




 本文详细介绍了MongoDB的三种高可用架构(Master-Slave、ReplicaSet和Sharding),讨论了它们的工作原理、优缺点以及如何保证数据的可靠性和一致性。重点讲解了Sharding分片模式,包括HashedSharding和RangeSharding策略。
本文详细介绍了MongoDB的三种高可用架构(Master-Slave、ReplicaSet和Sharding),讨论了它们的工作原理、优缺点以及如何保证数据的可靠性和一致性。重点讲解了Sharding分片模式,包括HashedSharding和RangeSharding策略。
MongoDB高可用架构涉及常用功能整理
MongoDB是一个开源的文档数据库,适用于构建各种类型的应用程序和用例。它是一种NoSQL数据库,意味着它不依赖关系模型,并且不使用SQL查询语言进行数据操作。
MongoDB的特点包括:
- 面向文档的数据模型:MongoDB存储的是以JSON风格的文档,可以包含各种类型的数据。文档的结构可以灵活地变化,便于处理复杂的数据。
- 高性能:MongoDB使用了一种称为BSON的二进制数据格式,以及一种称为聚集集合的存储引擎,以提供高性能的数据存储和查询操作。
- 可扩展性:MongoDB可以通过水平扩展集群来处理大规模的数据和高负载的请求。它支持自动分片和数据复制,以提供高可用性和可伸缩性。
- 强大的查询能力:MongoDB支持丰富的查询语法和索引功能,包括范围查询、全文搜索、地理位置查询等。
- 多种语言支持:MongoDB提供了多种编程语言的驱动程序,可以方便地与各种编程语言进行集成和开发。
本文主要探讨mongodb常见的高可用架构,以及mongo常用的功能,便于梳理知识点和技术细节。
1. mongo架构和相关组件
mongo在目前有3种模式高可用架构,不同类型的高可用架构在高可用以及集群容量上表现有差异
- Master-Slave主从模式
- Replica Set 副本集模式
- Sharding 分片模式
1.1. Master-Slave主从模式
Mongodb 提供的第一种冗余策略就是 Master-Slave 策略,这个也是分布式系统最开始的冗余策略,这种是一种热备策略。
Master-Slave 架构一般用于备份或者做读写分离,一般是一主一从设计和一主多从设计。
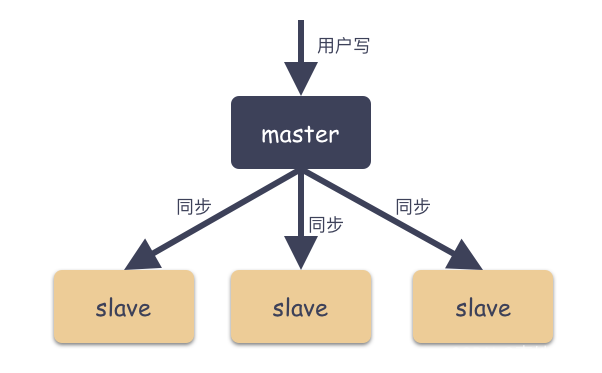
由两种角色构成:
-
主(Master)
可读可写,当数据有修改的时候,会将 Oplog 同步到所有连接的Salve 上去。master节点完成数据写入后,就会返回可客户端,并异步同步到slave节点。 由于从节点无法保证事务性,因此常见的问题,就是主从数据不一致和主从延迟问题。 -
从(Slave)
只读,所有的 Slave 从 Master 同步数据,从节点与从节点之间不感知。
主从架构有一个不可逾越的问题:数据不一致问题。根本原因在于只有 Master 节点可以写,Slave 节点只能同步 Master 数据并对外提供读服务,所以你会发现这个是一个异步的过程。
虽然最终数据会被 Slave 同步到,在数据完全一致之前,数据是不一致的,这个时候去 Slave 节点读就会读到旧的数据。所以,总结来说:读写分离的结构只适合特定场景,对于必须需要数据强一致的场景是不合适这种读写分离的。
当 Master 节点出现故障的时候,Slave节点不能自动切换为Master节点,需要通过人为 Check 和操作,手动把 Slave
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









