










爬取B站用户和评论,并且按照条件进行抽奖
一、前言
这是我写的第一篇爬虫博客(所以写了挺多)。试了一下午,也就写成这样了。兄弟们能提出建议就非常好了,以后就按差不多的框架写(就是最近没啥时间写了)。
某赛尔号UP主出了个抽奖视频,我进去看了下,他说他每几个星期就会组织一次抽奖(评论太多,单单筛选就得半年,非常浪费时间),所以我作为群管理员(不干事的便宜管理),觉得应该帮UP抽奖,才对得起他。
抽奖规则就一个:评论区回复关键字
二、总思路
就这还思路,玩呢?
1.爬取需要的内容
爬取B站某视频下评论区的用户和评论
页面地址为:链接: https://www.bilibili.com/
爬取的评论:
2.整理数据并进行抽奖
会用到Pandas和Random库
学习链接: https://www.pypandas.cn/
三、爬虫
1. 选择库
爬虫的库有很多,想好自己要使用什么库来写是很重要的。考虑的因素有很多,比如运行速度,代码难度(静态网页,动态网页,反爬机制等)。我思考的就很简单,哪种简单写那个。因为我是初学,所以我抛开了运行速度,用了写起来比较简单的Selenium库
2. 引用库
import time # 做间隔
import csv # 存储数据
from selenium import webdriver
from bs4 import BeautifulSoup
import emoji # 去除恶心的表情
import re # 去除奇怪的字符和表情
3. 设置Selenium参数
# 设置浏览器后台执行
options=webdriver.ChromeOptions()
options.add_argument('headless') # 无头模式:设置浏览器后台运行(无界面状态)
#禁止图片和css的加载,来保证运行速度
prefs = {"profile.managed_default_content_settings.images": 2,'permissions.default.stylesheet':2}
options.add_experimental_option("prefs", prefs)
driver=webdriver.Chrome(options=options) # 创建Chrome浏览器对象。打开浏览器窗口
4.爬取数据:
先打开网页:
url = 'https://www.bilibili.com/video/BV1P5411a7NF' # 打开网页
driver.get(url)
driver.maximize_window()# 窗口最大化
time.sleep(2) # 停止2秒加载网页
运行后,把代码一层一层剥开,发现并不能找到评论区代码(没有箭头)

需要下拉滚动条到评论区,以获取评论区的代码,一次即可(翻页后自动到评论区)
js = "window.scrollTo(0,1000)"
driver.execute_script(js) # 执行js命令
time.sleep(2)
再次运行,发现多了些小箭头,这样源代码就加载出来了

目前为止的代码(自己跟着试试):
import time
import csv
from selenium import webdriver
from bs4 import BeautifulSoup
import emoji
import re
options = webdriver.ChromeOptions()
options.add_argument('headless')
prefs = {"profile.managed_default_content_settings.images": 2,'permissions.default.stylesheet':2}
options.add_experimental_option("prefs", prefs)
driver=webdriver.Chrome(options=options) # 创建Chrome浏览器对象。打开浏览器窗口
url = 'https://www.bilibili.com/video/BV1P5411a7NF' # 打开网页
driver.get(url)
driver.maximize_window()# 窗口最大化
time.sleep(2) # 停止2秒加载网页(时间按照网速和电脑运行速度决定)
js = "window.scrollTo(0,1000)"
driver.execute_script(js) # 执行js命令
time.sleep(1)
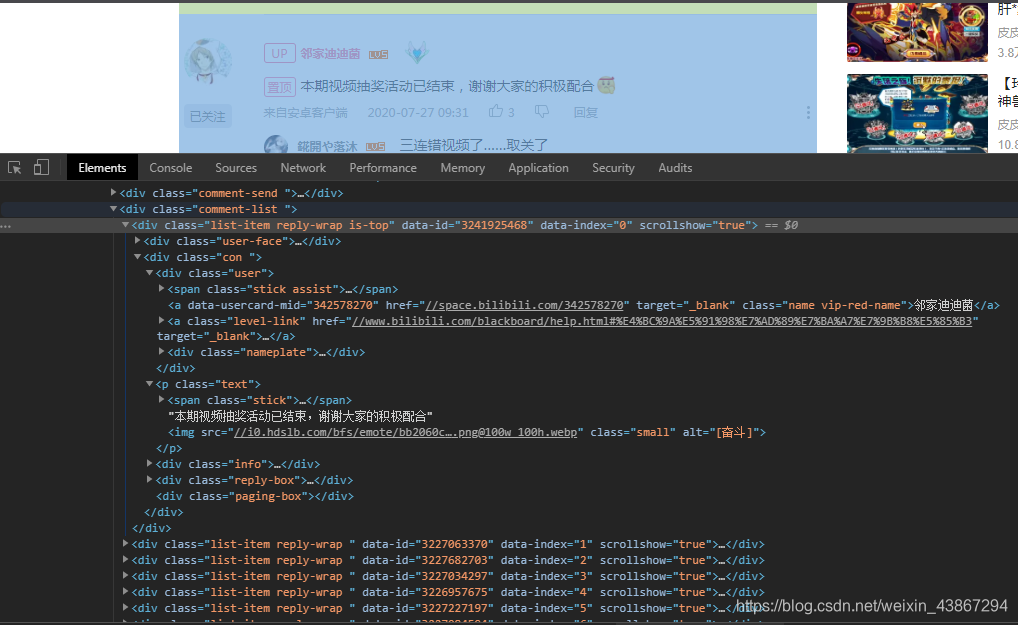
要爬的东西只有用户名和评论,一层层剥开分析

a标签,class=name
users = soup.find('div', class_='con').find_all_next('a', class_='name')

p标签,class=text
comments = soup.find('div', class_='con').find_all_next('p', class_='text')
把找到的用户名和评论保存到data列表
data = [['用户名', '评论']]
for (i, j) in zip(users, comments):
i = i.text
j = j.text
data.append([i, j])
接下来大概率出问题,因为现在人起昵称真的是什么都有,评论也有一堆无法识别的表情。
'''
出现报错:'gb2312' codec can't encode character '\U0001f251' in position 13: illegal multibyte sequence
原因:
爬取的数据中的emoji表情或者其他无法编码的东西
解决方法:
用现成的库emoji来处理emoji字符串。不过还是不够
'''
就算是这样,也还是有可能出现无法编码的东西,这个真的就请编码大佬来吧,我搜了好久也找不到好的方法。把这个编码问题完善好之后,我觉得放在GitHub星数肯定会非常非常高。感兴趣的可以试试哟,成功了就联系我,我想完善一下。O(∩_∩)O~
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U0001F250-\U0001F252"
u"\U0001F319"
u"\u2600-\u27FF"
u"\u2022-\u2FFF"
u"\u053e"
u"\ub000-\ubFFF"
u"\uf000-\uffff"
u"\ub77c"
u"\u3000-\u3040"
u"\u309f-\u31ff"
u"\u0111-\u10FF"
u"\u10FF-\u312F"
u"\u3130-\u318F"
# u"\xb4"
u"\u2714"
u"\u0300-\u0e07"
"]+", flags=re.UNICODE)
def filter_emoji(text):
return emoji_pattern.sub(r'', text)
for (i, j) in zip(users, comments):
i = emoji.emojize(i.text)
j = emoji.emojize(j.text)
data.append([filter_emoji(i), filter_emoji(j)])
这样第一页就抓取并保存完了,接下来是翻页

找到下一页的代码

然后再复制它的selector路径
# 点击下一页代码
driver.find_element_by_css_selector(
'#comment > div > div.comment > div.bb-comment > div.bottom-page.paging-box-big > a.next').click()
print('请等待......')
接下来的操作都重复的,加个循环就好,具体代码如下:
import time
import csv
from selenium import webdriver
from bs4 import BeautifulSoup
import emoji
import re
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U0001F250-\U0001F252"
u"\U0001F319"
u"\u2600-\u27FF"
u"\u2022-\u2FFF"
u"\u053e"
u"\ub000-\ubFFF"
u"\uf000-\uffff"
u"\ub77c"
u"\u3000-\u3040"
u"\u309f-\u31ff"
u"\u0111-\u10FF"
u"\u10FF-\u312F"
u"\u3130-\u318F"
# u"\xb4"
u"\u2714"
u"\u0300-\u0e07"
"]+", flags=re.UNICODE)
def filter_emoji(text):
return emoji_pattern.sub(r'', text)
options = webdriver.ChromeOptions()
options.add_argument('headless')
prefs = {"profile.managed_default_content_settings.images": 2,'permissions.default.stylesheet':2}
options.add_experimental_option("prefs", prefs)
driver=webdriver.Chrome(options=options) # 创建Chrome浏览器对象。打开浏览器窗口
url = 'https://www.bilibili.com/video/BV1P5411a7NF' # 打开网页
driver.get(url)
driver.maximize_window()# 窗口最大化
time.sleep(2) # 停止2秒加载网页
js = "window.scrollTo(0,1000)"
driver.execute_script(js) # 执行js命令
time.sleep(1)
page = int(input('请输入页数:'))
print('抓取时间视评论页数决定')
data = [['用户名', '评论']]
for i in range(page):
pageSource = driver.page_source # 获取Elements中渲染完成的网页源代码
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
users = soup.find('div', class_='con').find_all_next('a', class_='name')
comments = soup.find('div', class_='con').find_all_next('p', class_='text')
for (i, j) in zip(users, comments):
i = emoji.emojize(i.text)
j = emoji.emojize(j.text)
data.append([filter_emoji(i), filter_emoji(j)])
driver.find_element_by_css_selector(
'#comment > div > div.comment > div.bb-comment > div.bottom-page.paging-box-big > a.next').click()
print('请等待......')
print('评论全部抓取完毕')
driver.quit() # 这句必须要加,否则程序并不会停止,还在后台运行,多了之后内存就炸了!
5.保存数据到一个csv文件中
wb = r'D:\\候选名单.csv'
with open(wb, 'w', newline='') as myFile:
writer = csv.writer(myFile)
for i in data:
print(i)
writer.writerow(i)
四、抽奖
1.读取数据
data = []
path = r'D:\\候选名单.csv'
with open(path,'r') as csvFile:
reader = csv.reader(csvFile)
for item in reader: # 把数据放到列表中处理
data.append(item)
2.筛选数据、抽奖并显示结果
df = pd.DataFrame(data)
# 筛选出评论中包含关键字的,并把UP主给去除
comments = df[df.loc[:,1].str.contains('帝皇之御')&~df.loc[:,0].str.contains('邻家迪迪菌')]
# 去除重复的用户,保证公平。并放在result里
result = comments.drop_duplicates([0])
# result包含用户名和评论,评论不需要。
users = result[0].values
user = random.choices(users, k=2) # 从用户种随机抽取两名用户
print(user)
结果:

3.完整代码
import time
import csv
from selenium import webdriver
from bs4 import BeautifulSoup
import emoji
import re
import pandas as pd
import random
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U0001F250-\U0001F252"
u"\U0001F319"
u"\u2600-\u27FF"
u"\u2022-\u2FFF"
u"\u053e"
u"\ub000-\ubFFF"
u"\uf000-\uffff"
u"\ub77c"
u"\u3000-\u3040"
u"\u309f-\u31ff"
u"\u0111-\u10FF"
u"\u10FF-\u312F"
u"\u3130-\u318F"
# u"\xb4"
u"\u2714"
u"\u0300-\u0e07"
"]+", flags=re.UNICODE)
def filter_emoji(text):
return emoji_pattern.sub(r'', text)
options = webdriver.ChromeOptions()
options.add_argument('headless')
prefs = {"profile.managed_default_content_settings.images": 2,'permissions.default.stylesheet':2}
options.add_experimental_option("prefs", prefs)
driver=webdriver.Chrome(options=options) # 创建Chrome浏览器对象。打开浏览器窗口
url = 'https://www.bilibili.com/video/BV1P5411a7NF' # 打开网页
driver.get(url)
driver.maximize_window()# 窗口最大化
time.sleep(2) # 停止2秒加载网页
js = "window.scrollTo(0,1000)"
driver.execute_script(js) # 执行js命令
time.sleep(1)
page = int(input('请输入页数:'))
print('抓取时间视评论页数决定')
data = [['用户名', '评论']]
for i in range(page):
pageSource = driver.page_source # 获取Elements中渲染完成的网页源代码
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
#for i in range(21):
# soup.find('div', class_="reply-box").decompose()
# soup.find('div', class_="info").decompose()
users = soup.find('div', class_='con').find_all_next('a', class_='name')
comments = soup.find('div', class_='con').find_all_next('p', class_='text')
for (i, j) in zip(users, comments):
i = emoji.emojize(i.text)
j = emoji.emojize(j.text)
data.append([filter_emoji(i), filter_emoji(j)])
driver.find_element_by_css_selector(
'#comment > div > div.comment > div.bb-comment > div.bottom-page.paging-box-big > a.next').click()
print('请等待......')
print('评论全部抓取完毕')
driver.quit()
wb = r'D:\\候选名单.csv'
with open(wb, 'w', newline='') as myFile:
writer = csv.writer(myFile)
for i in data:
#print(i) # 查看结果用的
writer.writerow(i)
candidateList_path = r'D:\\候选名单.csv'
#list_path = r'D:\\抽奖名单.csv'
with open(candidateList_path,'r') as csvFile:
#读取csv文件,返回的是迭代类型
reader = csv.reader(csvFile)
for item in reader:
data.append(item)
df = pd.DataFrame(data)
# 筛选出评论中包含关键字的,并把UP主给去除
comments = df[df.loc[:,1].str.contains('帝皇之御')&~df.loc[:,0].str.contains('邻家迪迪菌')]
# 去除重复的用户,保证公平
result = comments.drop_duplicates([0])
# result.to_csv(list_path)
users = result[0].values
#with open(list_path, 'w') as myFile:
# writer = csv.writer(myFile)
# for i in users:
#print(i)
# writer.writerow(i)
# for i in range(users):
# print(i)
# k代表抽取的人数
user = random.choices(users, k=2)
print("中奖名单:")
print(user)
五、总结
Selenium是个很不错库,可以用来爬虫,模拟真实的浏览,这样很难被发现是爬虫。用这个库做爬虫,代码很简单,但是速度会慢很多,这里只是用来练习(只会这个,o(╥﹏╥)o)。














 5555
5555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









