






内存泄漏经常是由于scrapy开发者在Requests中(有意或无意)传递对象的引用(例如,使用meta属性或者request回调函数),使得该对象的生命周期与Request的生命周期所绑定。这是目前未知最常见的内存泄漏的原因,同时对新手来说也是一个比较难调式的问题。
在大项目中,spider是由不同的人所编写。而这其中的spider可能是有’泄露的‘,当所有的爬虫同时运行时,这些影响了其他(写好)的爬虫,最终,影响整个爬取进程。
与此同时,在不限制框架的功能的同时避免造成泄漏的原因十分困难。因此,我们决定不限制这些功能二十提供调式这些泄漏的实用工具。这些工具回答了一个问题:哪个spider在泄漏。
内存泄漏可能存在与一个您编写的中间件,管道(pipeline)或者扩展,在代码中您没有正确释放(之前分配的)资源。例如,您在spider_orened中分配资源但在spider_closed中没有释放它们。
使用trackref调式内存泄漏
trackref是scrapy提供哦那个与调式大部分内存泄漏情况的模块。简单来说,其追踪了所有活动(live)的Request,item及Selector对象的引用。
您可以进入telnet终端并通过prefs()功能来检查多少(上面所提到的)活跃(alive)对象。pref()是print_live_refs()功能的引用:

正如所见,报告也展现了每个类中最老的对象的时间(age)。if you’re running multiple spiders per process chances are you can figure out which spider is leaking by looking at oldest or response. You can get the oldest object of each class using the get_oldest() function(from the telnet console).
如果您有内存泄漏,那您能找到哪个spider正在泄漏的机会是查看最老的request或者response。您可以使用get_oldest()方法来获取每个类中最老的对象,正如此所示(在终端中)(原文档没有样例)。
哪些对象被追踪了?
trackref追踪的对象包括以下类(及其子类)的对象:
- scrapy.http.Request
- scrapy.http.Response
- scrapy.item.Item
- scrapy.se;ector.Selector
- scrapy.spider.Spider
真实例子
让我们来看一个假设的具有内存泄漏的准确例子。
假如我们有些spider的代码中有一行类似这样的代码
return Request("http://www.somenastyspider.com/product.php?pid=%d" % product_id, callback=self.parse, meta={referer: response}")
代码中的request中传递了一个response的引用,使得response的生命周期与request所绑定,进而造成了内存泄漏。
让我们来看看如何使用trackref工具来发现哪一个是有问题的spider(当然是在不知道任何的前提的情况下)。
当crawler运行了一小阵子后,我们发现内存占用增长了很多。这时候我们进入telnet终端,查看活跃(live)的引用:
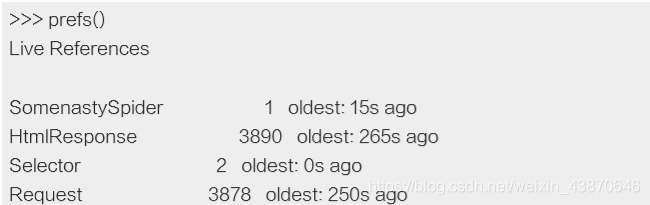
上面具有非常多的活跃(且运行时间很长)的response,而其比Request的时间还有长的现象肯定是有问题的。因此,查看最老的response:

就这样,通过查看最老的reponse的URL,我们发现其属于somenastyspider.com spider。现在我们可以查看spider的代码并发现导致泄漏的那行代码(在request中传递response的引用)。
如果您想要遍历所有而不是最老的对象,您可以使用iter_all()方法:

很多spider?
如果您的项目有很多的spider,prefs()的输出会变得很难阅读。针对于此,该方法具有ignore参数,用于忽略特定的类(及其子类)。例如:

将不会展现任何spider的活跃引用。
scrapy.utils.trackref模块
以下是trackref模块中可用的方法。
class scrapy.utils.trackref.object_ref
如果您想通过trackref模块追踪活跃的实例,继承该类(而不是对象)。
scrapy.utils.trackref.print_live_refs(class_name,ignore=NoneType)
打印活跃引用的报告,以类名分类。
参考:ignore(类或者类的元组)- 如果给定,所有指定类(或者类的元组)的对象将会被忽略。
scrapy.utils.trackref.get_oldest(class_name)
返回给定类名的最活跃(alive)对象,如果没有则返回None。首先使用print_libe_refs()来获取每个类所跟踪的所有活跃(live(对象的列表。
scrapy.utils.trackref.iter_all(class_name)
返回一个能给定类名的所有活跃对象的迭代器,如果没有则返回None。首先使用print_live_refs() 来获取每个类所跟踪的所有活跃(live)对象的列表。















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











