







第一范式
字段不可分,保证字段的原子性,字段不能是集合、多个值。
下面第二行是违反第一范式的:
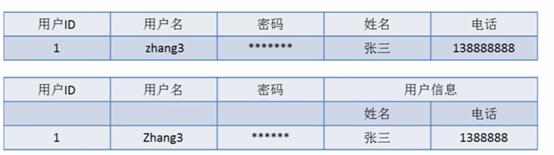
第二范式
有主键,非主键字段依赖主键。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要我们设计一个主键来实现(这里的主键不包含业务逻辑)。
即满足第一范式前提,当存在多个主键的时候,才会发生不符合第二范式的情况。比如有两个主键,不能存在这样的属性,它只依赖于其中一个主键,这就是不符合第二范式。通俗理解是任意一个字段都只依赖表中的同一个字段。(涉及到表的拆分)
第三范式
第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段。
就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键join就用外键join)。很多时候,我们为了满足第三范式往往会把一张表分成多张表。

反范式化
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。
这样可以减少关联查询(join)。
https://www.cnblogs.com/moxiaotao/p/10120672.html
https://blog.csdn.net/drdongshiye/article/details/80738482















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









