







前言
本篇主要实现的是对任意一部电影短评(热门)的抓取以及可视化分析。 也就是你只要提供链接和一些基本信息,他就可以
分析
对于豆瓣爬虫,what shold we 考虑?怎么分析呢?豆瓣电影首页
这个首先的话尝试就可以啦,打开任意一部电影,这里以姜子牙为例。打开姜子牙你就会发现它是非动态渲染的页面,也就是传统的渲染方式,直接请求这个url即可获取数据。但是翻着翻着页面你就会发现:未登录用户只能访问优先的界面,登录的用户才能有权限去访问后面的页面。
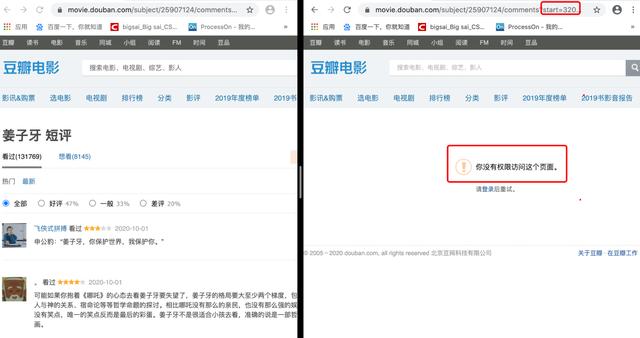
所以这个流程应该是 登录——> 爬虫——>存储——>可视化分析。
这里提一下环境和所需要的安装,环境为python3,代码在win和linux可成功跑,如果mac和linux不能跑友字体乱码问题还请私我。其中pip用到包如下,直接用清华 镜像下载不然很慢很慢(够贴心不)。如果大家在学习中遇到困难,想找一个python学习交流环境,可以加入我们的python圈,裙号930900780,可领取python学习资料,会节约很多时间,减少很多遇到的难题。
-
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple -
复制代码
登录
豆瓣的登录地址
进去后有个密码登录栏,我们要分析在登录的途中发生了啥,打开F12控制台是不够的,我们还要使用Fidder抓包。
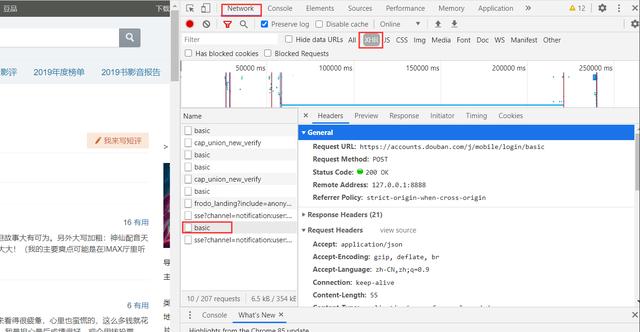
打开F12控制台然后点击登录,多次试探之后发现登录接口也很简单:
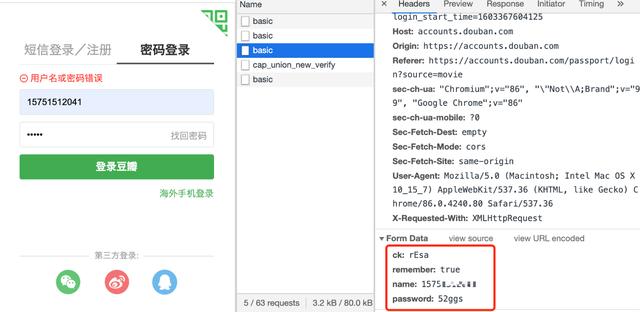
查看请求的参数发现就是普通请求,无加密,当然这里可以用fidder进行抓包,这里我简单测试了一下用错误密码进行测试。如果失败的小伙伴可以尝试手动登陆再退出这样再跑程序。
这样编写登录模块的代码:
-
url='https://accounts.douban.com/j/mobile/login/basic' -
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36', -
'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony', -
'Origin': 'https://accounts.douban.com', -
'content-Type':'application/x-www-form-urlencoded', -
'x-requested-with':'XMLHttpRequest', -
'accept':'application/json', -
'accept-encoding':'gzip, deflate, br', -
'accept-language':'zh-CN,zh;q=0.9', -
'connection': 'keep-alive' -
,'Host': 'accounts.douban.com' -
} -
data={ -
'ck':'', -
'name':'', -
'password':'', -
'remember':'false', -
'ticket':'' -
} -
def login(username,password): -
global data -
data['name']=username -
data['password']=password -
data=urllib.parse.urlencode(data) -
print(data) -
req=requests.post(url,headers=header,data=data,verify=False) -
cookies = requests.utils.dict_from_cookiejar(req.cookies) -
print(cookies) -
return cookies -
复制代码
这块高清之后,整个执行流程大概为:
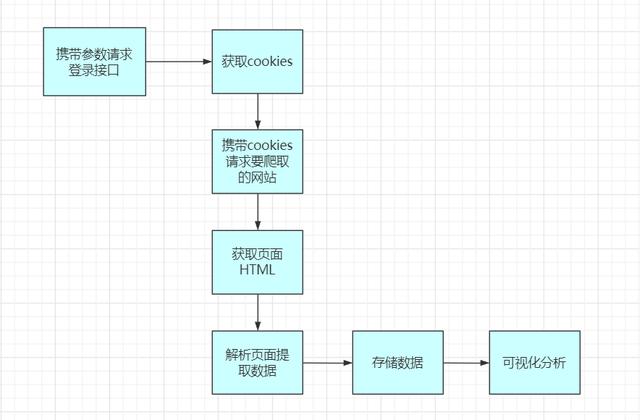
爬取
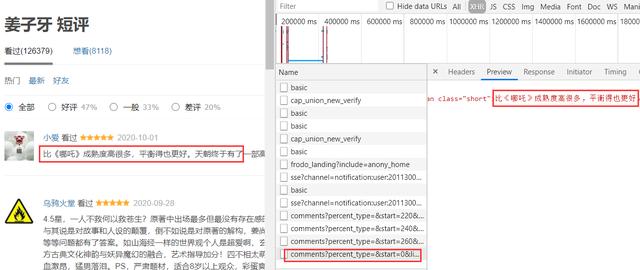
成功登录之后,我们就可以携带登录的信息访问网站为所欲为的爬取信息了。虽然它是传统交互方式,但是每当你切换页面时候会发现有个ajax请求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1905
1905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









