







18.检查点模型
截止到P265页
//2022.1.18日22:14开始学习
在第13章中,我们讨论了如何在培训完成后将模型保存和序列化到磁盘上。在上一章中,我们学习了如何在发生欠拟合和过拟合时发现它们,使你能够在保留训练时表现良好的模型的同时,剔除表现不佳的实验。
然而,您可能想知道是否有可能将这两种策略结合起来。当我们的损失/准确性提高时,我们可以序列化模型吗?或者,在培训过程中,是否可能只序列化最好的模型(即,损失最低或准确度最高的模型)?你的赌注。幸运的是,我们也不需要构建一个自定义回调函数——这个功能已经被集成到Keras中了。
18.1 检查点神经网络模型的改进
检查点的一个很好的应用是,在培训期间每次有改进时,都将网络序列化到磁盘上。我们将“改进”定义为损失的减少或准确性的增加——我们将在实际的Keras回调中设置这个参数。
代码略。
对保存权重的解释:
![]()
对于上述文件名的解释:
正如你所看到的,每个文件名有三个组件。第一个是静态字符串,权重。然后是历元数。文件名的最后一个组成部分是我们度量改进的指标,在本例中是验证丢失。
请记住,您的结果将与我的不匹配,因为网络是随机的,并初始化随机变量。根据初始值,您可能有显著不同的模型检查点,但在训练过程结束时,我们的网络应该获得类似的准确性(±几个百分点)。
18.2 检查点最佳NN
检查点改进也许最大的缺点在于,我们最终得到一堆extrafiles(不太可能)感兴趣,这是尤其如此,如果我们确认损失上下运动在训练时期——这些改进将被捕获和序列化到磁盘。在这种情况下,最好只保存一个模型,并在我们的度量在训练期间每次改进时简单地覆盖它。
幸运的是,完成这个操作就像更新ModelCheckpoint类以接受一个简单的字符串一样简单(即,没有任何模板变量的文件路径)。然后,每当我们的指标改进时,该文件就会被简单地覆盖。为了理解这个过程,让我们创建第二个名为cifar10_checkpoint_best.py的Python文件,并查看其中的差异。
在这里,您可以看到我们覆盖了cifar10_best_weights。如果我们的验证损失减少,hdf5文件与更新的网络。这有两个主要好处:
- 在训练过程的最后只有一个序列化文件——获得最低损失的模型历元。
- 我们没有捕捉到损失上下波动的“增量改进”。相反,我们只保存和覆盖现有的最佳模型,如果我们的度量获得的损失低于所有以前的时代。
18.3 总结
在本章中,我们回顾了如何在培训期间监控给定的指标(例如,验证丢失、验证准确性等),然后将高性能网络保存到磁盘。在Keras内部有两种方法来实现这一点:
- 检查点增量的改进。
- 检查点只在过程中找到最好的模型。
就我个人而言,比起前者,我更喜欢后者,因为它会产生更少的文件和一个代表培训过程中发现的最佳时期的输出文件。
19.可视化网络结构
截止到2022.1.18日晚上23:40
P273页
//2022.1.19日上午10:46开始阅读
我们还没有讨论的一个概念是架构可视化,即在网络中构造节点和相关连接的图,并将图保存为图像(即. png)到磁盘的过程。JPG,等等)。图中的节点表示层,而节点之间的连接表示网络中的数据流。
图像常常包含以下组件:
- 输入像素大小;
- 输出向量大小;
- 图层名称;
我们通常在(1)调试我们自己的自定义网络体系结构和(2)发布时使用网络体系结构可视化,其中体系结构的可视化比包含实际的源代码或试图构造一个表来传递相同的信息更容易理解。在本章的其余部分中,您将学习如何使用Keras构建网络架构可视化图,然后将图作为实际的映像序列化到磁盘上。
19.1 网络结构可视化的重要性
需要使用到网络结构可视化的情况:
- 在出版物中实现了网络架构但是并不清晰;
- 实现自定义的网络架构;
简而言之,网络可视化验证了我们的假设,即代码正确地构建了我们想要构建的模型。通过检查输出图形图像,您可以看到您的逻辑中是否存在缺陷。最常见的缺陷包括:
- 网络中不正确的层排序;
- 假设CONV或POOL层后的输出卷大小(不正确)。
每当实现一个网络架构时,我建议您在每个CONV和POOL层块之后将网络架构可视化,这将使您能够验证您的假设(更重要的是,及早捕获网络中的“bug”)。
卷积神经网络中的错误与应用程序中由边缘情况导致的其他逻辑错误不同。相反,一个CNN可以很好地训练和获得合理的结果,即使与不正确的层顺序,但是如果您没有意识到这个错误已经发生,您可能会报告您的结果,以为您做了一件事,但实际上做了另一件事。
19.1.1 安装需要的库graphviz和pydot-ng
19.1.2 可视化Keras网络
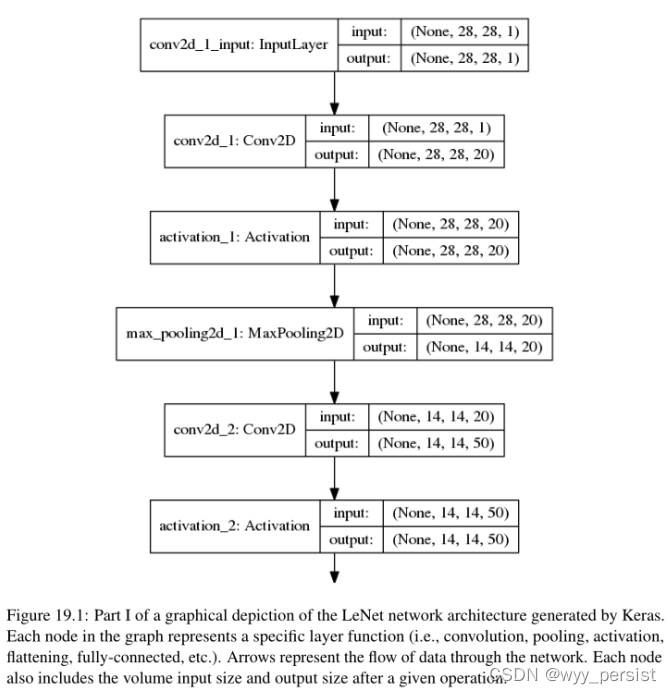
在这里,我们可以看到通过网络的数据流的可视化。每一层都表示为体系结构中的一个节点,然后连接到其他层,最终在应用softmax分类器后终止。注意网络中的每一层是如何包含一个输入和输出属性的——这些值是进入该层和退出该层时各自的体积空间维度的大小。
您可能想知道None在数据形状中表示什么(None, 28, 28, 1)。None实际上是我们的批处理大小。当可视化网络架构时,Keras不知道我们想要的批处理大小,所以它将该值保留为None。当训练时,这个值将改变为32、64、128等,或任何我们认为合适的批量大小。
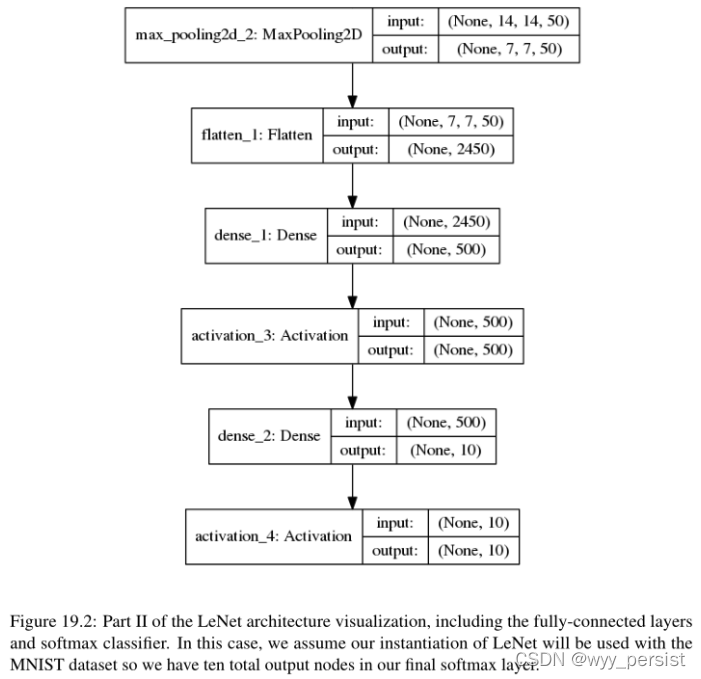
19.2 总结
正如我们可以用代码表达LeNet架构一样,我们也可以将模型本身可视化为一个图像。当您开始深度学习之旅时,我强烈建议您使用这段代码来可视化您正在使用的任何网络,特别是如果您对它们不熟悉的话。确保您理解通过网络的数据流,以及基于CONV、POOL和FC层的容量大小如何变化,将使您对体系结构有更深入的了解,而不仅仅是依赖于代码。
在实现我自己的网络架构时,我在实际编写网络代码时,每隔2-3个层块就将架构可视化,以此验证我的思路是否正确——这一操作有助于我尽早发现逻辑中的错误或缺陷。
20. 开箱即用的分类cnn
到目前为止,我们已经学会了如何从零开始训练我们自己的自定义卷积神经网络。大部分这些cnn更浅一侧(和在较小的数据集),所以他们可以很容易地训练我们的cpu,而无需诉诸更多昂贵的gpu,让我们掌握基本的神经网络和深度学习不用空我们的口袋。
然而,由于我们一直在研究更浅层的网络和更小的数据集,我们还不能充分利用深度学习提供给我们的全部分类能力。幸运的是,Keras库附带了五个在ImageNet数据集上预先训练过的cnn:
- VGG16
- VGG19
- ResNet50
- Inception V3
- Xception
正如我们在第5章中讨论的,ImageNet大规模视觉识别挑战(ILSVRC)[42]的目标是训练一个模型,可以正确地将输入图像分类为1000个单独的对象类别。这1000个图像类别代表了我们在日常生活中遇到的对象类别,比如狗、猫、各种家居用品、车辆类型等等。
这意味着,如果我们利用在ImageNet数据集上预先训练的cnn,我们可以立即识别所有这1000个对象类别——不需要训练!一个完整的对象类别列表,你可以使用预先训练的ImageNet模型识别,可以在这里找到http://pyimg.co/x1ler。
在本章中,我们将回顾在Keras库中预先训练的最先进的ImageNet模型。然后,我将演示如何编写Python脚本来使用这些网络对我们自己的定制图像进行分类,而无需从头开始训练这些模型。
20.1 在Keras库中最先进的CNN
参数化学习的两个方面:
- 定义一个机器学习模型,它可以在训练期间从我们的输入数据中学习模式(这需要我们在训练过程中花费更多的时间),但测试过程要快得多。
- 获得一个可以使用少量参数定义的模型,这些参数可以很容易地表示网络,而不管训练的大小。
因此,我们的实际模型大小是其参数的函数,而不是训练数据的数量。我们可以在100万张图像的数据集或100张图像的数据集上训练非常深入的CNN(如VGG或ResNet),但结果输出的模型大小将是相同的,因为模型大小是由我们选择的架构决定的。
其次,神经网络承担了绝大部分的工作。我们将大部分时间花在训练cnn上,这可能是由于架构的深度、训练数据的数量,也可能是为了调整超参数而进行的实验数量。
gpu等优化硬件使我们能够加速训练过程,因为我们需要在反向传播算法中执行前向传递和后向传递——正如我们已经知道的,这个过程是我们的网络实际学习的过程。然而,一旦网络被训练,我们只需要执行forward pass对给定的输入图像进行分类。前向传递速度大大加快,使我们能够使用CPU上的深度神经网络对输入图像进行分类。
在大多数情况下,本章中介绍的网络架构无法在CPU上实现真正的实时性能(为此我们需要GPU)——但这没关系;您仍然可以在您自己的应用程序中使用这些预先训练过的网络。如果您有兴趣学习如何在具有挑战性的ImageNet数据集上从头开始训练最先进的卷积神经网络,请务必参考本书的ImageNet Bundle,我在那里演示了这一点。
20.1.1 VGG16 和 VGG19

VGG网络架构(图20.1)由Simonyan和Zisserman在2014年的论文《Very Deep Convolutional Networks for Large Scale Image Recognition》中引入[95]。
正如我们在第15章中讨论的那样,VGG网络家族的特征是只使用3 × 3卷积层,它们彼此叠加在一起,且深度不断增加。减少卷大小是由最大池处理的。两个完全连接的层(每个层有4,096个节点)之后是一个softmax分类器。
在2014年,16和19层网络被认为是非常深的,尽管我们现在已经有了ResNet架构,可以成功地训练深度为50-200的ImageNet和超过1000的CIFAR-10。不幸的是,VGG有两个主要缺点:
- 这是痛苦的慢训练(幸运的是,我们只测试输入图像在本章)。
- 网络权值本身相当大(就磁盘空间/带宽而言)。由于其深度和全连接节点的数量,VGG16序列化的权重文件为533MB,而VGG19为574MB。
幸运的是,这些权重只需要下载一次——从那里我们可以将它们缓存到磁盘。
20.1.2 ResNet
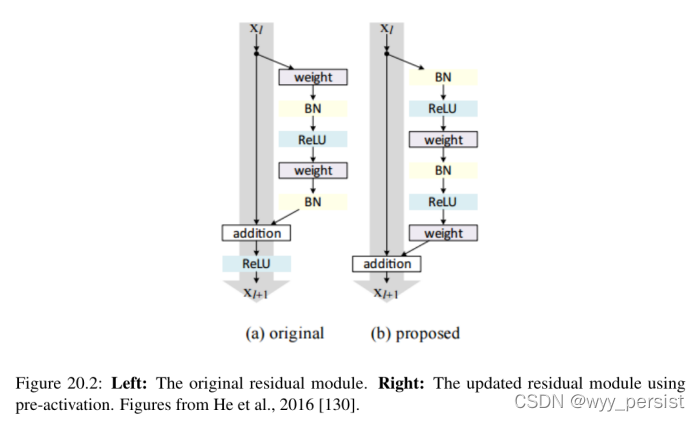
首先介绍了他在他们一份2015年的论文等人,深残余学习图像识别[96],ResNet架构已经成为一个具有开创性的工作深度学习文学,证明极深的网络可以使用标准训练SGD(和一个合理的初始化函数)通过使用剩余模块。
进一步的准确性可以通过更新残差模块来使用身份映射来获得(图20.2),这在他们2016年的后续出版物《深度残差网络中的身份映射》中得到了证明[130]。
也就是说,请记住,Keras核心库中的ResNet50(即50个权重层)实现是基于前一篇2015年的论文。尽管ResNet比VGG16和VGG19要深得多,但由于使用了全局平均池而不是全连接层,模型尺寸实际上要小得多,这使得ResNet50的模型尺寸减少到102MB。
如果你有兴趣学习ResNet架构的更多信息,包括剩余的模块和它是如何工作的,请参考实践者Bundle和ImageNet Bundle,其中深入介绍了ResNet。
20.1.3 Inception V3
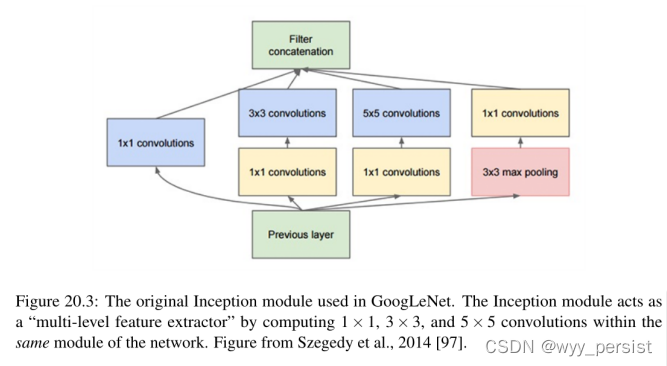
“盗梦空间”模块(以及最终的盗梦空间架构)是由Szegedy等人在2014年的论文《深入卷积》中引入的[97]。《盗梦空间》的目标模块(图20.3)是作为“多层次特征提取器”通过计算1×1,3×3,那5×5卷绕在同一个模块中网络——然后thesefilters堆放在通道的输出尺寸被送入下一层之前的网络。
这个架构的最初的化身被称为GoogLeNet,但是随后的表现被简单地命名为Inception vN,其中N指的是谷歌发布的版本号。Keras核心中包含的Inception V3架构来自后期由Szegedy等人出版的《重新思考计算机视觉的Inception架构》(2015)[131],其中提出了对Inception模块的更新,以进一步提高ImageNet分类的准确性。盗梦空间V3的权重比VGG和ResNet都小,只有96MB。
有关Inception模块如何工作的更多信息(以及如何从头开始训练GoogLeNet),请参阅实践者Bundle和ImageNet Bundle。
20.1.4 Xception
Xception是由François Chollet本人提出的,他是Keras库的创造者和主要维护者,他在2016年的论文《Xception: Deep Learning with depth -》中提出[132]。Xception是Inception体系结构的扩展,它用深度可分离的卷积替换标准的Inception模块。Xception权值是Keras库中包含的预训练网络中最小的,为91MB。
20.1.5 能不能再小一点
虽然它没有包含在Keras库中,但我想说的是,当我们需要一个小的内存空间时,经常会使用SqueezeNet架构[127]。SqueezeNet非常小,只有4.9MB,并且通常在需要对网络进行培训,然后通过网络和/或资源受限的设备部署网络时使用。
再次,SqueezeNet不包括在Keras的核心中,但我确实演示了如何从ImageNet集合内的ImageNet数据集上从头开始训练它。
20.2 使用预先训练的ImageNet cnn分类图像
我们已经知道,CNN将图像作为输入,然后返回一组与类标签对应的概率作为输出。在ImageNet上训练的CNN的典型输入图像大小为224 × 224、227 × 227、256 × 256和299 × 299;然而,您也可能看到其他方面。
VGG16、VGG19和ResNet都接受224 × 224个输入图像,而Inception V3和Xception需要229 × 229个像素输入,如下代码块所示:
# 初始化输入图像的形状及预处理函数(可能会根据选择的模型进行改变)
inputShape = (224, 224)
preprocess = imagenet_utils.preprocess_input
# 如果我们是用Inception V3或者Xception,那么改变输入的图片大小
if args["model"] in ("inception", "xception"):
inputShape = (299, 299)
preprocess = preprocess_input
在这里,我们初始化我们的inputShape为224 × 224像素。我们还将我们的预处理函数初始化为来自Keras的标准preprocess_input(它执行均值减法,一种我们在实践者包中介绍的规范化技术)。然而,如果我们使用Inception或Xception,我们需要将inputShape设置为299 × 299像素,然后更新预处理以使用执行不同类型缩放http://pyimg.co/3ico2的单独预处理功能。

第58行使用MODELS字典和——model命令行参数来获取正确的网络类。然后在第59行使用预先训练的ImageNet权值实例化CNN。
同样,请记住,VGG16和VGG19的权重是500MB。ResNet权重≈100MB,而Inception和Xception权重在90-100MB之间。如果这是您第一次为给定的网络架构运行这个脚本,这些权重将(自动)下载并缓存到您的本地磁盘。根据你的网速,这可能需要一段时间。但是,一旦下载了权重,就不需要再次下载它们,从而允许imagenet_pretraining .py的后续运行速度更快。
我们的网络现在已经加载完毕,可以对图像进行分类了——我们只需要对图像进行预处理,以便进行分类:
# 从磁盘加载预训练模型权重,如果是第一次,那么需要下载
print("[INFO] loading {}...".format(args["model"]))
Network = MODELS[args["model"]]
model = Network(weight="imagenet")
# 加载图像,并使用Keras库的helper助手,保证输入图像和inputShape保持一致
print("[INFO] loading and pre-processing image...")
image = load_img(args["image"], target_size=inputShape)
image = img_to_array(image)
# 调整输入图像的形式
image = np.expand_dims(image, axis=0)
# 使用恰当的预处理函数处理图片
image = preprocess(image)
第65行使用提供的inputShape从磁盘加载输入图像,以调整图像的宽度和高度。假设我们使用“通道最后”排序,我们的输入图像现在被表示为NumPy数组的形状(inputShape[0], inputShape[1], 3)。
但是,我们使用cnn对图像进行批量训练/分类,所以我们需要通过np在数组中增加一个额外的维度。expand_dims函数在第72行。后调用np。expand_dims,我们的图像现在将有形状(1,inputShape[0], inputShape[1], 3),同样,假设通道最后排序。忘记添加这个额外的维度将导致在调用模型的.predict方法时出现错误。
最后,第76行调用适当的预处理函数来执行均值减法和/或缩放。
现在,我们准备将图像通过网络传递,并获得输出分类:
# 分类图像
print("[INFO] classifying image with {}...".format(args["model"]))
preds = model.predict(image)
P = imagenet_utils.decode_predictions(preds)
# 循环所有的预测,并显示排名前5的预测
for (i, (imagenetID, label, prob)) in enumerate(P[0]):
print("{}. {}: {:2f}%".format(i + 1, label, prob * 100))
在80号线上调用。predict返回来自CNN的预测。给出这些预测后,我们将它们传递到ImageNet实用函数.decode_predictions中,以获得ImageNet类标签id、“人类可读的”标签以及与每个类标签相关的概率列表。前5个预测(即概率最大的标签)然后打印到终端的第85行和第86行。
我们最终的代码块将处理通过OpenCV从磁盘加载我们的图像,在图像上绘制#1预测,并最终显示到我们的屏幕上:

20.2.1 分类结果
使用以下命令实现使用预训练模型预测结果输出。


预测结果展示。
20.3 总结
在本章中,我们回顾了在Keras库的ImageNet数据集上预先训练的五个卷积神经网络:

然后,我们学习了如何使用这些体系结构对您自己的输入图像进行分类。假设ImageNet数据集包含1000个您在日常生活中可能遇到的常见对象类别,这些模型将成为非常好的“通用”分类器。根据您自己学习深度学习的动机和最终目标,仅这些网络就足以构建您想要的应用程序。
但是,如果读者有兴趣学习更高级的技术,以便在更大的数据集上训练更深入的网络,我绝对建议您阅读实践者Bundle。如果读者想要完整的体验,并了解如何在具有挑战性的ImageNet数据集上训练这些最先进的网络,请参阅ImageNet Bundle。
21.案例学习:使用CNN破解验证码
到目前为止,在这本书中,我们已经使用了为我们预先编译和标记的数据集-但如果我们想要开始创建我们自己的自定义数据集,然后训练一个CNN呢?在本章中,我将展示一个完整的深度学习案例研究,它将给你一个例子:
- 下载一组图片;
- 标注并注解图片用于训练;
- 训练一个CNN网络在自己的数据集上;
- 评价并测试训练过的CNN
我们将下载的图像数据集是一组验证码图像,用于防止机器人自动注册或登录到一个给定的网站(或更糟的是,试图强行进入某人的帐户)。
一旦我们下载了一组验证码图像,我们需要手动标记验证码中的每一个数字。我们将发现,获取和标记一个数据集可能是战斗的一半(如果不是更多的话)。取决于你需要多少数据,是多么容易获得,以及是否需要标签的数据(例如,分配一个真实图像标签),它可以是一个昂贵的过程,无论是从时间和/ orfinances(如果你花钱雇人标签的数据)。
因此,只要有可能,我们就尝试使用传统的计算机视觉技术来加速标记过程。在本章的背景下,如果我们使用图像处理软件,如Photoshop或GIMP,手动提取验证码图像中的数字来创建我们的训练集,可能会花费我们几天不间断的工作来完成任务。
然而,通过应用一些基本的计算机视觉技术,我们可以在不到一个小时的时间内下载并标记我们的训练集。这也是我鼓励深度学习从业者投资计算机视觉教育的众多原因之一。书等实际Python和OpenCV旨在帮助您迅速掌握计算机视觉和OpenCV的基本面——如果你是认真的掌握深度学习应用于计算机视觉,你应该好好学习的基础广泛的计算机视觉和图像processingfield。
我还想提到的是,现实世界中的数据集不像像MNIST、CIFAR-10和ImageNet这样的基准数据集,在这些基准数据集中,图像被整齐地标记和组织,我们的目标只是在数据上训练一个模型并对其进行评估。这些基准数据集可能是具有挑战性的。但在现实世界中,困难往往在于获取(标记的)数据本身——在许多情况下,标记的数据比通过在数据集上训练网络而获得的深度学习模型更有价值。
例如,如果您正在运营一家负责为美国政府创建一个定制的自动牌照识别(ANPR)系统的公司,您可能会花费数年时间来构建一个健壮的、大规模的数据集,同时评估各种识别牌照的深度学习方法。积累如此庞大的标签数据集将使你比其他公司更有竞争优势——在这种情况下,数据本身比最终产品更有价值。
你的公司更有可能被收购,仅仅因为你拥有对大量标签数据集的独家权利。建立一个令人惊叹的深度学习模式识别车牌的价值只会增加你的公司,但同样,带安全标签的数据获取和复制是昂贵的,如果你自己的数据集的关键,很难(如果不是不可能的话)复制,毫无疑问,你的公司的主要资产是数据,而不是深度学习。
在本章的其余部分,我们将看看如何获取图像数据集,对其进行标记,然后应用深度学习来破解验证码系统。
21.1 用CNN破解验证码
这一章被分成许多部分,以帮助保持它的组织和易于阅读。在第一部分中,我将讨论我们正在使用的验证码数据集,并讨论负责任披露的概念——当涉及到计算机安全时,您应该总是这样做。
从这里我将讨论我们项目的目录结构。然后我们创建一个Python脚本来自动下载一组图像,我们将使用这些图像进行培训和评估。
下载完我们的图片后,我们需要使用一些计算机视觉来帮助我们对图片进行标记,这使得这个过程比在GIMP或Photoshop等图片软件中简单地裁剪和标记要容易得多,速度也快得多。一旦我们对数据进行标记,我们将训练LeNet架构——正如我们将发现的那样,我们能够打破验证码系统,并在不到15个epoch内获得100%的准确性。
21.1.1 关于负责任披露的说明
生活在美国东北部/中西部地区,如果没有E-ZPass,很难在主要高速公路上出行[133]。E-ZPass是一种电子收费系统,用于许多桥梁、州际公路和隧道。游客只需购买一个易通转发器,将其放在汽车的挡风玻璃上,就可以享受不用停车就能快速通行的能力,因为易通账户上的信用卡会收取任何通行费。
- ZPass让过路费变成了一个更加“享受”的过程(如果有的话)。与其在需要进行实体交易的地方没完没了地排队(比如,把钱交给收银员,拿到找零,打印报销收据,等等),你可以在快车道上快速行驶而不停车——这为你节省了很多时间,也少了很多麻烦(不过你还是得付过路费)。
我花了很多时间在马里兰和康涅狄格之间旅行,这两个州沿着美国I-95走廊。I-95公路走廊,尤其是在新泽西州,有太多的收费站,所以对我来说,买快易通通行证是一个很简单的决定。大约一年前,我的易趣通账户上的信用卡过期了,我需要更新它。我去了E-ZPass纽约网站(我购买E-ZPass的州)登录并更新我的信用卡,但我突然停了下来(图21.1)。
你能找出这个系统的缺陷吗?他们的“验证码”不过是在纯白色背景上的四位数字,这是一个主要的安全风险——对于那些拥有基本计算机视觉的人来说或者深度学习体验可以开发一款软件来破解这个系统。
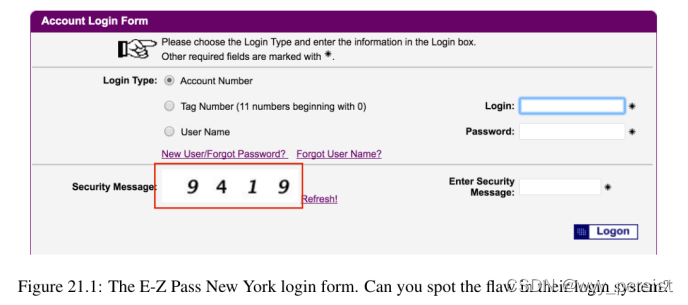
这就是负责任披露概念的由来。负责任的披露是一个计算机安全术语,用于描述如何披露漏洞。在检测到威胁后,不要立即将其发布到互联网上让所有人都看到,而是要首先联系利益相关者,确保他们知道存在问题。涉众可以尝试修补软件并解决漏洞。
简单地忽略漏洞并隐藏问题是一种错误的安全性,这是应该避免的。在理想情况下,该漏洞在公开披露之前就已解决。
然而,当利益相关者不承认问题或者没有在合理的时间内解决问题时,就会产生一个道德难题——你是否隐藏问题并假装它不存在?或者你会披露它,让更多的人注意到问题,从而更快地解决问题?负责任的披露是指你首先将问题提交给利益相关者(负责任)——如果问题没有解决,那么你需要披露问题(披露)。
为了证明E-ZPass NY系统面临的风险,我训练了一个深度学习模型来识别验证码中的数字。然后我写了第二个Python脚本(1)自动填充我的登录凭证(2)打破验证码,允许我的脚本访问我的帐户。
在这种情况下,我只是自动登录我的帐户。使用这个“功能”,我可以自动更新信用卡,生成过路费报告,甚至在我的易通卡中添加一辆新车。但一些不法分子可能会利用这一方法,以暴力方式进入客户的账户。
在我写这一章的一年前,我通过电子邮件、电话和Twitter联系了E-ZPass。他们确认收到了我的信息;然而,尽管进行了多次接触,但没有采取任何措施来解决这个问题。
在本章的其余部分,我将讨论如何使用E-ZPass系统来获取验证码数据集,然后我们将对其进行标记和训练深度学习模型。我不会分享Python代码自动登录到一个帐户-这是在责任披露的边界之外,所以请不要问我这段代码。
我真诚的希望在这本书出版的时候,E-ZPass NY将更新他们的网站并解决验证码漏洞,从而使本章成为将深度学习应用于手工标记数据集的一个很好的例子,没有任何漏洞威胁。
请记住,所有的知识都伴随着责任。这种知识,在任何情况下,都不应用于邪恶或不道德的原因。本案例研究是一种方法,用于演示如何获取和标记自定义数据集,然后在此基础上训练深度学习模型。
21.1.2 验证码破解器的目录结构
在pyimagesearch模块中的目录:

我们还将在pyimagessearch模块之外创建第二个目录,这个名为captcha_breaker,并包含以下文件和子目录:

captcha_breaker目录是我们所有的项目代码存储的地方,用来破坏图像验证码。我们将在dataset目录中存储我们将手工标记的带标签的数字。我喜欢用下面的目录结构模板来组织我的数据集:

因此,我们的数据集目录将具有以下结构:
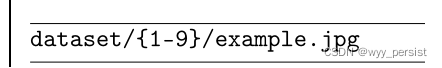
其中dataset是根目录,{1-9}是可能的数字名,example.jpg将是给定数字的示例。
下载目录将存储从E-ZPass网站下载的原始验证码。jpg文件。在输出目录中,我们将存储经过训练的LeNet体系结构。
顾名思义,download_images.py脚本将负责实际下载示例验证码并将它们保存到磁盘。一旦我们下载了一组验证码,我们将需要从每个图像中提取数字并手工标记每个数字——这将通过annotation .py来完成。
train_model.py脚本将在标记的数字上训练LeNet,而test_model.py将把LeNet应用于验证码图像本身。
21.1.3 自动下载示例图片
构建验证码破坏程序的第一步是下载验证码图像的示例。如果我们右击上图21.1中“安全图像”文本旁边的验证码图像,我们将获得以下URL:
如果你复制并粘贴这个URL到你的浏览器中,点击多次刷新,你会注意到这是一个动态程序,每次刷新都会生成一个新的验证码。因此,为了获得示例验证码图像,我们需要请求该图像几百次并保存结果图像。
要自动获取新的验证码图像并将它们保存到磁盘,我们可以使用download_images.py

第2-5行导入所需的Python包。请求库使得处理HTTP连接变得很容易,并且在Python生态系统中被大量使用。如果你的系统上还没有安装请求,你可以通过以下方式安装:
第二个可选的开关numimages,控制我们要下载的验证码图片的数量。默认值为500张图片。由于每个验证码中有4位数字,这个值500将给我们500 × 4 = 2000个数字,我们可以用来训练我们的网络。
我们的下一个代码块初始化我们要下载的验证码图像的URL,以及到目前为止生成的图像的总数:
# 循环下载图片
for i in range(0,args["num_images"]):
try:
# 尝试下载一个图片
r = requests.get(url, timeout=60)
# 保存图片到本地目录中
p = os.path.sep.join(args["output"],"{}.jpg".format(str(total).zfill(5)))
f = open(p, "wb")
f.write(r.content)
f.close()
# 更新计数器
print("[INFO] download:{}".format(p))
total += 1
except:
print("[INFO] error in downloading image...")
# 插入一个sleep线程为了更好的服务
time.sleep(0.1)
在第22行,我们开始对我们想要下载的——num-images进行循环。在第25行上发出下载映像的请求。然后将映像保存到第28-32行上的磁盘。如果下载图像时出现错误,第39行和第40行上的try/except块将捕捉到它,并允许脚本继续。最后,我们在第43行插入一个小睡眠,以礼貌地对待我们所请求的web服务器。
然而,这些只是原始的验证码图像——我们需要提取并标记验证码中的每个数字来创建我们的训练集。为了实现这一点,我们将使用一些OpenCV和图像处理技术来简化我们的工作。
21.1.4 注释并创建我们自己的数据集
那么,如何对每个验证码图像进行标记和注释呢?我们是否打开Photoshop或GIMP,使用“选择/选框”工具复制出一个给定的数字,保存到磁盘,然后重复重复?如果我们这样做,我们可能会花几天的时间不停地工作,以标记原始验证码图像中的每一个数字。
相反,更好的方法是在OpenCV库中使用基本的图像处理技术来帮助我们。打开一个新文件,命名为annotation .py,然后插入以下代码,看看如何更有效地给数据集贴标签:
实际的注释过程如下:
# loop over the image paths
22 for (i, imagePath) in enumerate(imagePaths):
23 # display an update to the user
24 print("[INFO] processing image {}/{}".format(i + 1,
25 len(imagePaths)))
26
27 try:
28 # load the image and convert it to grayscale, then pad the
29 # image to ensure digits caught on the border of the image
30 # are retained
31 image = cv2.imread(imagePath)
32 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
33 gray = cv2.copyMakeBorder(gray, 8, 8, 8, 8,
34 cv2.BORDER_REPLICATE)
在第22行,我们开始对每个单独的imagepath进行循环。对于每个图像,我们从磁盘加载它(第31行),将其转换为灰度(第32行),并在每个方向上用8个像素填充图像的边框(第33和34行)。下图21.2显示了原始图像(左)和填充图像(右)之间的差异。

我们执行这个填充只是为了防止任何我们的数字接触到图像的边界。如果这些数字接触到边界,我们就无法从图像中提取出它们。因此,为了防止这种情况,我们有意地填充输入图像,使给定的数字不可能接触到边界。
我们现在准备通过Otsu的阈值方法对输入图像进行二值化(第九章,实用Python和OpenCV):

这个函数调用自动对我们的图像设定阈值,这样我们的图像就变成了二值图像——黑色像素代表背景,而白色像素代表前景,如图21.3所示。
对图像进行阈值化是我们图像处理管道中的关键步骤,因为我们现在需要找到每个数字的轮廓:
# find contours in the image, keeping only the four largest
41 # ones
42 cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
43 cv2.CHAIN_APPROX_SIMPLE)
44 cnts = cnts[0] if imutils.is_cv2() else cnts[1]
45 cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:4]
第42和43行找到图像中每个数字的轮廓(即轮廓)。为了防止图像中出现“噪声”,我们根据轮廓的面积对其进行排序,只保留四个最大的轮廓(即我们的数字本身)。
考虑到我们的轮廓,我们可以通过计算边界框来提取它们:
# 对于四个轮廓,通过计算边界框来得到数字值
for c in cnts:
# 计算数字的边界框,然后提取数字
(x, y, w, h) = cv2.boundingRect(c)
roi = gray[y - 5:y + h + 5, x - 5 : x + w + 5]
# 显示字符,使其足够大,以便我们看到,然后等待按键
cv2.imshow("ROI", imutils.resize(roi, width=28))
key = cv2.waitKey()
在第48行,我们对阈值图像中的每个轮廓进行循环。我们称之为cv2。boundingRect用于计算数字区域的边界框(x, y)坐标。然后从第52行上的灰度图像中提取感兴趣区域(ROI)。我在图21.4中包含了从原始验证码图像中提取的数字样本作为蒙太奇。
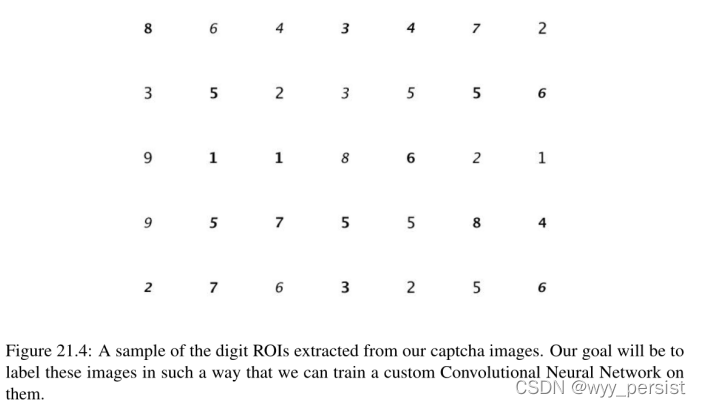
第56行将数字ROI显示在屏幕上,调整其大小,使其足够大,便于我们查看。然后第57行等待键盘上的键按—但是要明智地选择键按!您按下的键将用作数字的标签。
通过cv2了解标签过程是如何工作的。waitKey调用,看看下面的代码块:
# 如果'键被按下,那么忽略当前的数字
if key == ord("'"):
print("[INFO] ignoring character")
continue
# 获取按下的键并构造路,得到输出目录
key = chr(key).upper()
dirPath = os.path.sep.join([args["annot"], key])
# 如果输出目录不存在,请创建该目录
if not os.path.exists(dirPath):
os.makedirs(dirPath)
如果按下了波浪键'(波浪键),我们将忽略字符(第60和62行)。如果我们的脚本意外地检测到输入图像中的“噪音”(即,除了数字以外的任何东西),或者如果我们不确定数字是什么,就可能需要忽略一个字符。否则,我们假定按下的键是数字的标签(第66行),并使用该键构造输出标签的目录路径(第67行)。
因此,所有包含数字“7”的图像将存储在dataset/7子目录中。第70和71行检查dirPath目录是否存在——如果不存在,我们就创建它。
一旦确保dirPath正确存在,我们只需将示例数字写入文件:

第74行获取到目前为止为当前数字写入磁盘的示例总数。然后,我们使用dirPath构造示例数字的输出路径。在执行第75和76行之后,我们的输出路径p看起来像:
再次注意,所有包含数字7的roi示例都将存储在数据集/7子目录中——这是一种简单、方便的方式来组织你的数据集,当标记图像时。
如果我们想按ctrl+c退出脚本,或者如果处理图像出错,我们的最终代码块句柄:
except KeyboardInterrupt:
print("[INFO] manually leaving script")
break
# 此特定图像出现未知错误
except:
print("[INFO] skipping image for some particular reasons...")
如果我们希望按ctrl+c并尽早退出脚本,第85行检测到这一点,并允许我们的Python程序优雅地退出。第90行捕获所有其他错误并简单地忽略它们,允许我们继续标记过程。
在标记数据集时,您最不希望看到的是由于图像编码问题而出现的随机错误,从而导致整个程序崩溃。如果发生这种情况,您将不得不重新开始标记过程。显然,您可以构建额外的逻辑来检测您在哪里中断了,但是这样的示例超出了本书的范围。
要给从E-ZPass NY网站下载的图片贴上标签,只需执行以下命令:
python annotate.py --input downloads --annot dataset

作者已经将上述的2000个数字标注好了,具体数据集在书中的链接中。
21.1.5 预处理数字
正如我们所知,我们的卷积神经网络在训练时需要一个固定宽度和高度的图像来传递。然而,我们标记的数字图像大小不一——有些高过宽,有些宽过高。因此,我们需要一种方法来填充和调整我们的输入图像到固定大小,而不扭曲它们的长宽比。
我们可以通过在captchhelper .py中定义一个预处理函数来调整图像的大小和填充图像,同时保持图像的长宽比:
//截止到2022.1.20日凌晨0:25 截止到P300
//2022.1.20日上午10:52开始学习

行12和13我们做一个检查宽度大于高度,如果是这样,我们沿着大调整图像尺寸(宽度)否则,如果高度大于宽度,我们沿着高度调整(17和18行),这意味着宽度或高度(根据输入图像的尺寸)机关。
然而,相反的维度比它应该的要小。为了解决这个问题,我们可以沿着较短的维度“填充”图像以获得我们的固定大小:

第22和23行计算达到目标宽度和高度所需的填充量。第27和28行对图像应用填充。应用这个填充应该使我们的图像达到我们的目标宽度和高度;然而,在某些情况下,我们可能会在给定的维度上偏离一个像素。解决这种差异的最简单方法就是调用cv2。调整大小(第29行)以确保所有图像的宽度和高度相同。
我们没有立即调用cv2的原因。在函数的顶部调整大小是因为我们首先需要考虑输入图像的长宽比,并尝试首先正确填充它。如果我们不保持图像的宽高比,那么我们的数字就会被扭曲。
21.1.6 训练验证码破解器
# 初始化数据和标签
data = []
labels = []
# 循环输入的图像
for imagePath in paths.list_images(args["dataset"]):
# 加载图像,预处理图片,并存放到data list中
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = preprocess(image, 28, 28)
image = img_to_array(image)
data.append(image)
# 提取类标签从路径中,更新标签list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
在第25和26行,我们分别初始化了数据和标签列表。然后循环遍历第29行labeled——dataset中的每一个图像。对于数据集中的每个图像,我们将其从磁盘加载,将其转换为灰度,并对其进行预处理,使其宽度为28像素,高度为28像素(第31-35行)。然后将图像转换为与keras兼容的数组,并添加到数据列表中(第34和35行)。
我们的下一个代码块处理将原始像素强度值归一化到范围[0,1],然后构造训练和测试分割,并对标签进行one-hot编码:

21.1.7 测试验证码破解器
# 循环得到所有的图片
for imagePath in imagePaths:
# 加载图片然后转换为灰度图像,然后填充图片,保证输入的像素和CNN匹配。
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.copyMakeBorder(gray, 20, 20, 20, 20, cv2.BORDER_REPLICATE)
# 然后使用阈值图像显示数字
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
在第30行,我们开始对每个采样的imagepath进行循环。就像在注释.py示例中一样,我们需要提取验证码中的每个数字。这个提取过程是这样完成的:从磁盘加载图像,将其转换为灰度,填充边界,使数字不能触及图像的边界(第34-37行)。我们在这里添加额外的填充,这样我们就有足够的空间来实际绘制和可视化图像上的正确预测。
第40行和第41行阈值图像,使数字在黑色背景下显示为白色前景。
接着需要在阈值图像中寻找图像的轮廓:

我们可以通过调用cv2来找到这些数字。findContours在thresh图像上。这个函数返回一个(x, y)坐标列表,用于指定每个数字的轮廓。
然后,我们执行两个阶段的排序。第一阶段根据轮廓的大小对其进行排序,只保留最大的四个轮廓。我们(正确地)假设四个最大的等高线是我们想要识别的数字。然而,这些轮廓线并没有固定的空间顺序——我们希望识别的第三个数字可能是碳纳米管列表中的第一个数字。因为我们是从左到右读取数字,所以我们需要从左到右对轮廓进行排序。这是通过sort_contours函数(http://pyimg.co/sbm9p)完成的。
第53行获取我们的灰度图像,并通过复制灰度通道三次(分别对应Red、Green和Blue通道)将其转换为三个通道的图像。然后由CNN在第54行初始化我们的预测列表。
已知验证码中数字的轮廓,我们现在可以打破它:
# 循环轮廓
for c in cnts:
# 计算box对于轮廓,然后得到数字
(x, y, w, h) = cv2.boundingRect(c)
roi = gray[y - 5:y + h + 5, x - 5:x + w + 5]
# 预处理ROI并分类
roi = preprocess(roi, 28, 28)
roi = np.expand_dims(img_to_array(roi), axis=0) / 255.0
pred = model.predict(roi).argmax(axis=1)[0] + 1
predictions.append(str(pred))
# 绘制预测结果在输出图像上
cv2.rectangle(output, (x - 2, y - 2), (x + w + 4, y + h + 4), (0, 255, 0), 1)
cv2.putText(output,str(pred), (x - 5, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 255, 0), 2)
在第57行,我们遍历这些数字的每个轮廓(已经从左到右排序)。然后,我们提取第60行和第61行数字的ROI,然后在第64行和第65行对其进行预处理。
第66行调用模型的.predict方法。由.predict返回概率最大的索引将是我们的类标签。我们给这个值加上1,因为索引值从0开始;但是,没有零类——只有数字1-9的类。然后这个预测被添加到第67行上的预测列表中。
第70和71行在当前数字周围绘制一个边界框,而第72和73行在输出图像本身上绘制预测数字。
我们的最后一个代码块处理将破解出来的验证码作为字符串写入终端,并显示输出的图像:
# show the output image
76 print("[INFO] captcha: {}".format("".join(predictions)))
77 cv2.imshow("Output", output)
78 cv2.waitKey()
在图21.7中,我包含了运行test_model.py生成的四个示例。在每一个案例中,我们都正确地预测了数字字符串,并使用在少量训练数据上训练的简单网络结构破坏了图像验证码。
21.2 总结
在本章中,我们学习了如何:收集原始图像的数据集。2. 标签和注释我们的图像训练。3.在我们标记的数据集上训练一个自定义卷积神经网络。4. 在示例图像上测试和评估我们的模型。

我强烈建议你学习图像处理和OpenCV库的基础知识——对这些概念有一个基本的理解将使你能够:
- 在更高的层次上欣赏深度学习。2. 开发更健壮的应用程序,使用深度学习进行图像分类3。利用图像处理技术来更快地实现你的目标。
在上面的第21.1.4节中可以找到一个很好的使用基本图像处理技术的例子,在这里我们能够快速地注释和标记我们的数据集。如果不使用简单的计算机视觉技术,我们就只能用Photoshop或GIMP等图像编辑软件手动裁剪并将示例数字保存到磁盘上。相反,我们能够编写一个快速而简单的应用程序,自动从验证码中提取每一位数字——我们所要做的就是按键盘上适当的键来标记图像。
如果你是OpenCV或计算机视觉的新手,或者你只是想提升你的技能,我强烈建议你阅读我的书《实用Python和OpenCV[8]》。这本书是一个快速阅读,将给你的基础,你需要成功地应用深度学习图像分类和计算机视觉任务。
22.案例学习:微笑检测
为了完成这个任务,我们将在包含微笑和不微笑的人脸的图像数据集上训练LetNet架构。一旦我们的网络训练好,我们将创建一个单独的Python脚本——这个脚本将通过OpenCV内置的Haar级联人脸检测器检测图像中的人脸,从图像中提取感兴趣的人脸区域(ROI),然后将ROI通过LeNet进行微笑检测。
当开发真实世界的图像分类应用程序时,您常常需要将传统的计算机视觉和图像处理技术与深度学习相结合。我尽我最大的努力确保这本书在算法、技术和库方面独立,你需要了解这些知识,才能在学习和应用深度学习时获得成功。然而,对OpenCV和其他计算机视觉技术的全面回顾超出了本书的范围。
为了快速掌握OpenCV和图像处理的基础知识,我建议你阅读《实用Python》和OpenCV——这本书可以快速阅读,用不了一个周末的时间就能读完。当你完成的时候,你将对图像处理的基本原理有一个很好的理解。
要了解更深入的计算机视觉技术,请务必参考PyImageSearch Gurus课程。不管你在计算机视觉和图像处理方面的背景如何,当你完成本章的时候,你将拥有一个完整的微笑检测解决方案,你可以在自己的应用程序中使用。
22.1 微笑数据集
SMILES数据集由微笑或不笑[51]的人脸图像组成。在该数据集中,共有13,165幅灰度图像,每幅图像的大小为64 × 64像素。
如图22.1所示,该数据集中的图像在脸部周围被严格裁剪,这将使训练过程更容易,因为我们将能够从输入的图像中直接学习“微笑”或“不微笑”模式,就像我们在本书前面的类似章节中所做的那样。
上面:“微笑的”脸的例子。底部:“不笑”的脸的样本。在本章中,我们将训练卷积神经网络在实时视频流中识别微笑和不微笑的面孔。
然而,近裁剪在测试过程中带来了一个问题——因为我们的输入图像不仅包含一张脸,但图像的背景,wefirst需要本地化的脸在图像并提取ROI之前,我们可以通过网络检测。幸运的是,使用传统的计算机视觉方法,如Haar级联,这是一个比听起来容易得多的任务。
我们需要在SMILES数据集中处理的第二个问题是类不平衡。数据集中有13165张图片,其中9475张不是微笑的,而只有3690张属于微笑类。考虑到“不微笑”的图片比“微笑”的图片多2.5倍,我们在设计训练程序时需要格外小心。
我们的网络可能会很自然地选择“不笑”的标签,因为(1)分布不均,(2)它有更多“不笑”的例子。正如我们将在本章后面看到的,我们可以通过在训练期间计算每个职业的“权重”来对抗职业不平衡。
22.2 训练微笑CNN
建立我们的微笑探测器的第一步是在SMILES数据集上训练CNN来区分微笑和不微笑的面孔。为了完成这个任务,让我们创建一个名为train_model.py的新文件。从那里,插入以下代码:
# initialize the list of data and labels
data = []
labels = []
# loop over the input images
for imagePath in sorted(list(paths.list_images(args["dataset"]))):
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = imutils.resize(image, width=28)
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-3]
label = "smiling" if label == "positives" else "not_smiling"
labels.append(label)
在第29行,我们遍历——dataset input目录中的所有图像。对于这些图像,我们:1。从磁盘加载它(第31行)。2. 将其转换为灰度(第32行)。3.调整其大小,使其固定的输入大小为28 × 28像素(第33行)。4. 将图像转换为与Keras兼容的数组及其通道顺序(第34行)。5. 将图像添加到LeNet将要训练的数据列表中。
第39-41行句柄从imagePath中提取类标签并更新标签列表。SMILES数据集将微笑的面孔存储在SMILES/positives/positives7子目录中,而非微笑的面孔存储在SMILES/negatives/negatives7子目录中。
我们可以通过在图像路径分隔符上拆分并获取倒数第三个子目录:posix来提取类标签。事实上,这正是第39行所完成的。
现在我们的数据和标签已经构建好了,我们可以将原始像素强度缩放到[0,1]的范围,然后对标签应用一热编码:
# scale the raw pixel intensities to the range [0, 1]
44 data = np.array(data, dtype="float") / 255.0
45 labels = np.array(labels)
46
47 # convert the labels from integers to vectors
48 le = LabelEncoder().fit(labels)
49 labels = np_utils.to_categorical(le.transform(labels), 2)
我们的下一个代码块通过计算类的权重来处理数据不平衡问题:

第52行计算每个类的示例总数。在这种情况下,classtotal将是一个数组:[9475,3690]分别表示“not smiling”和“smiling”。
然后在第53行缩放这些总数,以获得用于处理类不平衡的classWeight,生成数组:[1,2.56]。这个权重意味着我们的网络将把每个“微笑”的实例视为2.56个“不微笑”的实例,当看到“微笑”的实例时,通过将每个实例的损失放大一个更大的权重,从而帮助解决类失衡问题。
现在我们已经计算了类的权重,我们可以继续将我们的数据划分为训练和测试部分,使用80%的数据用于训练,20%的数据用于测试:
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.20, stratify=labels, random_state=42)
# initialize the model
print("[INFO] compiling model...")
model = LeNet.build(width=28, height=28, depth=1, classes=2)
model.compile(loss="binary_crossentropy", optimizer="adam",
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), class_weight=classWeight, batch_size=64, epochs=15, verbose=1)
我们还将使用binary_crosssentropy而不是categorical_crosssentropy作为损失函数。同样,分类交叉熵只在类的数量超过两个时使用。
到目前为止,我们一直在使用SGD优化器来训练我们的网络。这里我们将使用Adam(第63行)[113]。我将介绍更高级的优化器(包括Adam、RMSprop、Adadelta),以及实践者包中的其他优化器;然而,为了这个例子,只需理解Adam在某些情况下比SGD收敛得更快。
同样,优化器和相关参数通常被认为是在训练网络时需要调优的超参数。当我将这个例子整合在一起时,我发现Adam的表现比SGD要好得多。
68和69列火车LeNet总共15个时代使用我们提供的classWeight来对抗阶级不平衡。
在第6个时代之后,我们的验证损失开始停滞——在第15个时代之后进一步训练将导致过拟合。如果需要,我们可以通过使用更多的训练数据来提高微笑检测器的准确性,方法包括:
- 收集额外的训练数据。
2. 应用数据增强对现有训练集进行随机平移、旋转和移位。
在实践者包中详细介绍了数据增强。
22.3 测试smile CNN

第一个参数——cascade是用于检测图像中的人脸的Haar级联的路径。2001年由Paul Viola和Michael Jones首次发表,详细介绍了Haar级联在他们的工作中,使用简单特征的增强级联快速目标检测[134]。该出版物已成为计算机视觉文献中被引用最多的论文之一。
Haar级联算法能够检测图像中的目标,无论其位置和规模。也许最有趣的(和我们的应用程序相关的)是,检测器可以在现代硬件上实时运行。事实上,维奥拉和琼斯工作背后的动机是创造一个面部探测器。
因为使用传统计算机视觉方法的对象检测的详细回顾超出了这本书的范围,你应该回顾Haar级联,以及用于对象检测的常见的面向梯度直方图+线性SVM框架,参考这篇PyImageSearch博客文章(http://pyimg.co/gq9lu)以及PyImageSearch Gurus[33]中的对象检测模块。
第二个公共行参数——model指定磁盘上序列化的LeNet权重的路径。我们的脚本将默认从内置/USB摄像头读取帧;然而,如果我们想要从文件中读取帧,我们可以通过可选的——video开关来指定文件。
在检测微笑之前,我们首先需要执行一些初始化操作:
# load the face detector cascade and smile detector CNN
detector = cv2.CascadeClassifier(args["cascade"])
# 加载模型
model = load_model(args["model"])
# if a video path was not supplied, grab the reference to the webcam
if not args.get("video", False):
camera = cv2.VideoCapture(0)
# otherwise, load the video
else:
camera = cv2.VideoCapture(args["video"])
第20行和第21行分别加载Haar级联人脸检测器和预训练的LeNet模型。如果没有提供视频路径,则抓取一个指向摄像头的指针(第24和25行)。否则,我们打开一个指向磁盘上视频文件的指针(第28和29行)。
# 持续循环
while True:
# 得到当前帧
(grabbed, frame) = camera.read()
# if we are viewing a video and we did not grab a frame, then we
# have reached the end of the video
if args.get("video") and not grabbed:
break
# resize the frame, convert it to grayscale, and then clone the
# original frame so we can draw on it later in the program
frame = imutils.resize(frame, width=300)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frameClone = frame.copy()
第32行开始一个循环,直到(1)我们停止脚本或(2)我们到达视频文件的结尾(假设应用了——video路径)。
第34行抓取视频流中的下一帧。如果帧不能被抓取,那么我们就到达了视频文件的结尾。否则,我们通过调整帧的宽度为300像素(第43行)并将其转换为灰度(第44行)来对帧进行预处理以进行人脸检测。
.detectMultiScale方法处理检测框架中人脸的边界盒(x, y)坐标:
# detect faces in the input frame, then clone the frame so that
48 # we can draw on it
49 rects = detector.detectMultiScale(gray, scaleFactor=1.1,
50 minNeighbors=5, minSize=(30, 30),
51 flags=cv2.CASCADE_SCALE_IMAGE)
在这里,我们通过我们的灰度图像,并指出,对于一个给定的区域来说,它必须具有30 × 30像素的最小宽度。minNeighbors属性帮助删除错误信息,而scaleFactor控制生成的图像金字塔(http://pyimg.co/rtped)级别的数量。
同样,对用于对象检测的Haar级联的详细回顾超出了本书的范围。要更深入地了解视频流中的人脸检测,请参阅实用Python和OpenCV第15章。
detectmultiscale方法返回一个由4个元组组成的列表,这些元组组成了边框中限定人脸的矩形。这个列表中的前两个值是起始(x, y)坐标。rects列表中的第二个值分别是包围框的宽度和高度。
我们对下面的每一组边界框进行循环:
# loop over the face bounding boxes
54 for (fX, fY, fW, fH) in rects:
55 # extract the ROI of the face from the grayscale image,
56 # resize it to a fixed 28x28 pixels, and then prepare the
57 # ROI for classification via the CNN
58 roi = gray[fY:fY + fH, fX:fX + fW]
59 roi = cv2.resize(roi, (28, 28))
60 roi = roi.astype("float") / 255.0
61 roi = img_to_array(roi)
62 roi = np.expand_dims(roi, axis=0)
对于每个边界框,我们使用NumPy数组切片来提取面部ROI(第58行)。一旦获得ROI,我们就对其进行预处理,并通过LeNet为其分类做准备,方法是调整其大小、缩放其大小、将其转换为与keras兼容的数组,并为图像填充额外的维度(第69-62行)。
对roi进行预处理后,可以通过LeNet进行分类:
# determine the probabilities of both "smiling" and "not
65 # smiling", then set the label accordingly
66 (notSmiling, smiling) = model.predict(roi)[0]
67 label = "Smiling" if smiling > notSmiling else "Not Smiling"
在第66行上调用.predict将分别返回“不微笑”和“微笑”的概率。第67行根据哪个概率更大设置标签。
一旦我们有了标签,我们可以绘制它,以及在框架上相应的边界框:

# 展示图片
cv2.imshow("Face", frameClone)
# 如果q键被按下,停止循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 清除camera并关闭任何打开的窗口
camera.release()
cv2.destroyAllWindows()
//截止到2022.1.20日晚上16:21
22.4 总结
在本章中,我们学习了如何构建一个端到端计算机视觉和深度学习应用程序来执行微笑检测。为此,我们首先在SMILES数据集上训练LeNet架构。
由于SMILES数据集中的类不平衡,我们发现了如何计算用于帮助缓解问题的类权重。
经过训练后,我们在测试集上评估LeNet,发现该网络获得了可观的93%的分类精度。通过收集更多的训练数据或对已有的训练数据进行数据增广,可以获得更高的分类精度。
然后,我们创建了一个Python脚本,从网络摄像头/视频文件中读取帧,检测人脸,然后应用我们预先训练的网络。为了检测人脸,我们使用了OpenCV的Haar级联。一旦检测到人脸,它就会从图像中提取出来,然后通过LeNet来确定这个人是在微笑还是没有微笑。整体而言,我们的微笑检测系统可以轻松地在使用现代硬件的CPU上实时运行。
23.下一步
花一秒钟来祝贺自己;你已经用Python学习了整个计算机视觉深度学习入门包。这是一个很大的成就,是你应得的。
让我们回顾一下你的旅程。在这本书里你已经:•学习了图像分类的基本原理。•配置深度学习环境。•创建你的第一个图像分类器。•学习参数化学习。•学习了所有的基本优化方法(SGD)和正则化技术。•彻底研究了神经网络。•掌握卷积神经网络(CNN)的基本原理。•训练你的第一个CNN。•研究了更先进的架构,包括LeNet和MiniVGGNet。•学习如何发现欠拟合和过拟合。•在ImageNet数据集上应用预训练的cnn分类到你的图像。•构建端到端计算机视觉系统来破解验证码。•创建自己的微笑探测器。
至此,您对机器学习、神经网络和深度学习应用于计算机视觉的基础知识有了非常深入的了解。但是,我感觉你的旅程才刚刚开始…
23.1 下一步
Deep Learning for Computer Vision with Python入门包只是冰山一角。本书旨在帮助您理解卷积神经网络的基本原理,以及提供实际的端到端示例/案例研究,您可以使用这些示例/案例研究来指导您将深度学习应用到自己的应用程序。
但正如深度学习研究人员发现,越深入,网络越准确,我也鼓励你更深入地研究深度学习。
如果想要学到:
•了解更高级的培训技巧。•使用转移学习更快地训练你的人脉。•处理大数据集,大到无法装入内存。•提高您的分类精度与网络集成。•探索更多奇异的架构,如googlet和ResNet。•研究深层梦境和神经类型。•学习生成式对抗网络(GANs)。•培训最先进的架构,如AlexNet, VGGNet, GoogLeNet, ResNet,和SqueezeNet从scratch上具有挑战性的ImageNet数据集…
我希望你能允许我继续在你的深度学习之旅中指导你(并避免我曾经犯过的错误)。如果你还没有选择实践者Bundle或ImageNet Bundle的副本,你可以在这里这样做:
Deep Learning for Computer Vision with Python: Master Deep Learning Using My New Book
如果你有任何问题,请随时联系我:
//StarterBundle结束
//2022.1.20 晚上17:28















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











