






环境准备
操作系统:centos7.6
cpu:8核
内存:32G
存储:200G
切换国内k8s源
cat << EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
查看当前库支持k8s版本
yum list kubeadm --showduplicates | sort -r

本文档以安装1.20.6版本为例进行安装
安装kube工具(k8s版本通过kubectl,kubeadm,kubectl版本决定)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/configsudo yum install -y kubelet-1.20.6-0
sudo yum install -y kubeadm-1.20.6-0
sudo yum install -y kubectl-1.20.6-0
sudo systemctl enable --now kubelet
yum update
开始安装
执行kubeadm init
报错如下:

按照报错逐个解决问题:
# 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
#关闭swap分区
vim /etc/fstab # 注释 swap 行
swapoff -a
[root@master ~]# free -h # swap 一行应该全部是 0
total used free shared buff/cache available
Mem: 31G 337M 27G 832M 3.5G 29G
Swap: 0B 0B 0B
#将master主机名加到hosts
echo "127.0.0.1 master" >> /etc/hosts
echo "127.0.0.1 node" >> /etc/hosts #后面kubeadm init需要
#安装docker环境
重新执行kubeadm init
报错如下:

解决办法:
rm -rf /etc/containerd/config.toml
systemctl restart containerd
下载镜像:
#查看镜像列表(不使用代理是下载不下来的)
[root@master ~]# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.20.15
k8s.gcr.io/kube-controller-manager:v1.20.15
k8s.gcr.io/kube-scheduler:v1.20.15
k8s.gcr.io/kube-proxy:v1.20.15
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0
可以使用国内镜像源下载,通过tag重命名
kubeadm config images pull --kubernetes-version v1.20.6 --image-repository registry.aliyuncs.com/google_containers
提供另一个最笨的方法,远程下载好了直接load进来(适用于所有难下载的镜像)
下面写一下思路,以后所有连接不上的镜像都可以这么下载,只是比较麻烦,治标不治本,还是推荐使用代理的方式
打开以上链接,点击launch Terminal可以启动一个远程环境,(只能试用一小段时间就会销毁)

执行以下语句,将需要下载的镜像保存下来:
docker pull k8s.gcr.io/kube-apiserver:v1.20.15
docker pull k8s.gcr.io/kube-controller-manager:v1.20.15
docker pull k8s.gcr.io/kube-scheduler:v1.20.15
docker pull k8s.gcr.io/kube-proxy:v1.20.15
docker pull k8s.gcr.io/pause:3.2
docker pull k8s.gcr.io/etcd:3.4.13-0
docker pull k8s.gcr.io/coredns:1.7.0docker save k8s.gcr.io/kube-apiserver:v1.20.15 -o kube-apiserver.tar
docker save k8s.gcr.io/kube-controller-manager:v1.20.15 -o kube-controller-manager.tar
docker save k8s.gcr.io/kube-scheduler:v1.20.15 -o kube-scheduler.tar
docker save k8s.gcr.io/kube-proxy:v1.20.15 -o kube-proxy.tar
docker save k8s.gcr.io/pause:3.2 -o pause.tar
docker save k8s.gcr.io/etcd:3.4.13-0 -o etcd.tar
docker save k8s.gcr.io/coredns:1.7.0 -o coredns.tar
然后执行下面语句打开简易的http服务:
python -m SimpleHTTPServer 30001
点击右侧+号,选择第三行 “select port to view on Host 1”,端口号输入刚刚打开的30001,点击“DIspaly Port”,即可下载刚刚保存的tar包

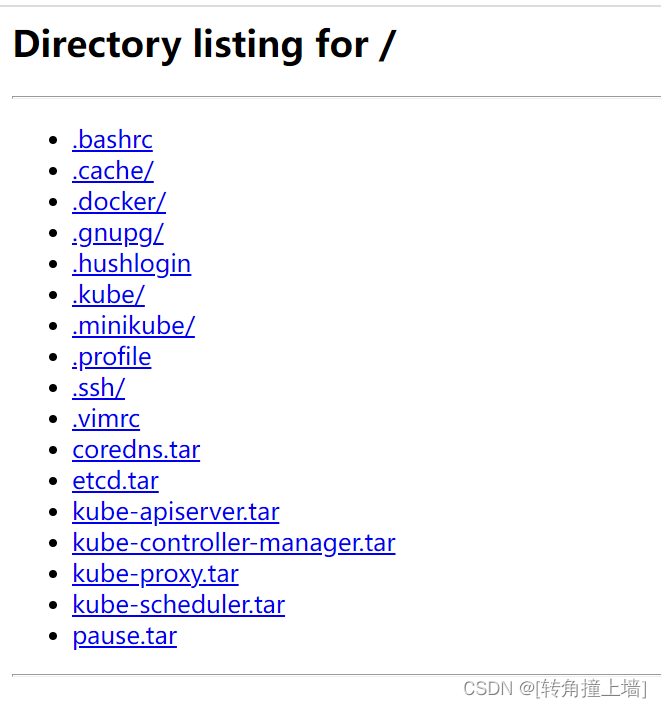
上传到自己的服务器,执行:
docker load -i kube-apiserver.tar
docker load -i kube-controller-manager.tar
docker load -i kube-scheduler.tar
docker load -i kube-proxy.tar
docker load -i pause.tar
docker load -i etcd.tar
docker load -i coredns.tar
自定义kubeadm配置(可选)
通过下面语句保存下kubeadm默认配置:
kubeadm config print init-defaults > kubeadm-init.yaml
修改配置文件,将imagePullPolicy设置为Never,因为镜像前面已经下载并加载进来了(默认是IfNotPresent,按理说本地存在应该就不用去远程下载了,但是不知道怎么回事一直去远程下载,导致失败)
执行:v 5是打印日志的级别,可以打印详细日志(如果执行失败,需要重新执行时,需要执行kubeadm reset进行重置,否则会失败)
kubeadm init --config kubeadm-init.yaml --v 5
也可以直接执行
kubeadm init --pod-network-cidr=10.10.0.0/16--service-cidr=10.20.0.0/16
- --kubernetes-version:指定kubernetes的版本号
- --pod-network-cidr:Pod可以用网络
- --service-cidr:Service可以用的网络
- --image-repository:指定国内的镜像仓库
将kubeadm init执行成功打印的kubeadm join语句保存下来,加入集群需要用到
执行成功后,如果是非root用户,执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果是root用户执行:
#并把该命令加到/etc/profile
export KUBECONFIG=/etc/kubernetes/admin.conf
问题处理:
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}
出现这种情况是kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,在文件中注释掉就可以了。(每台master节点都要执行操作)
#删除下面两个文件中的“--port=0”
sed-i'/--port=0/d'/etc/kubernetes/manifests/kube-controller-manager.yaml
sed-i'/--port=0/d'/etc/kubernetes/manifests/kube-scheduler.yaml
#重启kubelet
systemctl restart kubelet.service
- 修改/etc/kubernetes/manifests/kube-apiserver.yaml, 在 - --service-cluster-ip-range=10.20.0.0/16的下面加一行。
- 如果不修改,将无法使用较小的端口。(需重启kubelet服务)
vim/etc/kubernetes/manifests/kube-apiserver.yaml- --service-node-port-range=1-65355
如果想让master节点参与调度,执行:
kubectl taint nodes --all node-role.kubernetes.io/control-plane- node-role.kubernetes.io/master-
我这边只有master节点,没有control节点

添加master为worker角色
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 23m v1.20.6
kubectl label nodes 节点名字 node-role.kubernetes.io/ROLES属性名称=或-
#如果想删除,把=换成-
kubectl label nodes master node-role.kubernetes.io/worker=
[root@master pkg]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master,worker 119m v1.20.6
安装网络插件flannel
下载配置文件
wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
修改kube-flannel.yml中的Network的值,要与初始化时的参数--pod-network-cidr的值一致
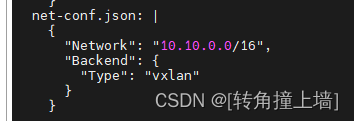
应用配置:
kubectl apply -f kube-flannel.yml
等待一段时间pods全启动起来了

node也已经ready

参考资料
kubernetes单机部署_wfx挥霍的人生的博客-CSDN博客_kubernetes单机部署
Installing kubeadm | Kubernetes
Creating a cluster with kubeadm | Kubernetes
centos7安装docker容器详细步骤_今天吃麻辣烫的博客-CSDN博客_centos7安装docker
Kubernetes02-安装Kubernetes(使用kubeadm) - 麦恒 - 博客园
https://www.jianshu.com/p/12154283470e















 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









