







 图森TuSimple提供了约7,000个1秒钟的20帧视频片段,用于自动驾驶中的车道检测,强调算法的时间/内存效率。数据集包含训练和测试集,分别有3626和2782个视频片段,标注集中在当前和相邻车道。数据集特点包括不同天气、车道数量和交通情况。参赛者需考虑车道语义,提供最多4/5车道的标记,并通过JSON文件提交预测结果,最终根据准确性、FP和FN评估算法性能。"
108958462,10012092,Python字典合并方法大全,"['python', 'django', '机器学习']
图森TuSimple提供了约7,000个1秒钟的20帧视频片段,用于自动驾驶中的车道检测,强调算法的时间/内存效率。数据集包含训练和测试集,分别有3626和2782个视频片段,标注集中在当前和相邻车道。数据集特点包括不同天气、车道数量和交通情况。参赛者需考虑车道语义,提供最多4/5车道的标记,并通过JSON文件提交预测结果,最终根据准确性、FP和FN评估算法性能。"
108958462,10012092,Python字典合并方法大全,"['python', 'django', '机器学习']
原文:
https://github.com/TuSimple/tusimple-benchmark/tree/master/doc/lane_detection
数据集下载地址:
道路上的对象可以分为两大类:静态对象和动态对象。 车道标记是高速公路上的主要静态组成部分。 他们指示车辆以交互方式安全地在高速公路上行驶。 为了鼓励人们解决高速公路上的车道检测问题,我们发布了大约7,000个1秒钟长的20帧长的视频剪辑。
车道检测是自动驾驶中的一项关键任务,它为汽车的控制提供定位信息。 我们为此任务提供了视频剪辑,每个剪辑的最后一帧都包含带标签的车道。 该视频剪辑可以帮助算法推断出更好的车道检测结果。 通过剪辑,我们希望竞争对手能提出更有效的算法。 对于自动驾驶车辆,时间/内存效率算法意味着更多资源可用于其他算法和工程流水线。
同时,我们希望参与者考虑自动驾驶车道的语义,而不是检测道路上的每个车道标记。 因此,注释和测试集中在当前车道和左/右车道上。
我们将有一个排行榜,显示提交的评估结果。 我们为前三名参赛者提供奖品,CVPR 2017自动驾驶挑战赛讲习班也将提及这些奖品。

数据集特征
复杂性:
- 良好和中等天气条件
- 白天不同
- 2车道/ 3车道/ 4车道/或更多高速公路
- 不同的交通状况
规模:
- 训练:3626个视频剪辑,3626个带标注的帧(每个剪辑clips有20帧,最后一帧带有标注)
- 测试:2782个视频剪辑
相机和视频片段:
- 1s剪辑20帧
- 相机的视线方向非常接近行车方向
注释类型:
- 车道标记折线
数据集细节
目录结构
训练/测试数据集的目录结构如下。 我们有一个JSON文件来指导您如何使用clips目录中的数据。
dataset
|
|----clips/ # 视频剪辑
|------|
|------|----some_clip/ # 剪辑中的序列图像, 共20帧
|------|----…
|
|----tasks.json # 训练集中的标记数据,以及测试集中的提交模板。
示例
演示代码显示了车道数据集的数据格式和评估工具的用法。
import json
import numpy as np
import cv2
import matplotlib.pyplot as plt
from evaluate.lane import LaneEval
%matplotlib inline
假设我们有两个json文件,一个是ground truth,另一个是预测。
我们假设预测json文件中的每一行都对应于地面真实json,这意味着这两行都与同一张图片相关。
json_pred = [json.loads(line) for line in open('pred.json').readlines()] # 二者好像没什么区别
json_gt = [json.loads(line) for line in open('label_data.json')]
pred, gt = json_pred[0], json_gt[0]
pred_lanes = pred['lanes']
run_time = pred['run_time']
gt_lanes = gt['lanes']
y_samples = gt['h_samples']
raw_file = gt['raw_file']
首先看一下图像。
img = plt.imread(raw_file)
plt.imshow(img)
plt.show()
其次看一下怎么用y_samples。
img_vis = img.copy()
for lane in gt_lanes_vis:
for pt in lane:
cv2.circle(img_vis, pt, radius=5, color=(0, 255, 0))
plt.imshow(img_vis)
plt.show()
 再次我们看一下真值和预测值的样例。
再次我们看一下真值和预测值的样例。
gt_lanes_vis = [[(x, y) for (x, y) in zip(lane, y_samples) if x >= 0] for lane in gt_lanes]
pred_lanes_vis = [[(x, y) for (x, y) in zip(lane, y_samples) if x >= 0] for lane in pred_lanes]
img_vis = img.copy()
for lane in gt_lanes_vis:
cv2.polylines(img_vis, np.int32([lane]), isClosed=False, color=(0,255,0), thickness=5)
for lane in pred_lanes_vis:
cv2.polylines(img_vis, np.int32([lane]), isClosed=False, color=(0,0,255), thickness=2)
plt.imshow(img_vis)
plt.show()
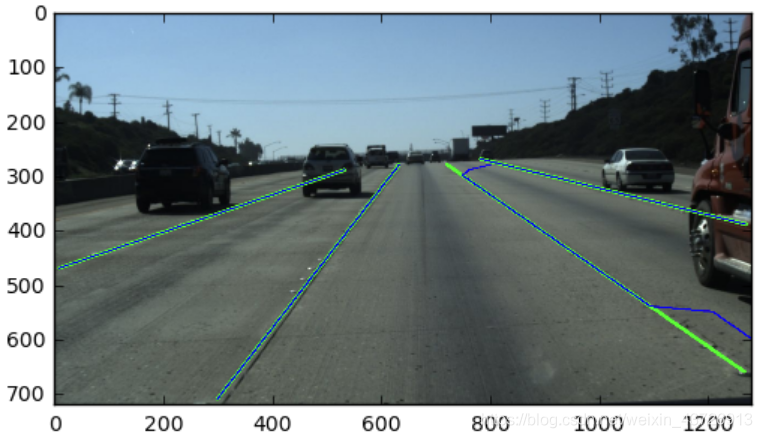 现在,我们可以使用该工具根据数据评估预测。
现在,我们可以使用该工具根据数据评估预测。
benchmark网页上描述了评估指标。
np.random.shuffle(pred_lanes)
# 整个数据集上的准确率Acc、FP、FN
print LaneEval.bench(pred_lanes, gt_lanes, y_samples, run_time)

benchmark网页如下。
import numpy  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









