







一.Resnet网络架构
1.plain network
(原文表述)Plain Network. Our plain baselines (Fig. 3, middle) are mainly inspired by the philosophy of VGG nets [41] (Fig. 3, left). The convolutional layers mostly have 3×3 filters and follow two simple design rules: (i) for the same output feature map size, the layers have the same number of filters; and (ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. We perform downsampling directly by convolutional layers that have a stride of 2. The network ends with a global average pooling layer and a 1000-way fully-connected layer with softmax. The total number of weighted layers is 34 in Fig. 3 (middle).
plain网络的结构主要受VGG网络的启发。卷积层主要为3*3的滤波器,并遵循以下两点要求:
1)输出特征图的大小相同的层,应该有相同数量的滤波器;2)如果特征图大小被减半,滤波器的数量应该加倍以保证每一层的时间复杂度相同。我们直接使用步长为2的卷积层进行下采样。这个网络最后以一个平均池化层和一个带有softmax的1000个通道的全连接层结束。其中有权重的层总数是34.
2.residual network
(原文表述)Residual Network. Based on the above plain network, we insert shortcut connections (Fig. 3, right) which turn the network into its counterpart residual version. The identity shortcuts (Eqn.(1)) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig.3). When the dimensions increase(dotted line shortcuts in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
残差网络。基于上述的plain网络,我们插入快捷连接,将网络转换为对应的残差版本。当输入和输出维度相同时,可以使用恒恒等快捷连接键。当维度增加时,考虑两个选项:(1)shortcut快捷连接仍使用恒等映射,在增加的维度上使用0来填充,这样做不会增加额外的参数;(2)使用等式2中的快捷连接通过1*1的卷积来保持维度一致。
对于这两个选项,当快捷连接跨过两种尺寸的特征图时,均使用步长为2的卷积。
3.bottleneck 中building Block
3.1 deeper bottleneck architecture
(原文表述)Deeper Bottleneck Architectures. Next we describe our deeper nets for ImageNet. Because of concerns on the training time that we can afford, we modify the building block as a bottleneck design 4 . For each residual function F, we use a stack of 3 layers instead of 2 (Fig. 5). The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3×3 layer a bottleneck with smaller input/output dimensions. Fig. 5 shows an example, where both designs have similar time complexity.
更深层次的瓶颈架构 :我们将描述针对ImageNet的更深层的网络:因为考虑到我们可以负担起训练时间,所以我们把building block积木块修改为瓶颈设计。对于每个残差函数F,我们使用一个由三层组成的堆栈。这三层分别是1*1、3*3和1*1卷积,其中1*1层负责减小维度然后增加(恢复)维度,使3*3层成为输入/输出维数较小的瓶颈。图5给出一个例子,如下两种结构都具有相似的时间复杂度。
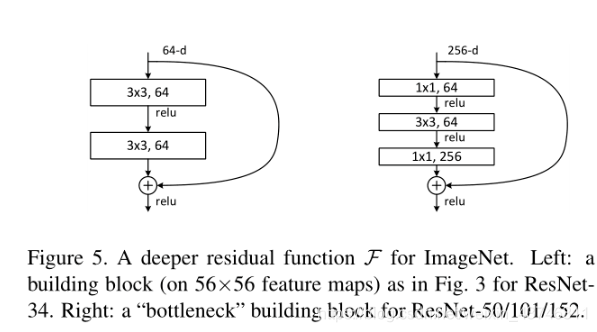
图5:ImageNet的一个深层次残差函数F。左图:如图3的一个用于resnet-34的积木块。右:resnet-50/101/152的“瓶颈积木块。
”
3.2 “bottleneck”building Block理解
(1)为何说两种设计都具有相似的时间复杂度?我们以图5为例进行验证,图5对应conv2.x,输出特征图的尺寸为56x56,我们主要计算卷积中的乘法次数,对于图5左边,乘法次数是(3x3x64x56x56x64)x2,对于图5右边,乘法次数是1x1x256x56x56x64+3x3x64x56x56x64+1x1x64x56x56x256,红色部分是一样的,剩余部分由于256=64x4,前者可以分解为3x3x(64x56x56x64),后者可以分解为(4+4)x(64x56x56x64),是9与8的细微差别,所以说具有相似的时间复杂度。
(2)如何将building Block块转换为对应的“bottleneck”building Block块?通过(1)的计算过程,可知,就保证时间复杂度相似而言,只需要将输出的维度变为原来的4倍就行了,比如原本的building Block块是{(3x3,d),(3x3,d},则转换后的对应“bottleneck”building Block块为{(1x1,d),(3x3,d),(1x1,4xd)}。














 5718
5718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









