






拆分顺序表
将一个长度为10的线性单链表:0123456789中的偶数取出,放到另一个单链表中,要求保持原来顺序。
#include<iostream>
#include<malloc.h>
#define OVERFLOW -1
using namespace std;
typedef int ElemType;
typedef struct LNode{
ElemType elem;
struct LNode *next;
}LNode,*LinkList;
//定义链表
int InitList(LinkList &L){
L=(LinkList)malloc(sizeof(LNode));
if(!L)
exit(OVERFLOW);
L->next=NULL;
return 1;
}
//尾插法创建链表
int CreatList(LinkList &L){
LinkList p=L;//p指向线性表L
LinkList q;//定义q
for(int i=0;i<=9;i++){
q=(LinkList)malloc(sizeof(LNode));//q为线性表的一个节点
q->elem=i;//q的值为i
q->next=NULL;//q的下一个节点赋为空
p->next=q;//p的下一个节点指向q
p=q;//将q节点赋给p
q=p->next;//将p的下一个节点赋给q,即NULL(现在的p即上面的q节点)
}
return 1;
}
//分解链表
int ApartList(LinkList &L,LinkList &M){
LinkList p=L;//p指向链表L
LinkList q=L->next;//q指向L的下一个节点防止链表丢失
LinkList m=M;//m指向链表M
while(q){//q不为空,循环
if(q->elem%2==0){//如果q的值模2等于0
p->next=q->next;//将q节点删除
p=q->next;//p指针后移一位
m->next=q;//尾插法将q节点插入到M链表中
q->next=NULL;//清空q的下一个节点
m=q;//m节点后移一位
}
q=p->next;
}
return 1;
}
//遍历链表并输出
void VisitList(LinkList L){
LinkList p=L->next;
while(p){
cout<<p->elem<<",";
p=p->next;
}
cout<<endl;
}
int main(){
LinkList L,M;//定义L,M结构体
InitList(L);//定义链表L
CreatList(L);//创建链表L
cout<<"list:";
VisitList(L);//遍历并输出L
InitList(M);//定义链表M
ApartList(L,M);//拆分链表L为L,M
cout<<"L:";
VisitList(L);//遍历链表L
cout<<"M:";
VisitList(M);//遍历链表M
}
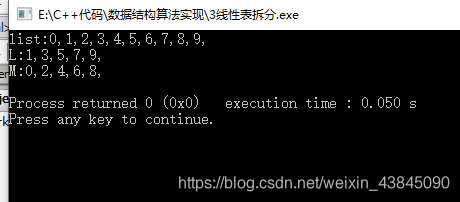
运行结果














 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









