







redis支持的数据类型:
-
String
redis 127.0.0.1:6379> SET zzd "张**" OK redis 127.0.0.1:6379> GET zzd "张**"一个键最大能存储5
-
hash
-
list
-
set
-
zset
-
BitMap
-
HyperLogLog
-
Geospatial
缓存概念知识
什么是缓存
日常生活中经常会听到缓存这个词,那到底什么是缓存呢?其实缓存就是数据交换的缓冲区(称作Cache),是临时存储数据(使用频繁的数据)的地方。当用户查询数据,首先在缓存中寻找,如果找到了则直接执行;如果找不到则去数据库中查询。
缓存的本质就是用空间换时间,牺牲数据的实时性,以服务器内存中的数据暂时代替从数据库读取最新的数据,减少数据库IO,减轻服务器压力,减少网络延迟,加快页面打开速度。
缓存的优缺点
优点:
- 加快了响应速度
- 减少了对数据库的读操作,数据库的压力降低
缺点:
- 内存容量相对硬盘小
- 缓存中的数据可能与数据库中数据不一致
- 内存断电就会清空数据,造成数据丢失
为什么使用缓存
一般在远端服务器上,考虑到客户端请求量多,某些数据请求量大,这些热点数据要频繁的从数据库中读取,给数据库造成压力,导致响应客户端较慢。所以,在一些不考虑实时性的数据中,经常将这些数据存在内存中,当请求时候,能够直接读取内存中的数据及时响应。
缓存主要解决高性能与高并发与减少数据库压力。缓存本质就是将数据存储在内存中,当数据没有发生本质变化的时候,应尽量避免直接连接数据库进行查询,因为并发高时很可能会将数据库压垮,先去缓存中读取数据,缓存中未查找到的数据再去数据库中查询,这样就大大降低了数据的读写次数,增加系统的性能和提高并发量
Redis概念知识
Redis简介
Redis是一个高性能的key-value开源数据库,是一个非关系型的数据库,是为了解决高并发、高扩展,大数据存储等一系列的问题而产生的数据库解决方案。但它不能替代关系型数据库,只能作为特定环境下的扩充。
为什么用Redis作为缓存
- 支持高可用:Redis支持master/slave 主从、sentinal哨兵模式、cluster集群模式,大大保证了Redis运行的稳定和高可用性
- 支持多种数据结构:Redis不仅支持简单的key/value类型的数据,同时还提供list、set、zset、hash、geospatital、hyperloglog、bitmap数据结构的存储
- 支持数据持久化:可以将内存中的数据持久化在磁盘中,当宕机或者故障重启时,可以再次加载,不会减少数据的丢失
- 生态完善:Redis已成为业界内缓存的首选目标,索引很多语言和工具对其支持
Redis支持的数据类型
- 字符串(String)【字符串是二进制安全的,这意味着他们有一个已知的长度没有任何特殊字符终止,所以你可以存储任何东西,512 M为上限,Value可以是字符串,也可以是数字】
- 哈希表(hash)
- 列表(list)
- 集合(set)
- 有序集合(zset)
- 地理位置(Geospatial)
- 基数统计(Hyperloglog)
- 位图场景(Bitmap)
redis的特性决定了它的功能,它可以用来做以下事情:
1.排行榜,利用zset可以方便的实现排序功能
2.计数器,利用redis中原子性的自增操作,可以统计阅读量,点赞量等功能
3.简单消息队列,list存储结构,满足先进先出的原则,可以使用lpush/rpop或rpush/lpop实现简单消息队列
4.session共享,分布式系统中,可以利用redis实现session共享
Redis持久化方式
redis 提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB,简而言之,就是在不同的时间点,将 redis 存储的数据生成快照并存储到磁盘等介质上;
AOF,则是换了一个角度来实现持久化,那就是将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实 RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭 RDB 和 AOF 方式,这样的话,redis 将变成一个纯内存数据库,就像 memcache 一样。
Redis缓存常见问题
缓存穿透
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qBPdJ45Q-1657430284329)(Java基础面试.assets/1620-16560394788852.png)]
**缓存穿透:**值查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库查询,造成缓存穿透。
解决方案:
- 缓存空置:在从DB查询对象为空时,也要将空值存入缓存,具体的值需要使用特殊的标识,能和真正缓存的数据取反开,另外将其过期时间设为较短时间
- 使用布隆过滤器,布隆过滤器能判断一个key一定不存在(不保证一定存在,因为布隆过滤器结构原因,不能删除,但是旧值可能被新值替换,而将旧值删除后它可能依旧判断其可能存在),在缓存的基础上,构建布隆过滤器数据结构,在布隆过滤器中存储对应的key,如果不存在,则说明key对应的值为空
- 在接口访问层对用户做校验,如接口传参、登陆状态、n秒内访问接口的次数【如:验证码等】
布隆过滤器结构图:
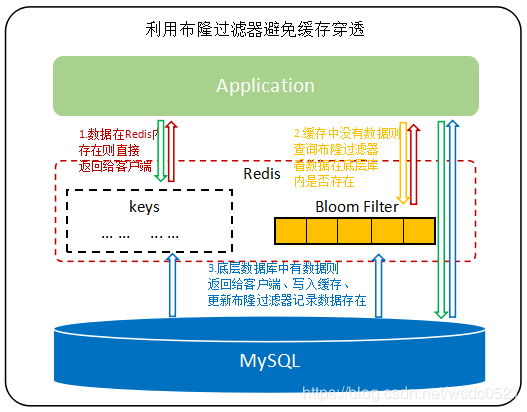
布隆过滤器的实现:
- 使用redis实现:
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import com.google.common.hash.Hashing;
import java.nio.charset.Charset;
/**
* 布隆过滤器核心类
*
* @param <T>
* @author
*/
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(int expectedInsertions) {
this.funnel = (Funnel<T>) Funnels.stringFunnel(Charset.defaultCharset());
bitSize = optimalNumOfBits(expectedInsertions, 0.03);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* redis操作布隆过滤器
*
* @param <T>
* @author xhj
*/
@Component
public class RedisBloomFilter<T> {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 删除缓存的KEY
*
* @param key KEY
*/
public void delete(String key) {
redisTemplate.delete(key);
}
/**
* 根据给定的布隆过滤器添加值,在添加一个元素的时候使用,批量添加的性能差
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param <T> 泛型,可以传入任何类型的value
*/
public <T> void add(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器添加值,在添加一批元素的时候使用,批量添加的性能好,使用pipeline方式(如果是集群下,请使用优化后RedisPipeline的操作)
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param valueList 值,列表
*/
public void addList(BloomFilterHelper<CharSequence> bloomFilterHelper, String key, List<String> valueList) {
redisTemplate.executePipelined(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (String value : valueList) {
//通过value来将对应的节点赋值为1,因此处的Bit最大值为2^64,所以会非常的准确
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
connection.setBit(key.getBytes(), i, true);
}
}
return null;
}
});
}
/**
* 根据给定的布隆过滤器判断值是否存在
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param <T> 泛型,可以传入任何类型的value
* @return 是否存在
*/
public <T> boolean contains(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
//使用相同的方法获取对应的节点
int[] offset = bloomFilterHelper.murmurHashOffset(value);
//遍历获取每一个节点是否有值,无值则不存在此对象,如果全部都匹配则存在此对象
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
import com.example.zzd.bloom.BloomFilterHelper;
import com.example.zzd.bloom.RedisBloomFilter;
import com.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@SpringBootTest
class RedisBloomFilterTests {
@Autowired
private RedisBloomFilter<?> redisBloomFilter;
@Test
public void testRedisBloomFilter() {
int expectedInsertions = 100000;
double fpp = 0.1;
redisBloomFilter.delete("bloom");
BloomFilterHelper<CharSequence> bloomFilterHelper = new BloomFilterHelper<>(Funnels.stringFunnel(Charset.defaultCharset()), expectedInsertions, fpp);
int j = 0;
// 添加1000个元素
List<String> valueList = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
valueList.add(i + "");
}
long beginTime = System.currentTimeMillis();
redisBloomFilter.addList(bloomFilterHelper, "bloom", valueList);
long costMs = System.currentTimeMillis() - beginTime;
log.info("-----------------------------------------------------------------");
log.info("布隆过滤器添加{}个值,耗时:{}ms", 100, costMs);
for (int i = 0; i < 10000; i++) {
boolean result = redisBloomFilter.contains(bloomFilterHelper, "bloom", i + "");
if (!result) {
j++;
}
}
log.info("漏掉了{}个,验证结果耗时:{}ms", j, System.currentTimeMillis() - beginTime);
}
}
- 使用google的guava实现:【测试后发现redis布隆过滤器相较于redis布隆过滤器要错误率稍高一些】
@Test
void testGuavaBloomFilter() {
/**
* 插入的数据量
*/
int insertions = 100000;
/**
* 误差率
*/
double fpp = 0.02;
//初始化一个存储string数据的布隆过滤器,默认误判率0.03
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions, fpp);
//用于存放所有实际存在的key,用于是否存储
HashSet<Object> set = new HashSet<>(insertions);
//用于存放所有实际存在的key,用于取出
ArrayList<String> list = new ArrayList<>(insertions);
//随机字符串
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bloomFilter.put(uuid);
set.add(uuid);
list.add(uuid);
}
int rightNum = 0;
int wrongNum = 0;
for (int i = 0; i < 10000; i++) {
//0-10000之间,可以被100整除的数有100个
String data = i % 100 == 0 ? list.get(i / 100) : UUID.randomUUID().toString();
if (bloomFilter.mightContain(data)) {
if (set.contains(data)) {
rightNum++;
continue;
}
wrongNum++;
}
}
System.out.println(rightNum);
System.out.println(wrongNum);
BigDecimal percent = new BigDecimal(wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
BigDecimal bingo = new BigDecimal(9900 - wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
System.out.println("在10W个元素中,判断100个实际存在的元素,布隆过滤器认为存在的:" + rightNum);
System.out.println("在10W个元素中,判断9900个实际不存在的元素,误认为存在的:" + wrongNum + ",命中率:" + bingo + ",误判率:" + percent);
}
缓存击穿
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WilK8AAi-1657430284331)(Java基础面试.assets/1620-16560396351994.png)]
**缓存击穿:**缓存击穿和缓存穿透从名词上很难区分,它们的区别是:穿透表示底层数据库没有数据且缓存中也没有数据,击穿表示底层数据库有数据而缓存内没有数据。当热点数据key从缓存内失效,大量访问同时请求这个数据,就会将查询下沉到数据库,此时数据库层负载压力会邹增,这种现象为“缓存击穿”
解决方案:
-
延长热点key的过期时间或者设置永不过期,如排行榜,首页异地会有一个高并发的接口
-
统计某段时间比如一天内 数据的出现次数,把数据出现的次数进行排序,当达到某个条件比如出现次数达到一万或者更多的时候就将数据的过期时间进行重新设置过期时间(记录数据的情况次数,可以通过日志或使用redis记录,当达到某个阈值的时候直接设置最近一个比较长的时间点不过期,每日进行统计)
-
利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的这个数据,一旦查到数据就缓存到redis中,避免其他大量请求同时穿过redis访问底层数据库
【在使用互斥锁的时候需要避免出现死锁或者锁过期的情况:
- 使用事务将获取锁和设置过期时间作为一个原子操作,以避免出现某个客户端获取锁之后宕机导致的锁不被释放造成死锁现象
- 另起一个线程监控获取锁的线程的状态,快到锁过期时间还每查询结束则延长锁的过期时间,避免多次查询多次锁过期造成计算资源的浪费】
缓存雪崩
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GHhRKKb7-1657430284331)(Java基础面试.assets/1620-16560428661256.png)]
**缓存雪崩:**当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大的压力,造成数据库后端故障,从而引起应用服务器雪崩
解决方案:
- 在可接受的时间范围内随机设置key的过期时间,分散key的过期时间,以防止大量的key在同一时刻过期;
- 对于一定要在国定时间让key失效的场景(例如每日12点准时梗死你所有最新排名),可以在固定的失效时间时在接口服务器端设置随机延时,将请求时间打散,让一部分查询先将数据缓存起来
- 延长热点key的过期时间或者设置永不过期,这一点和缓存击穿中的方案一样
- 设置主从复用等高可用情况
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WKrQ3GYf-1657430284331)(Java基础面试.assets/1620-16560432068468.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X8OtaBs6-1657430284332)(Java基础面试.assets/1620-165604324940810.png)]
缓存预热
缓存预热如字面意思,当系统上线时,缓存内还么有数据,如果直接提供给用户使用,每个请求都会穿透过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前将数据库内的热点数据缓存到Redis内,再提供出去使用,这种操作就是“缓存预热”。
缓存预热的实现方式有很多,比如通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内
缓存更新
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据的不一致问题。如何解决并发场景下更新操作的双鞋一致是缓存系统的一个重要知识点。
第二步操作异常:缓存和数据的操作顺序中,第二个动作报错。如数据库被更新此时失效缓存的时候出错,缓存内数据仍是旧版本
缓存更新的设计模式有四种:
- Cache aside:查询–先查缓存,缓存没有就查数据库,然后加载到缓存内;更新–先更新数据库,然后让缓存失效;或者先失效缓存然后更新数据库
- Read through:在查询操作中更新缓存,即当缓存失效时,Cache Aside模式是由调用方负责把数据加载入缓存,而Read Though则用缓存服务自己来加载
- Write through:在更新数据时发生。当有数据更新的时候,如果没有命中缓存,则直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库
- Write behind caching:俗称write back,在更新数据的时候,只更新缓存,不更新数据库,缓存会异步地定时批量更新数据库
Cache aside:
- 为了避免在并发的场景下,多个请求同时更新同一个缓存导致脏数据,因此不能直接更新缓存而是令缓存失效。
- 先更新数据库后失效缓存:并发场景下,推荐使用延迟失效(写请求完成后给缓存设置1秒过期时间),在读请求缓存数据时若redis内已有该数据(其他写请求还未结束)则不更新。当redis内没有该数据的时候(其他写请求已令该缓存失效),读请求才会更新redis内的数据。这里的读请求缓存数据可以加上失效时间,以防第二步操作异常导致的不一致情况。
- 先失效缓存后更新数据库:并发场景下,推荐使用延迟失效(写请求开始前给缓存设置1s过期时间),在写请求时设置缓存失效时间延时1s,然后再去更新数据库中的数据,此时其他读请求仍然可以读到缓存内的数据,当数据库端更新完成后,缓存内的数据已失效,之后的读请求会将数据库端最新的数据加载到缓存内保证缓存和数据库端数据一致性;在这种方案下,第二步操作异常不会引起数据不一致,例如设置了缓存1s失效,然后再更新数据库时报错,即使缓存失效,之后的读请求仍然把更新前的数据重新加载到缓存内。
推荐使用先失效缓存,后更新数据库,配合延迟失效来更新缓存的模式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0d5ZVfJT-1657430284332)(Java基础面试.assets/1620-165605715271714.png)]
- 1.client_1写请求key_A,设置key_A缓存在1s后失效
- 2.写请求更新数据库中的数据
- 3.client_2和clinet_3读key_A数据(读取到缓存内的旧数据)
- 4.若写请求更新数据库成功则在缓存失效时,之后的读请求才会将最新数据加载到redis中,此时两端数据一致
- 5.若写请求更新数据库失败,则缓存失效时,之后的读请求将原来的旧数据加载到redis内,此时两端数据一致
四种缓存更新模式的优缺点:
- Cache aside:实现起来较简单,但需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Reposity)
- Read/Write Through:只需要维护一个数据存储(缓存),但是实现起来要复杂一些
- Write Behind Caching:与Read/Write Through类似,区别是Write Behind Caching的数据持久化是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。优点是直接操作内存速度快,多次操作可以合并持久化到数据库。确定是数据可能会丢失,例如系统断电等
缓存本身就是通过牺牲强一致性来提高性能,因此使用缓存提升性能,就会有数据更新的延迟性。这就需要我们在评估需求和设计阶段根据实际场景去做权衡了。
缓存降级
缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍需保证主服务可用。可用将其他次要服务的数据进行缓存降级,从而提升主服务的稳定性。
降级的目的是保证核心服务可用,即使是有损的。如双十一的时候淘宝购物车无法修改地址之恩给你使用默认地址,这个服务就是被降级了,这里阿里保证了订单可用正常提交和付款,但修改地址的服务可以在服务器压力降低,并发量相对减少的时候在恢复。
降级可以根据实时的监控数据进行字段降级也可以配置开关人工降级。是否需要降级,哪些服务需要降级,在什么情况下降级,取决于大家对于系统功能的取舍。
【如有侵权,请联系我,删除】















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









