






 本文深入探讨了自动编码器的各种类型,包括堆叠自编码器、欠完备/过完备自编码器、稀疏自编码器和除噪自编码器。这些模型在特征学习和数据降维方面起着关键作用。同时,文章还介绍了生成对抗网络(GANs),强调其在密度估计和生成新样本的能力。GANs通过竞争性的训练过程,由生成器和判别器共同学习数据分布。此外,提到了其他GAN变种如条件GAN和InfoGAN,它们增强了模型的稳定性和应用范围。
本文深入探讨了自动编码器的各种类型,包括堆叠自编码器、欠完备/过完备自编码器、稀疏自编码器和除噪自编码器。这些模型在特征学习和数据降维方面起着关键作用。同时,文章还介绍了生成对抗网络(GANs),强调其在密度估计和生成新样本的能力。GANs通过竞争性的训练过程,由生成器和判别器共同学习数据分布。此外,提到了其他GAN变种如条件GAN和InfoGAN,它们增强了模型的稳定性和应用范围。
文章目录
自动编码器 (Autoencoders)
从概念上讲,自动编码器是一个前馈网络 (feedforward network),经过训练可以将其输入 复制到 其输出 (尽管不完美)
结构包含了隐藏层
h
h
h,描述 表示输入 的编码。
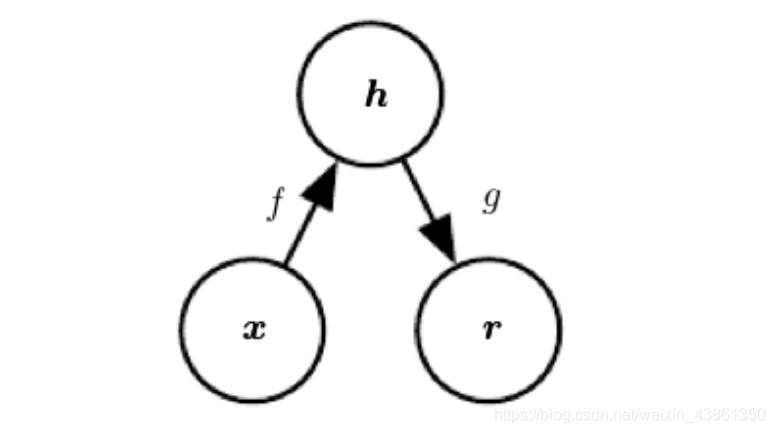
自动编码器 一般结构: 输入
x
x
x 通过 内部表示 或 编码 (internal representation or code)
h
h
h 映射到 输出
r
r
r (重构)。
自动编码器拥有两部分: 能产生 输入的 表示编码 (representative code) 的编码函数 (encoder function) h = f ( x ) h=f(x) h=f(x); 从 编码 生产出的重构的 解码器函数 (decoder function) r = g ( h ) r = g(h) r=g(h)
自动编码器 到 随机映射 (stochastic mappings) 的泛化: p e n c o d e r ( h ∣ x ) p_{encoder}(h | x) pencoder(h∣x) 以及 p d e c o d e r ( x ∣ h ) p_{decoder}(x | h) pdecoder(x∣h)
典型的训练策略类似于 前馈网络 使用的策略 —— 小批量梯度下降 (minibatch gradient descent)
堆叠自编码器 (Stacked Autoencoder)
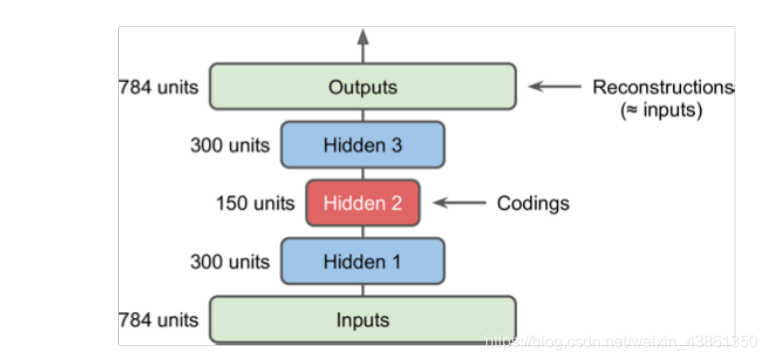
用于 MNIST 数据集的 堆叠自动编码器 (stacked autoencoder) 示例: 784 (
28
×
28
28 × 28
28×28) 个输入神经元; 300 个隐藏神经元 (hidden neurons) ; 150 个中央隐藏神经元 (central hidden neurons) ; 顶部是之前描述的镜像。
实用的自编码器是一个栈。
堆叠自编码器 的架构通常 关于 中央隐藏层 (编码层) 对称。
欠完备/过完备自编码器 (Undercomplete/ Overcomplete autoencoders)
将
h
h
h 限制为比
x
x
x 更小的维度会导致 欠完备自动编码器。
h
h
h 捕获输入的最显着特征 (most salient features)。
学习需要最小化损失函数:
L
(
x
,
g
(
f
(
x
)
)
)
L(x, g(f(x)))
L(x,g(f(x)))
若
g
(
f
(
x
)
)
g(f(x))
g(f(x)) 和
x
x
x 不相似,
L
L
L 进行惩罚。
如果 编码 的维度大于输入的参数,我们就有 过完备自动编码器。
通过使用正则化,我们可以训练任何自动编码器架构,而不会出现 容量过剩 (over-capacity) 或 学习简单代表 (learning a trivial identity) 的风险。
正则化可以将属性分配给损失函数:
- 数据表示的稀疏性。
- 小的数据表示的导数。
- 对噪声有健壮性。
- 对缺失数据有健壮性。
自动编码器和主成分分析
使用 线性解码器 g ( h ) g(h) g(h) 和 均方误差损失 (mean squared error loss),欠完备自动编码器 学习 与 PCA 相同的子空间。
使用 非线性编码器 和 解码器 (分别为 f ( x ) f(x) f(x) 和 g ( h ) g(h) g(h)),自动编码器可以学习更强大的 PCA 泛化。
稀疏自动编码器 (Sparse Autoencoders)
稀疏自动编码器 具有 用于在 编码层
h
h
h 上 以 重构误差 (reconstruction error) 和 稀疏惩罚形式 (sparsity penalty) 进行训练的成本函数:
L
(
x
,
g
(
f
(
x
)
)
)
+
Ω
(
h
)
L(x, g(f(x))) + \Omega(h)
L(x,g(f(x)))+Ω(h)
其中
h
h
h 是 编码器输出,如之前解释的,
h
=
f
(
x
)
h = f(x)
h=f(x)。
稀疏自编码器 可用于 学习可以输入 其他任务的特征,例如 分类 (半监督分类)。
稀疏自编码器 可以解释为 近似 最大似然 (maximum likelihood) 训练的 生成模型,该模型具有潜在变量 ( h h h)
在这方面,其最大化:
l
o
g
p
m
o
d
e
l
(
h
,
x
)
=
l
o
g
p
m
o
d
e
l
(
h
)
+
l
o
g
p
m
o
d
e
l
(
x
∣
h
)
log_{p_{model}} (h, x) = log_{p_{model}}(h) + log_{p_{model}}(x|h)
logpmodel(h,x)=logpmodel(h)+logpmodel(x∣h)
l
o
g
p
m
o
d
e
l
(
h
)
log_{p_{model}}(h)
logpmodel(h) 可以是稀疏诱导 (sparsity-inducing)
除噪自编码器 (Denosing Autoencoders)
除噪 旨在 减少信号中的噪声。
除噪自编码器 最小化:
L
(
x
,
g
(
f
(
x
‾
)
)
)
L(x, g(f(\overline{x})))
L(x,g(f(x)))
其中
x
‾
\overline{x}
x 是被 某种噪声 破坏的
x
x
x 的副本。
训练流程 使 f f f 和 g g g 隐式学习 p d a t a ( x ) p_{data}(x) pdata(x) 的结构。
另一种正则化的形式
λ
∑
i
∣
∣
∇
x
h
i
∣
∣
2
\lambda \sum_i ||\nabla_x h_i||^2
λ∑i∣∣∇xhi∣∣2 使得 学习 一个在
x
x
x 稍有微小变化时 的函数。
L
(
x
,
f
(
g
(
x
)
)
)
+
λ
∑
i
∣
∣
∇
x
h
i
∣
∣
2
L(x, f(g(x))) + \lambda \sum_i ||\nabla_x h_i||^2
L(x,f(g(x)))+λi∑∣∣∇xhi∣∣2
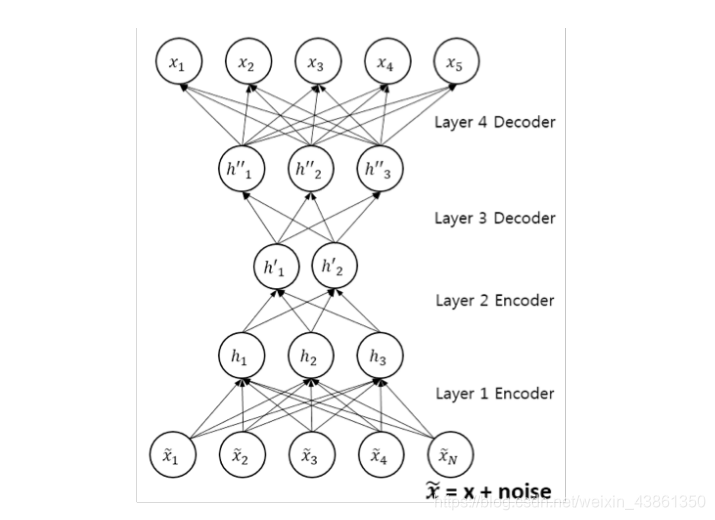
上图表示 堆叠卷积降噪自编码器 (stacked convolutional denoising autoencoder)。
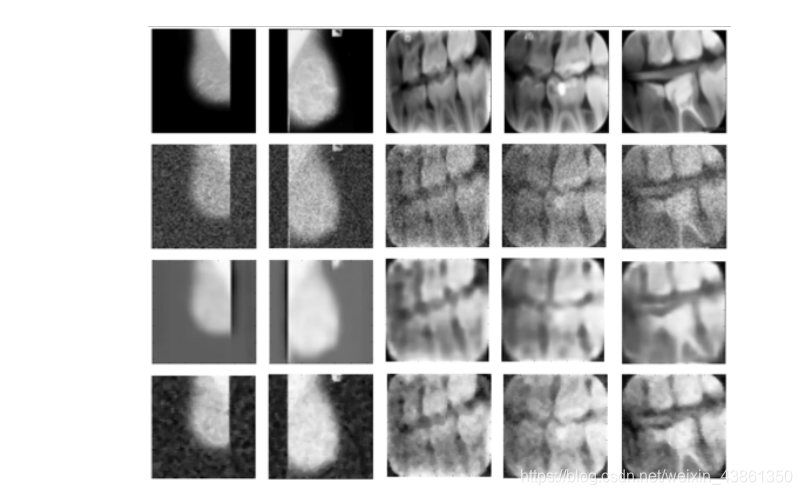
上图表示 堆叠卷积去噪自编码器 和 中值滤波器 (median filter) 输出的比较,其加入了高斯噪声:
μ
=
0
,
σ
=
1
μ = 0, σ = 1
μ=0,σ=1
更多编码器 - 成本函数
收缩自编码器 (Contractive autoencoder)
在代码
h
=
f
(
x
)
h = f(x)
h=f(x) 上引入正则化,以鼓励
f
f
f 的导数尽可能小:
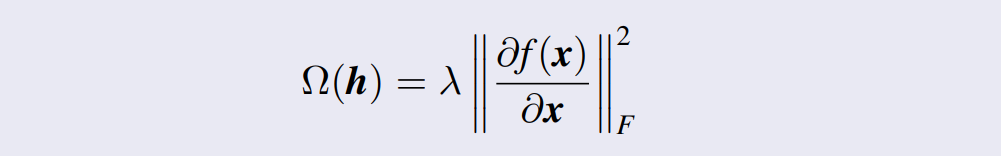
当输入噪声小且高斯时,收缩自编码器 和 去噪自编码器 相关:
- 去噪自编码器 使 重构函数 抵抗输入的 小但有限 的 震荡 (perturbations)。
- 收缩自编码器 使 特征提取函数 抵抗输入的 小但无穷 的震荡。
生成对抗网络 (Generative Adversarial Network - GAN)
GAN 要解决的核心问题是 密度估计 (density estimation),GAN 隐式地 捕获 数据背后的分布 (underlying data distribution)。
GAN 可以被用在 非监督 或 监督 学习场景上。
其特点是 竞争式地 训练两个网络:
- 有一个 名为 生成器 (generator G G G) 的网络,它试图从给定数据中学习的分布中生成样本,即 模仿,伪造或合成数据。
- 第二个网络是 判别器 (discriminator D D D),它能够区分合成样本 (synthetic samples) 和真实样本。
这个解决方案的目标是为了生成 与 真实信号 没有区别的 合成信号。
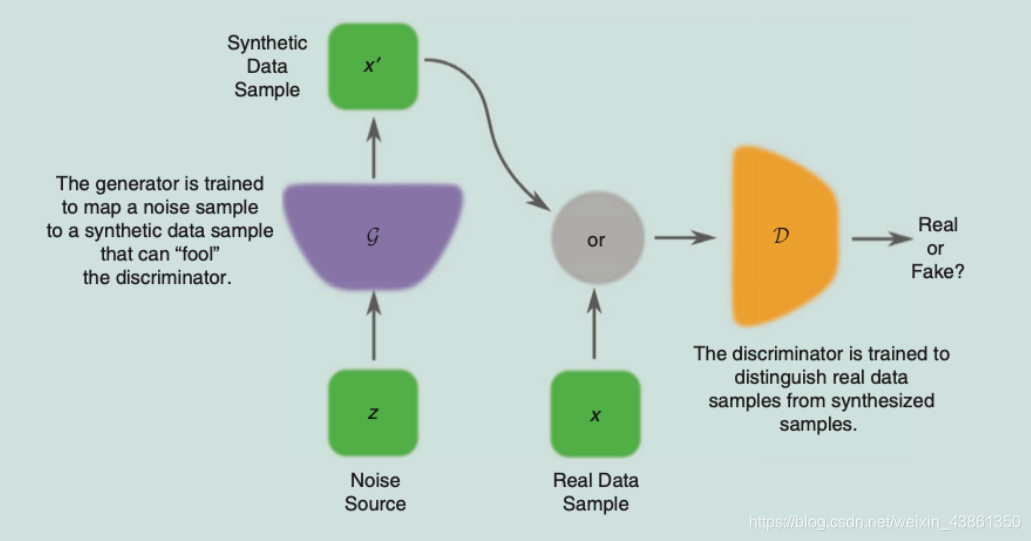
上图表示,训练 GAN 时学习了两个模型,一个是 生成器 (
G
G
G) 另一个是 判别器 (
D
D
D)。这是使用神经网络实现的模型,但也可以使用任何可微分系统 (differentiable system)。
如上图,生成器不会接触到真实样本。
生成器网络
G
G
G 将 一些 表示空间 (representation space/ latent space) 映射到 数据样本空间:
g
:
g
(
z
)
→
R
∣
x
∣
g: g(z) \to R^{|x|}
g:g(z)→R∣x∣
其中
z
∈
R
∣
x
∣
z \in R^{|x|}
z∈R∣x∣ 是数据样本,而
∣
.
∣
|.|
∣.∣ 表示数据维度。
判别器网络
D
D
D 将 数据样本 映射到 样本来自 真实数据分布而非生成器分布 的概率:
D
:
D
(
x
)
→
(
0
,
1
)
D: D(x) \to (0, 1)
D:D(x)→(0,1)
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x) 代表了 数据样本的概率密度函数 (在
R
∣
x
∣
R^{|x|}
R∣x∣中),而
p
g
(
x
)
p_g(x)
pg(x) 代表了生成器产生的样本分布。
在训练过程,我们将 目标函数 设置为 对于生成器 J G ( Θ G ; Θ D ) J_G(\Theta_G;\Theta_D) JG(ΘG;ΘD),对于判别器 J D ( Θ D ; Θ G ) J_D(\Theta_D;\Theta_G) JD(ΘD;ΘG)
注意到 J G J_G JG 以及 J D J_D JD 在网络参数上是相互依赖的 (co-dependent), Θ G \Theta_G ΘG 以及 Θ D \Theta_D ΘD 作为网络被迭代训练。
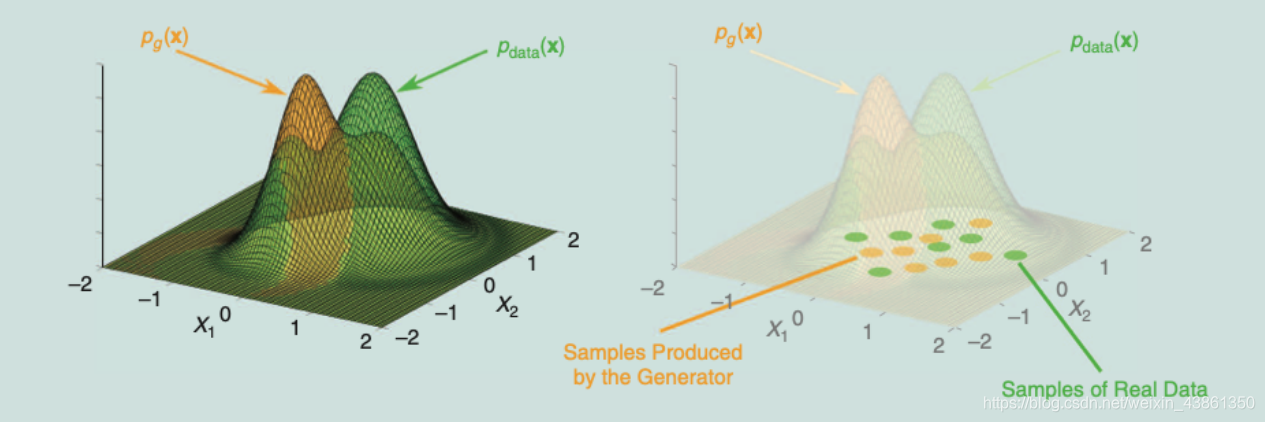
上图表示 在 GAN 的训练过程中,生成器 被鼓励生成 能 匹配真实数据分布
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x) 的 样本分布
p
g
(
x
)
p_g(x)
pg(x)。
GAN 训练
我们寻找判别器的参数,使其最大限度地提高分类精度,并找到一个最大限度能 混淆判别器 (confuses the discriminator) 的 生成器 的参数。
使用 价值函数 (value function) 评估训练成本,解以下的极小极大问题 (mini-max problem):
m
a
x
D
m
i
n
g
V
(
g
,
D
)
max_Dmin_gV(g, D)
maxDmingV(g,D)
其中
V
(
g
,
D
)
=
E
p
d
a
t
a
(
x
)
l
o
g
D
(
x
)
+
E
p
g
(
x
)
l
o
g
(
1
−
D
(
x
)
)
V(g, D) = E_{p_{data(x)}}logD(x) + E_{p_{g(x)}}log(1 - D(x))
V(g,D)=Epdata(x)logD(x)+Epg(x)log(1−D(x))
当一个模型的参数是固定的,另一个模型的参数可以被更新。
最优的判别器是唯一的:
D
∗
(
x
)
=
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
D^*(x) = \frac{p_{data(x)}}{p_{data(x)}+p_{g(x)}}
D∗(x)=pdata(x)+pg(x)pdata(x)
当以下条件满足,生成器是最优的:
p
g
(
x
)
=
p
d
a
t
a
(
x
)
p_{g(x)} = p_{data(x)}
pg(x)=pdata(x)
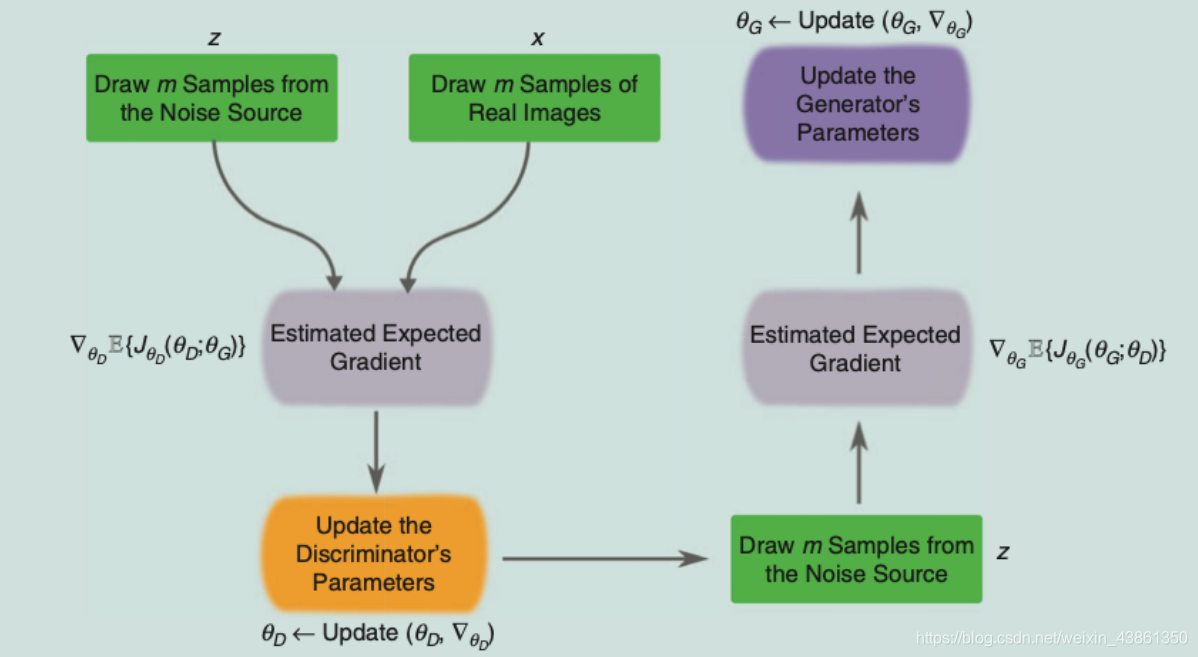
上图表示 GAN 训练的循环,新的数据样本
x
0
x_0
x0 可以通过 将随机样本
z
z
z 通过生成器网络来抽取。在更新生成器之前,判别器的梯度可能会更新
k
k
k 次。
其他 GAN 架构
初始 GAN 架构 使用全连接神经网络。其特点是难以训练,存在稳定性问题,其只在数据集的子集上成功。
深度卷积 GAN 提供了更高的稳定性。
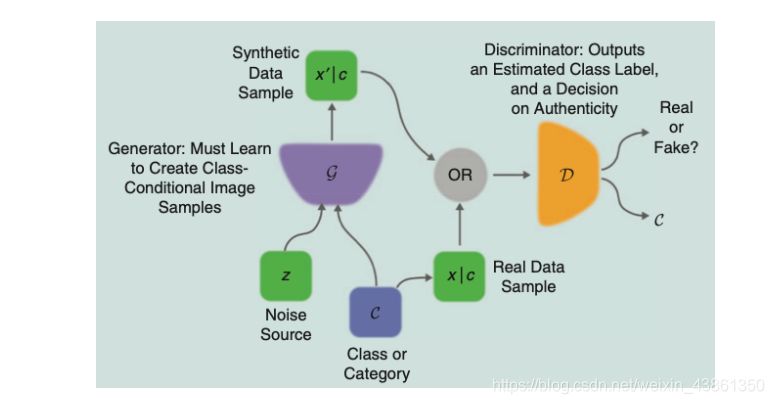
条件GAN (Conditional GAN),生成器和判别器网络都是 类条件的 (class-conditional)。其可以为 多模态数据生成 (multimodal data generation) 提供更好的表示。
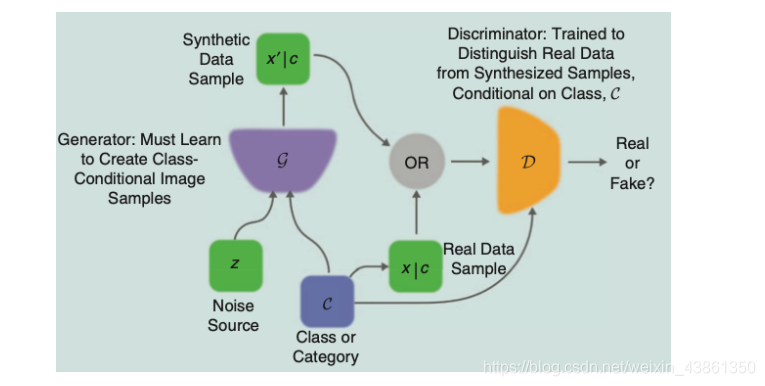
InfoGAN 将 噪声源 分解为 不可压缩源 (incompressible source) 和 潜在编码 (latent code),其尝试通过最大化 潜在编码 和 生成器输出 之间的互信息 (mutual information) 来发现 潜在的变异因素 (latent factors of variation)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









