







爬虫js逆向系列
我会把做爬虫过程中,遇到的所有js逆向的问题分类展示出来,以现象,解决思路,以及代码实现。我觉得做技术分享,不仅仅是要记录问题,解决办法,更重要的是要提供解决问题的思路。怎么突破的,遇到这个问题怎么思考,尝试的方法有哪些。这样就可以有的放矢。希望对大家有用
爬虫认知
在程序猿所有的方向中,爬虫是离money最近的一个方向,你的明白?而且爬虫可发展的方向很多,前可走大数据,人工智能,后可转后端,还有就是安全领域。而且爬虫做得好,要求的技术栈还是比较全面的。如果你对爬虫有兴趣,欢迎加V:13809090874,一起沟通交流
免责申明:
此内容仅供学习交流使用,不用于商业用途,如果涉及侵权,联系作者删除
上面一篇我们说完了请求参数的破解,用我们模拟的请求链接+固定的cookies就可以通过代码的形式访问接口了。但有一个问题就是cookies是有失效期的,过一段时间,cookies就不能用了,我们必须得去破解登录的问题,然后建立自己的cookies池,才能真正实现自动化抓取。
1. 先人工登录,观察一下需要什么
1.微信扫码登录
2. 账号密码登录
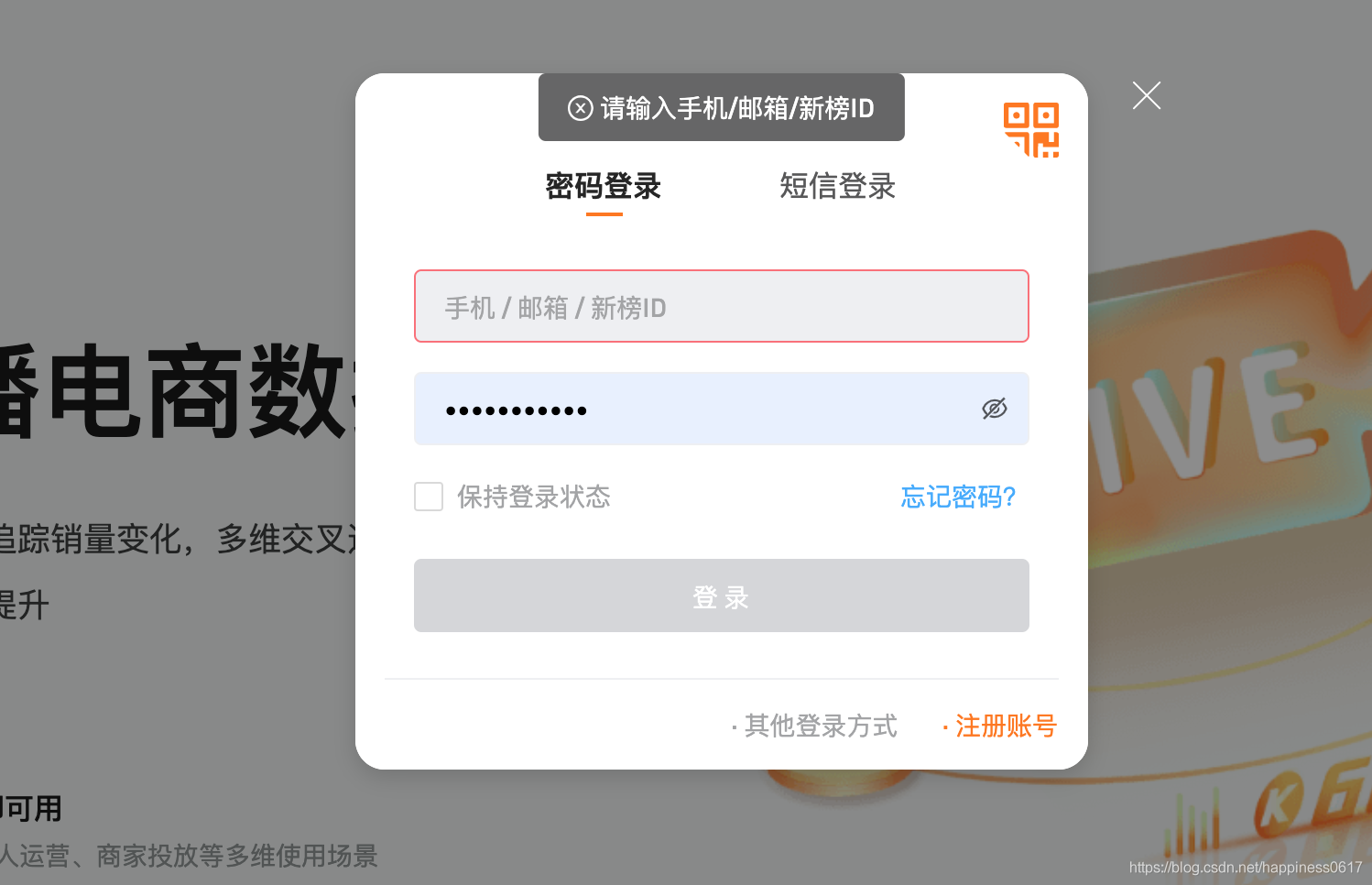
我们可以看到这里有三种登录方式:1.微信扫码登录,2.密码登录,3.短信登录。
这其中难度系数,估计大家也都清楚,微信扫码登录和短信登录是很麻烦的,需要一些第三方服务,这个以后再讲。这个平台,可以用密码登录,最好不过了。
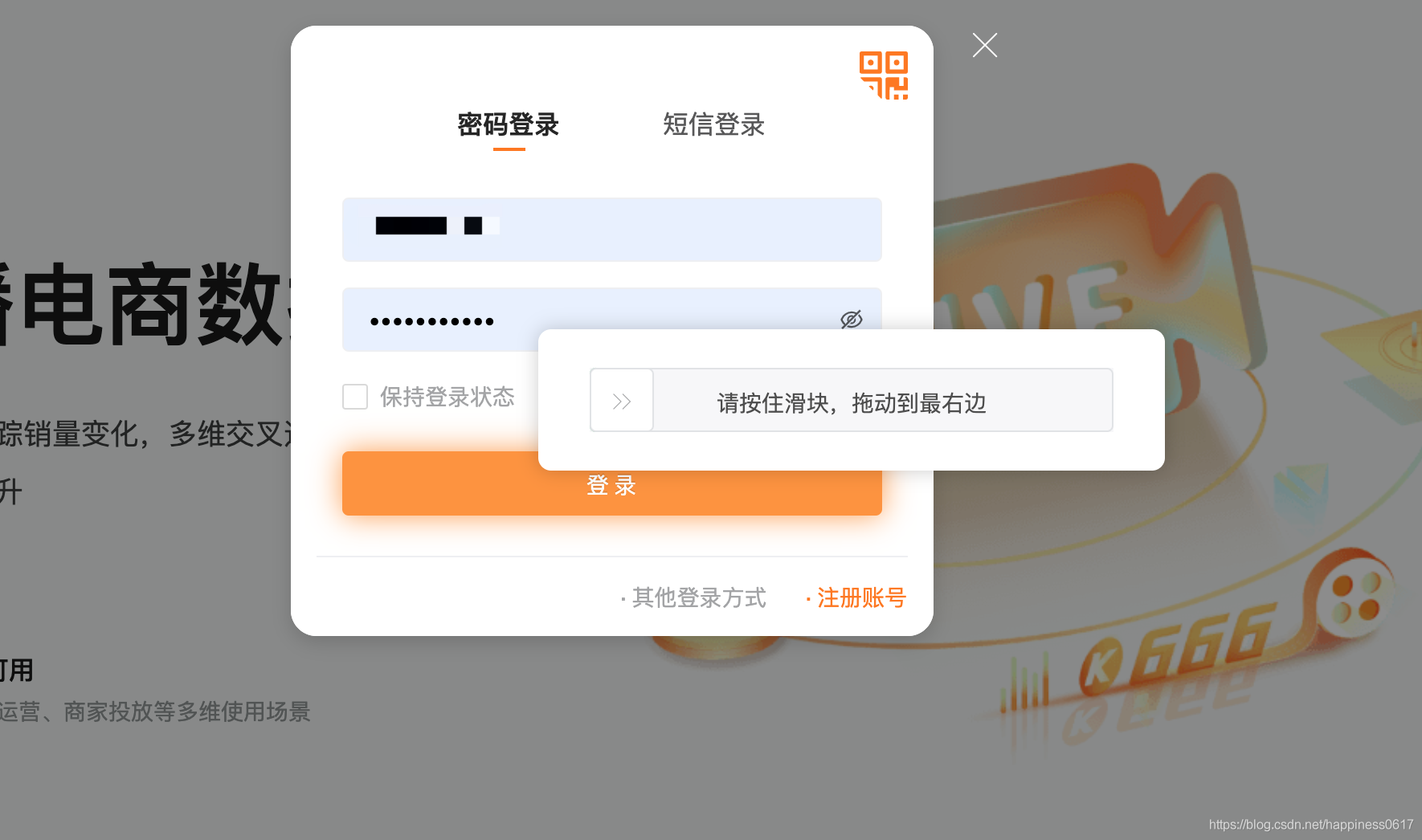
我们点击登录后需要拖动滑块。这个滑块,大家在看js的时候,如果细心一点,可以看到这个网站是调用阿里的滑块的服务的。
以下我给出的也是阿里滑块的通用解决方案。
阿里滑块解决–selenium屏蔽webdriver
我们通过selenium去调用chrome的webdriver,然后模拟拖动滑块,是拖不过去的,因为阿里会对你是不是用了webdriver进行检测的。
废话不多说,上代码:
def init_chrome_options(self,):
chrome_options = webdriver.ChromeOptions()
# 设置浏览器初始 位置x,y & 宽高x,y
chrome_options.add_argument(f'--window-position={217},{172}')
chrome_options.add_argument(f'--window-size={1200},{1000}')
# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式
# window.navigator.webdriver还是返回True,当返回undefined时应该才可行。
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 关闭开发者模式
chrome_options.add_experimental_option("useAutomationExtension", False)
# 禁止图片加载
# prefs = {"profile.managed_default_content_settings.images": 2}
# chrome_options.add_experimental_option("prefs", prefs)
# 设置中文
chrome_options.add_argument('lang=zh_CN.UTF-8')
# 更换头部
chrome_options.add_argument(
'user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
path = './../chromedriver'
driver = webdriver.Chrome(executable_path=path, options=chrome_options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
return driver
这是我常用的selenium配置,拿走不谢。
加上这个配置,然后通过selenium去拖动滑块就可以。这个滑块直接滑到最右边就可以。没有路径,速度检测的。
def login(self):
c_list = []
while 1:
driver = self.init_chrome_options()
try:
url = 'https://xk.newrank.cn/?backUrl=https%3A%2F%2Fxk.newrank.cn%2Fdata%2F'
driver.get(url)
time.sleep(1)
#获取登录元素,并输入账号密码
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/div/div[2]/div/div[1]').click()
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/div/div[2]/div/div[2]/div[2]/div[1]/input') \
.send_keys('xxxxx')
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/div/div[2]/div/div[2]/div[2]/div[2]/span/input') \
.send_keys('xxxxx')
time.sleep(1)
#点击登录按钮
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/div/div[2]/div/div[2]/div[2]/div[4]/button').click()
time.sleep(2)
#获取滑块按钮
slider = driver.find_element_by_id('nc_1_n1z')
#拖动滑块
action_chains = ActionChains(driver)
action_chains.click_and_hold(slider).perform()
action_chains.move_by_offset(xoffset=random.randint(380,450), yoffset=0).perform()
# action_chains.release(slider).perform()
time.sleep(3)
alert = EC.alert_is_present()(driver)
if alert:
print('出现弹窗')
alert.accept()
try:
WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.CLASS_NAME, 'nr-pro-menu-wrap'))
)
cookie = driver.get_cookies()
except UnexpectedAlertPresentException:
driver.switch_to.alert.accept()
WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.CLASS_NAME, 'nr-pro-menu-wrap'))
)
cookie = driver.get_cookies()
for item in cookie:
c = "{}={}".format(item['name'],item['value'])
c_list.append(c)
cookiestr = ';'.join(c_list)
print(cookiestr)
if 'token' in cookiestr:
self.redis_cli.lpush('ksxk_cookies',cookiestr)
print('登录成功')
break
else:
time.sleep(1)
except:
traceback.print_exc()
等这10个网站的爬虫研究完,会针对所有的登录问题,滑块问题,js混淆的问题等出一个垂直系列,敬请期待
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









