定什么可以存储在保留内存中。R与其他编程语言(如 C 中的 C 和 java)相反,R中变量不必要声明类型。 变量分配有 R 对象,R 对象的数据类型变为变量的数据类型。尽管有很多类型的 R 对象,但经常使用的是:向量, 列表,矩阵,数据, 因子,数据框
这些对象中最简单的是向量对象,向量可以用6种基本数据类型组成, 其他的R对象也建立在这些基本元素之上, 分别是:
- 数字型 1.12
- 整型 1,2
- 复合型 1+2i
- 字符 “a”
- 逻辑值 TRUE, FALSE
- 原型 "A"的原型为41
class() 函数可以查看数据类型, 如下:
testvector<- list(1.1, 100L ,1+2i, "a", TRUE, charToRaw("A"))
for( item in testvector){
print(c(item, class(item)))
}
[1] "1.1" "numeric"
[1] "100" "integer"
[1] "1+2i" "complex"
[1] "a" "character"
[1] "TRUE" "logical"
[1] "41" "raw"
2 向量
向量(Vector)在 Java、Rust、C# 这些专门编程的的语言的标准库里往往会提供,这是因为向量在数学运算中是不可或缺的工具——向量从数据结构上看就是一个线性表,可以看成一个一维数组。R 语言中向量作为一种类型存在让向量的操作变得十分简便。
2.1 向量创建
a<-c(1,2,3)# 直接用c()创建
d1<-seq(0, 10, 2) # seq()函数生成一个等差序列 seq(begin, end, step)
d2<-seq(0, 10, length.out=5) #seq也可指定生成序列的长度
e<-rep(1,5) # repeat 重复一个元素生成序列
f<-2:5 # min:max 生成连续序列
2.2 向量运算
相同长度的向量可以进行逐元素的四则运算, 不同长度的可以进行运算,但最好不要。
> a<-c(1,2)# 直接用c()创建
> b<-c(3,4)
> a+b
[1] 4 6
> a*b
[1] 3 8
2.3 向量统计
| 函数 | 作用 |
|---|---|
| sum | 求和 |
| mean | 求平均值 |
| var | 方差 |
| sd | 标准差 |
| min | 最小值 |
| max | 最大值 |
| range | 取值范围(二维向量,最大值和最小值) |
> a<-c(1, 2, 3, 4)
> sum(a)
[1] 10
> mean(a)
[1] 2.5
> var(a)
[1] 1.666667
> sd(a)
[1] 1.290994
> min(a)
[1] 1
> max(a)
[1] 4
> range(a)
[1] 1 4
2.3 向量索引
R种[ ] 可以用来索引,使用起来也很方便, 常用的几种用法如下
> a<-c(1, 2, 3, 4,5)
> a[1]# 取出第1项, 向量种下标是第几个,不是从0开始的, 是从1 开始的
[1] 1
> a[1:4] # 取出第 1 到 4 项,包含第 1 和第 4 项
[1] 1 2 3 4
> a[c(1, 3)] # 取出第 1, 3, 5 项
[1] 1 3
> a[c(-1, -2)] # 去掉第 1 和第 5 项
[1] 3 4 5
> a[c(TRUE,FALSE,TRUE,TRUE,TRUE )] # 布尔值索引
[1] 1 3 4 5
> a[c(a>2)] # 条件索引,原理就是布尔值索引
[1] 3 4 5
备注 : 向量要求所有元素类型相同,则如果向量存在字符元素, 所有元素都会转化为字符型。
> a <-c(1,2,1+8i, "a")
> a
[1] "1" "2" "1+8i" "a"
3 列表
列表是一个用途广泛的R对象,它可以在其中包含许多不同类型的元素,如向量,函数甚至其中的另一个列表。 创建一个列表,你应该使用list() 函数,这意味着将元素组合成一个列表。
3.1 列表创建
> a <- list("hello", "world", c(1,2), list(1,2),1+8i)
> a
[[1]]
[1] "hello"
[[2]]
[1] "world"
[[3]]
[1] 1 2
[[4]]
[[4]][[1]]
[1] 1
[[4]][[2]]
[1] 2
[[5]]
[1] 1+8i
3.2 列表操作
我们可以使用 names() 函数给列表的元素命名:
names(a) <- c("x", "y","u","v","w")
> print(a)
$x
[1] "hello"
$y
[1] "world"
$u
[1] 1 2
$v
$v[[1]]
[1] 1
$v[[2]]
[1] 2
$w
[1] 1+8i
修改元素
> a[1]<-"hi"
> a[1]
[[1]]
[1] "hi
可以添加元素
> a[length(a)+1]<-"new"
> print(a[6])
[[1]]
[1] "new"
删除元素
a<- a[-1] # 删除第一个元素
合并列表
> mergedlist <- c(list1,list2)
> mergedlist
[[1]]
[1] "hello"
[[2]]
[1] "world"
3.3 列表索引
列表中的元素可以使用索引来访问,与向量相同, 如果使用names() 函数命名后,我们还可以使用对应名字来访问:
> a$x
[1] "hello"
3.4 列表转化为向量
> a<-list(1,2,3)
> a<-unlist(a)
> a
[1] 1 2 3
4 矩阵
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
矩阵里的元素可以是数字、符号或数学式。
4.1 矩阵创建
R 语言的矩阵可以使用 matrix() 函数来创建,语法格式如下:
参数说明:
- data 向量,矩阵的数据
- nrow 行数
- ncol 列数
- byrow 逻辑值,为 FALSE 按列排列,为 TRUE 按行排列 , 默认按列
- dimname 设置行和列的名称
a<-matrix(data = 1:6, ncol = 2, byrow = FALSE,
dimnames=list(c("张三","李四",'王二麻子'), c("电费", "水费")))
print(a)
电费 水费
张三 1 4
李四 2 5
王二麻子 3 6
4.2 矩阵操作
R 语言矩阵提供了 t() 函数,可以实现矩阵的行列互换。例如有个 m 行 n 列的矩阵,使用 t() 函数就能转换为 n 行 m 列的矩阵。
# 矩阵转置
> M = matrix( 1:6, nrow = 2)
> print(M)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> # 转换为 3 行 2 列的矩阵
> print(t(M))
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
4.3 矩阵索引
获取矩阵元素,可以通过使用元素的列索引和行索引[ , ],单个行索引和列索引与向量索引相同;
> a<-matrix(data = 1:6, ncol = 2, byrow = FALSE,
dimnames=list(c("张三","李四",'王二麻子'), c("电费", "水费")))
> a[1:2, 1:2]
电费 水费
张三 1 4
李四 2 5
> a[1,1] # 第一行,第一列
[1] 1
> a[1,] # 第一行
电费 水费
1 4
4.4 矩阵计算
形状相同的矩阵之间可以做四则运算,具体为每个位置元素的加减乘除.
> M1 = matrix( 1:6, nrow = 2)
> M2 = matrix( 1:6, nrow = 2)
> M1*M2 # 矩阵乘法
[,1] [,2] [,3]
[1,] 1 9 25
[2,] 4 16 36
> M1+M2 # 矩阵加法
[,1] [,2] [,3]
[1,] 2 6 10
[2,] 4 8 12
也可以做矩阵内积乘法,符号位%*%,它只有在第一个矩阵的列数(column)和第二个矩阵的行数(row)相同时才有意义 ,一个m×n的矩阵乘以n×m的矩阵为一个m×m的矩阵。
> M1%*%t(M2)
[,1] [,2]
[1,] 35 44
[2,] 44 56
4.5 矩阵使用apply函数计算
apply(matrix, margins, func) 函数
在R语言的帮助文档里,apply函数的功能是把一个function作用到array或者matrix的margins(可以理解为数组的每一行或者每一列)中,返回值时vector、array、list。简单的说,apply函数经常用来计算矩阵中行或列的均值、和值的函数,具体方法如下:
第一个参数是指要参与计算的矩阵;
第二个参数是指按行计算还是按列计算,1—表示按行计算,2—按列计算;
第三个参数是指具体的运算函数。
> apply(M1,1,sum)
[1] 9 12
> apply(M1,2,sum)
[1] 3 7 11
5 数组
R 语言数组是一个同一类型的集合,之前的矩阵 matrix 其实就是一个二维数组。向量、矩阵、数组关系可以看下图:
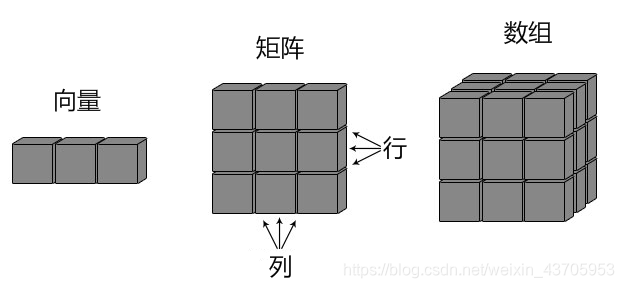
5.2 数组创建
R 语言的数组可以使用 array() 函数来创建,语法格式如下:
参数说明:
- data 向量,数组的数据
- dim 数组的维度,默认是一维数组。
- dimnames 维度的名称,必须是个列表
> A<- array(seq(1,18),dim =c(3,3,2),
+ dimnames =list(c("rowone","row two","row three"),
+ c("col one","col two","col three"),
+ c("matrix one", "metrix two")))
> A
, , matrix one
col one col two col three
row one 1 4 7
row two 2 5 8
row three 3 6 9
, , metrix two
col one col two col three
row one 10 13 16
row two 11 14 17
row three 12 15 18
5.2 数组索引
数组索引相当于三个维度的向量索引,原理相同。 这里省略。数组的修改亦于向量相同。
6 因子
因子用于存储不同类别的数据类型,因子即数据分析中的特征,如性别是一个因子(特征) , 因子的不同取值即水平,“男”,“女”即水平。
6.1 因子创建
R 语言创建因子使用 factor() 函数,向量作为输入参数。
参数说明:
- x:向量
- levels:指定各水平值, 不指定时由x的不同值来求得
- labels:水平的标签, 不指定时用各水平值的对应字符串
- exclude:排除的字符
- ordered:逻辑值,用于指定水平是否有序
- nmax:水平的上限数量。
> F<-factor(x=c("boy","girl","boy","boy","boy","girl","don't know"),
exclude="don't know") # 生成因子
> F
[1] boy girl boy boy boy girl <NA>
Levels: boy girl
> F<-factor(x=c("boy","girl","boy","boy","boy","girl","don't know"),
levels=c('boy','girl'),labels=c('男孩','女孩'), # 修改水平名称
exclude="don't know",ordered=FALSE) # 各水平之间无序
> F
[1] 男孩 女孩 男孩 男孩 男孩 女孩 <NA>
Levels: 男孩 女孩
7 数据框
数据框(Data frame)可以理解成excel中的表格,每一列都有一个唯一的列名,长度都是相等的,同一列的数据类型需要一致,不同列的数据类型可以不一样。
7.1 数据框创建
R 语言数据框使用 data.frame() 函数来创建
> DF = data.frame(
+ 姓名 = c("张三", "李四","王二麻子"),
+ 科目 = c("数学","数学","语文"),
+ 分数 = c(100, 59,90)
+ )
> print(DF) # 查看 table 数据
姓名 科目 分数
1 张三 数学 100
2 李四 数学 59
3 王二麻子 语文 90
7.2 数据框展示
可以使用 str()查看数据结构
> str(DF)
'data.frame': 3 obs. of 3 variables:
$ 姓名: chr "张三" "李四" "王二麻子"
$ 科目: chr "数学" "数学" "语文"
$ 分数: num 100 59 90
summary( )显示概要
> summary(DF)
姓名 科目 分数
Length:3 Length:3 Min. : 59.0
Class :character Class :character 1st Qu.: 74.5
Mode :character Mode :character Median : 90.0
Mean : 83.0
3rd Qu.: 95.0
Max. :100.0
7.3 数据框索引
可以通过类似向量索引的方式获取数据, 也可以通过列名获取某列
> DF$姓名
[1] "张三" "李四" "王二麻子"
> DF$分数
[1] 100 59 90
7.4 数据框修改增加数据
数据框修改数据之间索引位置赋值即可, 如果要添加一列,方法如下:
> DF$教师<-c("马老师","张老师","刘老师")
> DF
姓名 科目 分数 教师
1 张三 数学 100 马老师
2 李四 数学 59 张老师
3 王二麻子 语文 90 刘老师
7.5 数据框合并
我们可以使用 cbind() 函数将多个向量合成一个数据框, c即columns,多个列合并;
两个数据框进行合并可以使用 rbind() 函数,r即row,按行合并。
cbind()合并向量
> name<- c("张三", "李四","王二麻子")
> subject<- c("数学","数学","语文")
> scores<-c(100, 59,90)
> newdf<-cbind(name, subject, scores)
> newdf
name subject scores
[1,] "张三" "数学" "100"
[2,] "李四" "数学" "59"
[3,] "王二麻子" "语文" "90"
rbind()合并数据框
> df1 = data.frame(
+ 姓名 = c("张三", "李四","王二麻子"),
+ 科目 = c("数学","数学","语文"),
+ 分数 = c(100, 59,90)
+ )
> df2 = data.frame(
+ 姓名 = c("徐晃","胡莉娅"),
+ 科目 = c("英语","物理"),
+ 分数 = c(80,89)
+ )
> new <- rbind(df1,df2)
> new
姓名 科目 分数
1 张三 数学 100
2 李四 数学 59
3 王二麻子 语文 90
4 徐晃 英语 80
5 胡莉娅 物理 89


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









