







1.MQ是什么?
MQ是message queue,消息队列,也叫消息中间件,遵守JMS(java message service)规范的一种软件
是类似于数据库一样需要独立部署在服务器上的一种应用,提供接口给其他系统调用。
MQ是一种跨进程的通信机制,用于上下游传递消息。
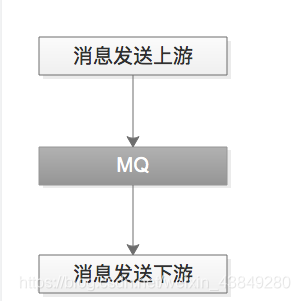
MQ是一种常见的上下游“逻辑解耦+物理解耦”的消息通信服务。
使用了MQ之后,消息发送上游只需要依赖MQ,逻辑上和物理上都不用以来其他服务。
2.说说在你的项目中是怎么使用MQ的?
3.为什么使用MQ?
3.1什么时候不适用MQ?
技术选型
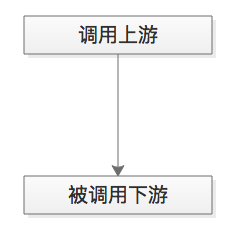
MQ是解耦利器,那为什么不都使用MQ?这是一个误区,调用与被调用的关系,是无法被MQ取代的。
MQ的不足是:
- 系统更复杂,多了一个MQ组件
- 消息传递路径更长,延时会增加
- 消息可靠性和重复性护卫矛盾,消息不丢不重难以同时保证
- 上游无法知道下游的执行结果,致命点
**例子:**用户登录场景,登录页面调用passport服务,passport服务的执行结果直接影响登录结果,此处的“登录页面”与“passport服务”就必须使用调用关系,而不能使用MQ通信
结论:调用方法时依赖执行结果的业务场景,使用调用,而不是MQ。
3.2什么时候使用MQ
典型场景一:数据驱动的任务依赖
设么是任务依赖,举个例子,互联网公司经常在凌晨进行一些数据统计任务,这些任务之间有一定的依赖关系,比如:
1)task3需要使用task2的输出作为输入
2)task2需要使用task1的输出作为输入
这样的haul,tast1,task2,task3之间就有任务依赖关系,必须先执行task1,再执行task2,再执行task3.
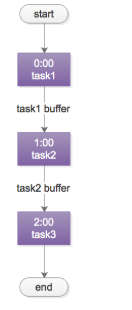
对于这类需求,常见的实现方式是,使用cron人工排执行时间表:
1)task1,0:00执行,经验执行时间为50分钟
2)task2,1:00执行(为task1预留10分钟buffer),经验执行时间也是50分钟
3)task3,2:00执行(为task2预留10分钟buffer)
这种方法的坏处是:
1)如果有一个任务执行时间超过了预留buffer的时间,将会得到错误的结果,因为后置任务不清楚前置任务是否执行成功,此时要手动重跑任务,还有可能要调整排班表
2)总任务的执行时间很长,总是要预留很多buffer,如果前置任务提前完成,后置任务不会提前开始
3)如果一个任务被多个任务依赖,这个任务将会成为关键路径,排班表很难体现依赖关系,容易出错
4)如果有一个任务的执行时间要调整,将会有多个任务执行时间要调整
无论如何,采用“cron排班表”的方法,各任务耦合,
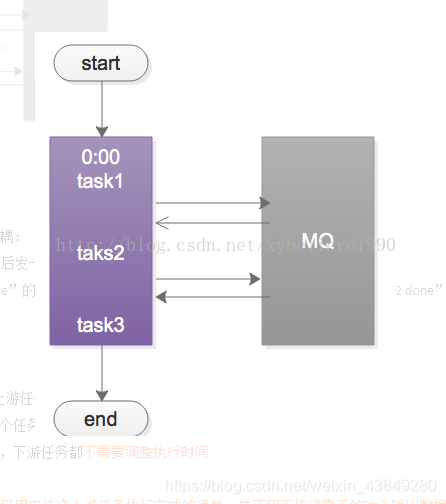
优化方案,采用MQ解耦:
1)task1准时开始,结束后发出一个“task1 done”的消息
2)task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息
3)task3同理
采用MQ的优点:
1)不需要预留buffer,上游任务执行完,下游任务总会第一时间被执行
2)依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
3)有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是:MQ只是用来传递上游任务执行完成消息,并不用于传递真正的输入输出数据。
典型场景二:上游不关心执行结果
上游需要关注执行结果要用“调用”,上游不关心执行结果时,就可以使用MQ了
举个自理,58同城的很多下游需要关注“用户发布帖子”这个事件,比如招聘用户发布帖子后,招聘业务要奖励58豆,房产用户发布帖子后,房产业务要送2个指定,二手用户发布帖子后,二手业务要修改用户统计数据。
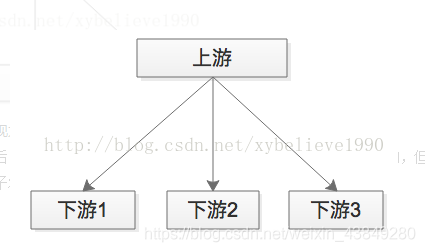
这种方法的坏处是:
1)帖子发布流程的执行时间增加了
2)下游服务宕机,可能导致帖子发布服务器影响,上下游逻辑+物理依赖严重
3)每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务,这一点是最恶心的,属于架构设计中典型的依赖倒转。
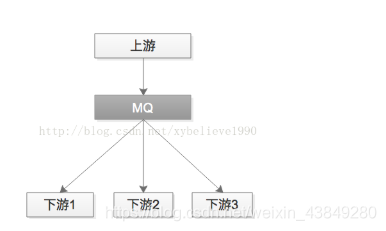
优化方案是,采用MQ解耦:
1)帖子发布成功后,向MQ发一个消息
2)哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
采用MQ的优点是:
1)上游执行时间段
2)上下游逻辑+物理解耦,除了与MQ有物理连接,模块之间都不相互依赖
3)新增一个下游消息关注方,上游不需要修改代码
典型场景三:上游关注执行结果,但执行时间很长
有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦
举个例子,微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么办?
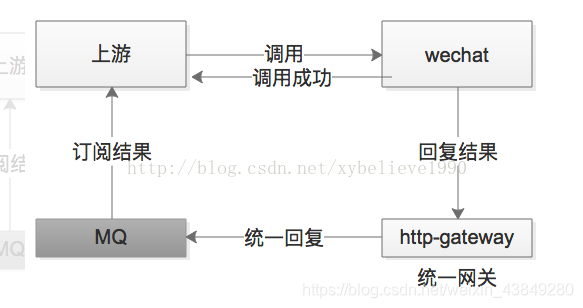
一般采用“回调网关+ MQ”方案解耦:
1)调用方直接跨公网调用微信接口
2)微信返回调用成功,此时并不代表返回成功
3)微信执行完成后,回调统一网关
4)网关将返回结果通知MQ
5)请求方收到结果通知
需要注意,不应该由回调网关来调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+MQ的方案,新增任何对微信支付的调用,都不需要修改代码。
3.3不用MQ的系统耦合场景
自己听的一个例子:耦合问题
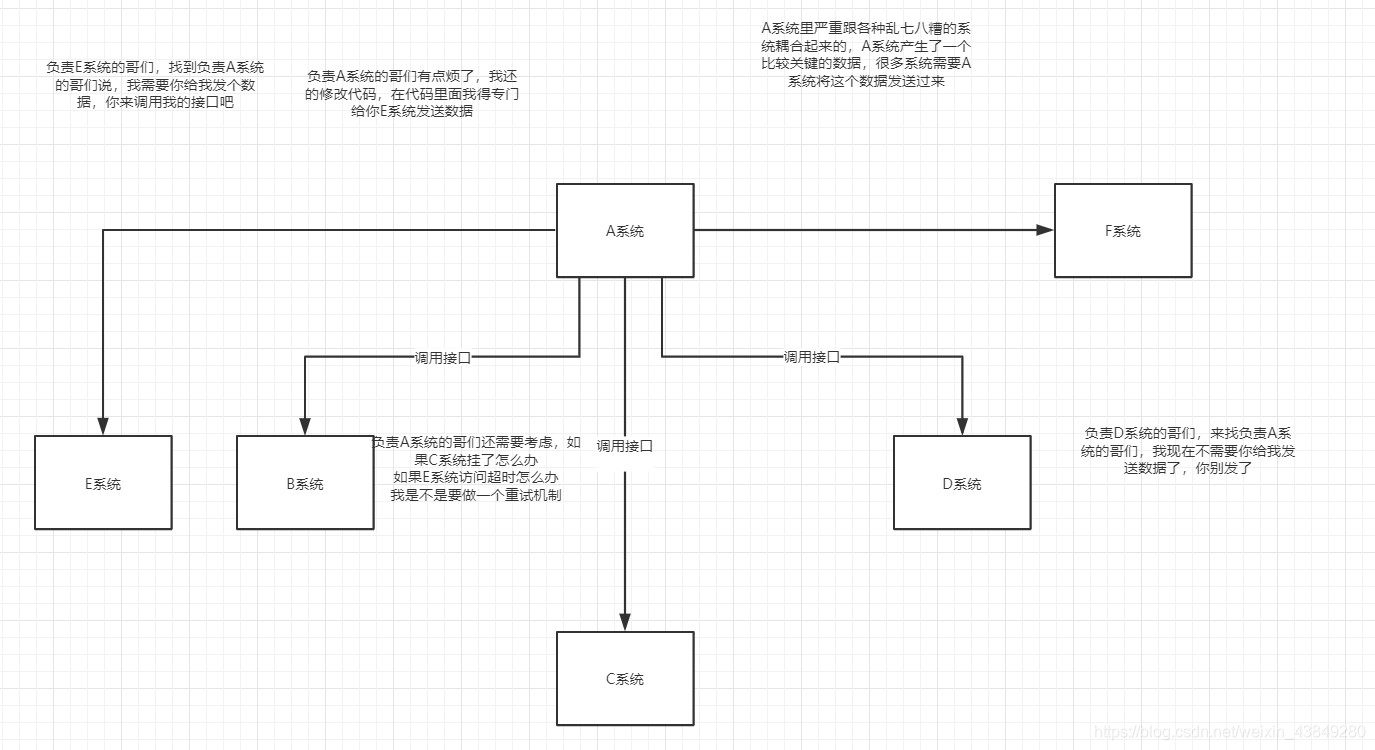
3.4使用MQ之后的解耦场景
解决耦合问题
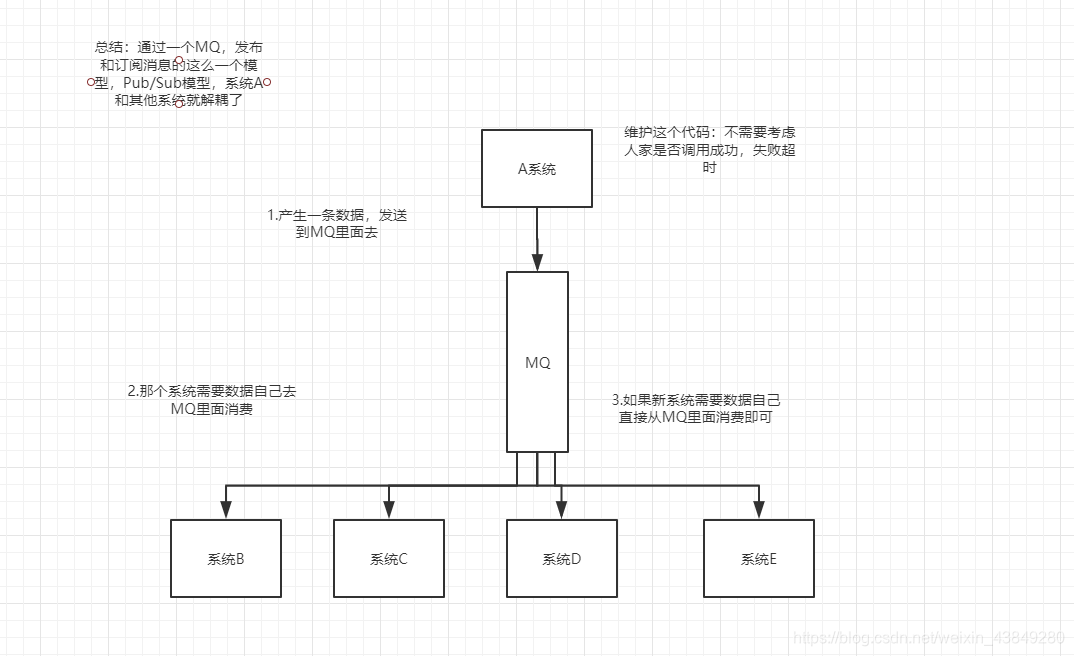
面试技巧:你需要去考虑一下你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用MQ给他异步化解耦,也是可以的,你就需要去考虑在你的项目里,是不是可以运用这个MQ去进行系统的解耦。在简历中体现出来这块东西,用MQ作解耦。
3.5不用MQ的同步高延时请求场景
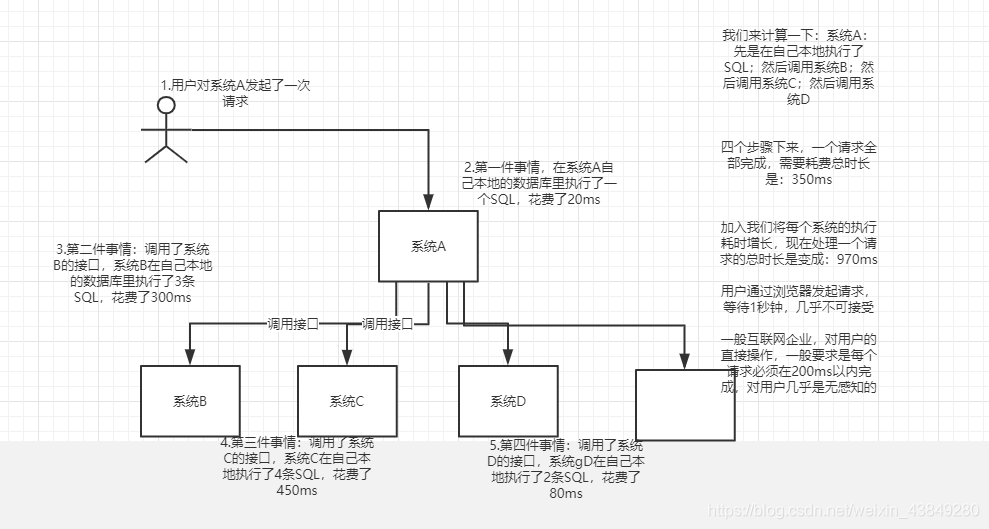
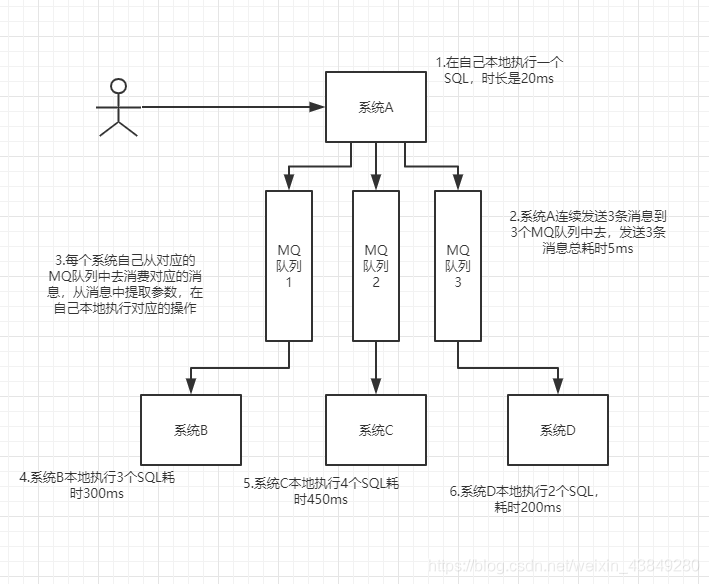
3.6使用MQ进行异步化之后的接口性能优化
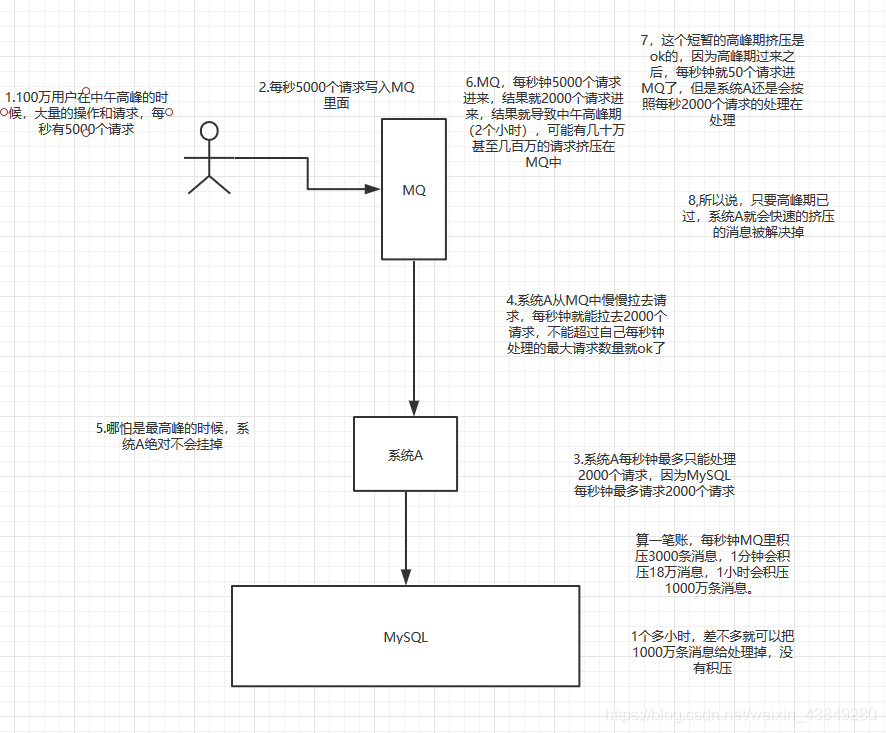
3.7没有用MQ的时候高峰期系统被打死的场景
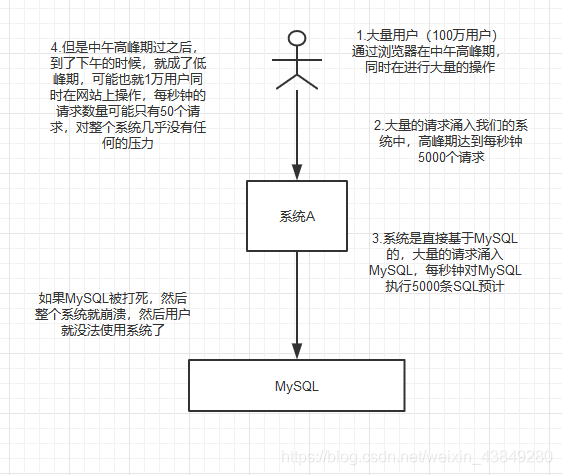
3.8使用MQ来进行削峰场景
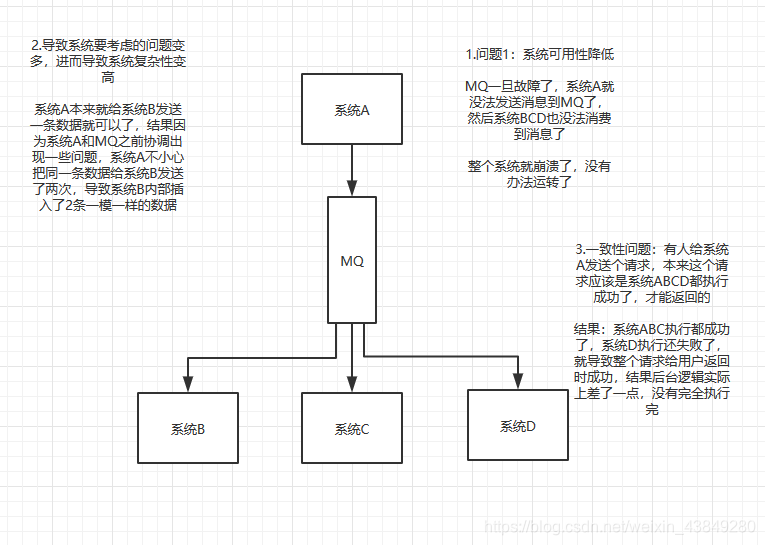
3.9架构中引入MQ可能会引发的问题(缺点:)
4.MQ都有什么优点和缺点?
5.kafka、activemq、rabbitmq、rocketmq有什么区别?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
|---|---|---|---|---|
| 单击吞吐量 | 万级,比RocketMQ和Kafka要低一个数量级 | 万级,比RocketMQ和Kafka要低一个数量级 | 10万级 | 10万级别,一般配合大数据类的系统来进行实时数据计算,日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降 | topic从几十个到几百个的时候,吞吐量会大幅度下降,所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | ||
| 时效性 | ms | 微妙级,延时是最低的 | ms级 | 延迟在ms级以内 |
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 通过参数优化配置,可以做到0丢失 | 通过参数优化配置,可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发性能很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣 | 非常成熟,业内使用多,偶尔会有丢失消息,并且社区维护少,较少在大规模吞吐的场景中用 | erlang语言开发,性能好,延时低,吞吐量到万级,MQ功能完善,管理界面友好,社区活跃,问题是吞吐量低一些,erlang源码维护定制难度高 | 接口简单易用,大规模吞吐,性能好,分布式扩展方便,java源码可控,不足,阿里出台的技术万一被抛弃会有后面的风险 | 超高的吞吐量,ms级别的延时,不足:消息重复消费,对数据准确性有影响,大数据领域以及日志采集的标准 |
6.如何保证消息队列的高可用?
6.1怎么开启这个镜像集群模式呢?
其实很简单rabbitmq有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点的,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
7.如何保证消息不被重复消费?如何保证消费的时候是幂等?
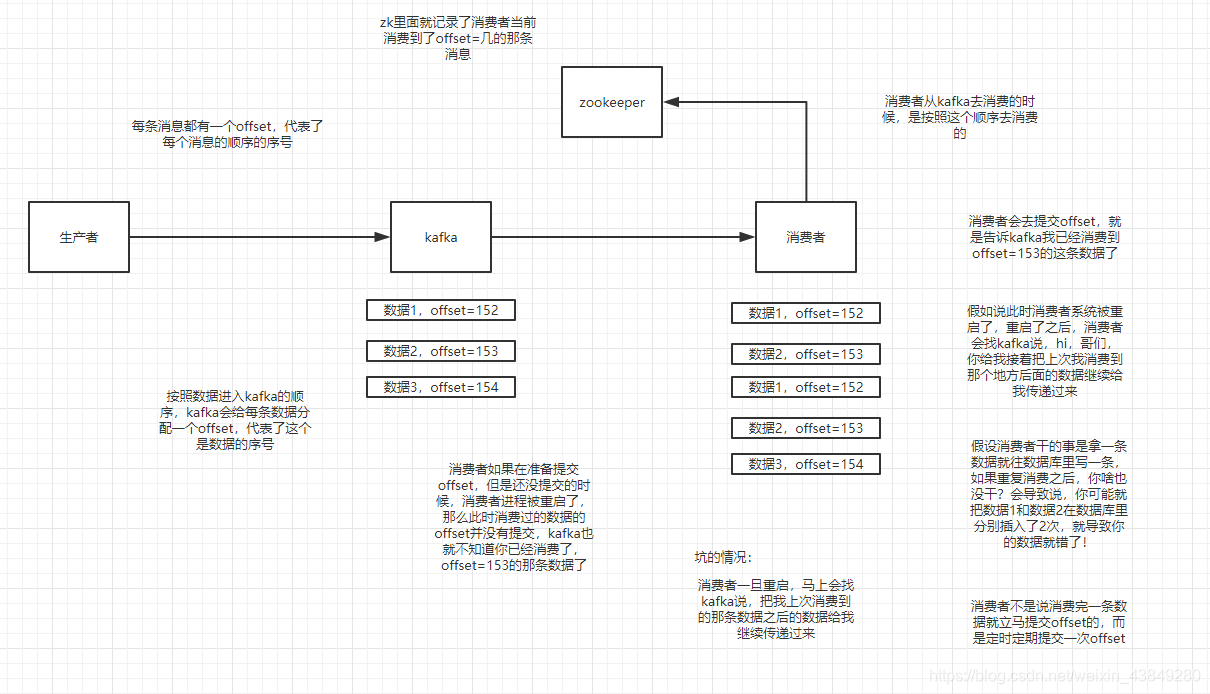
kafka消费端可能出现的重复消费问题:
幂等性,通俗一点说:就是一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
问题:怎么保证幂等性?
其实还是得结合业务来思考,我这里给几个思路:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性
(3)比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
还有比如基于数据库的唯一键来保证重复数据不会重复插入多条,我们之前线上系统就有这个问题,就是拿到数据的时候,每次重启可能会有重复,因为kafka消费者还没来得及提交offset,重复数据拿到了以后我们插入的时候,因为有唯一键约束了,所以重复数据只会插入报错,不会导致数据库中出现脏数据
如何保证MQ的消费是幂等性的,需要结合具体的业务来看
8.如何保证消息的可靠性传输?消息丢失怎么办?
如果说你这个是用mq来传递非常核心的消息,比如说计费,扣费的一些消息,因为我以前设计和研发过一个公司非常核心的广告平台,计费系统,计费系统是很重的一个业务,操作是很耗时的。所以说广告系统整体的架构里面,实际上是将计费做成异步化的,然后中间就是加了一个MQ。
我们当时为了确保说这个MQ传递过程中绝对不会把计费消息给弄丢,花了很多的精力。广告主投放了一个广告,明明说好了,用户点击一次扣费1块钱。结果要是用户动不动点击了一次,扣费的时候搞的消息丢了,我们公司就会不断的少几块钱,几块钱,积少成多,这个就对公司是一个很大的损失。
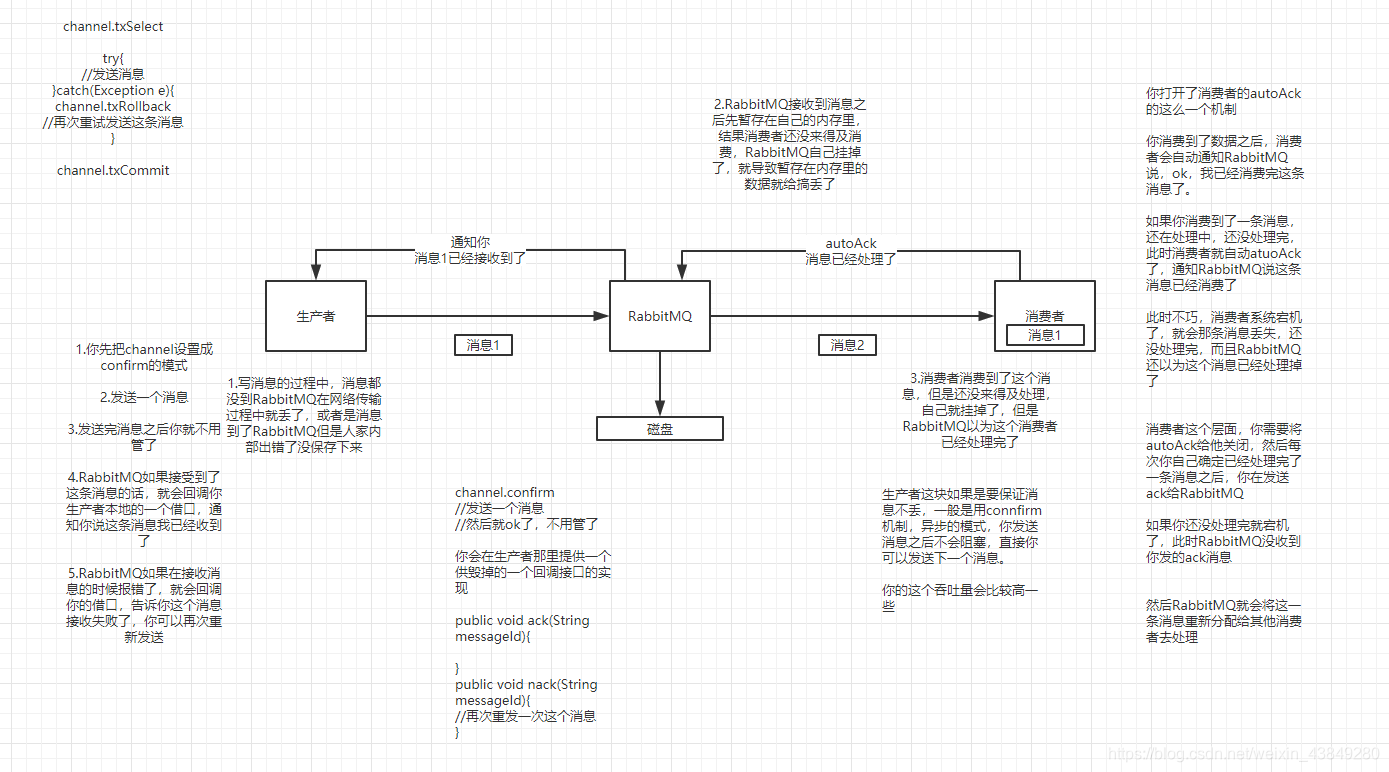
RabbitMQ可能存在的数据丢失问题

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









