







1.安装软件
1.在本机 Windows 安装 Anaconda。
安装 PyCharm professional。
2.再虚拟机搭建spark
2.配置pycharm
1.新建项目

2.开菜单"Tools -> Deployment -> Configuration…”

3.新建一个通过 SFTP 把本地文件远程发布到虚拟机的设置。
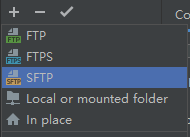
4.输入虚拟机的地址,用户名,密码
5.测试连接成功后,保存并退出。

6.打开菜单"File -> Settings”

7.新增一个 Interpreter(Python解析器),这里我们需要设置虚拟机的 Python 解析器相关设定,这样我们通过 SFTP 从本地发送到虚拟机的Python 脚本才能知道使用哪个解析器进行解析运行


9.选择"ssh-interpreter”,配置虚拟机的地址,用户名和密码。


10.interpreter 需要选择Python的所在路径,这里设置为/usr/bin/python3。把本地项目路径D:/workspaces/workspace_python/spark-exp映射到虚拟机的路径/home/hadoop/spark-exp,如果虚拟机路径不存在请先创建。完成以后点击"Finish”。

11.在 spark-exp 项目下新建一个 wordcount2.py 文件。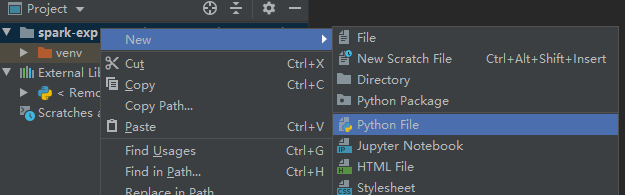
12.wordcount2 输入以下代码
from pyspark import SparkContext
sc = SparkContext("spark://node0:7077", "WordCountApp")
rs = sc.textFile("/home/hadoop/你的学号/wc.txt").flatMap(lambda line: line.split(" ")).map(lambda w: (w, 1)).reduceByKey(lambda x, y: x+y).sortBy(lambda x:x[1], False).collect()
for e in rs:
print(e)
把wordcount2.py 文件上传到虚拟机

14.编辑 python 脚本的运行设置模板。

15.新增一个 python 运行设置模板。

16.在环境变量中增加以下虚拟机的变量
SPARK_HOME /opt/spark
PYTHONPATH /opt/spark/python
JAVA_HOME /opt/jdk8
HADOOP_HOME /opt/hadoop
SCALA_HOME /opt/scala2-12

17.
把"Script path"配置设置为本地 wordcount2.py 文件路径。“Python interpreter” 选择刚创建的解析器。

18.从模板创建一个运行设置

19.启动虚拟机的spark
20.运行 wordcount2 看是否能够得到结果
















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









